08-hive中的函数
Posted java全栈_coder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了08-hive中的函数相关的知识,希望对你有一定的参考价值。
hive内置函数
在Hive中,函数主要分两大类型,一种是内置函数,一种是用户自定义函数。
函数查看
show functions;
desc function functionName;
日期函数
1)当前系统时间函数: current_date(). current_timestamp()、unix_timestamp()
-- 函数1:current_date();
当前系统日期 格式:"yyyy-MM-dd"
-- 函数2:current_timestomp();
当前系统时问戳:格式:"yyyy-MM-dd HH:mmm:ss.ms"
-- 函数3: unix_timestamp();
当前系统时间戳格式:距离1970年1月1日0点的秒数。
2)日期转时间戳函数: unix_timestamp()
格式: unix_timestamp([date[,pattern]])
案例:
select unix_timestamp( '1970-01-01 0:0:0'); -- 传入的日期时间是东八区的时间,返回值是相对于子午线的时间来说的
select unix_timestamp('1970-01-01 8:0:0') #0
-- 自定义格式
select unix_timestamp('0:0:0 1970-01-01' ,"HH:mm:ss yyyy-MM-dd");
select unix_timestamp(current_date());
3)时间戳转日期函数: from_unixtime
语法:from__unixtime(unix_time[,pattern])
案例;
select from_unixtime(1574092800);
select from_unixtime(1574096401,'yyyy/MM/dd');
select from_unixtime(1574896401,'yyyy-MM-dd HH:mm:ss');
select from_unixtime(0,'yyyy-MM-dd HH:mm:ss');
select from_unixtime(-28800,"yyyy-MM-dd HH:mm:ss";
4)计算时间差函数: datediff().months_between0
格式: datediff(date1,date2) - Returns the number of days between date1 and date2
select datediff("2019-11-20","2019-11-01"); #返回19
select datediff("2019-11-01","2019-11-19"); #返回-18
格式: months_between(date1,date2) - returns number of months between dates date1 and date2
select months_between( '2019-11-20','2019-11-01'); #返回0.6 (个月)
select months_between( '2019-10-30','2019-11-30'); #返回 1 (个月)
select months_betweenC '2019-10-31','2019-11-30');
select months_between( '2019-11-00','2019-11-30');
5)日期时间分量函数: year()、 month0、day0、 hour()、minute()、 second()
-- 案例
select year(current_date);
select month(current_date);
select day(current_date);
select year(current_timestamp);
select month(current_timestamp);
select day(current_timestamp);
select hour(current_timestamp);
select minute(current_timestamp);
select second(current_timestamp);
select dayofmonth(current_date); #今天是这个月的第几天
select weekofyear(current_date); #这周是今年的第几周
6)日期定位函数:last_day()、next_day()
-- 月末:
select last_day(current_date)
-- 下周
select next_day(current_date,'thursday') ; #下一个thursday是什么日期
7)日期加减函数: date_addo.date_subo、add_months()
select date_add(current_date,1);
select date_sub(current_date,90);
select add_months(current_date,12;
select date_add('2019-12-10',1); #返回 2019-12-11
8)字符串转日期: to_date(
(字符串必须为: yyyy-MM-dd格式)
select to_date('2017-01-01 12:12:12');
9)日期转字符串(格式化) 函数: date_format
select date_format(current_timestamp(),'yyyy-MM-dd HH:mm:ss');
select date_format(current_date(),'yyyyMMdd');
select date_format( '2017-21-01','yyyy-MM-dd HH:mm:ss');
字符串函数
lower -- (转小写)
select lower('ABC');
upper -- (转大写)
select upper('abc');
length -- (字符串长度,字符数)
select length('abc');
concat -- (字符串拼接)
select concat('A','B','C'); # ABC
concat_ws -- (指定分隔符)
select concat_ws('-','a','b','c'); # a-b-c
substr-- (求子串)
select substr('abcde',3); # cde
select substr('abcde',2,3); # bc
split(str ,regex) -- 切分字符串,返回数组。
select split("a-b-c-d-e-f","-");
类型转换函数
cast(value as type) -- 类型转换
select cast("123" as int)+1;
数学函数
round -- 四舍五入((42.3 ->42))
select round(42.3);
ceil -- 向上取整(42.3=>43)
select ceil(42.3);
floor -- 向下取整(42.3=>42)
select floor(42.3);
其他常用函数
nvl(value ,default value):如果value为null,则使用default value,否则使用本身value.
