使用线程安全型双向链表实现简单 LRU Cache 模拟
Posted 苏州程序大白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用线程安全型双向链表实现简单 LRU Cache 模拟相关的知识,希望对你有一定的参考价值。
使用线程安全型双向链表实现简单 LRU Cache 模拟
目录

🌟博主介绍
💂 个人主页:苏州程序大白
💂 个人社区:CSDN全国各地程序猿
🤟作者介绍:中国DBA联盟(ACDU)成员,CSDN全国各地程序猿(媛)聚集地管理员。目前从事工业自动化软件开发工作。擅长C#、Java、机器视觉、底层算法等语言。2019年成立柒月软件工作室。
💬如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连)和C#、Halcon、python+opencv、VUE、各大公司面试等一些订阅专栏哦
🎗️ 承接各种软件开发项目
💅 有任何问题欢迎私信,看到会及时回复
👤 微信号:stbsl6,微信公众号:苏州程序大白
🎯 想加入技术交流群的可以加我好友,群里会分享学习资料
前言
双向链表是计算机内一种重要的数据结构。在例如 LRU 缓冲区调度算法、区块链技术等应用背景下发挥着重要的作用。同时在当今各种高并发的实用场景下,保证双向链表处于一个线程安全的状态,不会因为多线程并发造成数据混乱是一项最基本的要求。
github:https://github.com/sendwe/-LRU-Cache-
1、动机
在计算机内部,通常存在多个线程访问同一个双向链表的问题。在同一时刻,可能有多个线程对该链表进行修改或者读取。而又由于链表访问时必须从头部或尾部开始逐一访问,若同时有线程正在修改链表结构,则会造成读取错误。因此我们需要设计一个线程安全型的链表,保证链表的读写正确性,在多线程环境下链表也能正常工作。
1.1、要解决的问题
-
链表正常修改:在多线程环境下,能正确地修改链表结构。同时能提供删除、插入等功能。
-
链表正常访问:在多线程环境下,能正确地访问链表。同时能提供打印链表、查询链表等功能。
-
链表在生产环境中能正确运行:在实际生产环境当中,链表能稳定运行。在本课程设计当中,使用缓冲区调度算法最近最少使用(LRU)来作为生产环境示例。
2、系统设计
2.1、系统总体框架
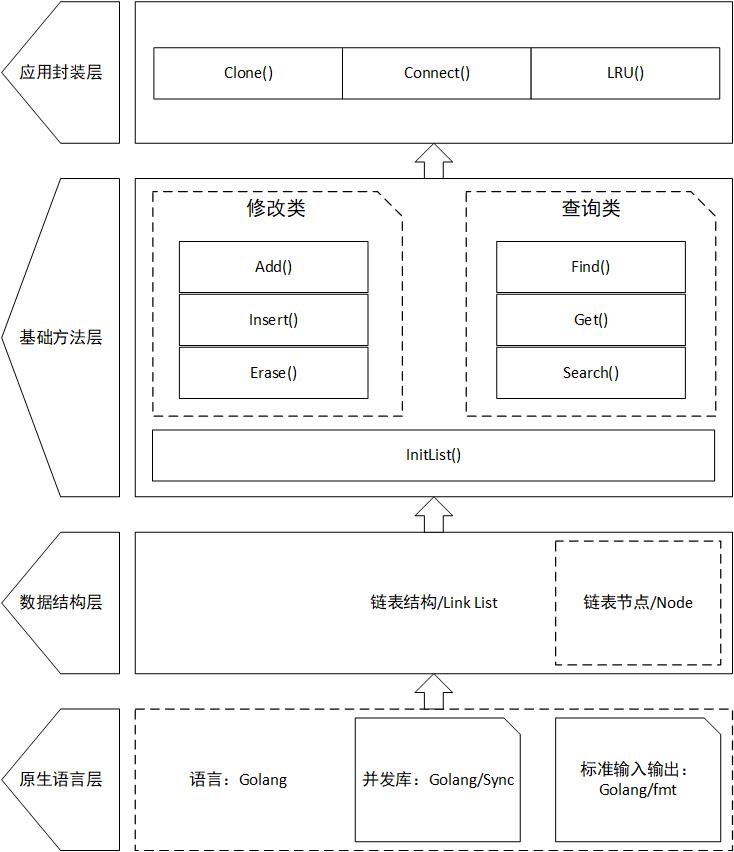
2.2、系统功能模块
-
原生语言层:本系统基于 Golang 语言进行开发。使用 Golang 及其提供的标准库,实现整个系统的全部功能。
-
数据结构层:使用传统的双向链表结构,每个链表节点带一个前驱指针与后继指针。
-
基础方法层:在传统双向链表的结构上增加了7种基础的链表操作方法,并保证其具有线程安全的特性。各方法功能请查看下表:
| 方法名称 | 介绍 |
|---|---|
| InitList() | 初始化双向链表 |
| Add() | 往链表末尾添加节点 |
| Insert() | 往指定的索引处插入节点 |
| Erase() | 删除指定位置的节点 |
| Find() | 传入一个节点实例,返回其索引 |
