Hadoop——MapReduce相关eclipse配置及Api调用(图文超详细版)(内含遇到错误的解决方法)
Posted HuiSoul
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop——MapReduce相关eclipse配置及Api调用(图文超详细版)(内含遇到错误的解决方法)相关的知识,希望对你有一定的参考价值。
一、前情提要
前面两篇文章我们已经成功搭建了Hadoop以及安装了Hive,Sqoop和mysql数据库,现在我们就来利用Hadoop尝试做一个小实战,实现单词统计!
还没有搭建Hadoop成功的同学,欢迎看看我之前的文章:Hadoop集群搭建(步骤图文超详细版)
二、前置条件
| 需要安装 | 下载方法 |
|---|---|
| eclipse | 自备 |
| hadoop-eclipse-plugin-2.7.0.jar | 百度网盘下载 , 提取码:f259 |
| MobaXterm | 百度网盘下载,提取码:f64v |
本次将会用到的,HDFS命令大全:Hadoop——HDF的Shell命令,建议大家在操作时看看!!
三、上传文件至HDFS
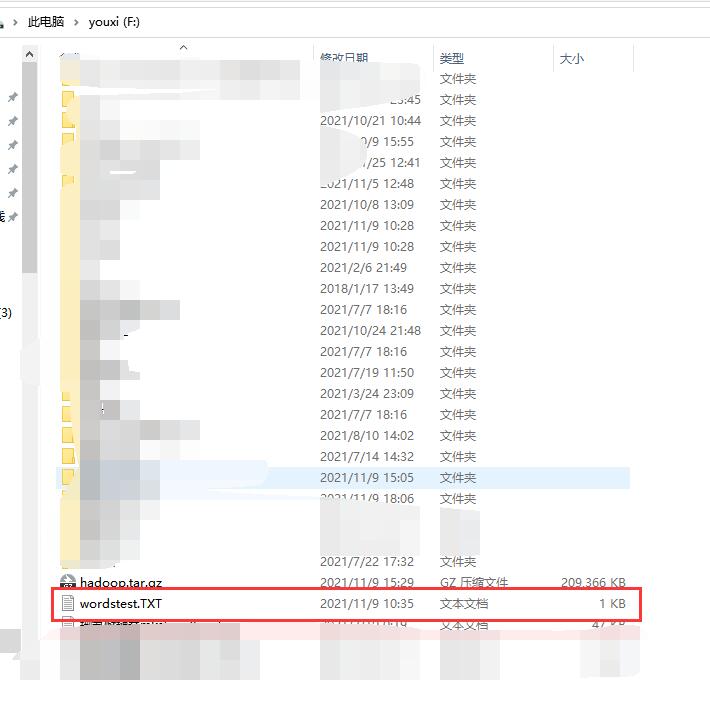
首先,我们需要在Windows准备一个装有英语单词的文本文件↓(不限词数)
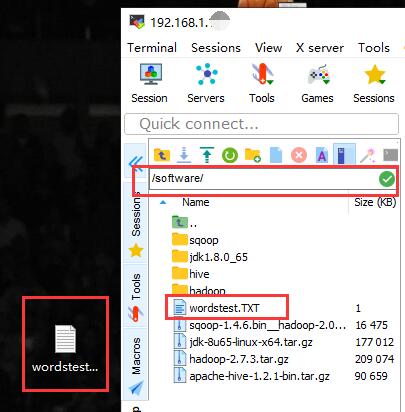
我们利用 MobaXterm 软件将单词文件上传至 Centos 中与 hadoop 文件同目录的 /software,这里大家根据自己文件存放的地方存储就好了,不一定要和我同一个目录↓。
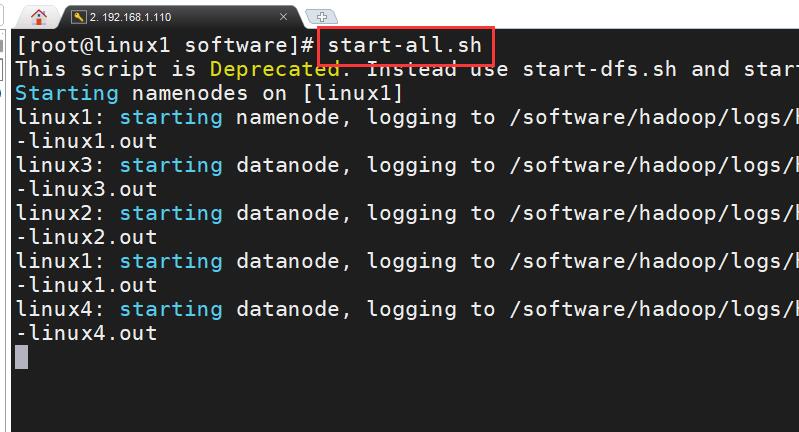
上传至HDFS系统之前我们需要先启动 Hadoop 集群!!
启动 Hadoop 集群命令:start-all.sh
Tips:如果发现这个命令无法在任何目录下使用,请检查全局文件中Hadoop路径!!
