Hadoop单机伪分布式安装(完整版)
Posted 祁酒仲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop单机伪分布式安装(完整版)相关的知识,希望对你有一定的参考价值。
在学习Hadoop时,我发现网上的各种安装的资料要不不全,要不前后不匹配(比如有的是伪分布式,有的是完全分布式)。此篇文章,我总结了身边的同学在安装Hadoop时遇到的毛病,在前面安装配置环节,尽可能使用最优化的处理方式,以便于我们后续hbase的安装和使用。
前言:我所使用的Hadoop版本为Hadoop 2.10.1,jdk版本为jdk1.8.0_112, hbase版本为hbase2.3.3。在版本选择时,你们可以选择与我不同的版本,但记得一定要考虑版本的兼容性。说不多说,我们开始进行Hadoop单机伪分布安装吧!
一、创建Hadoop用户并设置密码
[用户名@localhost ~] $ su root
[root@localhost 用户名] # useradd –m hadoop –s /bin/bash
[root@localhost 用户名] # passwd hadoop

二、安装jdk
(1) 查看jdk版本
[root@localhost 用户名] # rpm –qa | grep jdk

(2)删除原先自带的jdk
[root@localhost 用户名] # rpm –qa | grep –i java | xargs -n1 rpm -e --nodeps
[root@localhost 用户名] # rpm –qa | grep –i java
[root@localhost 用户名] # reboot

(3)在/opt目录下分别新建modules和software目录。
建两个文件夹的原因是:software文件夹存放要解压的文件,modules文件夹存放解压之后的文件。
[root@localhost 用户名] # cd /opt
[root@localhost opt] # mkdir modules
[root@localhost opt] # mkdir software

(4)将要用到的压缩包移到/opt/software文件夹下,解压缩jdk,并移动到modules目录下
[root@localhost software] # tar –zxvf jdk-8u112-linux –x64.tar.gz


查看一下jdk解压之后的版本,并将其移动到/opt/modules文件夹里
[root@localhost software] # mv jdk1.8.0_112 /opt/modules
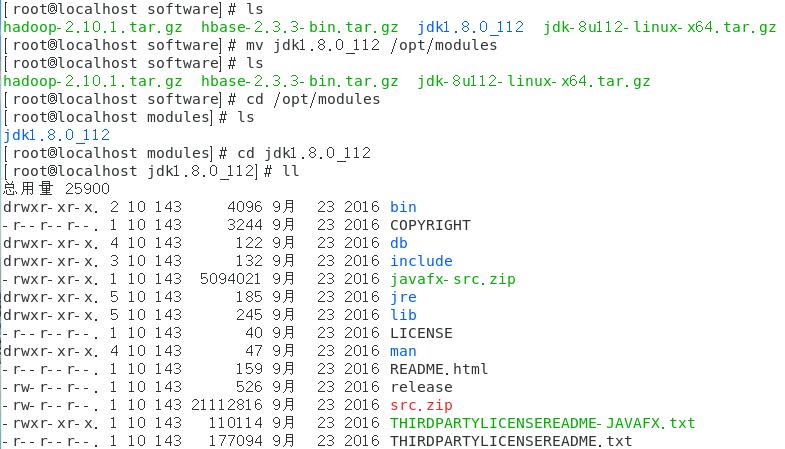
(5)配置Java环境变量
[root@localhost modules] # vi /etc/profile
#要增加的内容:
export JAVA_HOME=/opt/modules/jdk1.8.0_112
export PATH=$JAVA_HOME/bin:$PATH

[root@localhost modules] # cat /etc/profile
#添加了JAVA_HOME和PATH路径,用cat命令查看文件内容修改成功。


用source命令在当前bash环境下读取并执行/etc/profille中的命令,用java-version检查环境变量配置成功。
[root@localhost modules] # source /etc/profile
[root@localhost modules] # java -version

三、安装配置SSH
(1) 检查SSH是否安装
[root@localhost ~] # rpm -qa| grep ssh
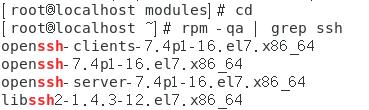 (2) 修改sshd配置文件
(2) 修改sshd配置文件
[root@localhost ~] # vim /etc/ssh/sshd_config

