多渠道归因分析(Attribution):用attention-RNN来做归因建模(附代码demo)
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多渠道归因分析(Attribution):用attention-RNN来做归因建模(附代码demo)相关的知识,希望对你有一定的参考价值。
之前几篇多渠道归因分析应该算是比较通用的一些方法论:
- 多渠道归因分析(Attribution):传统归因(一)
- 多渠道归因分析:互联网的归因江湖(二)
- 多渠道归因分析:python实现马尔可夫链归因(三)
- 多渠道归因分析(Attribution):python实现Shapley Value(四)
- 多渠道归因分析(Attribution):用attention-RNN来做归因建模(附代码demo)(五)
之前在查阅资料的时候,有看到一篇更进阶的,用深度学习来解决问题,
论文可参考18年的一篇:
Deep Neural Net with Attention for Multi-channel Multi-touch Attribution
我们来看这篇以及品鉴一下关联代码:
官方:channel-attribution-model
我把可以跑通demo代码放在自己的github之中:mattzheng/Attention-RNN-Multi-Touch-Attribution
1 基于注意力的循环神经网络多点触摸归因模型

假设有 如下7-13个 触点的路径:
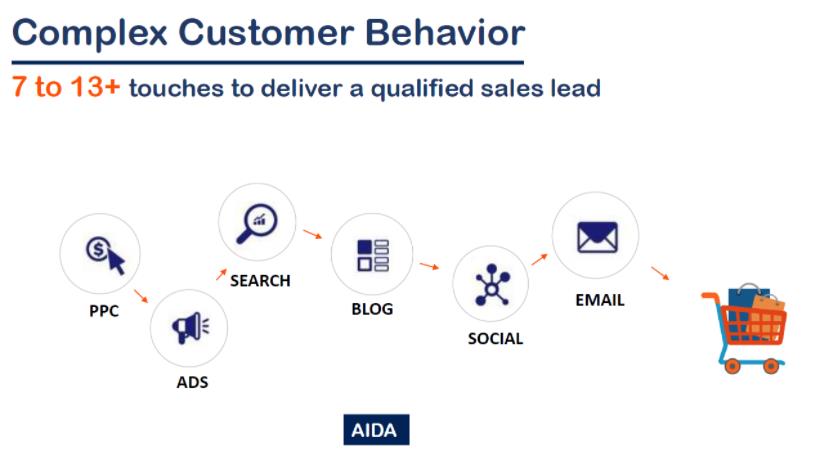
1.1 与markov、Sharpley 的差异
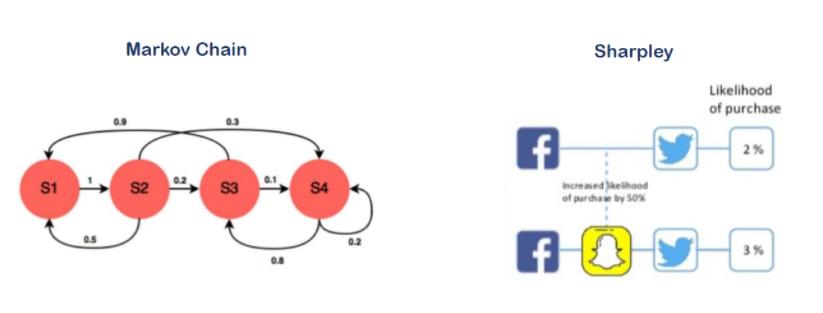
markov、Sharpley 是市面上最、最常见的两种归因分析的方法了,但是两种都缺少考虑:
- 长路径序列下路径间的影响(markov考虑了顺序)
