client,server,nginx 在使用keepAlive里要保持一致,否则起不到效果
Posted 沧海一滴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了client,server,nginx 在使用keepAlive里要保持一致,否则起不到效果相关的知识,希望对你有一定的参考价值。
2. TCP keepalive overview
In order to understand what TCP keepalive (which we will just call keepalive) does, you need do nothing more than read the name: keep TCP alive. This means that you will be able to check your connected socket (also known as TCP sockets), and determine whether the connection is still up and running or if it has broken.
2.1. What is TCP keepalive?
The keepalive concept is very simple: when you set up a TCP connection, you associate a set of timers. Some of these timers deal with the keepalive procedure. When the keepalive timer reaches zero, you send your peer a keepalive probe packet with no data in it and the ACK flag turned on. You can do this because of the TCP/IP specifications, as a sort of duplicate ACK, and the remote endpoint will have no arguments, as TCP is a stream-oriented protocol. On the other hand, you will receive a reply from the remote host (which doesn\'t need to support keepalive at all, just TCP/IP), with no data and the ACK set.
If you receive a reply to your keepalive probe, you can assert that the connection is still up and running without worrying about the user-level implementation. In fact, TCP permits you to handle a stream, not packets, and so a zero-length data packet is not dangerous for the user program.
This procedure is useful because if the other peers lose their connection (for example by rebooting) you will notice that the connection is broken, even if you don\'t have traffic on it. If the keepalive probes are not replied to by your peer, you can assert that the connection cannot be considered valid and then take the correct action.
2.2. Why use TCP keepalive?
You can live quite happily without keepalive, so if you\'re reading this, you may be trying to understand if keepalive is a possible solution for your problems. Either that or you\'ve really got nothing more interesting to do instead, and that\'s okay too. :)
Keepalive is non-invasive, and in most cases, if you\'re in doubt, you can turn it on without the risk of doing something wrong. But do remember that it generates extra network traffic, which can have an impact on routers and firewalls.
In short, use your brain and be careful.
In the next section we will distinguish between the two target tasks for keepalive:
-
Checking for dead peers
-
Preventing disconnection due to network inactivity
2.3. Checking for dead peers
Keepalive can be used to advise you when your peer dies before it is able to notify you. This could happen for several reasons, like kernel panic or a brutal termination of the process handling that peer. Another scenario that illustrates when you need keepalive to detect peer death is when the peer is still alive but the network channel between it and you has gone down. In this scenario, if the network doesn\'t become operational again, you have the equivalent of peer death. This is one of those situations where normal TCP operations aren\'t useful to check the connection status.
Think of a simple TCP connection between Peer A and Peer B: there is the initial three-way handshake, with one SYN segment from A to B, the SYN/ACK back from B to A, and the final ACK from A to B. At this time, we\'re in a stable status: connection is established, and now we would normally wait for someone to send data over the channel. And here comes the problem: unplug the power supply from B and instantaneously it will go down, without sending anything over the network to notify A that the connection is going to be broken. A, from its side, is ready to receive data, and has no idea that B has crashed. Now restore the power supply to B and wait for the system to restart. A and B are now back again, but while A knows about a connection still active with B, B has no idea. The situation resolves itself when A tries to send data to B over the dead connection, and B replies with an RST packet, causing A to finally to close the connection.
Keepalive can tell you when another peer becomes unreachable without the risk of false-positives. In fact, if the problem is in the network between two peers, the keepalive action is to wait some time and then retry, sending the keepalive packet before marking the connection as broken.
