技术+案例详解无监督学习Autoencoder
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术+案例详解无监督学习Autoencoder相关的知识,希望对你有一定的参考价值。
摘要:本篇文章将分享无监督学习Autoencoder的原理知识,然后用MNIST手写数字案例进行对比实验及聚类分析。
本文分享自华为云社区《[Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解》,作者: eastmount。
一.什么是Autoencoder
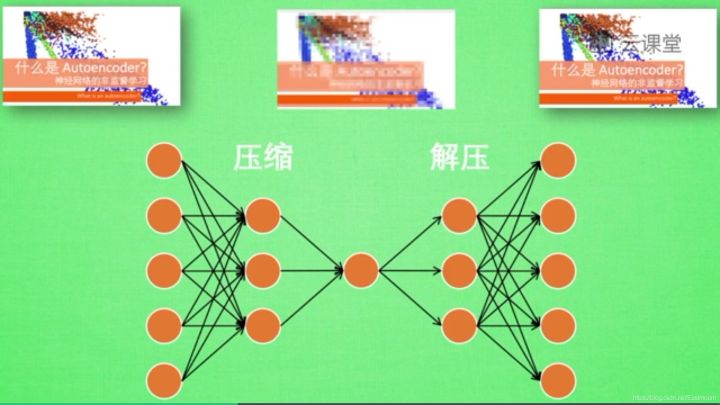
首先,什么是自编码(Autoencoder)?自编码是一种神经网络的形式,注意它是无监督学习算法。例如现在有一张图片,需要给它打码,然后又还原图片的过程,如下图所示:

一张图片经过压缩再解压的工序,当压缩时原有的图片质量被缩减,当解压时用信息量小却包含所有关键性文件恢复出原来的图片。为什么要这么做呢?有时神经网络需要输入大量的信息,比如分析高清图片时,输入量会上千万,神经网络从上千万中学习是非常难的一个工作,此时需要进行压缩,提取原图片中具有代表性的信息或特征,压缩输入的信息量,再把压缩的信息放入神经网络中学习。这样学习就变得轻松了,所以自编码就在这个时候发挥作用。
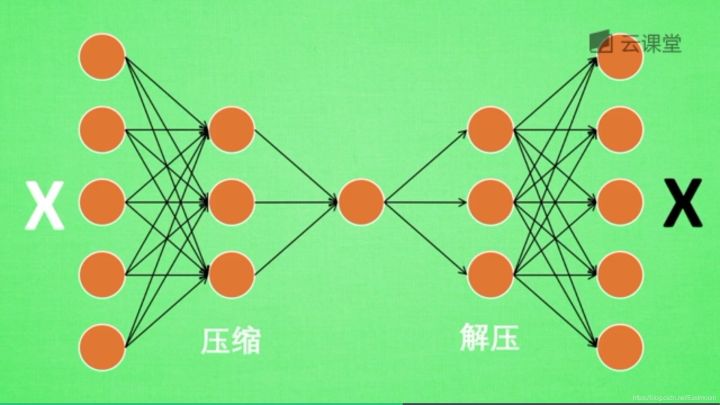
如下图所示,将原数据白色的X压缩解压成黑色的X,然后通过对比两个X,求出误差,再进行反向的传递,逐步提升自编码的准确性。
训练好的自编码,中间那部分就是原数据的精髓,从头到尾我们只用到了输入变量X,并没有用到输入变量对应的标签,所以自编码是一种无监督学习算法。
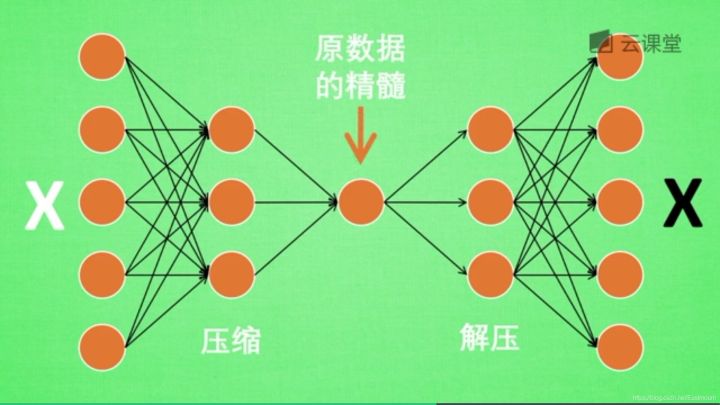
但是真正使用自编码时,通常只用到它的前半部分,叫做编码器,能得到原数据的精髓。然后只需要创建小的神经网络进行训练,不仅减小了神经网络的负担,而且同样能达到很好的效果。
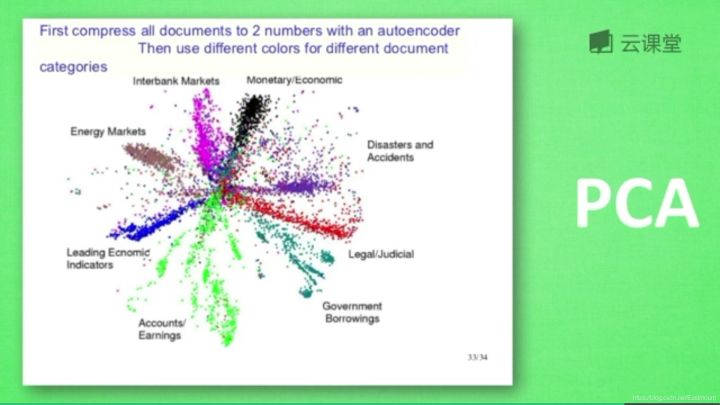
下图是自编码整理出来的数据,它能总结出每类数据的特征,如果把这些数据放在一张二维图片上,每一种数据都能很好的用其精髓把原数据区分开来。自编码能类似于PCA(主成分分析)一样提取数据特征,也能用来降维,其降维效果甚至超越了PCA。
二.Autoencoder分析MNIST数据
Autoencoder算法属于非监督学习,它是把数据特征压缩,再把压缩后的特征解压的过程,跟PCA降维压缩类似。
本篇文章的代码包括两部分内容:
- 第一部分:使用MNIST数据集,通过feature的压缩和解压,对比解压后的图片和压缩之前的图片,看看是否一致,实验想要的效果是和图片压缩之前的差不多。
- 第二部分:输出encoder的结果,压缩至两个元素并可视化显示。在显示图片中,相同颜色表示同一类型图片,比如类型为1(数字1),类型为2(数字2)等等,最终实现无监督的聚类。
有监督学习和无监督学习的区别
(1) 有监督学习方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。而非监督学习没有训练集,只有一组数据,在该组数据集内寻找规律。
(2) 有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法只有要分析的数据集的本身,预先没有什么标签。 如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
让我们开始编写代码吧!
第一步,打开Anaconda,然后选择已经搭建好的“tensorflow”环境,运行Spyder。
第二步,导入扩展包。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data第三步,下载数据集。
由于MNIST数据集是TensorFlow的示例数据,所以我们只需要下面一行代码,即可实现数据集的读取工作。如果数据集不存在它会在线下载,如果数据集已经被下载,它会被直接调用。
# 下载手写数字图像数据集
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
第四步,定义参数。
MNIST图片是28*28的像素,其n_input输入特征为784,feature不断压缩,先压缩成256个,再经过一层隐藏层压缩到128个。然后把128个放大,解压256个,再解压缩784个。最后对解压的784个和原始的784个特征进行cost对比,并根据cost提升Autoencoder的准确率。
#-------------------------------------初始化设置-------------------------------------------
# 基础参数设置
learning_rate = 0.01 #学习效率
training_epochs = 5 #5组训练
batch_size = 256 #batch大小
display_step = 1
examples_to_show = 10 #显示10个样本
# 神经网络输入设置
n_input = 784 #MNIST输入数据集(28*28)
# 隐藏层设置
n_hidden_1 = 256 #第一层特征数量
n_hidden_2 = 128 #第二层特征数量
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input]))