select if(1>2 ,ture,false); # 返回false
select coalesce(1,2,3,4,5) # 返回第一个不为空的 本题返回 1
select coalesce(NULL,2,3,4,5) # 本题返回 2
hive的窗口函数(重点)
窗口函数over简介
先来看一下这个需求:求每个部门的员工信息以及部门的平均工资。在mysql中如何实现呢
SELECT emp.*,avg_sal
FROM emp
J0IN (
SELECT deptno
,round(AVG(ifnull(sal, 0))) AS avg_sal
FR0M emp
GROUP BY deptno
) t
ON emp.deptno = t.deptno
ORDER BY deptno;
select emp.*,(select avg(ifnull(sal,0)) from emp B where B.deptno = A.deptno) from emp A;
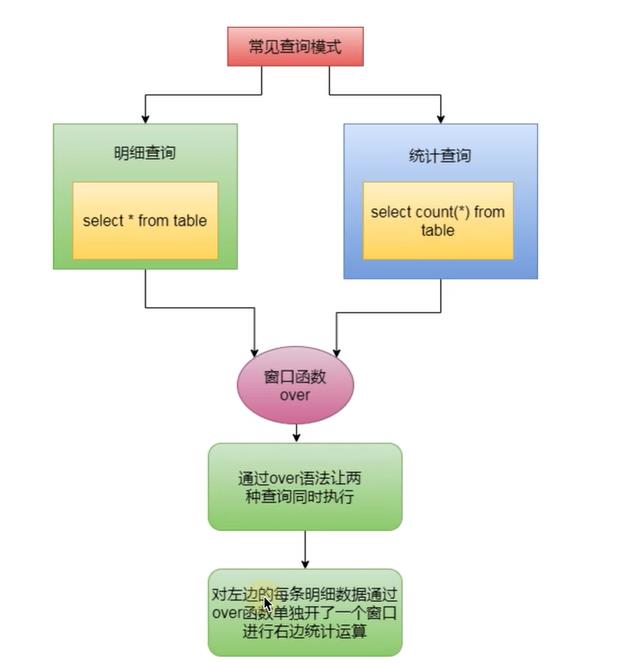
通过这个需求我们可以看到,如果要查询详细记录和聚合数据,必须要经过两次查询,比较麻烦。这个时候,我们使用窗口函数,会方便很多。那么窗口函数是什么呢?
-1)窗口函数又名开窗函数。属于分析函数的一种。
-2)是一种用于解决复杂报表统计需求的函数。
-3)窗口函数常用于计算基于组的某种值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。简单的说窗口函故对每条详细记录开一个面口,进行聚合遶计的查询
-4)开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。
-5)窗口函数一般不单独使用
-6)窗口函数内也可以分组和排序
案例准备
数据准备order.txt
姓名 购买日期 购买数量
saml,2018-01-01,10
tomy,2018-01-02,15
saml,2018-02-03,23
…
-- 1.创建order表:
create table if not exists t_order(
name string,
orderdata string,
cost int
)row format delimited fields terminated by ',';
-- 2.加载数据
load data local inpath "./root/order.txt" into table t_order;
需求:查询每个订单的信息,以及订单的总数
– 1.不使用窗口函数
-- 查询所有明细
select * from t_order;
#查询总量
select count(*) from t_order;
– 2.使用窗口函数:通常格式为可用函数+over()函数
select *, count(*) over() from t_order;
-- 查询返回的结果
saml,2018-01-01,10 3
tomy,2018-01-02,15 3
saml,2018-02-03,23 3
注意:
窗口函数是针对每一行数据的.