- 未融入用户属性信息

1.2 注意力的循环神经网络多点触摸归因模型框架
一种基于注意力的循环神经网络多点触摸归因模型,以监督学习的方式预测一系列事件是否导致转换(购买)。
模型可以输出不同节点的重要性(LSTM的),同时还结合了非常关键的信息,将用户背景信息(如用户人口统计和行为)作为控制变量,以减少媒体效应的估计偏差。
来说明几个特色:
- LSTM 来捕捉长路径模式
- RNN with Attention 将时间衰减作为attention加入
- customer profile — embedding layer + ANN:额外融入用户属性信息
- 还可以输出每个触点的重要性(即LSTM的节点)
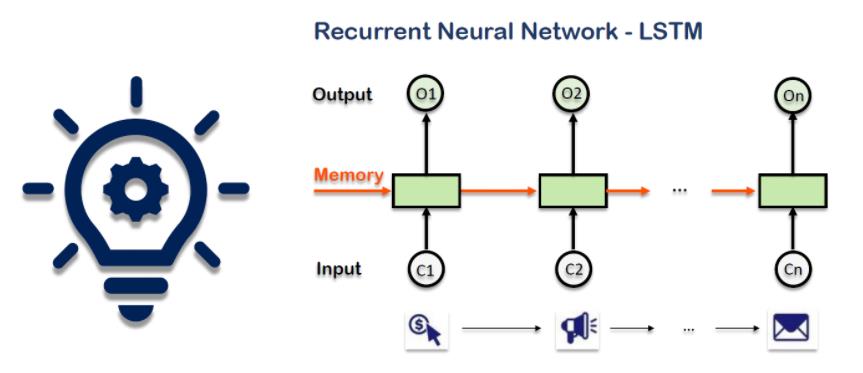
用LSTM来解读路径周期,将路径作为input输入LSTM之中
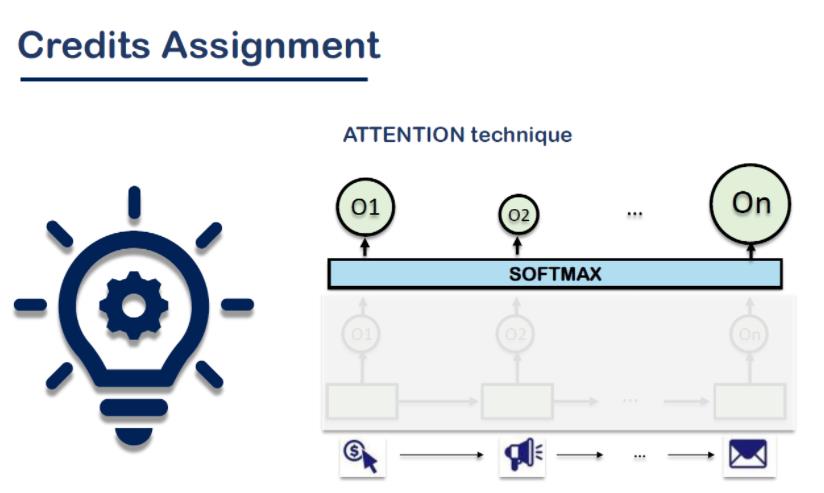
将时间衰减作为attention加入

整个架构图:
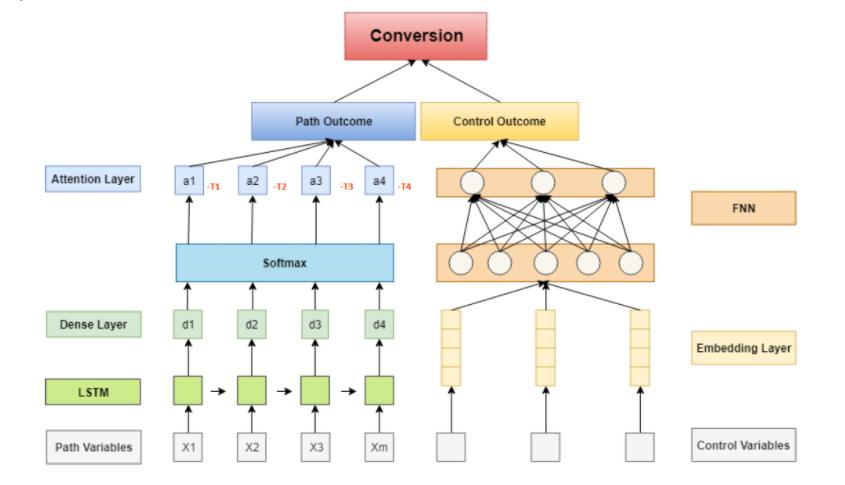
左边是路径模块,右边是用户属性模块,
- 路径模块带有attenion(时间衰减)
- 用户模块,属性embedding之后输出
最后两者add()在一起做输出。
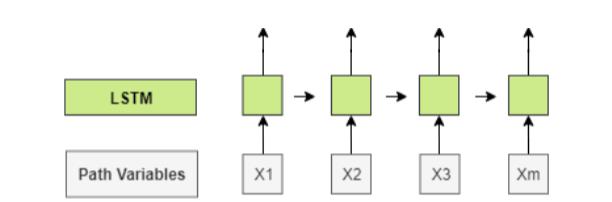
1.3 LSTM 来捕捉长路径模式
路径变量作为输入数据被发送到LSTM层,并获得每个路径变量的输出。LSTM体系结构能够捕获通道数据的顺序模式。
1.4 RNN with Attention 将时间衰减作为attention加入
这个环节是节点模块的比较有意思的模块:
The time-lapse data are scaled and will be used in the revised softmax function in Attention layer.