_____ _____
| | | |
| A | | B |
|_____| |_____|
^ ^
|--->--->--->-------------- SYN -------------->--->--->---|
|---<---<---<------------ SYN/ACK ------------<---<---<---|
|--->--->--->-------------- ACK -------------->--->--->---|
| |
| system crash ---> X
|
| system restart ---> ^
| |
|--->--->--->-------------- PSH -------------->--->--->---|
|---<---<---<-------------- RST --------------<---<---<---|
| |
|
2.4. Preventing disconnection due to network inactivity
The other useful goal of keepalive is to prevent inactivity from disconnecting the channel. It\'s a very common issue, when you are behind a NAT proxy or a firewall, to be disconnected without a reason. This behavior is caused by the connection tracking procedures implemented in proxies and firewalls, which keep track of all connections that pass through them. Because of the physical limits of these machines, they can only keep a finite number of connections in their memory. The most common and logical policy is to keep newest connections and to discard old and inactive connections first.
Returning to Peers A and B, reconnect them. Once the channel is open, wait until an event occurs and then communicate this to the other peer. What if the event verifies after a long period of time? Our connection has its scope, but it\'s unknown to the proxy. So when we finally send data, the proxy isn\'t able to correctly handle it, and the connection breaks up.
Because the normal implementation puts the connection at the top of the list when one of its packets arrives and selects the last connection in the queue when it needs to eliminate an entry, periodically sending packets over the network is a good way to always be in a polar position with a minor risk of deletion.
_____ _____ _____
| | | | | |
| A | | NAT | | B |
|_____| |_____| |_____|
^ ^ ^
|--->--->--->---|----------- SYN ------------->--->--->---|
|---<---<---<---|--------- SYN/ACK -----------<---<---<---|
|--->--->--->---|----------- ACK ------------->--->--->---|
| | |
| | <--- connection deleted from table |
| | |
|--->- PSH ->---| <--- invalid connection |
| | |
|
3. Using TCP keepalive under Linux
Linux has built-in support for keepalive. You need to enable TCP/IP networking in order to use it. You also need procfs support and sysctl support to be able to configure the kernel parameters at runtime.
The procedures involving keepalive use three user-driven variables:
- tcp_keepalive_time
-
the interval between the last data packet sent (simple ACKs are not considered data) and the first keepalive probe; after the connection is marked to need keepalive, this counter is not used any further
- tcp_keepalive_intvl
-
the interval between subsequential keepalive probes, regardless of what the connection has exchanged in the meantime