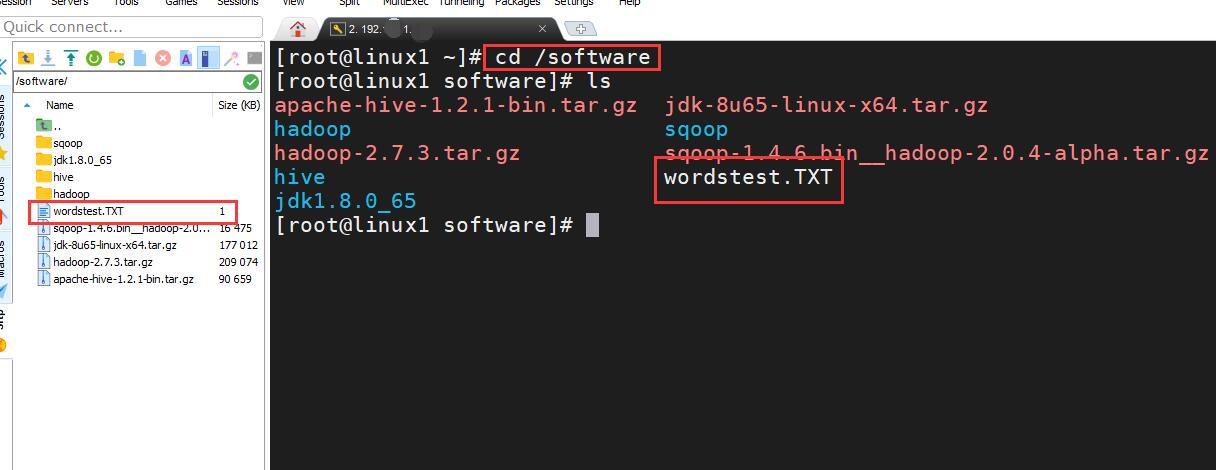
启动集群之后,我们 cd 到存放单词文件的目录下,命令↓
cd /software
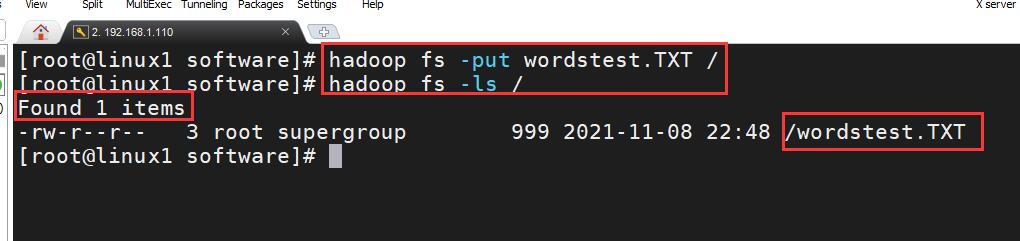
接着我们使用Hadoop的上传文件命令,再用 -ls 命令查看HDFS根目录中的文件,命令↓
hadoop fs -put wordstest.TXT /
hadoop fs -ls
注意!!如果Hadoop集群没有正常启动,将会报以下错误↓

查看上传的wordstest.txt文件内容,命令↓
hdfs dfs -cat /wordstest.TXT
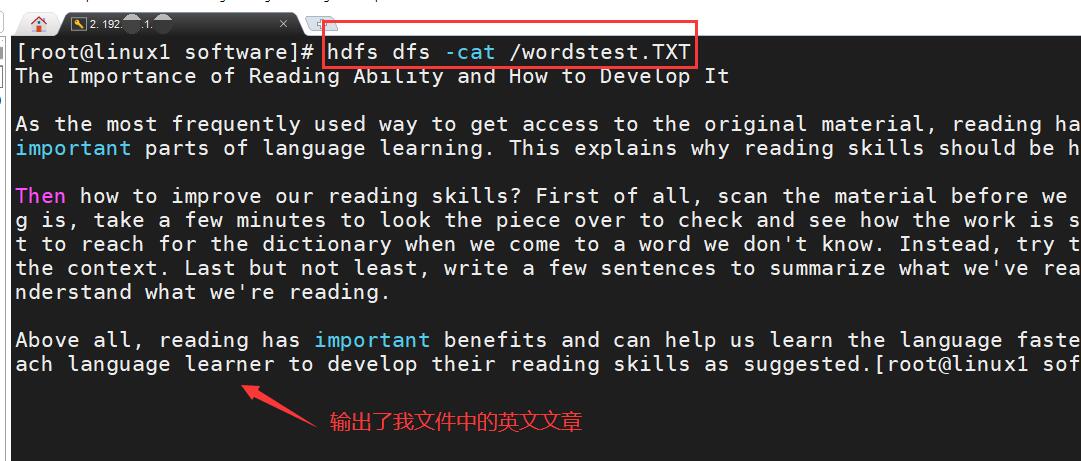
到这,英语单词文件已经上传HDFS成功了!