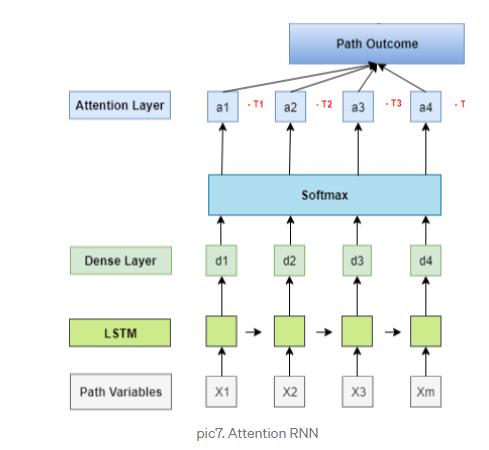
在机器翻译上下文中,重复这一步,得到长度等于翻译单词数的输出向量上下文,然后将这些输出再次发送到另一个LSTM中,得到最终的翻译结果。但在本例中,我们只需要从注意力输出一个结果。
值得注意的是,由于时间衰减元素在客户路径中起着作用,我们将修改softmax函数来考虑这个因素。
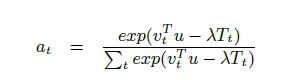
源码中为,参考FFDNA.py :
input_att = Input(shape=(self.Tx, self.vocab_size), name='input_path')
s0 = Input(shape=(self.n_s,), name='s0')
s = s0
# input time decay data
t0 = Input(shape=(self.Tx,1), name='input_timeDecay')
t = t0
# Step 1: Define pre-attention LSTM.
a = LSTM(self.n_a,return_sequences=True)(input_att)
# Step 2: import attention model
context = self.one_step_attention(a,s,t)
c = Flatten()(context)
out_att = Dense(32, activation = "sigmoid", name='single_output')(c)
这里主要是路径模块,完全可以当做文本来看待,这里有三个需要输入的:
input_att,第一个输入,主要记录路径的,其中self.vocab_size一般是总词量 +1,这边就是所有路径节点数+ 1(5个);self.Tx代表文字的padding 长度,这里是20,之后 -> 进入到LSTM -> attention层s0 = Input(shape=(self.n_s,), name='s0'),初始化decoder LSTM隐藏层 -> attenion层t0 = Input(shape=(self.Tx,1), name='input_timeDecay')时间维度因素 -> attention层
然后简单来看一下attention层,上面的三个输入如何计算:
def one_step_attention(self, a, s_prev,t0):
repeator = RepeatVector(Tx)
concatenator = Concatenate(axis=-1)
densor1 = Dense(10, activation = "tanh")
densor2 = Dense(1, activation = "relu")
activator = Activation(self.softmax, name='attention_weights') # We are using a custom softmax(axis = 1) loaded in this notebook
dotor = Dot(axes = 1)
# Use repeator to repeat s_prev to be of shape (m, Tx, n_s) so that you can concatenate it with all hidden states "a".
s_prev = repeator(s_prev)
# Use concatenator to concatenate a and s_prev on the last axis
concat = concatenator([s_prev,a])
# Use densor1 to propagate concat through a small fully-connected neural network to compute the "intermediate energies" variable e.
