大数据运维:datanode启动后挂了Initialization failed for Block pool <registering>
Posted 涤生手记大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据运维:datanode启动后挂了Initialization failed for Block pool <registering>相关的知识,希望对你有一定的参考价值。
1.案发现场还原
datanode节点因为坏盘,机器卡死掉线,datanode退役。把坏盘目录去掉后,重启datanode后,出现运行一会后dn自动挂掉的情况。
查看日志报错如下:
1月 8, 上午10点26:12.689 WARN org.apache.hadoop.hdfs.server.common.Storage
Failed to analyze storage directories for block pool BP-465426754-10.5.32.151-1456251355718
java.io.IOException: BlockPoolSliceStorage.recoverTransitionRead: attempt to load an used block storage: /hadoop8/dfs/dn/current/BP-465426754-10.5.32.151-1456251355718
at org.apache.hadoop.hdfs.server.datanode.BlockPoolSliceStorage.loadBpStorageDirectories(BlockPoolSliceStorage.java:212)
at org.apache.hadoop.hdfs.server.datanode.BlockPoolSliceStorage.recoverTransitionRead(BlockPoolSliceStorage.java:244)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:477)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1424)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1385)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:228)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:829)
at java.lang.Thread.run(Thread.java:745)
11月 8, 上午10点26:12.690 WARN org.apache.hadoop.hdfs.server.common.Storage
Failed to add storage for block pool: BP-465426754-10.5.32.151-1456251355718 : BlockPoolSliceStorage.recoverTransitionRead: attempt to load an used block storage: /hadoop8/dfs/dn/current/BP-465426754-10.5.32.151-1456251355718
11月 8, 上午10点26:12.690 INFO org.apache.hadoop.hdfs.server.common.Storage
Storage directory [DISK]file:/hadoop9/dfs/dn/ has already been used.
11月 8, 上午10点26:12.722 INFO org.apache.hadoop.hdfs.server.common.Storage
Analyzing storage directories for bpid BP-465426754-10.5.32.151-1456251355718
11月 8, 上午10点26:12.722 WARN org.apache.hadoop.hdfs.server.common.Storage
Failed to analyze storage directories for block pool BP-465426754-10.5.32.151-1456251355718
java.io.IOException: BlockPoolSliceStorage.recoverTransitionRead: attempt to load an used block storage: /hadoop9/dfs/dn/current/BP-465426754-10.5.32.151-1456251355718
at org.apache.hadoop.hdfs.server.datanode.BlockPoolSliceStorage.loadBpStorageDirectories(BlockPoolSliceStorage.java:212)
at org.apache.hadoop.hdfs.server.datanode.BlockPoolSliceStorage.recoverTransitionRead(BlockPoolSliceStorage.java:244)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:477)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1424)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1385)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:228)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:829)
at java.lang.Thread.run(Thread.java:745)
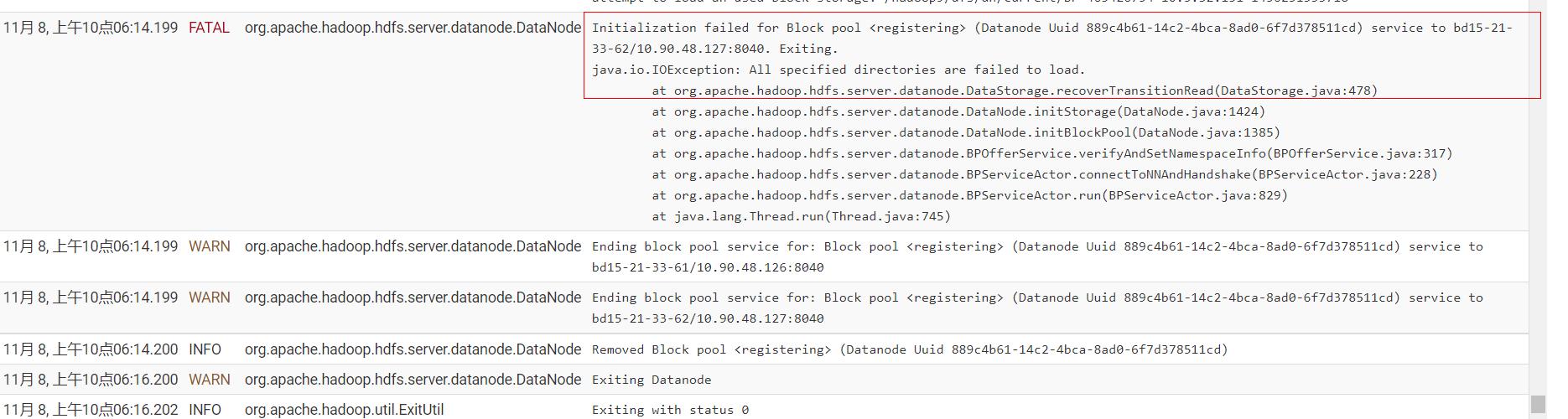
核心最后fetal报错如下,dn服务停止:
11月 8, 上午10点26:12.723 WARN org.apache.hadoop.hdfs.server.common.Storage
Failed to add storage for block pool: BP-465426754-10.5.32.151-1456251355718 : BlockPoolSliceStorage.recoverTransitionRead: attempt to load an used block storage: /hadoop9/dfs/dn/current/BP-465426754-10.5.32.151-1456251355718
11月 8, 上午10点26:12.723 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode
Initialization failed for Block pool <registering> (Datanode Uuid 889c4b61-14c2-4bca-8ad0-6f7d378511cd) service to bd15-21-33-62/10.90.48.127:8040. Exiting.