| Get() | 传入一个索引,返回其节点实例 |
| Search() | 传入一个数据值,返回第一个与数据值相等的节点实例 |
应用封装层:在保证基础方法线程安全的情况之下,再在其基础上进一步封装,增加了3种应用函数。
| 函数名称 | 介绍 |
|---|---|
| Clone() | 复制一个一模一样的双向链表 |
| Connect() | 连接两个链表 |
| LRU() | 使用该数据结构实现的 LRU 缓存调度算法 |
2.3 系统整体流程
下方是流程图描述的是使用该数据结构实现的 LRU 缓存调度算法:
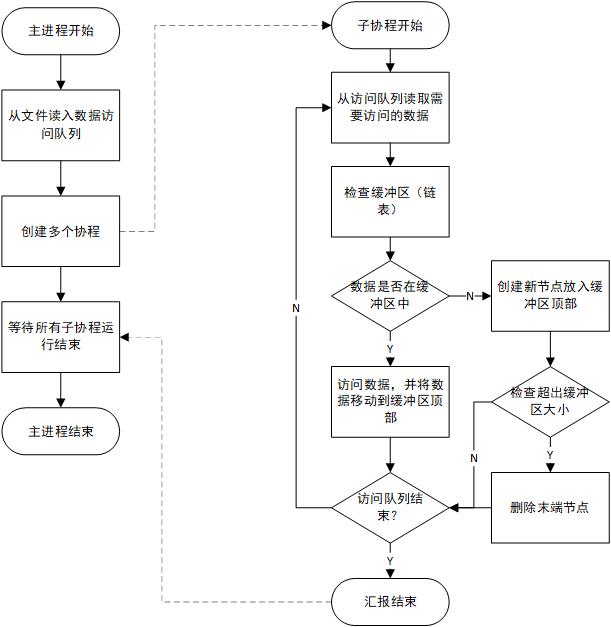
3、数据结构设计
节点/Node:
type Node struct {
Pre *Node // 前驱
Suc *Node // 后继
Data int // 数据
}
链表/LinkList
type LinkList struct {
Head *Node // 头部
Tail *Node // 尾部
Length int // 链表长度
}
缓冲区/CacheStruct:
type CacheStruct struct {
Cache LinkList // 缓冲区
MaxLength int // 缓冲区大小
}
4、关键技术与系统实现
4.1、生成访问序列
为了模拟 LRU 算法,我们需要生成每个子进程的访问序列,并将其保存于本地的 txt 文件当中。访问序列为一串数字列表,在系统运行后会写入访问序列并让每个子线程依次访问。
为了方便单独的调用与测试,访问序列的生成函数放入了单元测试文件中。每次会生成2次幂个自然数(在代码中生成数量为32个),并按照正态分布来生成访问序列。
以下为关键部分代码:
// 生成随机数列
func TestGenerate(t *testing.T) {
// 生成服从正态分布的随机数序列
var normalNumbersList string
s := 5.0 // 标准差
q := 100.0 // 期望
for i := .0; i < count; i ++ {
// 生成数字
num := rand.NormFloat64() * s + q
if num < 0 { // 防止出现小于0的数字
num = 0
}
// 将数字转化为字符串
normalNumbersList = normalNumbersList + strconv.Itoa(int(num)) + "\\n"
}
// 写入文件
err = ioutil.WriteFile("./numbers_list2.txt",[]byte(normalNumbersList), 0644)
if err != nil {
t.Fatal(err.Error())
}
}
4.2 各进程的推进
系统在运行时,会产生一个主进程和多个子线程。
主进程负责在开始时加载各个资源、访问序列,并初始化链表。之后便会创建多个子线程访问读取序列,并和包含了链表的缓冲区进行交互与调度。主进程由于只负责资源的分配调度,在将资源分配给子线程后便会结束程序,但同时子线程也将被关闭,这是我们不希望得到的。