- tcp_keepalive_probes
-
the number of unacknowledged probes to send before considering the connection dead and notifying the application layer
Remember that keepalive support, even if configured in the kernel, is not the default behavior in Linux. Programs must request keepalive control for their sockets using the setsockopt interface. There are relatively few programs implementing keepalive, but you can easily add keepalive support for most of them following the instructions explained later in this document.
http://www.tldp.org/HOWTO/html_single/TCP-Keepalive-HOWTO/
keepalive不是说TCP的常连接,当我们作为服务端,一个客户端连接上来,如果设置了keeplive为true,当对方没有发送任何数据过来,超过一个时间(看系统内核参数配置),那么我们这边会发送一个ack探测包发到对方,探测双方的TCP/IP连接是否有效(对方可能断点,断网)。如果不设置,那么客户端宕机时,服务器永远也不知道客户端宕机了,仍然保存这个失效的连接。
当然,在客户端也可以使用这个参数。客户端Socket会每隔段的时间(大约两个小时)就会利用空闲的连接向服务器发送一个数据包。这个数据包并没有其它的作用,只是为了检测一下服务器是否仍处于活动状态。如果服务器未响应这个数据包,在大约11分钟后,客户端Socket再发送一个数据包,如果在12分钟内,服务器还没响应,那么客户端Socket将关闭。如果将Socket选项关闭,客户端Socket在服务器无效的情况下可能会长时间不会关闭。
尽管keepalive的好处并不多,但是很多开发者提倡在更高层次的应用程序代码中控制超时设置和死的套接字。同时需要记住,keepalive不允许你为探测套接字终点(endpoint)指定一个值。所以建议开发者使用的另一种比keepalive更好的解决方案是修改超时设置套接字选项。
说白了:这个参数其实对应用层的程序而言没有什么用。可以通过应用层实现了解服务端或客户端状态,而决定是否继续维持该Socket。
很多应用层协议都有HeartBeat机制,通常是客户端每隔一小段时间向服务器发送一个数据包,通知服务器自己仍然在线,并传输一些可能必要的数据。使用心跳包的典型协议是IM,比如QQ/MSN/飞信等协议。
学过TCP/IP的同学应该都知道,传输层的两个主要协议是UDP和TCP,其中UDP是无连接的、面向packet的,而TCP协议是有连接、面向流的协议。
所以非常容易理解,使用UDP协议的客户端(例如早期的“OICQ”,听说OICQ.com这两天被抢注了来着,好古老的回忆)需要定时向服务器发送心跳包,告诉服务器自己在线。
然而,MSN和现在的QQ往往使用的是TCP连接了,尽管TCP/IP底层提供了可选的KeepAlive(ACK-ACK包)机制,但是它们也还是实现了更高层的心跳包。似乎既浪费流量又浪费CPU,有点莫名其妙。
具体查了下,TCP的KeepAlive机制是这样的,首先它貌似默认是不打开的,要用setsockopt将SOL_SOCKET.SO_KEEPALIVE设置为1才是打开,并且可以设置三个参数tcp_keepalive_time/tcp_keepalive_probes/tcp_keepalive_intvl,分别表示连接闲置多久开始发keepalive的ack包、发几个ack包不回复才当对方死了、两个ack包之间间隔多长,在我测试的Ubuntu Server 10.04下面默认值是7200秒(2个小时,要不要这么蛋疼啊!)、9次、75秒。于是连接就了有一个超时时间窗口,如果连接之间没有通信,这个时间窗口会逐渐减小,当它减小到零的时候,TCP协议会向对方发一个带有ACK标志的空数据包(KeepAlive探针),对方在收到ACK包以后,如果连接一切正常,应该回复一个ACK;如果连接出现错误了(例如对方重启了,连接状态丢失),则应当回复一个RST;如果对方没有回复,服务器每隔intvl的时间再发ACK,如果连续probes个包都被无视了,说明连接被断开了。
这里有一篇非常详细的介绍文章: http://tldp.org/HOWTO/html_single/TCP-Keepalive-HOWTO ,包括了KeepAlive的介绍、相关内核参数、C编程接口、如何为现有应用(可以或者不可以修改源码的)启用KeepAlive机制,很值得详读。
这篇文章的2.4节说的是“Preventing disconnection due to network inactivity”,阻止因网络连接不活跃(长时间没有数据包)而导致的连接中断,说的是,很多网络设备,尤其是NAT路由器,由于其硬件的限制(例如内存、CPU处理能力),无法保持其上的所有连接,因此在必要的时候,会在连接池中选择一些不活跃的连接踢掉。典型做法是LRU,把最久没有数据的连接给T掉。通过使用TCP的KeepAlive机制(修改那个time参数),可以让连接每隔一小段时间就产生一些ack包,以降低被T掉的风险,当然,这样的代价是额外的网络和CPU负担。
前面说到,许多IM协议实现了自己的心跳机制,而不是直接依赖于底层的机制,不知道真正的原因是什么。
就我看来,一些简单的协议,直接使用底层机制就可以了,对上层完全透明,降低了开发难度,不用管理连接对应的状态。而那些自己实现心跳机制的协议,应该是期望通过发送心跳包的同时来传输一些数据,这样服务端可以获知更多的状态。例如某些客户端很喜欢收集用户的信息……反正是要发个包,不如再塞点数据,否则包头又浪费了……
https://www.felix021.com/blog/read.php?2076
为什么要有KeepAlive?