e = densor1(concat)
# Use densor2 to propagate e through a small fully-connected neural network to compute the "energies" variable energies.
energies = densor2(e)
# Use "activator" on "energies" to compute the attention weights "alphas"
energies = Subtract(name='data-time')([energies,t0])
alphas = activator(energies)
# Use dotor together with "alphas" and "a" to compute the context vector to be given to the next layer
context = dotor([alphas,a])
return context
大概是先计算attention weights:
将三个Input,concatenator([s_prev,a]),然后求差Subtract(name='data-time')([energies,t0]),进入activator激活层中特别的softmax,计算attention weights
然后将attention weights 点积 路径的lstm隐含层,得到输出项
这里的attention weights就是非常关键的每个节点的权重了
1.5 customer profile — embedding layer + ANN:额外融入用户属性信息
一个简单的全连接神经网络来处理客户数据。这部分非常简单,只有几个密集的层。
之前用户编码会用one-hot encoding,这里使用的是embedding layer自训练。
嵌入层 Embedding:将正整数(索引值)转换为固定尺寸的稠密向量。
例如: [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
来看一个keras官方的例子[Embedding]:
model = Sequential()
model.add(Embedding(1000, 64, input_length=10))
# 模型将输入一个大小为 (batch, input_length) 的整数矩阵。
# 输入中最大的整数(即词索引)不应该大于 999 (词汇表大小)
# 现在 model.output_shape == (None, 10, 64),其中 None 是 batch 的维度。
input_array = np.random.randint(1000, size=(32, 10))
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64)
来看一下开源的代码,整个用户属性模块的embedding张这样,参考FFDNA.py :
def build_embedding_network(self, no_of_unique_cat=83, output_shape=32):
inputss = []
embeddings = []
for c in self.categorical_vars:
inputs = Input(shape=(1,),name='input_sparse_'+c)
#no_of_unique_cat = data_lr[categorical_var].nunique()
embedding_size = min(np.ceil((no_of_unique_cat)/2), 50 )
embedding_size = int(embedding_size)
embedding = Embedding(no_of_unique_cat+1, embedding_size, input_length = 1)(inputs)
embedding = Reshape(target_shape=(embedding_size,))(embedding)
inputss.append(inputs)
embeddings.append(embedding)
input_numeric = Input(shape=(1,),name='input_constinuous')
embedding_numeric = Dense(16)(input_numeric)
inputss.append(input_numeric)
embeddings.append(embedding_numeric)
x = Concatenate()(embeddings)
x = Dense(10, activation = 'relu')(x)
x = Dropout(.15)(x)
out_control = Dense(output_shape)(x)
return inputss,out_control
这里每个用户属性categorical_vars,都会进行一次Embedding,然后之后拼接在一起Concatenate()(embeddings),进入一个dense(10)全连接层。
该模块的输入:inputss,需要同时给入三个属性变量,
输出:out_control 32维的全连接输出
1.6 融合层
路径模块和客户属性模块,输出到另一个dense层,然后由sigmoid激活函数到最终,0/1分类
out_att = Dense(32, activation = "sigmoid", name='single_output')(c)
