个人分享天池数据达人赛:汽车产品聚类分析
Posted 广外唯稳办
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了个人分享天池数据达人赛:汽车产品聚类分析相关的知识,希望对你有一定的参考价值。
纯个人分享,若方法、代码有不当之处,请多批评指正。
本赛题以竞品分析为背景,通过数据的聚类,为汽车提供聚类分类。对于指定的车型,可以通过聚类分析找到其竞品车型。通过这道赛题,鼓励参赛者利用车型数据,进行车型画像的分析,为产品的定位,竞品分析提供数据决策。
首先是常规操作,加载第三方库。
# 加载第三方库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
from sklearn.cluster import KMeans
# 统一量纲
from sklearn.preprocessing import MinMaxScaler as mms
# 根据轮廓系数选择合适的 n_clusters
from sklearn.metrics import silhouette_score
把数据读进来看看长什么样子。
# 读取数据
path = r'D:\\汽车产品聚类分析\\car_price.csv'
data = pd.read_csv(path)
data.head()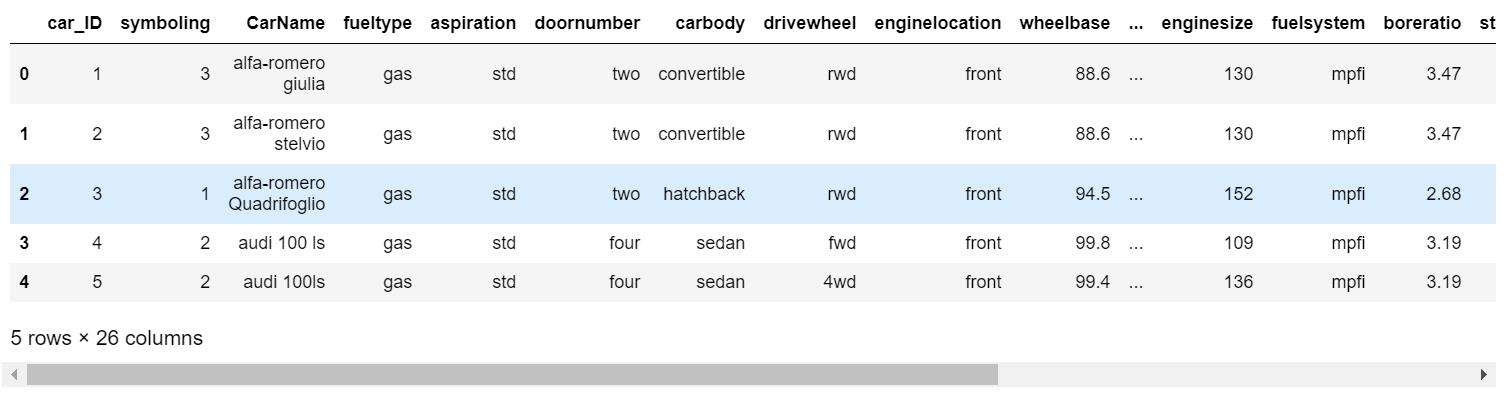
一共有26个字段,先看看各字段的数据类型、是否有空值。
# 查看字段的数据类型、空值
# 结果显示无空值
data.info()
赛题要求找出大众汽车的竞品,因此先对品牌字段做洞察、清洗。
# 查看品牌字段的值
data['CarName'].unique()
发现品牌字段有很多不规则命名,对其进行替换,顺便看看替换后的效果。
# 替换品牌字段的不规则命名
data['CarName'] = data['CarName'].replace({'audi 100 ls':'audi 100ls',
'vokswagen rabbit':'volkswagen rabbit',
'vw dasher':'volkswagen dasher',
'vw rabbit':'volkswagen rabbit'})
data['CarName'].unique()
是否需要去除重复值呢?