java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:478)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1424)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1385)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:228)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:829)
at java.lang.Thread.run(Thread.java:745)
11月 8, 上午10点26:12.723 WARN org.apache.hadoop.hdfs.server.datanode.DataNode
Ending block pool service for: Block pool <registering> (Datanode Uuid 889c4b61-14c2-4bca-8ad0-6f7d378511cd) service to bd15-21-33-62/10.90.48.127:8040
11月 8, 上午10点26:12.723 INFO org.apache.hadoop.hdfs.server.datanode.DataNode
Removed Block pool <registering> (Datanode Uuid 889c4b61-14c2-4bca-8ad0-6f7d378511cd)
11月 8, 上午10点26:14.724 WARN org.apache.hadoop.hdfs.server.datanode.DataNode
Exiting Datanode
11月 8, 上午10点26:14.726 INFO org.apache.hadoop.util.ExitUtil
Exiting with status 0
11月 8, 上午10点26:14.729 INFO org.apache.hadoop.hdfs.server.datanode.DataNode
SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at bd15-21-131-85/10.21.131.85
************************************************************/
2. 分析解决
因为这种是一个大类报错,抛出的异常
排查1: namenode 和 datanode 集群 ID 不匹配?
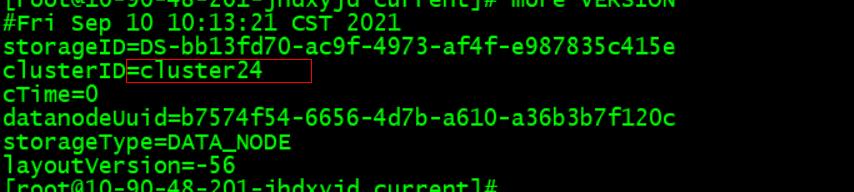

仔细查看了异常节点的所有数据盘符下的clusterid和namenode的ClusterID发现并没有不同,排除此方法。
尖叫提示:
注意,这种clusterID不一致的情况,一般是是集群namenode 格式化时才会出现的情况,比如集群下线了一个节点,然后重新格式化namenode,再把已经下线的节点上线集群,发现报错,clusterid不一致(因为格式化集群会重新分配clusterid),这种clusterid不一致的一般是小白学习中才会出现的,生产集群你给我格式化namenode看看,老板会让你怀疑人生,牢底坐穿。
所以这种解决方式比如重新格式化namenode,格式化集群肯定可以解决问题,但是不具有实际实操意义。跟你重装一下集群一个道理,简单粗暴没啥意义。
排查2: uuid不一致的问题?
其实一般不会有这种问题,比如uuid不一致等。
排查3:磁盘数据目录有异常,读取数据异常,造成整个节点挂了。
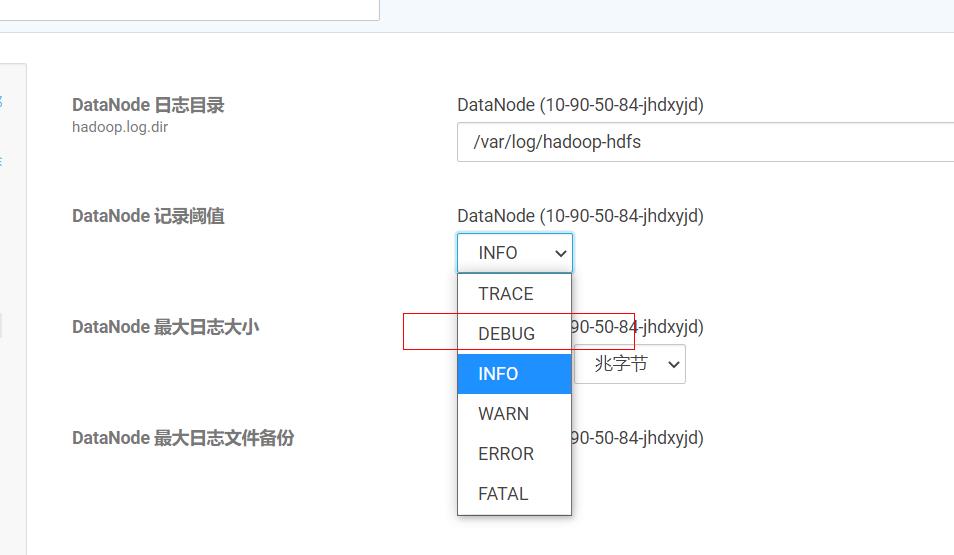
开启日志的debug模式,查看详细信息,慎用,因为会有大量日志,记得关闭
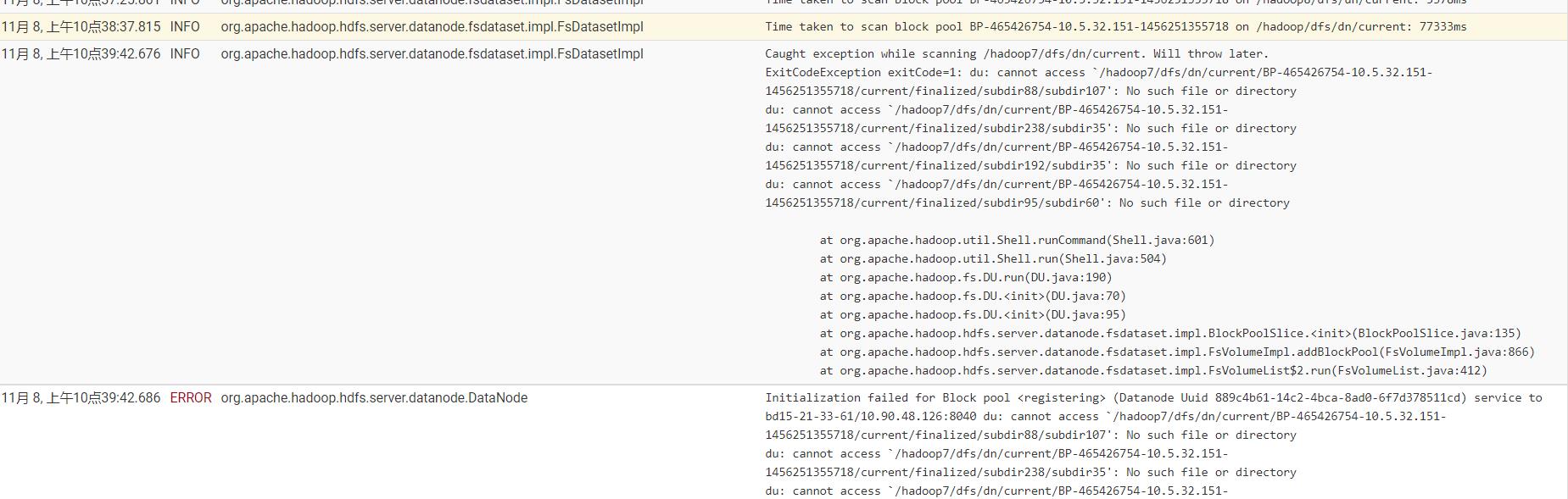
日志查看是/hadoop7数据目录有问题,进入查看,
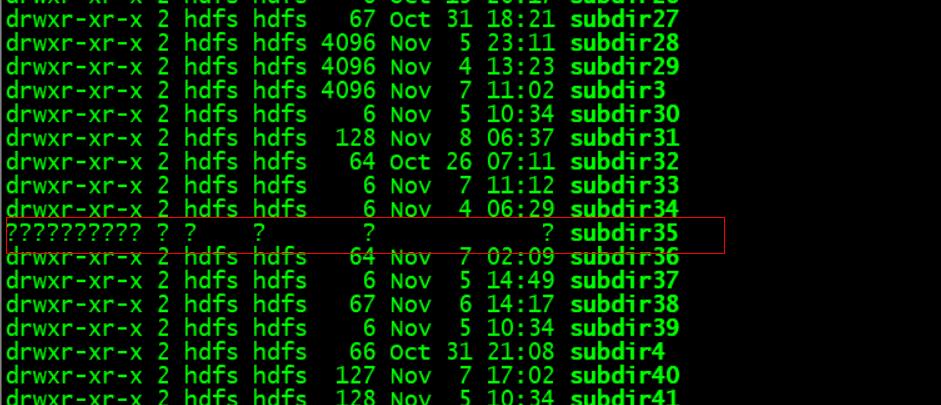
问题解决:
发现hadoop7目录下有个数据目录权限异常,造成加载失败,造成整个dn加载失败,无法注册。首先把/hadoop7目录直接从datanode的data_dir中删除。重新启动dn即可。
尖叫提示:
有时候报错只是一个大类的报错,抛出的异常,诱因有可能有多种。所以这个时候去查看详细的日志,debug日志,看日志从哪里开始异常的,逐步排查,而不是直接查看fetal失败的日志去百度,大类报错很难百度到问题。生产集群一个大类报错往往有很多种诱因造成,排查是个细致活,尽可能查看详细的日志。

以上是关于大数据运维:datanode启动后挂了Initialization failed for Block pool <registering>的主要内容,如果未能解决你的问题,请参考以下文章