# Step 3: import embedding data for customer-ralated variables
input_con,out_control = self.build_embedding_network()
added = Add()([out_att, out_control])
github中的代码两个输出直接相加add(),不是conatenate()

作者自己的测试结果:
- RNN-attenion模型,96% accuracy 和0.98 AUC
- markov模型,0.86 AUC
2 下游应用
2.1 下游应用一:分配路径权重
我将使用性能最好的模型来计算分配给每个通道的权值。基本上,对于每一个送入模型的观测数据,如果输出概率大于0.5(这意味着该观测将被归类为转换),我会从Attention层提取权值,并将其累加到相应的通道。
在得到每个渠道的权重后,我们将使用下面的公式来分配营销预算。

2.2 下游应用二:预算评估
哪些营销渠道在推动转化率和销售额,意味着你可以更好地将营销资金分配到最有效的渠道上,并更好地跟踪潜在客户的互动
如果你有一定预算,你会如何分配;当你通过模型得出不同路径的权重,就可以根据权重来分配。
当然这种方式比较简单,详细可见我之前贴的俩论文:
预算分配Budget Allocation:两篇论文(二)
2.3 确定最有影响力的路径
根据每个客户路径的转换概率排名,我列出了最具影响力的N条路径。
代码如下:
def critical_paths(self):
prob = self.model.predict([self.X_tr,self.s0,self.time_decay_tr,self.X_tr_lr.iloc[:,0],self.X_tr_lr.iloc[:,1],
self.X_tr_lr.iloc[:,2],self.X_tr_lr.iloc[:,3]])
cp_idx = sorted(range(len(prob)), key=lambda k: prob[k], reverse=True)
#print([prob[p] for p in cp_idx[0:100]])
cp_p = [self.paths[p] for p in cp_idx[0:100]]
cp_p_2 = set(map(tuple, cp_p))
print(list(map(list,cp_p_2)))
3 案例代码demo解读
笔者测试的时候的tf 、 keras版本号:
tf.__version__,keras.__version__
Out[7]: ('1.14.0', '2.2.4')
3.1 数据样式
在文章How to implement an Attention-RNN model into solving a marketing problem: Multi-Channel Attribution中没有放出数据,所以笔者自己造了按博文自己造了几条,代码可见:mattzheng/Attention-RNN-Multi-Touch-Attribution
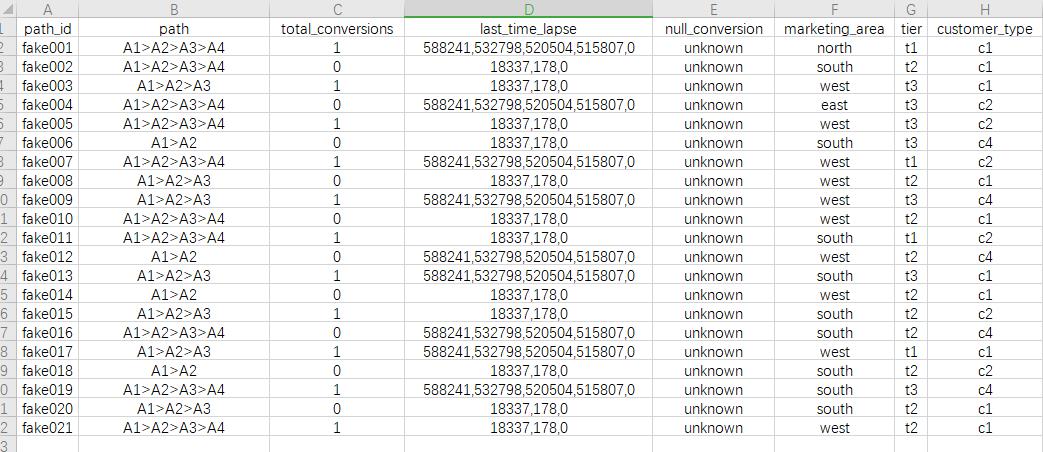
- total_conv就是最后是否转化
- last_time_lapse,节点访问时间经过,放入的是路径模块,作为attention模块,不过这个样式我自己造的时候也有点不确定,是否每个节点对应,可以自由灵活调配
- marketing_area 、 tier 、 customer_type都是用户属性类型,这里自由发挥,可以很多
这里在process_data.py中经过预处理之后:
data_all = process_data(data,seq_length = seq_length)
需要输出的内容:
- time_decay_tr, 训练集时间
- time_decay_te,测试集时间
- X_tr, 用户路径模块 -训练集X
- X_te,用户路径模块 - 测试集X
- X_tr_lr,用户属性模块-训练集X
- X_te_lr,用户属性模块-测试集X
- Y_train,
- Y_test,
- all_X, 所有x
- time_decay,所有时间
- newlines.shape,17*20,pad_sequence
- y ,所有y
- categorical_vars,用户属性模块 哪些字段
- paths , 所有路径
3.2 训练与预测
def train_model(self,save_name, loss='binary_crossentropy',opt='adam',metrics=['accuracy']):
self.model.compile(loss=loss,optimizer=opt,metrics=metrics)
self.history = self.model.fit([self.X_tr,self.s0,self.time_decay_tr,self.X_tr_lr.iloc[:,0],self.X_tr_lr.iloc[:,1],
self.X_tr_lr.iloc[:,2],self.X_tr_lr.iloc[:,3]
], self.Y_train, epochs=self.epochs, batch_size=self.batch_size,verbose=2)
self.save_weight(save_name,self.model)
从model.fit来看,这里需要Input的内容非常多;而且,这里的用户属性self.X_tr_lr.iloc[:,1],self.X_tr_lr.iloc[:,2],self.X_tr_lr.iloc[:,3]为什么分为三个?