如果over中没有指定参数默认窗口大小为全部结果集
需求:查询在2018年1月份购买过的顾客购买明细及总人数
select * ,count(*) over()
from t_order
where substring(orderdate,1,7) = '2018-01';
-- 查询返回的结果
saml,2018-01-01,10 2
tomy,2018-01-02,15 2
distribute by 子句
在over窗口中进行分组,对某一字段进行分组统计,窗口大小就是同一个组的所有记录
需求:查看顾客的购买明细及月购买总额
select name,orderdate,cost,sum(cost) over (distribute by month(orderdate))
from t_order;
saml,2018-01-01,10 33
tomy,2018-01-02,15 15
saml,2018-02-03,23 33
需求:查看顾客的购买明细及每个顾客的月购买总额
select name,orderdate,cost,sum(cost) over (distribute by name, month(orderdate))
from t_order;
saml,2018-01-01,10 33
tomy,2018-01-02,15 15
saml,2018-02-03,23 33
sort by 子句
sort by子句会让输入的数据强制排序(强调:当使用排序时,窗口会在组内逐行变大)
需求:查看顾客的购买明细及每个顾客的月购买总额,并且按照日期降序排序
select name,orderdate,cost,
sum(cost) over (distribute by name, month(orderdate)
sort by orderdata desc)
from t_order;
saml,2018-01-01,10 10
saml,2018-02-03,23 33
saml,2018-02-03,53 86
tomy,2018-01-02,15 15
hive的window子句
如果要对窗口的结果做更细粒度的划分,那么就使用window子句,常见的有下面几个
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING:表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点
需求:查看顾客到目前为止的购买总额
select name,
t_order.orderdata,
cost,
sum(cost) over(partition by name order by orderdata rows between UNBOUNDED PRECEDING and current row) as allCount
from t_order;
需求:求每个顾客最近三次的消费总额
select name,orderdate,cost,
sum(cost) over(partition by name order by orderdata rows between 2 PRECEDING and current row)
from t_order;
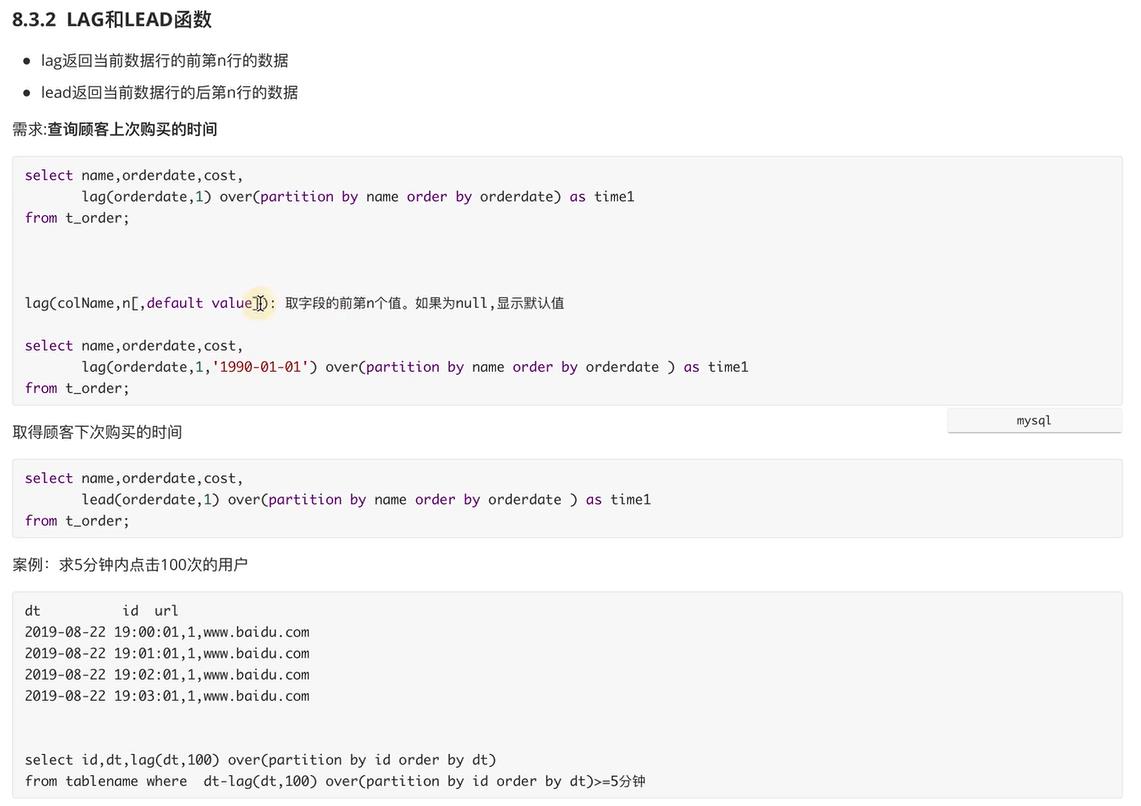
Hive的序列函数
NTILE
ntile 是Hive很强大的一个分析函数。可以看成是:它把有序的数据集合平均分配到指定的数量(num)个榻中,将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