在谈KeepAlive之前,我们先来了解下简单TCP知识(知识很简单,高手直接忽略)。首先要明确的是在TCP层是没有“请求”一说的,经常听到在TCP层发送一个请求,这种说法是错误的。
TCP是一种通信的方式,“请求”一词是事务上的概念,HTTP协议是一种事务协议,如果说发送一个HTTP请求,这种说法就没有问题。也经常听到面试官反馈有些面试运维的同学,基本的TCP三次握手的概念不清楚,面试官问TCP是如何建立链接,面试者上来就说,假如我是客户端我发送一个请求给服务端,服务端发送一个请求给我。。。
TCP层是没有请求的概念,HTTP协议是事务性协议才有请求的概念,TCP报文承载HTTP协议的请求(Request)和响应(Response)。
现在才是开始说明为什么要有KeepAlive。链接建立之后,如果应用程序或者上层协议一直不发送数据,或者隔很长时间才发送一次数据,当链接很久没有数据报文传输时如何去确定对方还在线,到底是掉线了还是确实没有数据传输,链接还需不需要保持,这种情况在TCP协议设计中是需要考虑到的。
TCP协议通过一种巧妙的方式去解决这个问题,当超过一段时间之后,TCP自动发送一个数据为空的报文给对方,如果对方回应了这个报文,说明对方还在线,链接可以继续保持,如果对方没有报文返回,并且重试了多次之后则认为链接丢失,没有必要保持链接。
如何开启KeepAlive?
KeepAlive并不是默认开启的,在Linux系统上没有一个全局的选项去开启TCP的KeepAlive。需要开启KeepAlive的应用必须在TCP的socket中单独开启。Linux Kernel有三个选项影响到KeepAlive的行为:
1.net.ipv4.tcpkeepaliveintvl = 75
2.net.ipv4.tcpkeepaliveprobes = 9
3.net.ipv4.tcpkeepalivetime = 7200
tcpkeepalivetime的单位是秒,表示TCP链接在多少秒之后没有数据报文传输启动探测报文; tcpkeepaliveintvl单位是也秒,表示前一个探测报文和后一个探测报文之间的时间间隔,tcpkeepaliveprobes表示探测的次数。
TCP socket也有三个选项和内核对应,通过setsockopt系统调用针对单独的socket进行设置:
TCPKEEPCNT: 覆盖 tcpkeepaliveprobes
TCPKEEPIDLE: 覆盖 tcpkeepalivetime
TCPKEEPINTVL: 覆盖 tcpkeepalive_intvl
举个例子,以我的系统默认设置为例,kernel默认设置的tcpkeepalivetime是7200s, 如果我在应用程序中针对socket开启了KeepAlive,然后设置的TCP_KEEPIDLE为60,那么TCP协议栈在发现TCP链接空闲了60s没有数据传输的时候就会发送第一个探测报文。
TCP KeepAlive和HTTP的Keep-Alive是一样的吗?
估计很多人乍看下这个问题才发现其实经常说的KeepAlive不是这么回事,实际上在没有特指是TCP还是HTTP层的KeepAlive,不能混为一谈。TCP的KeepAlive和HTTP的Keep-Alive是完全不同的概念。