因为用户属性每个属性特征都需要独立embedding
3.3 确定最优影响力的路径
其实这里就是一个预测,所有数据集中,因为本次训练target是购买率0/1,所以最高购买率的就是有影响力的。
prob = ana_mta_model.model.predict([ana_mta_model.X_tr,ana_mta_model.s0,ana_mta_model.time_decay_tr,\\
ana_mta_model.X_tr_lr.iloc[:,0],\\
ana_mta_model.X_tr_lr.iloc[:,1],
ana_mta_model.X_tr_lr.iloc[:,2],ana_mta_model.X_tr_lr.iloc[:,3]])
# 训练集预测 - 找到预测概率比较高的路径
cp_idx = sorted(range(len(prob)), key=lambda k: prob[k], reverse=True)
#print([prob[p] for p in cp_idx[0:100]])
cp_p = [ana_mta_model.paths[p] for p in cp_idx[0:100]]
cp_p_2 = set(map(tuple, cp_p))
print(list(map(list,cp_p_2)))
是在原函数的critical_paths之中
3.4 确定attention weight
确定每个节点的权重
layer = ana_mta_model.model.layers[20]
m_all,_,_ = ana_mta_model.all_X.shape # 训练集
ana_mta_model.s_all = np.zeros((m_all, ana_mta_model.n_s))
f_f = K.function([ana_mta_model.model.input[0],ana_mta_model.model.input[1],ana_mta_model.model.input[2]], [layer.output])
r=f_f([ana_mta_model.all_X[ana_mta_model.y==1],ana_mta_model.s_all[ana_mta_model.y==1],ana_mta_model.time_decay[ana_mta_model.y==1]])[0].reshape(ana_mta_model.all_X[ana_mta_model.y==1].shape[0],ana_mta_model.all_X[ana_mta_model.y==1].shape[1])
# att_f = {m:0 for m in range(1,6)}
# att_count_f = {m:0 for m in range(1,6)}
att_f = {m:0 for m in range(1,n_channels+1)}
att_count_f = {m:0 for m in range(1,n_channels+1)}
chan_used = ana_mta_model.newlines[ana_mta_model.y==1]
for m in range(chan_used.shape[0]):
for n in range(chan_used.shape[1]):
if chan_used[m,n]!=0:
att_f[chan_used[m,n]] += r[m,n]
att_count_f[chan_used[m,n]] += 1
for n in range(n_channels):
att_f[channels[n]] = att_f.pop(n+1)
在原函数的attributes,因为我是自己造的数据,channel不一样,所以需要自己改造一下这个函数。
就可以得到每个节点的权重。
4 后续YY
确定购买潜力以及其他更多的变形
如果有顾客点击了很多路径内容还没转化,可以通过模型得到他购买的可能性。
例如,如果你的公司也关心每个渠道其他转化情况(如电子邮件活动中的广告的点击率),你将在LSTM之上添加更多的层来实现这一点,如下图所示。
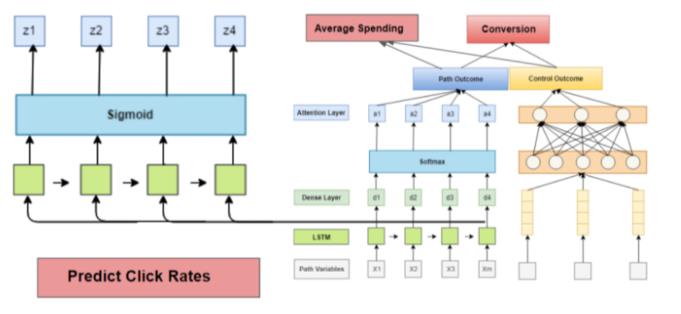
此外,您还可以预测一次购买的平均支出或金额,这可能会使分配权重更准确,也可以提供您关于调整供应链的信息。可以参考上文的输出接入:average spending
沿着这个一直再设想一下,一切NLP的模型都可以使用上;
比如利用预训练模型,后续可以接上非常多的应用,包括预测用户下一个点击页面是什么(NSP)
总之,这块应该还有非常多空间可以思考与继续深究
参考文献
How to implement an Attention-RNN model into solving a marketing problem: Multi-Channel Attribution
Attention-RNN Channel-Attribution Model
jeremite/channel-attribution-model
以上是关于多渠道归因分析(Attribution):用attention-RNN来做归因建模(附代码demo)的主要内容,如果未能解决你的问题,请参考以下文章