例子:
select name,orderdate,cost,
ntile(3) over(partition by name), #按照name进行分组,在分组内将数据切成3份
from t_order;

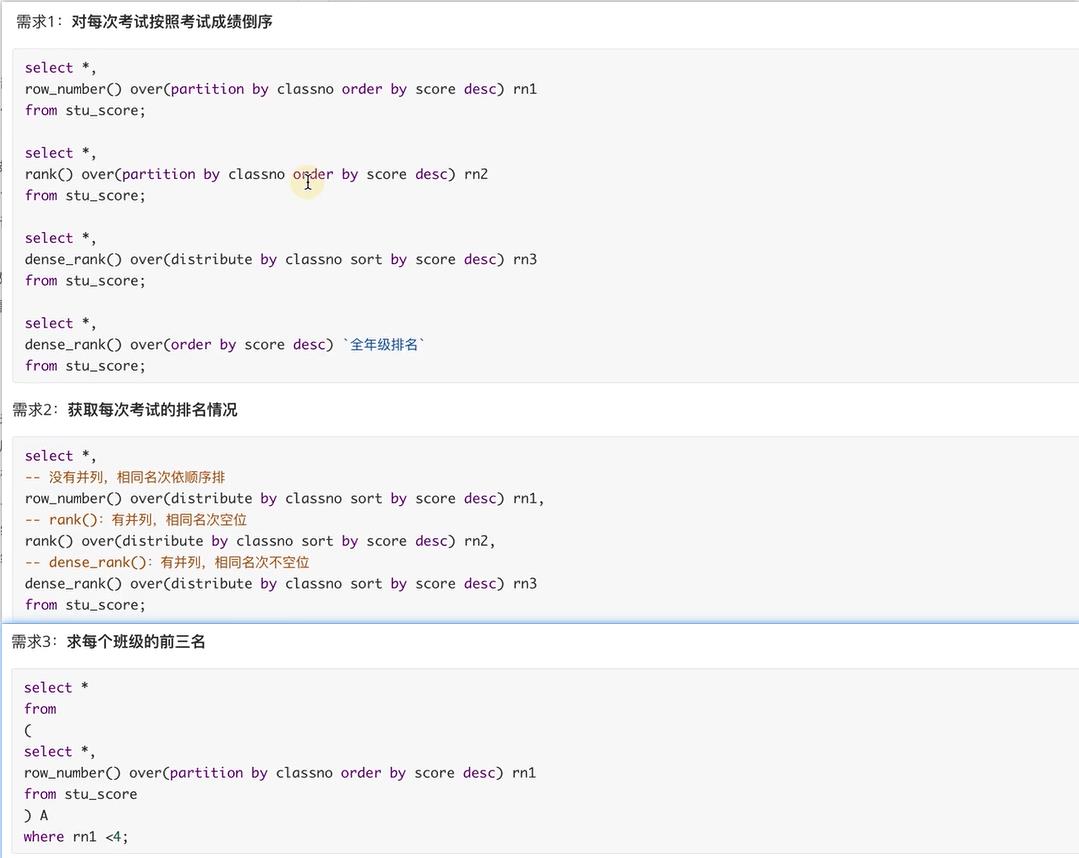
hive的排名函数

准备数据 stu_score.txt

create table if not exists stu_score(
userid int,
classno string,
score int
)
row format delimited
fields terminated by ' ';
local data inpath './root/stu_score.txt' overwrite into table stu_score;
hive的自定义UDF函数
介绍

案例
idea maven项目HiveFunction 在pom.xml加入以下maven的依赖包
<property>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
</property>
写个类 ConcatString
public class ConcatString extends UDF{
public String evaluate(String str){
return str+"!";
}
}
注意
1.继承org.apache.hadoop.hive.al.exec.UDF
2.编写evaluate(),这个方法不是由接口定义的,因为它可接受的参数的个数,数据类型都是不确定的。Hive会检查UDF ,看能否找到和函数调用相匹配的evaluate()方法
第一种:命令加载(只针对当前的session有效)
打包 双击package
HiveFunction-1.0.jar
上传上去
[root@tianqinglong01 ~]# mv HiveFunction-1.0.jar function.jar
# 将编写好的UDF打包并上传到服务器,将jar包添加到hive的classpath中
hive> add jar /root/function.jar
hive> create temporary function my_concot_str as 'com.qf.ConcatString'; #创建一个自定义的临时函数名
hive > show functions; # 查看我们创建的自定义函数
hive > select my_concot_str("hello") # 使用函数 返回hello!
# 删除自定义函数
hive> drop temporary function if exists my_concot_str;
第二种方式:配置文件加载(只要用hive命令行启动都会加载函数)
1、将编写好的自定函数上传到服务器
2、在hive的安装目录下的bin目录中创建一个文件,文件名为.hiverc
[root@tianqinglong01 hive]#vi ./bin/.hiverc
3、将添加函数的语句写入这文件中
vi $HIVE_HOME/bin/.hiverc
add jar /root/function.jar
create temporary function my_concot_str as 'com.qf.ConcatString'; 4、直接启动hive
jar一般放在lib目录下
以上是关于08-hive中的函数的主要内容,如果未能解决你的问题,请参考以下文章