为了避免这一情况的发生,引入了 golang/sync 库里的 WaitGroup() 方法。该方法在子线程开始前,需先使用 WaitGroup.Add() 声明创建的线程数量。在创建完所有子线程后,主进程并不会马上关闭,而是持续阻塞。当一个子线程运行完自己的任务后,会向主进程发送 WaitGroup.Done 报告。待所有子进程全部报告完成后,主进程才会结束。
以下为主进程的关键代码:
/*
实例:LRU最近最少使用调度
*/
func InstanceLRU() {
... // 从文件读入数组
linkList.InitList() // 创建基本链表
// 初始化
count := 3 // 线程数量
wg.Add(count) // 声明 WaitGroup
cache := CacheStruct{linkList, 15} // 创建缓冲区
// 创建子协程
for i := 0; i < count; i++ {
go func(id int) { // 创建子协程
for _, j := range numbersList { // 访问读取序列
LruCacheScheduling(id, &cache, j) // 调度函数
// 打印相关信息
...
}
wg.Done() // 汇报完成
}(i)
}
wg.Wait() // 阻塞
...
}
4.3、修改链表结构的相关方法实现
会对列表结构造成变化的主要有以下3个方法:
-
Add():往链表末尾添加节点。
-
**Insert():**往指定索引插入节点。
-
Erase():删除指定索引的节点.
在多线程修改链表结构时会引起“读者——写者”问题。因此,为了保证在修改链表时只有该子线程在对链表进行操作,引入 Go/Sync 包中的 RWMutex 方法。该方法会创建一个读写锁,当使用 RWMutex.Lock 时,便会以写者的身份申请临界资源并阻塞等待系统的调度。
待工作完成后,再使用 RWMutex.Unlock 释放读写锁以及相关的临界资源,从而保障了这些方法符合线程安全的基本要求。
Add()方法设计用于在初始化链表时能更快地往链表后方直接添加节点。在插入时,需同时修改链表最后一个节点的后继与链表的末尾指针。如果添加的是该链表的第一个元素,还应同时修改链表的头部指针指向该节点。插入后,该节点的前驱指针指向原本链表的末尾节点。
其逻辑上与 Insert() 方法一致,故不再展示该代码。
Insert() 方法可以根据索引在具体位置插入节点。该方法会从头部出发,直到找到索引标记的位置并将节点插入其中,并修改原本前驱与后继的关系。在插入到如头部或尾部等特殊位置时,还需要额外修改头指针或尾指针。
在插入节点前,为了避免该节点原有的数据造成影响,还需要设置其前驱与后继为 nil。
Insert() 方法的关键代码如下,rw.Unlock() 前的 defer 关键字表示该方法在函数结束后才运行:
/*
Insert: 在某一位置插入具体数值
position: 链表当中的位置
node: 需要插入的节点
*/
func (l *LinkList) Insert(position int, node *Node) error {
// 非法输入等异常处理
...