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input]))
}第五步,编写核心代码,即定义encoder和decoder函数来实现压缩和解压操作。

encoder就是两层Layer,分别压缩成256个元素和128个元素。decoder同样包括两层Layer,对应解压成256和784个元素。
#---------------------------------压缩和解压函数定义---------------------------------------
# Building the encoder
def encoder(x):
# 第一层Layer压缩成256个元素 压缩函数为sigmoid(压缩值为0-1范围内)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# 第二层Layer压缩成128个元素
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# Building the decoder
def decoder(x):
# 解压隐藏层调用sigmoid激活函数
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# 第二层Layer解压成784个元素
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
#-----------------------------------压缩和解压操作---------------------------------------
# 压缩:784 => 128
encoder_op = encoder(X)
# 解压:784 => 128
decoder_op = decoder(encoder_op)需要注意,在MNIST数据集中,xs数据的最大值是1,最小值是0,而不是图片的最大值255,因为它已经被这里的sigmoid函数归一化了。
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0第六步,定义误差计算方式。
其中,y_pred表示预测的结果,调用decoder_op解压函数,decoder_op又继续调用decoder解压和encoder压缩函数,对图像数据集X进行处理。
#--------------------------------对比预测和真实结果---------------------------------------
# 预测
y_pred = decoder_op
# 输入数据的类标(Labels)
y_true = X
# 定义loss误差计算 最小化平方差
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)第七步,定义训练和可视化代码,该部分为神经网络运行的核心代码。
首先进行init初始化操作,然后分5组实验进行训练,batch_x为获取的图片数据集,通过 sess.run([optimizer, cost], feed_dict={X: batch_xs}) 计算真实图像与预测图像的误差。
#-------------------------------------训练及可视化-------------------------------------
# 初始化
init = tf.initialize_all_variables()
# 训练集可视化操作
with tf.Session() as sess:
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# 训练数据 training_epochs为5组实验
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x)=1 min(x)=0
# 运行初始化和误差计算操作
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# 每个epoch显示误差值
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")第八步,调用matplotlib库画图,可视化对比原始图像和预测图像。
# 压缩和解压测试集
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# 比较原始图像和预测图像数据
f, a = plt.subplots(2, 10, figsize=(10, 2))
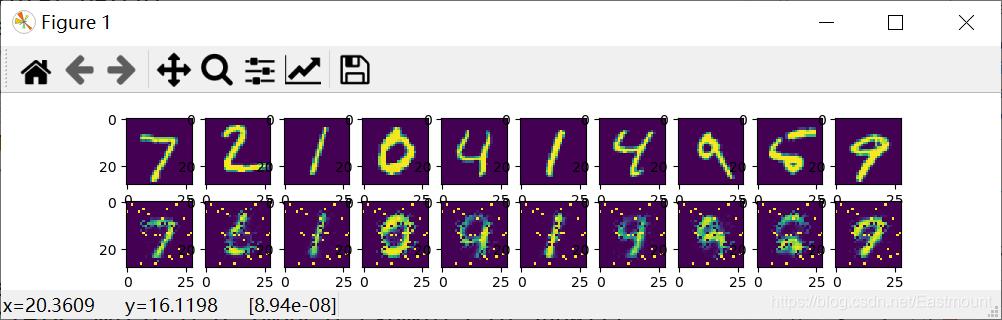
# 显示结果 上面10个样本是真实数据 下面10个样本是预测结果
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()第九步,运行代码并分析结果。
输出结果如下图所示,误差在不断减小,表示我们的无监督神经网络学习到了知识。
Extracting MNIST_data\\train-images-idx3-ubyte.gz
Extracting MNIST_data\\train-labels-idx1-ubyte.gz
Extracting MNIST_data\\t10k-images-idx3-ubyte.gz
Extracting MNIST_data\\t10k-labels-idx1-ubyte.gz
Epoch: 0001 cost= 0.097888887
Epoch: 0002 cost= 0.087600455
