CopyOnWriteArrayList实现原理源码分析
Posted hymKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CopyOnWriteArrayList实现原理源码分析相关的知识,希望对你有一定的参考价值。
针对于并发场景下动态数组的选型,可以使用线程安全的列表Vector,Vector是jdk1.0版本就带有的一个线程安全的动态数组类,但是Vector的实现原理之前分析过,对于所有对内部存储数据结构的操作,都添加了同步锁,这样的实现方式,虽然保证了线程的安全性,大并发场景下,却等同于多个线程的串行化执行,效率低下。jdk1.5引入了新的线程安全的列表实现CopyOnWriteArrayList。
一、CopyOnWriteArrayList的实现类图
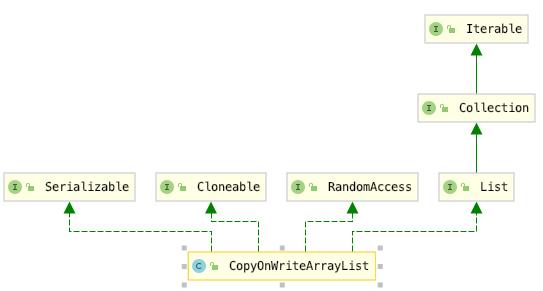
类图结构和ArrayList完全一致,这个也合理,从CopyOnWriteArrayList名称上看,它是一种特殊的ArrayList。
同ArrayList直接实现了了四个接口如上,其中List提供了基础的添加、删除、遍历操作;
RandomAccess提供了随机访问能力、Cloneable接口,提供了可以被克隆、Serializable接口,提供了可以序列化的能力;
RandomAccess、Cloneable、Serializable都是空接口,这种空接口在Jdk的机制中,这种标记接口被实现后,起到给类打标记的作用,程序在运行期间通过识别标记,实现相应的功能。当然有兴趣了解更多标记接口的实现和运行机制,可以查阅相关其它资料。
接下来,我们通过阅读源码看代码底层的数据结构的实现、扩容机制上的区别、是否线程安全、以及性能优势。
二、源码分析
内部数据结构对象的声明部分:
/** 保护所有增变基因的锁 */
final transient ReentrantLock lock = new ReentrantLock();
/** 私有的 内部数组 被volatile关键字修饰 */
private transient volatile Object[] array;
内部数据结构的声明部分比ArrayList要简单,仅仅一个数组的声明,但是不同的是有一个ReentrantLock锁。
lock:ReentrantLock独占锁,多线程运行下,只有一个线程可以获得这个锁,只有释放锁后其他线程才能获得。
array:存放数据的数组,关键是被volatile修饰了,保证了可见性,也就是一个线程修改后,其他线程立即可见。
看一下构造函数:
/**
* 创建一个空列表
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
/**
* 声明的成员变量,只能被setArray()、getArray()访问
*/
final void setArray(Object[] a) {
array = a;
}
setArray()、getArray()方法,都final关键字修饰,方法无法被重写,确定了内部封装性。
/**
* 获取列表的大小
* @return the number of elements in this list
*/
public int size() {
return getArray().length;
}
对比一下arrayList的获取list大小的方法:
/**
* The size of the ArrayList (the number of elements it contains).
*/
private int size;
/**
* @return the number of elements in this list
*/
public int size() {
return size;
}
public void add(int index, E element) {
....
size++;
}
CopyArrayListOnWrite的getSize获取的就是数组的长度,这里面可以猜测数组的长度,就是List元素的个数,这点和ArrayList是有差别的,差别大概率会是在数组容量的策略上,我们继续分析源代码,看实现。还是从元素添加的add方法切入:
/**
* 在list的尾部追加新的元素
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
//独占锁锁住
lock.lock();
try {
//获取当前的数组对象
Object[] elements = getArray();
//获取当前数组的长度
int len = elements.length;
//创建一个新的数组,将原有的数组copy进新数组,并追加一个空位置
Object[] newElements = Arrays.copyOf(elements, len + 1);//调用的底层system.arrayCopy
//将新增的数组添加到这个追加的新位置上,也就是数组的尾部
newElements[len] = e;
//将新的数组重新赋值给成员变量。
setArray(newElements);
return true;
} finally {
//独占锁解锁
lock.unlock();
}
}
从add方法的实现过程我们可以看到,整个操作过程是被独占锁保护,在新增元素的时候,是通过Copy一个新的数组,add()方法再拷贝新的数组的时候将数组的容量+1,为新元素的添加留下位置,这样虽然每次添加元素的时候都会浪费一定的空间,但是数组的长度正好是元素的长度,一定程度上节省了扩容的开销。add操作属于写操作,写时Copy也就正如是体现。
写时复制就是COW的核心设计思想。
remove方法:
/**
* 删除元素的方法,会返回被删除的元素
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
final ReentrantLock lock = this.lock;
//加锁
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)//删除的是末尾的元素
//直接copy,丢下末尾元素
setArray(Arrays.copyOf(elements, len - 1));
else {
//删除的元素是中间的元素
Object[] newElements = new Object[len - 1];
//copy前半部分
System.arraycopy(elements, 0, newElements, 0, index);
//copy后半部分
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
//重新赋值给成员变量的实际存储list元素的数组
setArray(newElements);
}
//解锁
return oldValue;
} finally {
lock.unlock();
}
}
/* System.arraycopy
* @param src 源数组
* @param srcPos 元素组的起始位置
* @param dest 目标数组
* @param destPos 目标数组的其实位置
* @param length 目标数组copy的元素个数
*/
remove方法的实现也比较简单,同样属于写操作,被独占锁保护,通过数组copy的方式完成移除。
最后,我们看一下读操作,获取元素的方法:
**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return get(getArray(), index);
}
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}
读操作可以认为是天然的安全性操作,但是如果没有合理的策略实现,会出现脏读,但在CopyOnWriteArrayList的实现中,存储元素的数组,声明时被volatile关键字修饰,实现了内存的可见性,能很大程度上避免脏读。
对比一下vector的获取元素的操作:
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
Vector的get操作,同样被synchronized修饰,会持有内置锁做同步。很显然CopyOnWrite既保证写操作的安全性,又提升了读操作的性能,在容量控制机制上,无扩容设计。
扫码关注个人公众号 获取文章更新更及时:

以上是关于CopyOnWriteArrayList实现原理源码分析的主要内容,如果未能解决你的问题,请参考以下文章