node.Pre = nil
node.Suc = nil
// 上读写锁
rw.Lock()
defer rw.Unlock()
// 插入数据
if (*l).Length == 0 { // 如果此时链表为0
(*l).Head = node
(*l).Tail = node
} else if position == (*l).Length { // 在最末尾插入
(*l).Tail.Suc = node
node.Pre = (*l).Tail
(*l).Tail = node
} else if position == 0 { // 在第一个位置插入
(*l).Head.Pre = node
node.Suc = (*l).Head
(*l).Head = node
} else { // 中间插入
item := (*l).Head
for i := 0; i < position-1; i++ {
item = item.Suc
}
... // 调整前驱与后继的关系
}
l.Length++
return nil
}
Erase() 方法会根据传入的数值,删除对应位置的节点。删除后调整其前驱与后继的关系,保证链表关系正确。
Erase() 关键部分代码如下:
/*
Erase: 删除具体位置的元素
position: 位置
*/
func (l *LinkList) Erase(position int) error {
...// 异常判断
// 上读写锁
rw.Lock()
defer rw.Unlock()
if position == 0 { // 删除头部
(*l).Head = (*l).Head.Suc
if (*l).Head != nil {
(*l).Head.Pre = nil
}
} else if position == (*l).Length-1 { // 删除末尾
(*l).Tail = (*l).Tail.Pre
(*l).Tail.Suc = nil
} else { // 删除其余位置
node := (*l).Head
for i := 0; i < position; i++ {
node = node.Suc
}
... // 调整前驱与后继的关系
}
(*l).Length--
return nil
}
4.4、访问链表的相关方法实现
负责链表访问的主要有以下4个方法:
-
Find():传入一个节点实例,返回其索引。
-
Get():传入一个索引,返回其节点实例。
-
Search():传入一个数据值,返回第一个与数据值相等的节点实例。
-
Display():将链表打印在屏幕上。
与修改链表类似,在对链表进行访问时,也同样需要套上读者锁。读者锁能支持多线程同时访问链表,实现线程安全的并发。当使用 RWMutex.RLock 时,便会以写者的身份申请临界资源并阻塞等待系统的调度。在读取完后,使用 RWMutex.RUnlock 进行释放。
Find()、Get()、Search() 三者逻辑基本一致,此处以 Find() 来进行说明。关键代码如下:
/*
Find: 查找
data: 所需要查找的节点地址
返回的节点地址和返回查找到的位置,如果未找到,返回 -1
*/
func (l *LinkList) Find(data *Node) int {
// 上读者锁
rw.RLock()
defer rw.RUnlock()
// 遍历查找
node := (*l).Head
p := 0
for node != nil {
if node == data {
return p
}
node = node.Suc
p++
}
return -1
}
4.5、应用封装层的实现
应用封装层包含以下三个函数:
-
LRU():缓冲区调度算法。
-
Clone():复制链表。
-
Connect():连接两个链表。
应用封装层为使用上述基础方法进一步实现的常用功能。因此其具有线程安全的特性。下面逐一对三个方法进行介绍。