Epoch: 0003 cost= 0.083100438
Epoch: 0004 cost= 0.078879632
Epoch: 0005 cost= 0.069106154
Optimization Finished!通过5批训练,显示结果如下图所示,上面是真实的原始图像,下面是压缩之后再解压的图像数据。注意,其实5批训练是非常少的,正常情况需要更多的训练。
完整代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 15 15:35:47 2020
@author: xiuzhang Eastmount CSDN
"""
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
#-----------------------------------初始化设置---------------------------------------
# 基础参数设置
learning_rate = 0.01 #学习效率
training_epochs = 5 #5组训练
batch_size = 256 #batch大小
display_step = 1
examples_to_show = 10 #显示10个样本
# 神经网络输入设置
n_input = 784 #MNIST输入数据集(28*28)
# 输入变量(only pictures)
X = tf.placeholder("float", [None, n_input])
# 隐藏层设置
n_hidden_1 = 256 #第一层特征数量
n_hidden_2 = 128 #第二层特征数量
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input]))
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input]))
}
# 导入MNIST数据
mnist = input_data.read_data_sets("MNIST_data", one_hot=False)
#---------------------------------压缩和解压函数定义---------------------------------------
# Building the encoder
def encoder(x):
# 第一层Layer压缩成256个元素 压缩函数为sigmoid(压缩值为0-1范围内)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# 第二层Layer压缩成128个元素
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# Building the decoder
def decoder(x):
# 解压隐藏层调用sigmoid激活函数(范围内为0-1区间)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# 第二层Layer解压成784个元素
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
#-----------------------------------压缩和解压操作---------------------------------------
# Construct model
# 压缩:784 => 128
encoder_op = encoder(X)
# 解压:784 => 128
decoder_op = decoder(encoder_op)
#--------------------------------对比预测和真实结果---------------------------------------
# 预测
y_pred = decoder_op
# 输入数据的类标(Labels)
y_true = X
# 定义loss误差计算 最小化平方差
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
#-------------------------------------训练及可视化-------------------------------------
# 初始化
init = tf.initialize_all_variables()
# 训练集可视化操作
with tf.Session() as sess:
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# 训练数据 training_epochs为5组实验
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x)=1 min(x)=0
# 运行初始化和误差计算操作
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# 每个epoch显示误差值
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# 压缩和解压测试集
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# 比较原始图像和预测图像数据
f, a = plt.subplots(2, 10, figsize=(10, 2))