# 是否有必要做去除重复值的操作(结果:没必要)
data.drop_duplicates().shape == data.shape
# 结果:True
分类型变量不适合做聚类分析,先把它们转换成哑变量。
# 需要转哑变量的字段
# lst_1 是字符型的变量,lst_2 是非字符型的变量
lst_1 = ['fueltype','aspiration','doornumber','carbody',
'drivewheel','enginelocation','enginetype','cylindernumber','fuelsystem']
lst_2 = ['symboling']
# 转换为字符类型
data[lst_2] = data[lst_2].astype(str)
# 删除原转码的字段,合并得到新表
data_1 = pd.get_dummies(data[lst_1 + lst_2])
data_2 = data.drop(columns = lst_1 + lst_2)
data_3 = pd.concat([data_1,data_2],axis = 1)
汽车ID、汽车品牌名不是汽车的属性,就不作为聚类的依据了。
# 删除不是汽车属性的字段
data_new = data_3.drop(columns = ['car_ID','CarName'])
各字段的量纲不一,先做归一化再做聚类。
# 归一化,统一量纲
MMS_01 = mms().fit(data_new)
data_01 = MMS_01.transform(data_new)
data_02 = pd.DataFrame(data_01,columns=data_new.columns)
看看转码、归一化后的表格长什么样子。
# 转码、归一化后的表格
data_02.head()
好了,数据清洗完毕,现在正式开始用 KMeans 做聚类。
最大的问题在于,如何选择最合适的参数 n_clusters。这里采用轮廓系数作为依据,目的是使簇外差异与簇内差异的两者之差最大。
# 绘制 n_clusters 和 所有样本的平均轮廓系数 的关系图
score = []
for i in range(2,21):
cluster = KMeans(n_clusters = i,random_state = 0).fit(data_02)
score.append(silhouette_score(data_02,cluster.labels_))
plt.plot(range(2,21),score)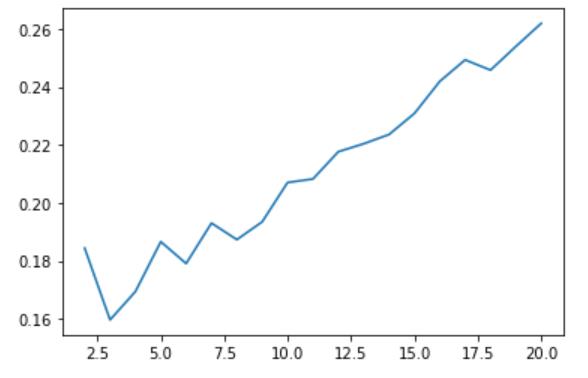
肉眼可见,轮廓系数与 n_clusters 正相关,但 n_clusters 并非越大越好,这里就粗略地选择【2,20】中轮廓系数最大的 n_clusters 吧。
# 找出平均轮廓系数最高时对应的 n_clusters:20
plt.axvline(pd.DataFrame(score).idxmax()[0]+2,ls=':')
最合适的参数也找到了,开始应用 KMeans。
# 应用 KMeans 进行聚类
n = pd.DataFrame(score).idxmax()[0]+2
cluster = KMeans(n_clusters = n,random_state = 0).fit(data_02)
y_pred = cluster.labels_
y_pred
至此,各汽车产品聚类完成,最后看看各分类的车型数量。
# 得到分类完成后的完整信息表
car = data_3[['car_ID','CarName']]
label = pd.Series(y_pred)
data_03 = pd.concat([car,data_02],axis = 1)
data_03['label'] = label
# 查看各分类的车型数量
data_03['label'].value_counts()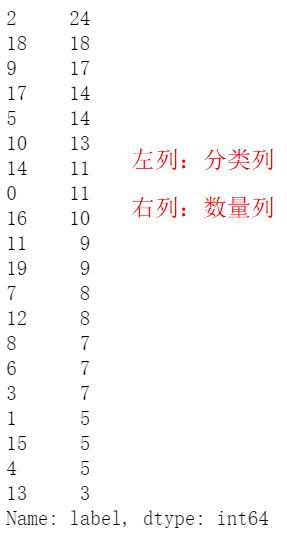
以上是关于个人分享天池数据达人赛:汽车产品聚类分析的主要内容,如果未能解决你的问题,请参考以下文章
ML之kmeans:通过数据预处理(分布图箱线图热图/文本转数字/构造特征/编码/PCA)利用kmeans实现汽车产品聚类分析(SSE-平均轮廓系数图/聚类三维图/雷达图/饼图柱形图)/竞品分析之详细
数据挖掘机器学习[二]---汽车交易价格预测详细版本{EDA-数据探索性分析}
数据挖掘机器学习[五]---汽车交易价格预测详细版本{模型融合(StackingBlendingBagging和Boosting)}