最近最少使用策略 LRU(Least Recently Used)的基本思路是维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头部开始顺序遍历链表。
1、如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据的对应结点,并将其从原来的位置删除,并插入到链表头部。
2、如果此数据没在缓存链表中,又可以分为两种情况处理:
如果此时缓存未满,可直接在链表头部插入新节点存储此数据;如果此时缓存已满,则删除链表尾部节点,再在链表头部插入新节点。
下面为 LRU 的关键代码:
/*
LruCacheScheduling: LRU 调度函数
id:线程 id
linkList:缓冲区使用的链表
cap:缓冲区大小
*/
func LruCacheScheduling(id int, cacheStruct *CacheStruct, data int) {
node := cacheStruct.Cache.Search(data)
// 如果存在缓冲区内,则将其放到缓冲区顶部
if node != nil {
pos := cacheStruct.Cache.Find(node)
_ = cacheStruct.Cache.Erase(pos)
_ = cacheStruct.Cache.Insert(0, node)
} else { // 不在缓冲区内,则将其放入缓冲区
node := &Node{Pre: nil, Suc: nil, Data: data}
... // 异常处理
_ = cacheStruct.Cache.Insert(0, node)
// 超出缓冲区,删除最末尾的节点
if cacheStruct.Cache.Length > cacheStruct.MaxLength {
_ = cacheStruct.Cache.Erase(cacheStruct.Cache.Length - 1)
}
}
}
Clone() 方法用于拷贝、切片链表。它会先创建一个空链表,之后遍历被克隆的链表中的节点,并创建一个一模一样的节点到新的链表中。同时还支持接受一个开始与结束的参数,能对链表进行切片。
/*
Clone: 链表克隆
*/
func (l *LinkList) Clone(start int, end int) (LinkList, error) {
// 创建新链表
ll := LinkList{}
if end < start || start < 0 && end > l.Length {
return ll, errors.New("parameter is abnormal")
}
// 复制
for i := start; i < end-start; i++ {
node, _ := l.Get(i)
item := *node
_ = ll.Add(&item)
}
return ll, nil
}
Connect()方法则将两个链表进行连接。它首先会依次使用 Clone() 方法拷贝两个链表,之后再将两个拷贝后的链表进行对接。
/*
ConnectLinkList: 链表连接
*/
func ConnectLinkList(a LinkList, b LinkList) LinkList {
var res LinkList
// 拷贝两个数组
aCopy, _ := a.Clone(0, a.Length)
bCopy, _ := b.Clone(0, b.Length)
...// 临界值处理
// 连接
aCopy.Tail.Suc = bCopy.Head
bCopy.Head.Pre = aCopy.Tail
res = aCopy
return res
}
4.6、统计缓冲区命中率