以下图片是需要修改的地方

(3) 重启sshd服务
[root@localhost ~] # service sshd restart

(4) 生成公钥和私钥
[root@localhost ~] # ssh-keygen -t rsa
[root@localhost ~] # cd .ssh
[root@localhost .ssh] # ls
 生成authorized_keys并查看
生成authorized_keys并查看
[root@localhost .ssh]# cat id_rsa.pub >> authorized_keys
修改密钥文件的相应权限
[root@localhost .ssh]# chmod 600 ./ authorized_keys

(5) 使用ssh localhost登录,测试是否可以免密登录
[root@localhost .ssh]# ssh localhost (第一次免密登录,看是否成功)
[root@localhost .ssh]# ssh localhost (第二次免密登录,测试是否稳定)
[root@localhost .ssh]# exit (退出)
 四、安装hadoop
四、安装hadoop
(1)在software里解压Hadoop
[root@localhost ~]# cd /opt/software
[root@localhost software]# ls
[root@localhost software]# tar zxvf hadoop-2.10.1.tar.gz

解压之后的文件重命名为hadoop,以便于后续使用
[root@localhost software]# ls (查看解压之后的结果)
[root@localhost software]# mv hadoop 2.10.1 hadoop (解压包重命名为hadoop)
[root@localhost software]# mv hadoop /opt/modules (将hadoop移动到modules文件夹内)
 (2)为Hadoop用户赋予hadoop文件夹的权限
(2)为Hadoop用户赋予hadoop文件夹的权限
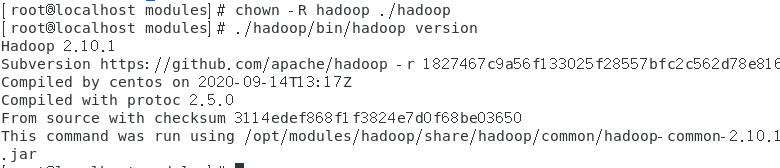
[root@localhost modules]# chown –R hadoop ./hadoop
(3) 查看hadoop版本信息
[root@localhost modules]# ./hadoop/bin/hadoop version
五、Hadoop的伪分布式安装
(1)切换用户到hadoop用户,编辑~/.bashrc文件
[root@localhost modules]# su hadoop
[hadoop@localhost modules]$ vim ~/.bashrc

#要增加的内容:
export HADOOP_HOME=/opt/modules/hadoop
export HADOO_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export JAVA_HOME=/opt/modules/jdk1.8.0_112

Source命令使文件配置生效。
[hadoop@localhost modules]$ source ~/.bashrc
 (2)修改core-site.xml和hdfs-site.xml配置文件
(2)修改core-site.xml和hdfs-site.xml配置文件

[hadoop@localhost hadoop]$ vim ./etc/hadoop/core-site.xml
#要增加的内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
 >[hadoop@localhost hadoop]$ vim ./etc/hadoop/hdfs-site.xml
>[hadoop@localhost hadoop]$ vim ./etc/hadoop/hdfs-site.xml
#要增加的内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/modules/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/modules/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
 (3)格式化namenode
(3)格式化namenode
[hadoop@localhost hadoop]$ ./bin/hdfs namenode -format


(4) 配置hadoop用户下的免密登录
1、 在Hadoop用户下重启sshd服务
[hadoop@localhost hadoop]$ service sshd restart

2、 生成公钥和私钥
[hadoop@localhost hadoop]$ ssh –keygen -t rsa

3、生成authorized_keys并查看
[hadoop@localhost hadoop]$ cat id_rsa.pub >> authorized_keys
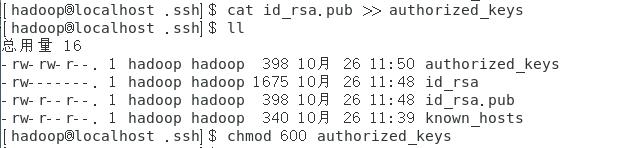
4、修改密钥文件的相应权限
[hadoop@localhost hadoop]$ chmod 600 ./ authorized_keys

此时Hadoop用户就可以实现免密登录了
(5)启动hadoop
[hadoop@localhost hadoop]$ ./sbin/start-dfs.sh

关闭Hadoop
[hadoop@localhost hadoop]$ ./sbin/stop-dfs.sh

Hadoop单机伪分布式安装就这样完成了,安装成功的你是不是成就满满呢。如果这篇文章对你有帮助的话,欢迎一键三连,我们一起进步。
以上是关于Hadoop单机伪分布式安装(完整版)的主要内容,如果未能解决你的问题,请参考以下文章