TCP层的KeepAlive上面已经解释过了。 HTTP层的Keep-Alive是什么概念呢? 在讲述TCP链接建立的时候,我画了一张三次握手的示意图,TCP在建立链接之后, HTTP协议使用TCP传输HTTP协议的请求(Request)和响应(Response)数据,一次完整的HTTP事务如下图: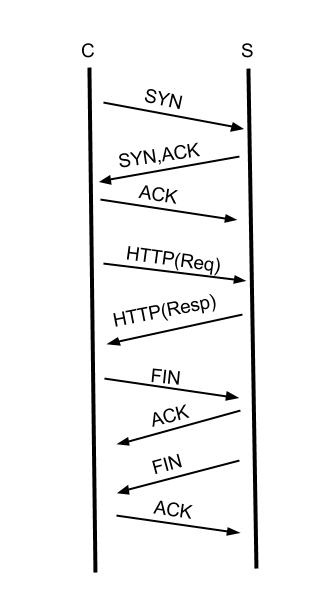
这张图我简化了HTTP(Req)和HTTP(Resp),实际上的请求和响应需要多个TCP报文。
从图中可以发现一个完整的HTTP事务,有链接的建立,请求的发送,响应接收,断开链接这四个过程,早期通过HTTP协议传输的数据以文本为主,一个请求可能就把所有要返回的数据取到,但是,现在要展现一张完整的页面需要很多个请求才能完成,如图片,JS,CSS等,如果每一个HTTP请求都需要新建并断开一个TCP,这个开销是完全没有必要的。
开启HTTP Keep-Alive之后,能复用已有的TCP链接,当前一个请求已经响应完毕,服务器端没有立即关闭TCP链接,而是等待一段时间接收浏览器端可能发送过来的第二个请求,通常浏览器在第一个请求返回之后会立即发送第二个请求,如果某一时刻只能有一个链接,同一个TCP链接处理的请求越多,开启KeepAlive能节省的TCP建立和关闭的消耗就越多。
当然通常会启用多个链接去从服务器器上请求资源,但是开启了Keep-Alive之后,仍然能加快资源的加载速度。HTTP/1.1之后默认开启Keep-Alive, 在HTTP的头域中增加Connection选项。当设置为Connection:keep-alive表示开启,设置为Connection:close表示关闭。实际上HTTP的KeepAlive写法是Keep-Alive,跟TCP的KeepAlive写法上也有不同。所以TCP KeepAlive和HTTP的Keep-Alive不是同一回事情。
nginx的TCP KeepAlive如何设置?
开篇提到我最近遇到的问题,Client发送一个请求到Nginx服务端,服务端需要经过一段时间的计算才会返回, 时间超过了LVS Session保持的90s,在服务端使用Tcpdump抓包,本地通过wireshark分析显示的结果如第二副图所示,第5条报文和最后一条报文之间的时间戳大概差了90s。
在确定是LVS的Session保持时间到期的问题之后,我开始在寻找Nginx的TCP KeepAlive如何设置,最先找到的选项是keepalivetimeout,从同事那里得知keepalivetimeout的用法是当keepalivetimeout的值为0时表示关闭keepalive,当keepalivetimeout的值为一个正整数值时表示链接保持多少秒,于是把keepalivetimeout设置成75s,但是实际的测试结果表明并不生效。