统计缓冲区命中率,需要分别统计链表的访问次数以及命中次数。在多线程并发的情况下,然而如果仅仅只是对二者进行加一操作,会造成数据错误。因此在操作访问次数与命中次数时,需将其放入临界区,保证数据正确。
统计缓冲区命中率的相关代码放入 LRU 调度当中。其中 countLock 为定义的 Mutex 锁。
csharp
func LruCacheScheduling(id int, cacheStruct *CacheStruct, data int) {
...
// 如果存在缓冲区内,则将其放到缓冲区顶部
if node != nil {
...
countLock.Lock()
HitCount ++
VisitCount++
} else { // 不在缓冲区内,则将其放入缓冲区
...
countLock.Lock()
VisitCount++
}
countLock.Unlock()
}
5、系统运行结果
5.1、运行环境
系统运行环境
| 属性 | 值 |
|---|---|
| 处理器 | Intel® Core™ i5-8300H CPU @ 2.90GHz 2.90 GHz |
| 操作系统 | Windows 10 专业版 20H2 |
| RAM | 32.00 GB |
| 系统类型 | 64 位操作系统, 基于 x64 的处理器 |
| 开发环境 | Goland 2021.3 |
| 运行环境 | go1.16 windows/amd64 |
5.2、运行与测试结果
5.2.1、运行结果
个线程会将其调用信息打印在屏幕上,Thread ID 表明该信息来自于哪一个线程,Search Data 则代表当前线程正在访问的数据,后面的一串数列代表当前缓冲区。
通过观察缓冲区我们可以发现,每个线程将访问后的资源放到缓冲区首部,符合 LRU 调度算法。
由于本身屏幕也属于临界资源,因此也需要各线程进行抢夺。但在实际过程中发现,在给屏幕临界资源加锁后,线程阻塞时间变长,导致从宏观上各线程变成了线性进行,失去了并发性。
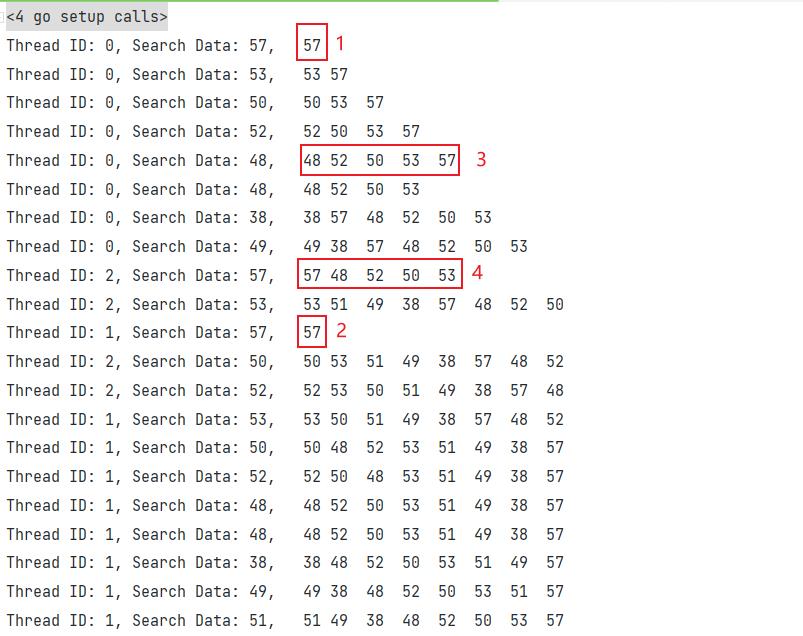
观察上方图可以发现,在线程0与线程1第一次出现时(图中标记位置1、2),缓冲区都仅有57这个数据,可见系统是并发执行的。当线程2第一次出现时(图中标记4),缓冲区当中已经拥有了一定数量的数据。经过观察可以发现,其调度发生在图中标记3之后,直接读取了缓冲区当中的数据57并将其放置在缓冲区首位。
下方图为结束时的运行结果,程序会计算缓冲区的命中率。
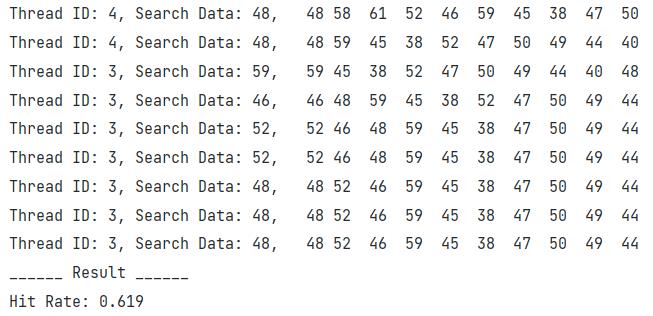
选用不同大小的缓冲区进行测试,可以得到不一样的命中率。由图5.3可知,该系统缓冲区的工作点位于11~12大小附近。
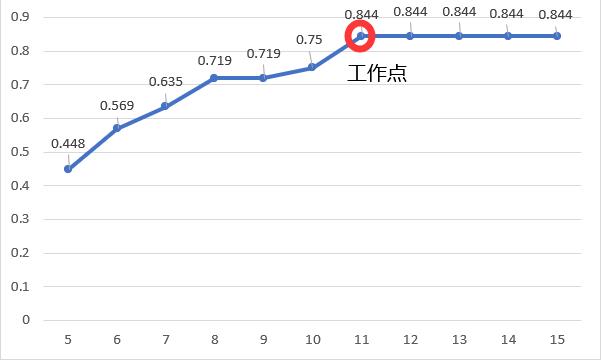
5.2.2、链表方法测试
我们对该系统的基础操作方法以及部分应用封装层的方法进行了自动化测试。测试选用的平台为 Golang 原生的测试工具 Go_Test。
测试样本选用了3组数据,内容如下方表所示:
| 样本名 | 值 |
|---|---|
| testNode1 | Node{Data: 100} |
| testNode2 | Node{Data: 101} |
| testNode3 | Node{Data: 102} |
下面表格展现了每个方法所测试的内容:
| 测试函数 | 测试值 | 测试内容 |
|---|---|---|
| Insert() | testNode1 | 插入末端 |
| Insert() | testNode2 | 插入索引20的位置 |
| Insert() | testNode3 | 插入首位 |
| Find() | testNode1 | 查询位置 |
| Find() | testNode2 | 查询位置 |
| Find() | Node{Data: 1022} | 查询位置(反例) |