# 显示结果 上面10个样本是真实数据 下面10个样本是预测结果
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()三.特征聚类分析
第一部分实验完成,它对比了10张原始图像和预测图像。我们接着分享第二部分的实验,生成聚类图。
第一步,修改参数。
修改如下,学习效率设置为0.001,训练批次设置为20。
# 基础参数设置
learning_rate = 0.001 #学习效率
training_epochs = 20 #20组训练
batch_size = 256 #batch大小
display_step = 1第二步,增加encoder和decoder层数,并修改参数。
我们将隐藏层设置为4层,这样的效果会更好。首先从784压缩到128,再压缩到64、10,最后压缩到只有2个元素(特征),从而显示在二维图像上。同时更新weights值和biases值,encoder和decoder都设置为4层。
# 隐藏层设置
n_hidden_1 = 128 #第一层特征数量
n_hidden_2 = 64 #第二层特征数量
n_hidden_3 = 10 #第三层特征数量
n_hidden_4 = 2 #第四层特征数量
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'encoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_3])),
'encoder_h4': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_4])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_4, n_hidden_3])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_2])),
'decoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h4': tf.Variable(tf.random_normal([n_hidden_1, n_input]))
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}第三步,修改压缩和解压定义函数,也是增加到四层。
#---------------------------------压缩和解压函数定义---------------------------------------
# Building the encoder
def encoder(x):
# 压缩隐藏层调用函数sigmoid(压缩值为0-1范围内)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
# 输出范围为负无穷大到正无穷大 调用matmul函数
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
# Building the decoder
def decoder(x):
# 解压隐藏层调用sigmoid激活函数(范围内为0-1区间)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4第四步,最后修改训练代码,我们不再观看它的训练结果,而是观察它解压前的结果。
# 观察解压前的结果
encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
# 显示encoder压缩成2个元素的预测结果
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)
plt.colorbar()
plt.show()完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 15 15:35:47 2020
@author: xiuzhang Eastmount CSDN
"""
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
#-----------------------------------初始化设置---------------------------------------
# 基础参数设置
learning_rate = 0.001 #学习效率
training_epochs = 20 #20组训练
batch_size = 256 #batch大小
display_step = 1
examples_to_show = 10 #显示10个样本
# 神经网络输入设置
n_input = 784 #MNIST输入数据集(28*28)
# 输入变量(only pictures)
X = tf.placeholder("float", [None, n_input])
# 隐藏层设置
n_hidden_1 = 128 #第一层特征数量
n_hidden_2 = 64 #第二层特征数量
n_hidden_3 = 10 #第三层特征数量
n_hidden_4 = 2 #第四层特征数量
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'encoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_3])),