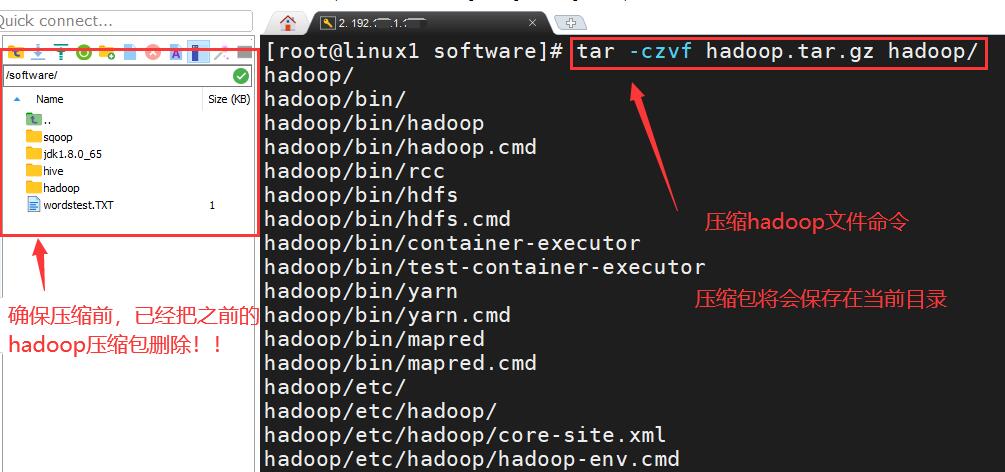
四、压缩Hadoop文件
命令↓
tar -czvf hadoop.tar.gz hadoop/
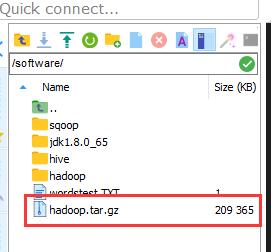
压缩后的hadoop文件↓
从 linux 系统上将 hadoop.tar.gz 压缩包复制到Windows任一常用盘下↓
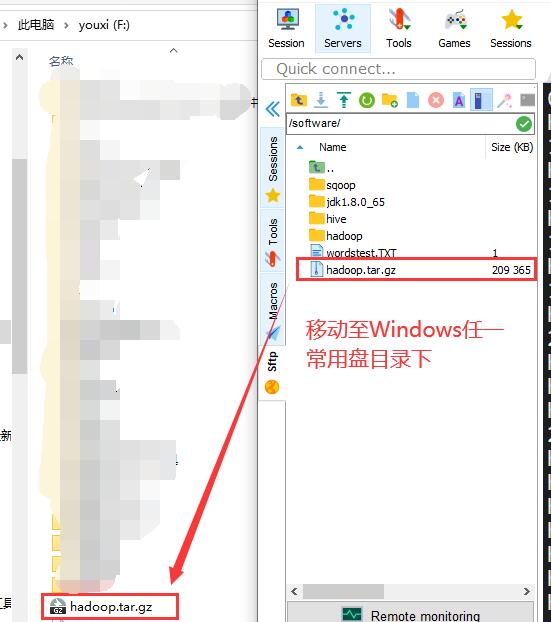
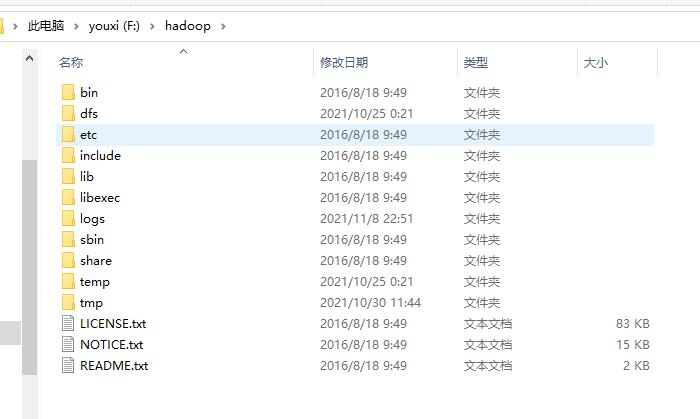
然后把 hadoop 压缩包解压缩↓
五、配置Eclipse
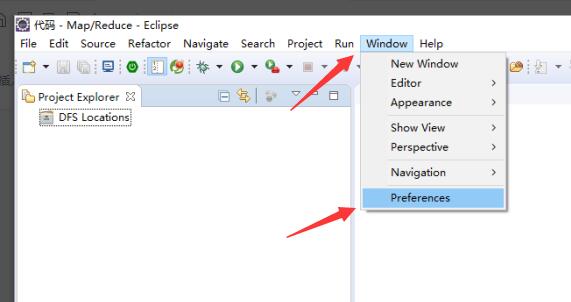
打开 Eclipse,在菜单栏找到 Window,点击里面的 Preferences↓
在左侧找到Hadoop/ Map/Reduce配置,然后选择hadoop文件夹路径↓
Tips:如果 Eclipse没有安装hadoop驱动插件,是不会显示 Hadoop/ Map/Reduce 配置的!!如果发现没有,在文章最上面找到 Eclipse-hadoop-plugin 下载,将插件放在 hadoop 目录下的 plugins 中!