| Search() | 100 | 查询位置 |
| Search() | 101 | 查询位置 |
| Search() | 1000 | 查询位置(反例) |
| Erase() | 末端 | 删除末端 |
| Erase() | 20 | 删除索引20的位置 |
| Erase() | 0 | 删除首位 |
| Get() | 0 | 查询首位 |
| Clone() | 0, 10 | 取得从0~10的链表切片 |
| Connect() | 克隆得到的新链表,原链表 | 测试连接 |
下面图是自动化测试后展现的结果,达到了90%以上的代码覆盖率。系统判定为通过:

6、调试与改进
实际上,对于 LRU 函数,并不是完全线程安全的。LRU 可以拆解为定位、删除、插入三个步骤,这三个步骤所对应的函数具有原子性,但对于这三个函数组成的 LRU 却不具有原子性。例如其中一个线程可以在另一个线程删除后进行插入等。
同时考虑到在多个连续操作时,线程锁连续地释放又被申请,造成了一定不必要的系统开销。因此在 LRU里面,可以将这三个函数拆解开来,放入到同一个临界区中,这样就解决了这个问题。
🌟作者相关的文章、资源分享🌟
🌟让天下没有学不会的技术🌟
学习C#不再是难问题
🌳《C#入门到高级教程》🌳
有关C#实战项目
👉C#RS232C通讯源码👈
👉C#委托数据传输👈
👉C# Modbus TCP 源代码👈
👉C# 仓库管理系统源码👈
👉C# 欧姆龙通讯Demo👈
👉C#+WPF+SQL目前在某市上线的车管所摄像系统👈
👉2021C#与Halcon视觉通用的框架👈
👉2021年视觉项目中利用C#完成三菱PLC与上位机的通讯👈
👉VP联合开源深度学习编程(WPF)👈
✨有关C#项目欢迎各位查看个人主页✨
🌟机器视觉、深度学习🌟
学习机器视觉、深度学习不再是难问题
🌌《Halcon入门到精通》🌌
🌌《深度学习资料与教程》🌌
有关机器视觉、深度学习实战
👉2021年C#+HALCON视觉软件👈
👉2021年C#+HALCON实现模板匹配👈
👉C#集成Halcon的深度学习软件👈
👉C#集成Halcon的深度学习软件,带[MNIST例子]数据集👈
👉C#支持等比例缩放拖动的halcon WPF开源窗体控件👈
👉2021年Labview联合HALCON👈
👉2021年Labview联合Visionpro👈
👉基于Halcon及VS的动车组制动闸片厚度自动识别模块👈
✨有关机器视觉、深度学习实战欢迎各位查看个人主页✨
🌟Java、数据库教程与项目🌟
学习Java、数据库教程不再是难问题
🍏《JAVA入门到高级教程》🍏
🍏《数据库入门到高级教程》🍏
有关Java、数据库项目实战
👉Java经典怀旧小霸王网页游戏机源码增强版👈
👉js+css类似网页版网易音乐源码👈
👉Java物业管理系统+小程序源码👈
👉JavaWeb家居电子商城👈
👉JAVA酒店客房预定管理系统的设计与实现SQLserver👈
👉JAVA图书管理系统的研究与开发mysql👈
✨有关Java、数据库教程与项目实战欢迎各位查看个人主页✨
🌟分享Python知识讲解、分享🌟
学习Python不再是难问题
🥝《Python知识、项目专栏》🥝
🥝《Python 检测抖音关注账号是否封号程》🥝
🥝《手把手教你Python+Qt5安装与使用》🥝
🥝《用一万字给小白全面讲解python编程基础问答》🥝
🥝《Python 绘制android CPU和内存增长曲线》🥝
🥝《☀️苏州程序大白用万字解析Python网络编程与Web编程☀️《❤️记得收藏❤️》》🥝
有关Python项目实战
👉Python基于Django图书管理系统👈
👉Python管理系统👈
👉2021年9个常用的python爬虫源码👈
👉python二维码生成器👈
✨有关Python教程与项目实战欢迎各位查看个人主页✨
🌟分享各大公司面试题、面试流程🌟 以上是关于使用线程安全型双向链表实现简单 LRU Cache 模拟的主要内容,如果未能解决你的问题,请参考以下文章