Hive分桶操作(Bucket)一图掌握核心内容
Posted 万家林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive分桶操作(Bucket)一图掌握核心内容相关的知识,希望对你有一定的参考价值。
什么是分桶?:
Hive基于hash值对数据进行分桶,按照分桶字段的hash值除以分桶的个数进行取余(bucket_id = column.hashcode % bucket.num)。
分桶的作用:
1、有更高的查询处理效率
2、使得抽样更高效
如何分桶?:
1、分桶之前需要执行命令set hive.enforce.bucketing=true;
2、创建分桶表
首先先创建一个普通表用于给分桶表传数据
create table employee_id(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\\n';
分桶表创建:
create table employee_id_buckets(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
#创建两个桶
clustered by(employee_id) into 2 buckets
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\\n';
执行命令set map.reduce.tasks=2;
将employee_id数据写入到分桶表employee_id_buckets。
insert overwrite table employee_id_buckets select * from employee_id;
分桶表创建完成。
一图看懂分桶核心操作:
分完桶之后,要去查看数据,命令为(注意关键字是tablesample)
select * from employee_id_buckets tablesample(bucket 1 out of 4 on employee_id)s;
核心代码:bucket X out of Y on employee_id
上面我们创建分桶时是创建了2个桶,这边的Y必须是创建的桶数的因子或者是整数倍,也就是说Y%2==0。
X指的是查询Y中第几个的桶的数据。接下来上图片!!
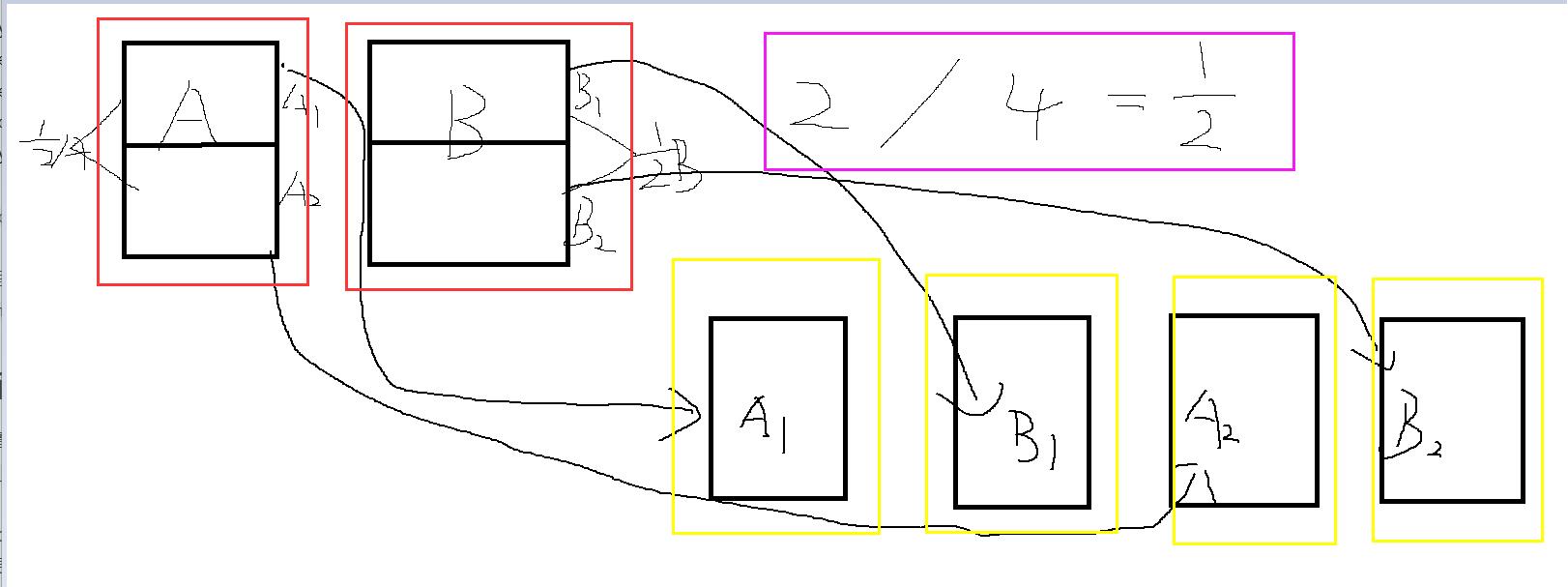
图片些许有点潦草,但是大概能看懂意思。
这边Y是4,也就是2的2倍,但是我们分桶是分了2个桶,所以我们这边一块数据就是1/2,按照顺序排列开来就是A1,B1,A2,B2,这边X是1,所以查询的是A1的数据,也就是A桶的一半的数据。
以上是关于Hive分桶操作(Bucket)一图掌握核心内容的主要内容,如果未能解决你的问题,请参考以下文章