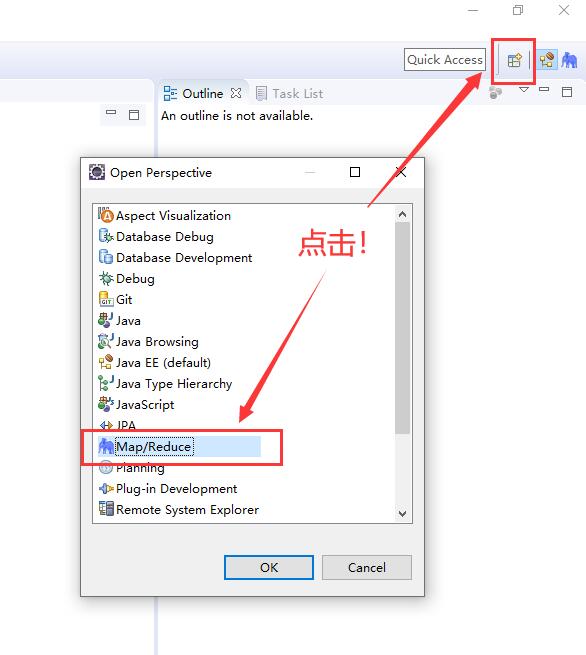
点击 Apply 应用后,点击 OK 回到主页面,在 Eclipse 右上角找到下面这个按钮点击,在里面找到 Map/Reduce视图 并选择 OK ↓,回到主界面就会发现 Map/Reduce 视图替换了之前的视图
在主界面按顺序分别点击 Map/Reduce 和 图标 后,填写一下信息↓
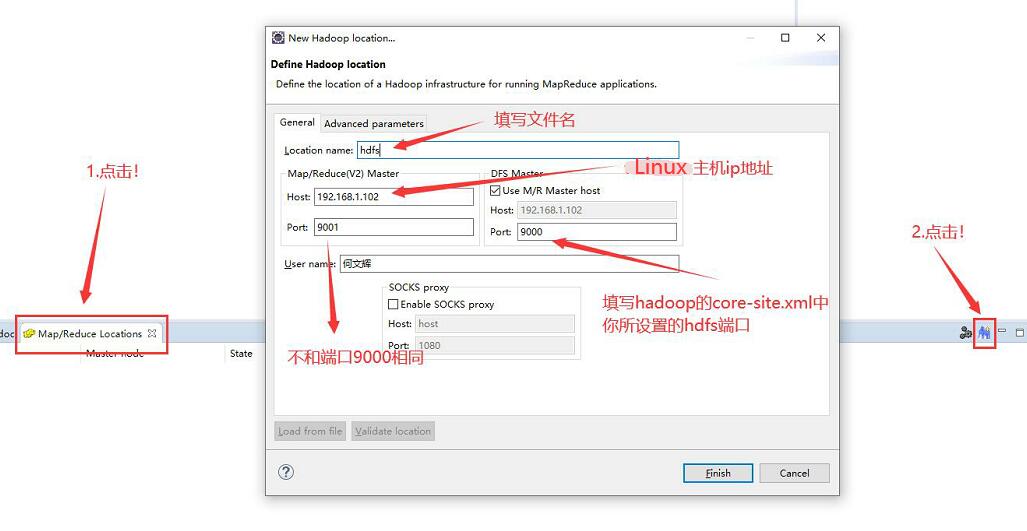
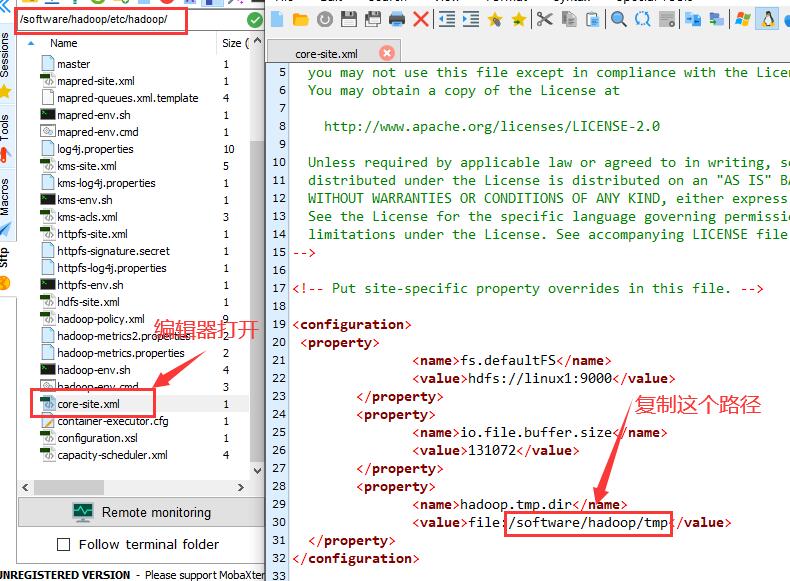
如果忘了设置 的HDFS 端口号,在 hadoop 文件夹的 /etc/hadoop 目录下找到 core-site.xml ,利用编辑器打开查看↓
同时!!我们查看完端口号后,还要复制 hadoop.tmp.dir 的目录路径↓
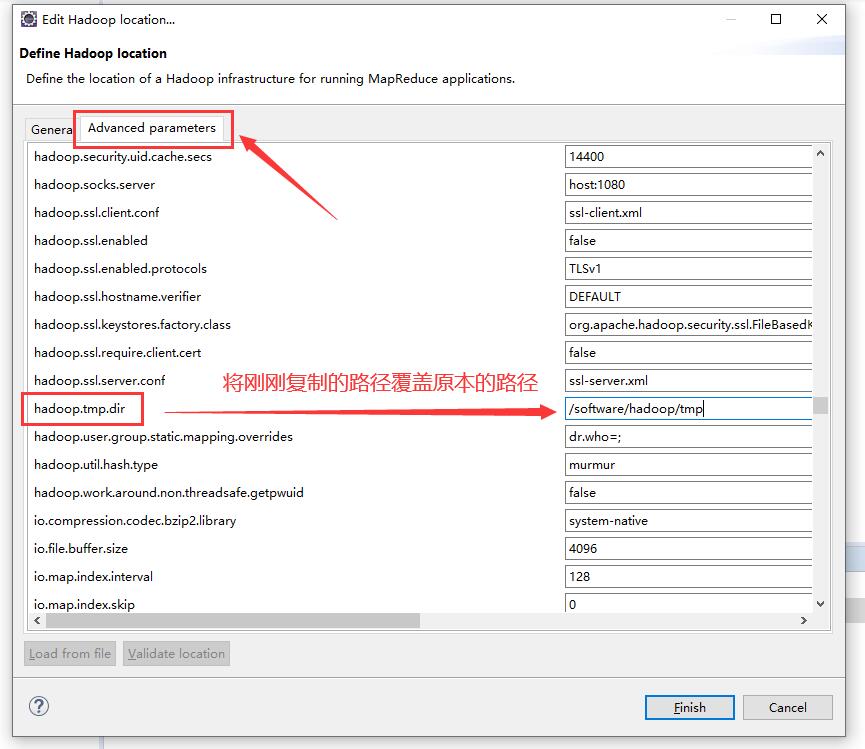
在 Edit Hadoop location 界面来到 Advanced parameters 页面,找到 hadoop.tmp.dir 设置,并把刚刚复制的路径覆盖原本的默认路径↓
