正则表达式练习之贴吧实例
Posted 二木成林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式练习之贴吧实例相关的知识,希望对你有一定的参考价值。
题目:提取一段小说链接文本中的章节链接和章节名
测试文本:
<div align="left"><a href="393711.shtml" title="更新时间:2006-10-25 1:24:00
更新字数:2075">第十九章 新式火铳(二)</a></div></td>
要求:获取 393711.shtml 和 第十九章 新式火铳(二)
答案:
- 提取章节链接:
<a href="(.*?)"或"(\\d+\\.shtml)" - 提取章节名:
>(.*?)</a>
题目:只能输入1-4个中文字
答案:[\\u4e00-\\u9fa5]{1,4}
题目:过滤<div>标签
测试文本:
A<div class="ds">B</div>C<div lagndfds=df>D<div lagndfds=df>E<div lagndfds=df>F</div></div></div>G
答案:</?div[^>]*>
解释:其实该正则表达式匹配的就是<div>标签,匹配到之后就可以通过替换的方式过滤掉。最开始我的思路是利用断言去匹配前面和后面不是<div>标签的情况,后来发现去匹配<div>标签是最简单的思路,可以写一个正则表达式匹配(</div>|<div[^>]*>),精简下就是上面的答案了。
原链接:https://tieba.baidu.com/p/109829889
题目:正则实现替换
测试文本:
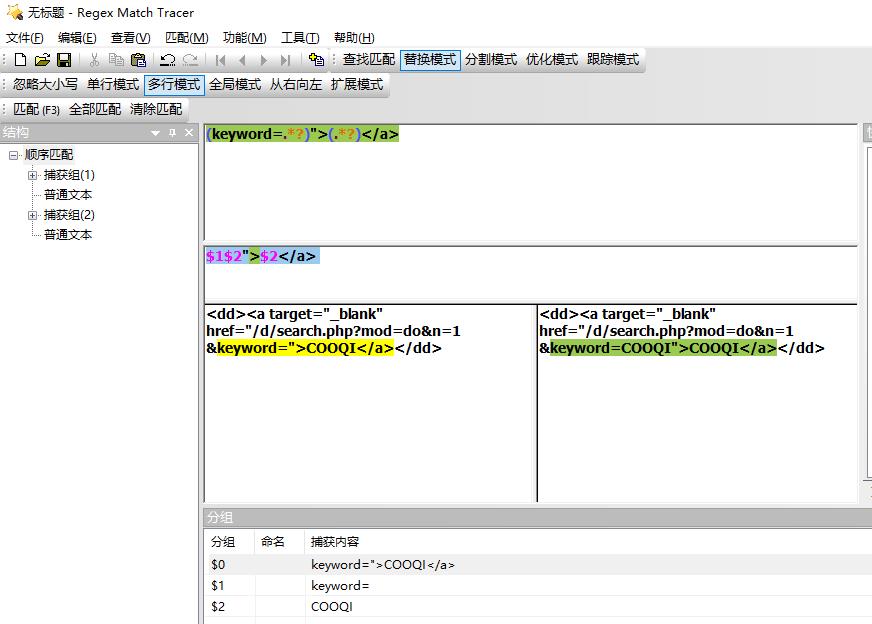
<dd><a target="_blank" href="/d/search.php?mod=do&n=1&keyword=">COOQI</a></dd>
要求:有上千条下面这样的,其中COOQI是没有规则,没有重复,都是不一样的汉字或者字符或者数字,想把COOQI复制替换到keyword=">里面。
<dd><a target="_blank" href="/d/search.php?mod=do&n=1&keyword=COOQI">COOQI</a></dd>
答案:使用(keyword=.*?)">(.*?)</a>进行匹配;使用$1$2">$2</a>进行替换
题目:111-1111 这样的正则表达式怎么写
要求:格式 111-1111 前三位是半角数字,第四位是一个横线,后面四位也半角数字。
答案:\\d{3}-\\d{4}
原链接:https://tieba.baidu.com/p/381677963
题目:用正则表达式查找出不是tom的人名
测试文本:tom,tom,tim,tom,tom,tom,tom,tom,tom,tom,tom,abcd,mike,tom
要求:这个例子中就是要找出第三个人名tim、倒数第三个人名abcd和倒数第二个人名mike。
答案:,?(?!tom)([a-z]+)(?<!tom),
解释:使用了先行断言和后行断言,找出,后面不是tom的情况,找出,前面不是tom的情况,中间的英文字符串就是我们所求的。
原链接:https://tieba.baidu.com/p/323290709
题目:匹配数字字符串
要求:求以10位数字开头,最后一位为4的正则表达式和以1395开头,后面是7位数字结尾的正则表达式。
答案:^10\\d+4$和^1395\\d{7}
原链接:https://tieba.baidu.com/p/467567711
题目:匹配`标签中的文本
要求:要匹配的文本:<title>果冻</title><title>哈哈</title>我想分别提取 title标签内的文字:果冻 和 哈哈。
答案:<title>(.*?)</title>
原链接:https://tieba.baidu.com/p/519226740
题目:对文本进行切割使用正则表达式
要求:想把下列字串 a111b222c333d444e555用正则表达式处理成
a111
b222
c333
d444
e555
答案:(?=[a-z]\\d{3})
Java代码:
@Test
public void test(){
String text="a111b222c333d444e555";