'encoder_h4': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_4])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_4, n_hidden_3])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_2])),
'decoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h4': tf.Variable(tf.random_normal([n_hidden_1, n_input]))
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}
# 导入MNIST数据
mnist = input_data.read_data_sets("MNIST_data", one_hot=False)
#---------------------------------压缩和解压函数定义---------------------------------------
# Building the encoder
def encoder(x):
# 压缩隐藏层调用函数sigmoid(压缩值为0-1范围内)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
# 输出范围为负无穷大到正无穷大 调用matmul函数
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
# Building the decoder
def decoder(x):
# 解压隐藏层调用sigmoid激活函数(范围内为0-1区间)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
#-----------------------------------压缩和解压操作---------------------------------------
# Construct model
# 压缩:784 => 128
encoder_op = encoder(X)
# 解压:784 => 128
decoder_op = decoder(encoder_op)
#--------------------------------对比预测和真实结果---------------------------------------
# 预测
y_pred = decoder_op
# 输入数据的类标(Labels)
y_true = X
# 定义loss误差计算 最小化平方差
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
#-------------------------------------训练及可视化-------------------------------------
# 初始化
init = tf.initialize_all_variables()
# 训练集可视化操作
with tf.Session() as sess:
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# 训练数据
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x)=1 min(x)=0
# 运行初始化和误差计算操作
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# 每个epoch显示误差值
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# 观察解压前的结果
encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
# 显示encoder压缩成2个元素的预测结果
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)
plt.colorbar()
plt.show()这个训练过程需要一点时间,运行结果如下图所示:
聚类显示结果如下图所示,它将不同颜色的分在一堆,对应不同的数字。比如左下角数据集被无监督学习聚类为数字0,而另一边又是其他的数据。
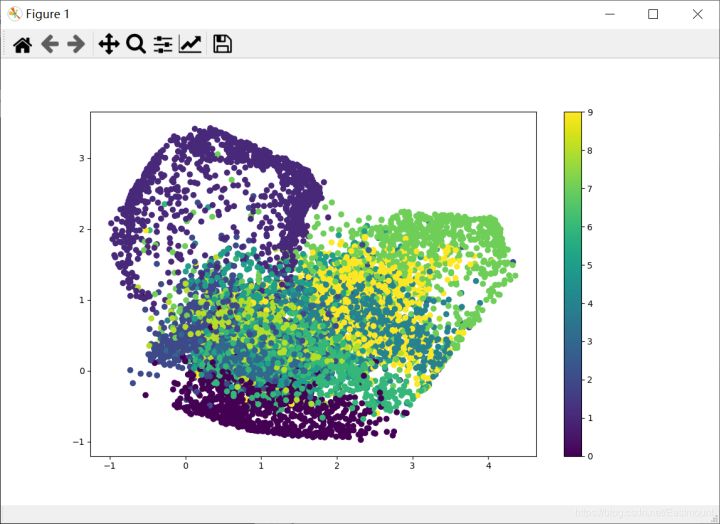
但其聚类结果还有待改善,因为这只是Autoencoder的一个简单例子。希望这篇文章能够帮助博友们理解和认识无监督学习和Autoencoder算法,后续作者会更深入的分享好案例。
参考文献:
[1] 杨秀璋, 颜娜. Python网络数据爬取及分析从入门到精通(分析篇)[M]. 北京:北京航天航空大学出版社, 2018.
[2] “莫烦大神” 网易云视频地址
[3] https://study.163.com/course/courseLearn.htm?courseId=1003209007
[4] https://github.com/siucaan/CNN_MNIST
[5] https://github.com/eastmountyxz/AI-for-TensorFlow
[6]《机器学习》周志华
[7] 深度学习(07)RNN-循环神经网络-02-Tensorflow中的实现 - 莫失莫忘Lawlite
[8] https://github.com/lawlite19/DeepLearning_Python
以上是关于技术+案例详解无监督学习Autoencoder的主要内容,如果未能解决你的问题,请参考以下文章