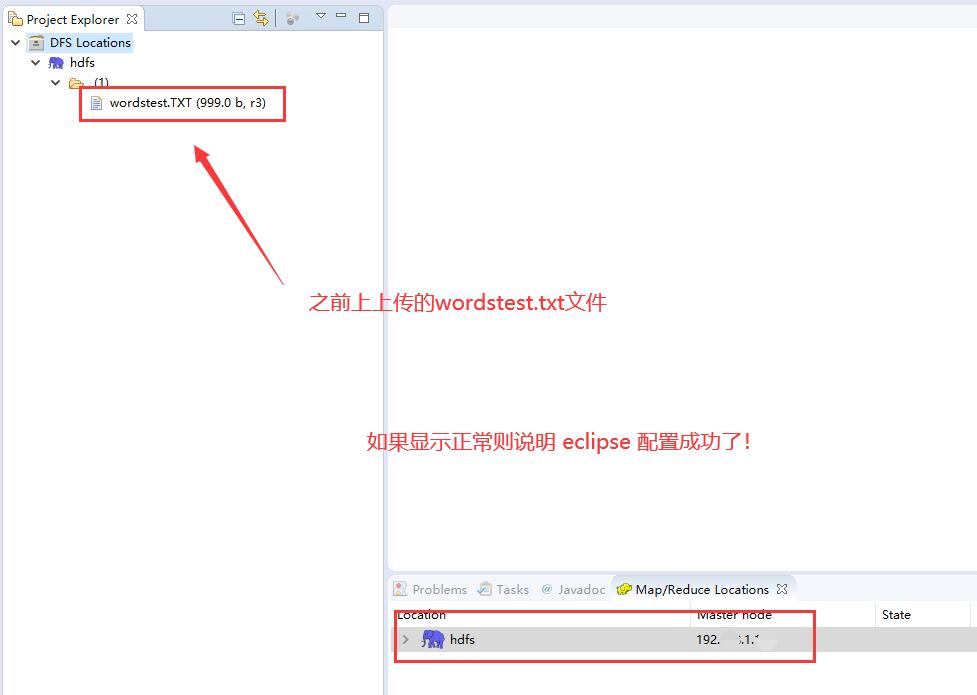
点击 Finish ,然后就可以在主界面左侧的hdfs项目中看到HDFS上的文件结构!
Tips:如果上面项目栏没有正常显示,而是显示了 fail to connect 乱七八糟的,解决方法如下↓
在 linux 的 hadoop 集群中的主节点下,修改 /etc/hosts 文件,将主节点的 ip地址改为 0.0.0.0
再重启网络和hadoop,总命令如下↓stop-all.sh vi /etc/hosts service network restart start-all.sh然后我们再回到 eclipse 中将原来项目删除,再重新建立一个,这时就会发现,哎!竟然成功了哈哈哈!
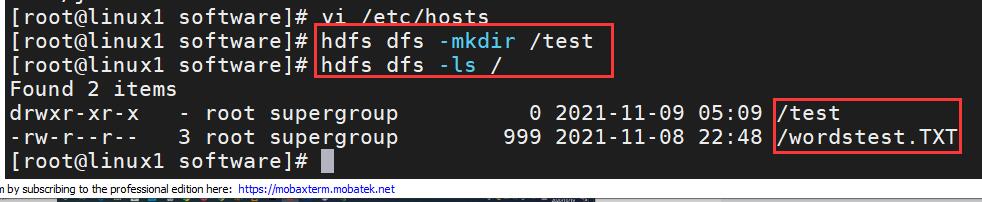
我们来尝试操作一下!在 linux 的主节点中我们试着用命令在 HDFS 中创建一个文件夹↓
然后在 eclipse 中刷新下,就能看到我们创建的 test 文件夹了!
至此,我们的 ecplise 也已经配置成功了!!给点掌声自己!!