String[] split = text.split("(?=[a-z]\\\\d{3})");
// [a111, b222, c333, d444, e555]
System.out.println(Arrays.toString(split));
}
原链接:https://tieba.baidu.com/p/567431485
题目:1-7的数字生成3位数字,不能重复
答案:^([1-7])(?!\\1)([1-7])(?!\\1|\\2)[1-7]$
解释:该数字由三位组成,每一位都是[1-7],但要求三位数字之间不能重复,那么123、456、241是符合要求的,而112、334、789、1234是不符合要求的。首先,确定第一位数字可以是[0-7],不受重复条件的约束;第二位数字也可以是[0-7],但不能与第一位数字重复,所以可以使用先行断言expr1(?!expr2),即匹配expr1但expr1后面不能是expr2,正好用到此处,要求第2位数字出现的位置不能是第1位已经出现过的数字,那么要引用第1位已经出现过的数字,则需要使用到分组将第一位数字包裹起来,然后使用\\1引用第一个分组的匹配结果,所以写出来的正则表达式是([1-7])(?!\\1)([1-7]);第三位数字同理,不能是第1位和第2位已经出现过的数字,使用|进行或的表达;同时要求数字是三位,所以使用^和$确定边界,最后写出来的正则表达式如上。该例十分之好,涉及正则表达式知识点较多,值得反复思考。
原链接:https://tieba.baidu.com/p/567230439
题目:求一个匹配01到25即01,02,03,……,10,11,12,……25的正则表达式
答案:^(0[1-9]|1[0-9]|2[0-5])$
原链接:https://tieba.baidu.com/p/637908669
题目:不能含有非空字符 和' 及 \\ 的0到100个字符
答案:[^\\s'\\\\]{0,100}
原链接:https://tieba.baidu.com/p/555973360
题目:要匹配所有以xn--开头,.com结尾的文字
答案:^xn--.*?\\.com$
原链接:https://tieba.baidu.com/p/549987646
题目:提取一段代码中的sql
测试文本:
String str="public class ss{string sql="select *from ss";DataTable dt=new DataTable();foreach(var item dt.Rows){};sql="select *rom bb";....sql="select *from kkk";}"
答案:sql="(.*?)";或(?<=sql=")[^"]*(?=")
原链接:https://tieba.baidu.com/p/644171942
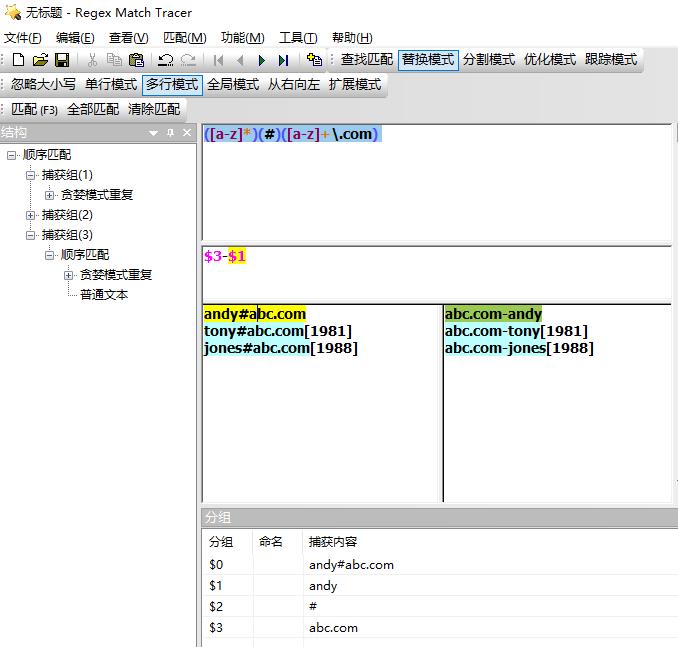
题目:替换文本
要求:把如下文本
andy#abc.com
tony#abc.com[1981]
jones#abc.com[1988]
替换成:
abc.com-andy
abc.com-tony[1981]
abc.com-jones[1988]
答案:([a-z]*)(#)([a-z]+\\.com)
原链接:https://tieba.baidu.com/p/546808168
题目:6~18个字符,包括字母、数字、下划线,字母开头,字母和数字结尾,不区分大小写
答案:^[a-zA-Z]\\w{4,16}[a-zA-Z0-9]$
原链接:https://tieba.baidu.com/p/658975825
题目:不超过7个汉字,或14个字节(数字,字母和下划线)
答案:(^[\\u4e00-\\u9fa5]{1,7}$|^[\\dA-Za-z_]{1,14}$)
原链接:https://tieba.baidu.com/p/666646561
题目:匹配除了FE0/22和FE0/23外所有FE0/1-FE0/24端口
测试文本:
FE0/22
FE0/23
FE0/24
FE0/1
FE0/12
FE0/9
答案:FE0/([1-9]|1[0-9]|20|21|24)$或FE0/([1-9]|1[0-9]|2[^23])$或FE0/(2([^23])|[^2]\\d?)