显然keepalivetimeout不能解决TCP层面的KeepAlive问题,实际上Nginx涉及到keepalive的选项还不少,Nginx通常的使用方式如下: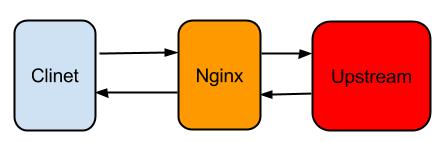
从TCP层面Nginx不仅要和Client关心KeepAlive,而且还要和Upstream关心KeepAlive, 同时从HTTP协议层面,Nginx需要和Client关心Keep-Alive,如果Upstream使用的HTTP协议,还要关心和Upstream的Keep-Alive,总而言之,还比较复杂。
所以搞清楚TCP层的KeepAlive和HTTP的Keep-Alive之后,就不会对于Nginx的KeepAlive设置错。我当时解决这个问题时候不确定Nginx有配置TCP keepAlive的选项,于是我打开Ngnix的源代码,
在源代码里面搜索TCP_KEEPIDLE,相关的代码如下:
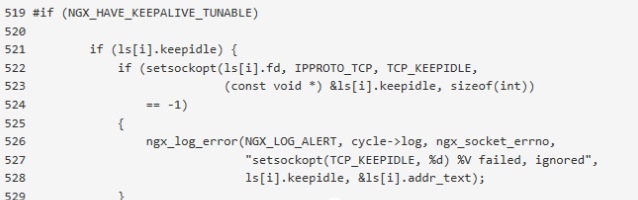
从代码的上下文我发现TCP KeepAlive可以配置,所以我接着查找通过哪个选项配置,最后发现listen指令的so_keepalive选项能对TCP socket进行KeepAlive的配置。

http://www.bubuko.com/infodetail-260176.html
KeepAlive,这次看下Nginx加Tomcat做反向代理这种典型场景下的KeepAlive配置与否的影响。以下图中的数据只能做个定性的参考,具体要根据实际业务测试。
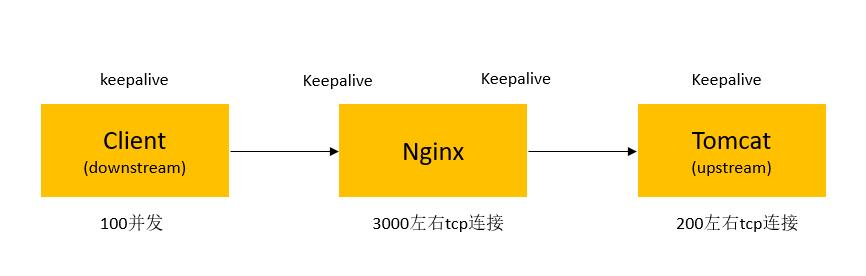
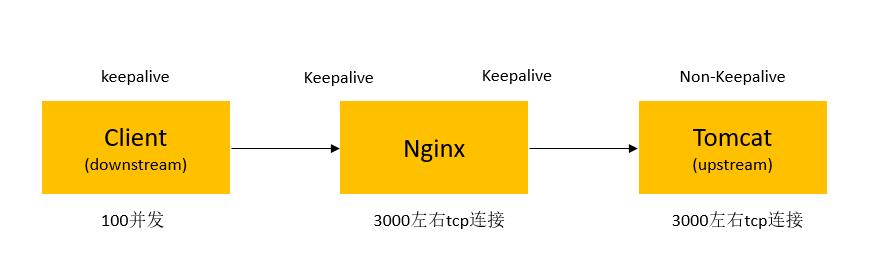

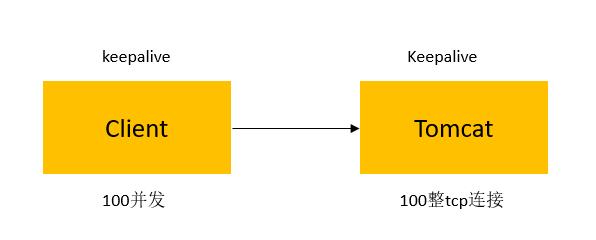
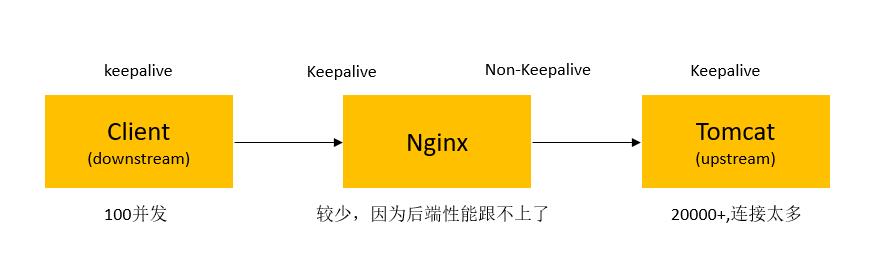

- 显然keepalive需要client和sever同时支持才生效;
- 未使用keepalive(无论是客户端还是服务端不支持),服务端会主动关闭TCP连接,存在大量的TIME_WAI;
- 是否使用keepalive比较复杂,并不是单纯的一个http头决定的;
- Nginx似乎跟upstream之间维持着一个长连接池,所以很少会看到TIME_WAIT,都处于ESTABLISHED状态。
Nginx有关KeepAlive的配置有两处:
一处是http节点下的keepalive_timeout,这个设置的是跟client(图中downstream)的连接超时时间;还有一处是upstream中配置的keepalive,注意这个单位是数量不是时间。
以上是关于client,server,nginx 在使用keepAlive里要保持一致,否则起不到效果的主要内容,如果未能解决你的问题,请参考以下文章
使用openid_client通过带有keycloak的pkce颤振应用程序进行身份验证后如何获取刷新令牌?
Android跨进程通信Client Crash后Server端onDestroy
Android跨进程通信Client Crash后Server端onDestroy