六、HDFS调用Api
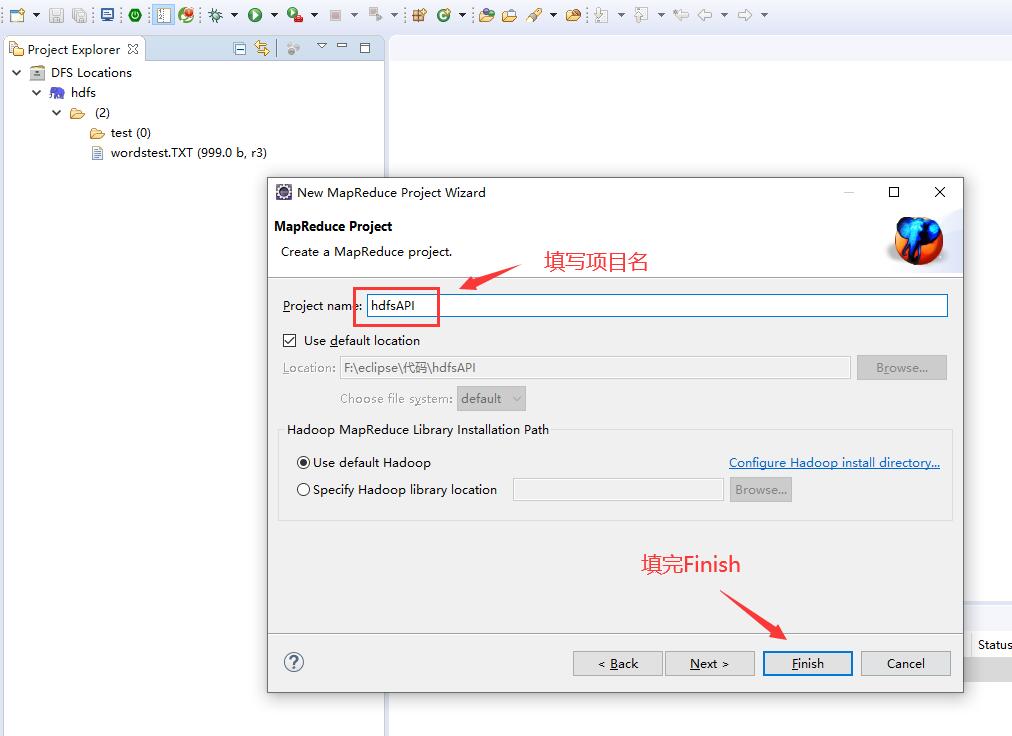
在 eclipse 创建一个 MapReduce 项目↓
在项目的 src 目录下创建包和包下的四个 java 文件:CreateFile(创建文件) 、GetFile(获取文件) 、PutFile(上传文件)、FileLocation(查看文件路径)
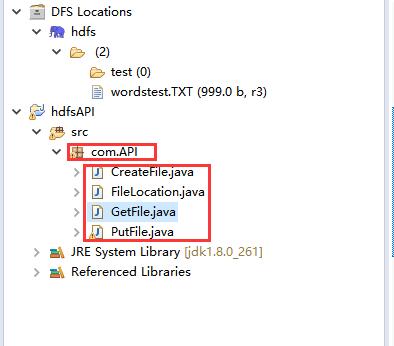
代码如下↓
注意:别忘了修改代码中你们自己的Linux主机IP地址!上传文件名也要选对你们放文件的路径!!
我存放文件的目录↓(以供参考,具体根据你们所定)
PutFile.java(上传文件)↓
package com.API;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
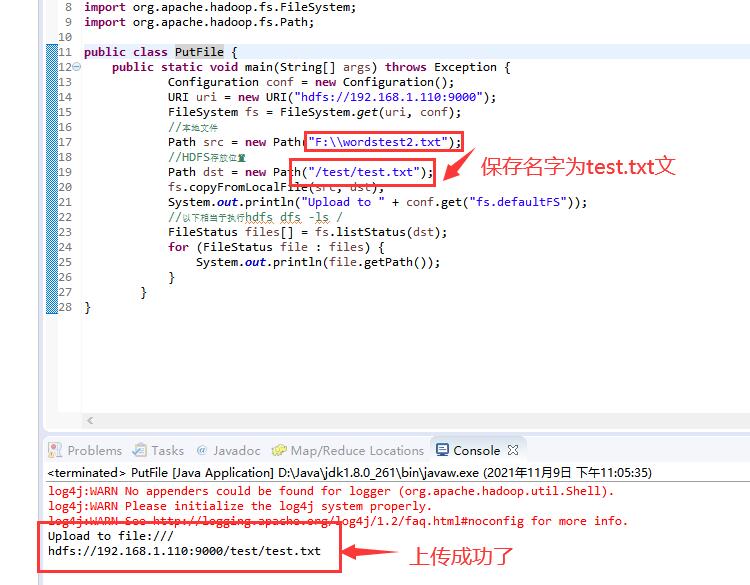
public class PutFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://linux主机IP地址:9000");
FileSystem fs = FileSystem.get(uri, conf);
//本地文件
Path src = new Path("F:\\\\wordstest2.txt");
//HDFS存放位置
Path dst = new Path("/test/test.txt");
fs.copyFromLocalFile(src, dst);
System.out.println("Upload to " + conf.get("fs.defaultFS"));
//以下相当于执行hdfs dfs -ls /
FileStatus files[] = fs.listStatus(dst);
for (FileStatus file : files) {
System.out.println(file.getPath());
}
}
}
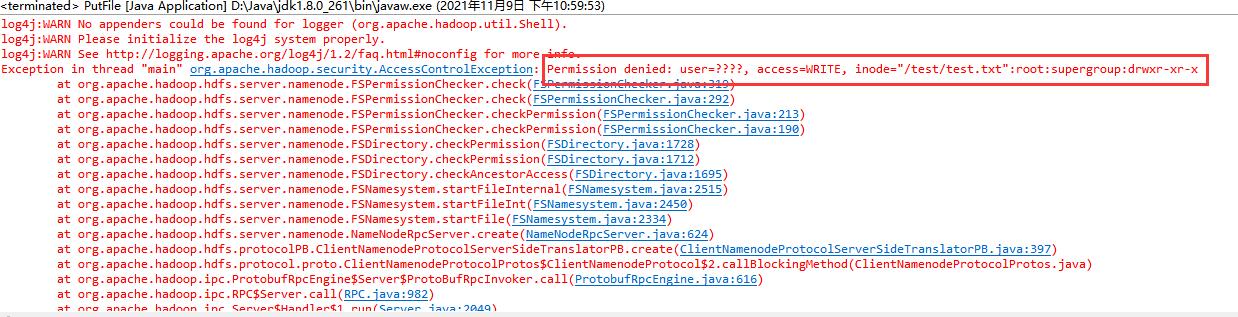
Tips:如果操作会有关于目录的,别忘了给目录加上可修改可读取可执行的权限,如这里就涉及到了/test目录,命令↓
hadoop fs -chmod 777 /文件夹名如果没有添加权限,eclipse报错如下↓
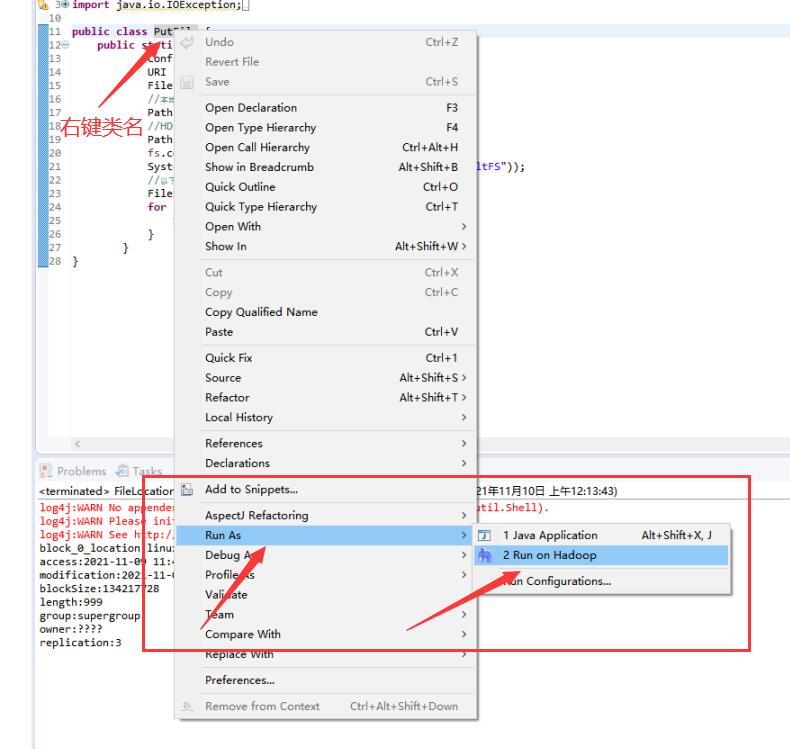
接着我们运行程序,方法如下↓
后面运行程序也是这么个步骤
输出结果↓
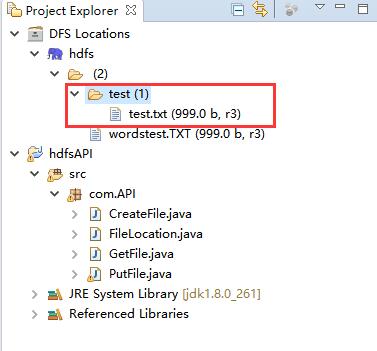
hdfs目录刷新一下,新增的txt文件就显示了
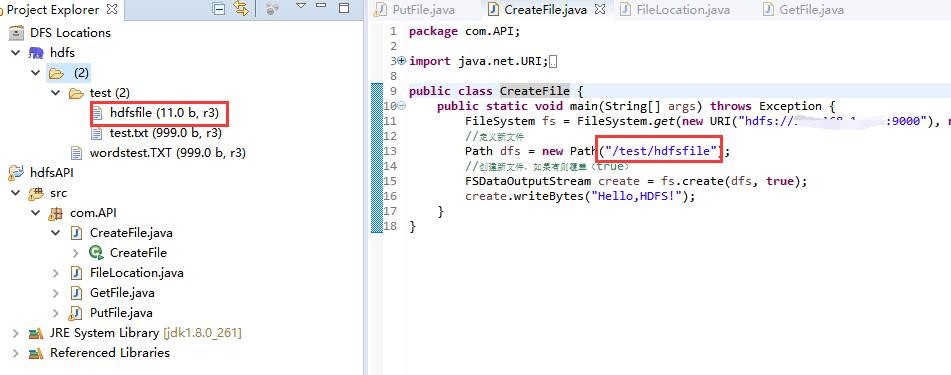
CreateFile.java(创建文件)↓
package com.API;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateFile {
public static void main(String[] args) throws Exception {
FileSystem fs = FileSystem.get(new URI("hdfs://linux主机IP地址:9000"), new Configuration());
//定义新文件
Path dfs = new Path("/test/hdfsfile");
//创建新文件,如果有则覆盖(true)
FSDataOutputStream create = fs.create(dfs, true);
create.writeBytes("Hello,HDFS!");
}
}
运行程序后左边hdfs目录下的test文件夹中多了一个hdfsfile文件↓
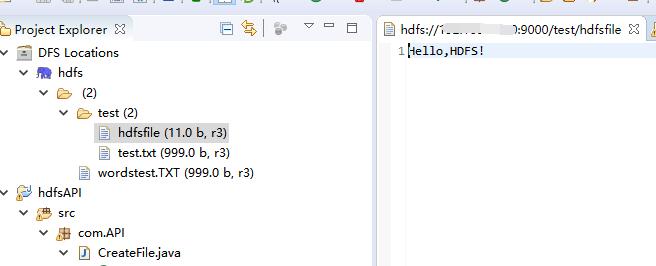
hdfsfile文件内容↓
GetFile.java(获取文件)↓
package com.API;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class GetFile {
public static void main(String[] args) throws Exception{
FileSystem fs = FileSystem.get(new URI("hdfs://linux主机IP地址:9000"), new Configuration());
//hdfs 上文件
Path src = new Path("/test/hdfsfile");
//下载到本地的文件名
Path dst = new Path("D:\\\\test\\\\newfile.txt");
fs.copyToLocalFile(false,src,dst,true);
}
}
运行程序后会选择下载到本地路径的D盘下创建一个test文件夹,并存放我们索要获取文件的副本↓
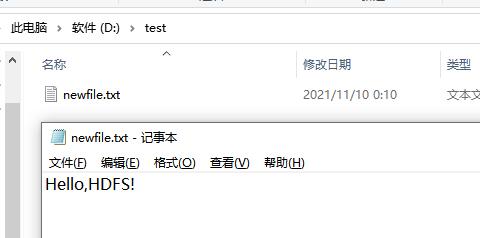
FileLocation.java(查看文件路径)↓
package com.API;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileLocation {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
FileSystem fs = FileSystem.get(new URI("hdfs://linux主机IP地址:9000"), new Configuration());
Path fpath = new Path("/test/test.txt");
FileStatus filestatus = fs.getFileStatus(fpath);
/*获取文件在HDFS集群位置:
* FileSystem.getFileBlockLocations(FileStatus file,long start,long
len);
*可查找指定文件在HDFS集群上的位置,其中file为文件的完整路径,start和len来表识查找的文件路径
*/