原链接:https://tieba.baidu.com/p/711815968
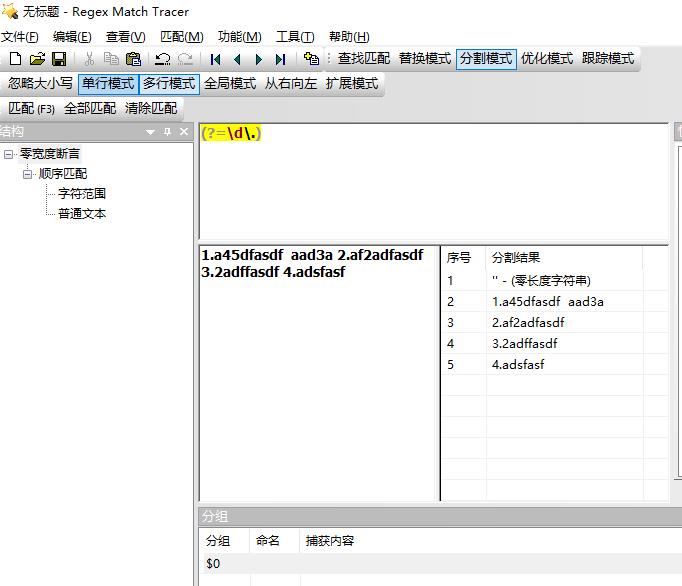
题目:分割字符串
测试文本:1.a45dfasdf aad3a 2.af2adfasdf 3.2adffasdf 4.adsfasf
要求:
1.a45dfasdf aad3a
2.af2adfasdf
3.2adffasdf
4.adsfasf
答案:(?=\\d\\.)
原链接:https://tieba.baidu.com/p/278339379
题目:密码验证
要求:该字符串只能包括字母和数字;至少有一个字母和一个数字;整个字符串长度在6到18。
答案:^(?![a-zA-Z]+$)(?![0-9]+$)[a-zA-Z0-9]{6,18}$
原链接:https://tieba.baidu.com/p/727501849
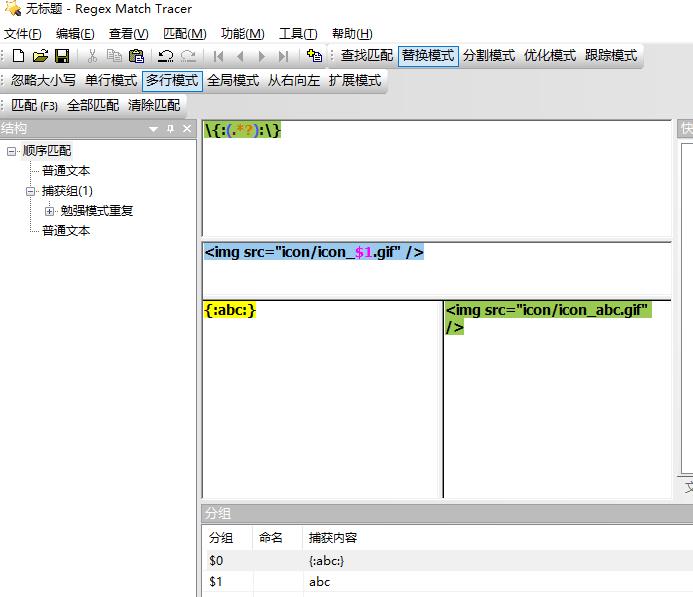
题目:要求替换表情代码
要求:比如我的表情代码是{:abc:},要替换成<img src="icon/icon_abc.gif" />。
答案:
- 匹配正则表达式:
\\{:(.*?):\\} - 替换正则表达式:
<img src="icon/icon_$1.gif" />
原链接:https://tieba.baidu.com/p/735068162
题目:判断词汇音标及汉语释义的正则表达式
测试文本:aboriginal [ˌæbəˈrɪdʒənəl] n.原始居民,土著
答案:([a-zA-Z]+) (\\[.*?\\])(.*)
原链接:https://tieba.baidu.com/p/734623744
题目:匹配格式为###.####的数字
要求:可以输入3位以内整数,或者3位以内整数+4位以内小数,如果只有整数,则不可以输入小数点。
答案:\\d{1,3}(\\.\\d{0,4})?
原链接:https://tieba.baidu.com/p/731241371
题目:以“13”开头,以“24”结尾,中间不含“abc”的字符串的正则表达式
答案:^13.*abc.*24$
解释:上面的正则表达式能匹配出以“13”开头,以“24”结尾,中间含有“abc”的字符串,然后在判断的时候“取非”。转换思路去考虑不匹配情况的正则表达式,而不是考虑匹配情况下的正则表达式。
以上是关于正则表达式练习之贴吧实例的主要内容,如果未能解决你的问题,请参考以下文章
Linux脚本练习之script046-统计文件中仅包含数字的行。