BlockLocation[] blkLocations = fs.getFileBlockLocations(filestatus, 0, filestatus.getLen());
filestatus.getAccessTime();
for (int i = 0; i < blkLocations.length; i++) {
String[] hosts = blkLocations[i].getHosts();
System.out.println("block_" + i + "_location:" + hosts[0]);
}
//格式化日期输出
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//获取文件访问时间,返回 long
long accessTime = filestatus.getAccessTime();
System.out.println("access:" + formatter.format(new Date(accessTime)));
//获取文件修改时间,返回long
long modificationTime = filestatus.getModificationTime();
System.out.println("modification:" + formatter.format(new Date(modificationTime)));
//获取块的大小,单位为B
long blockSize = filestatus.getBlockSize();
System.out.println("blockSize:" + blockSize);
//获取文件大小,单位为B
long len = filestatus.getLen();
System.out.println("length:" + len);
//获取文件所在用户组
String group = filestatus.getGroup();
System.out.println("group:" + group);
//获取文件拥有者
String owner = filestatus.getOwner();
System.out.println("owner:" + owner);
//获取文件拷贝数
short replication = filestatus.getReplication();
System.out.println("replication:" + replication);
}
}
运行程序后,输出包括访问时间、修改时间、文件长度、所占块大小、文件拥有者、文件用户组和文件复制数等信息↓
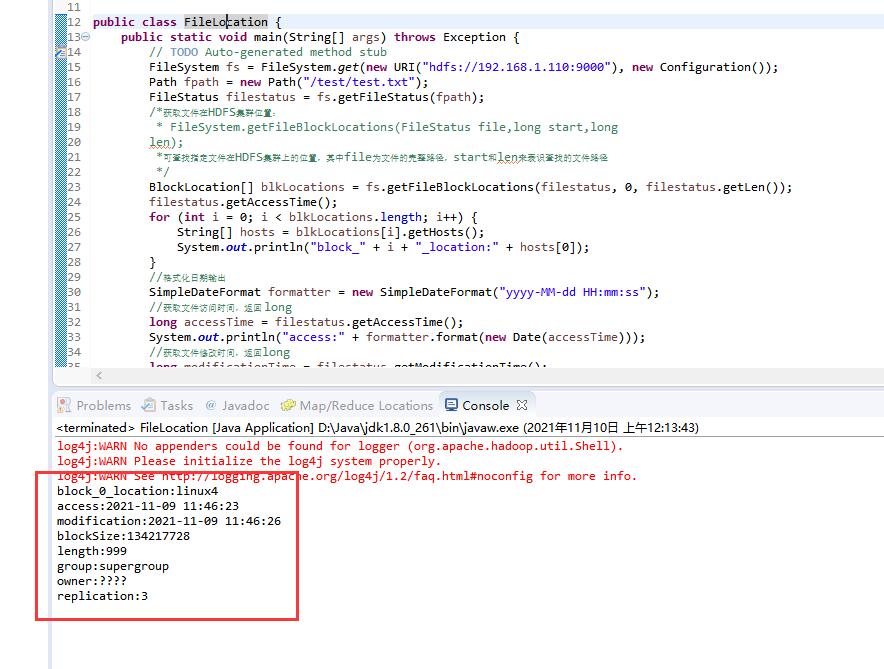
本次分享到此结束,谢谢大家阅读!!
欢迎大家看看我下一篇MapReduce——单词统计:Hadoop——MapReduce实现单词统计(图文超详细版)
以上是关于Hadoop——MapReduce相关eclipse配置及Api调用(图文超详细版)(内含遇到错误的解决方法)的主要内容,如果未能解决你的问题,请参考以下文章