GAN简介
Posted ^_^|
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GAN简介相关的知识,希望对你有一定的参考价值。
Introduction of Generative Models
我们已经学到各式各样的,network架构,可以处理不同的X 不同的Y

接下来我们要进入一个新的主题,这个新的主题是要把network,当做一个generator来用,我们要把network拿来做生成使用
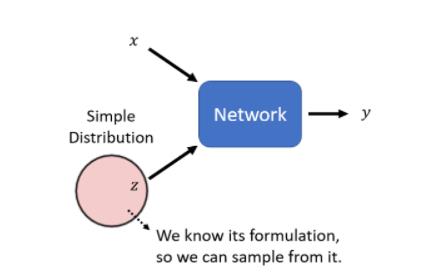
那把network拿来,当作generator使用,他特别的地方是现在network的输入,会加上一个random的variable,会加上一个Z **

这个Z,是从某一个,distribution sample出来的,所以现在network它不是只看一个固定的X得到输出,它是同时看X跟Z得到输出**
network怎么同时看X跟Z,有很多不同的做法,就看你怎样设计你的network架构,我们后续会有讨论
Z特别的地方是它是不固定的,每一次我们用这个network的时候,都会随机生成一个Z,所以Z每次都不一样,它是从一个distribution裡面,sample出来的
这个distribution,这边有一个限制是,它必须够简单,够简单的意思是,我们知道它的式子长什麼样子,我们可以从这个distribution,去做sample
我们一般可能会用normal distribution,但实际上经验看来不同的distribution之间的差异,可能并没有真的非常大,不过你还是可以找到一些文献,试著去探讨不同的distribution之间,有没有差异
所以每次今天,有一个X进来的时候,你都从这个distribution,裡面做一个sample,然后得到一个output,随著你sample到的Z不同,Y的输出也就不一样,所以这个时候我们的network输出,不再是单一一个固定的东西,而变成了一个复杂的distribution,同样的X作為输入,我们这边每次sample到,不一样的东西,通过一个复杂的network转换以后,它就会变成一个复杂的分布,你的network的输出,就变成了一个distribution
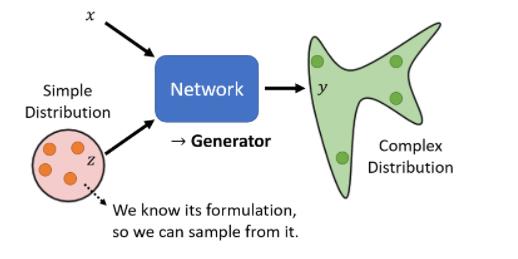
这种可以输出一个distribution的network,我们就叫它generator
Why distribution
在讲怎么训练出generator之前,我们第一个想要回答的问题是,为什么我们需要generator输出是一个分布?输入X输出Y,这样固定的输入跟输出关係不好吗?
那什么时候我们会特别需要,处理这种问题,什么时候,我们会特别需要这种,generator的model,当我们的任务需要一点创造力的时候
任务需要一点创造力这件事情,是比较拟人化的讲法,更具体一点的讲法就是,我们想要找一个function,同样的输入有多种可能的输出,而这些不同的输出都是对的
举例来说假设你选择你的Z,是一个比如说,binary的random variable,它就只有0跟1 那可能各佔50%,也许你的network就可以学到说,Z sample到1的时候就向左转,Z sample到0的时候就向右转,就可以解决,这个世界有很多不可预测的东西,的状况
GeneratIve Adversarial Network(GAN)
generative的model,其中一个非常知名的,就是generative adversarial network,它的缩写 是GAN,那我们这一堂课主要就是介绍,generative adversarial network,发音就是 gàn
Generator
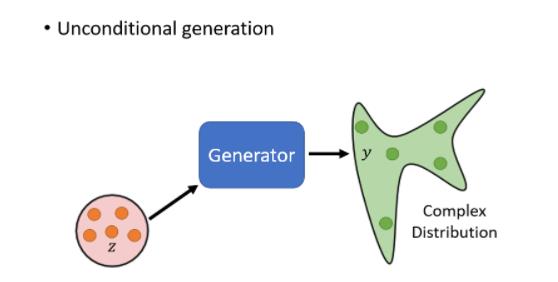
我们现在要举的例子,就是要让机器生成动画人物的,二次元人物的脸,我们举的例子是Unconditional的generation,unconditional generation,就是我们这边先把X拿掉
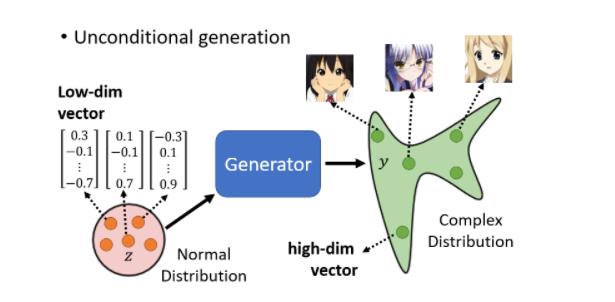
我们都假设Z是从一个normal distribution里sample出来的向量,那这个向量通常会是一个,low-dimensional的向量,它的维度其实是你自订的,你自己决定的,那通常你就订个50100,的大小,它是你自己决定的
好你从这边Z,你从这个normal distribution,裡面sample一个向量以后,丢到generator裡面,Generator就给你一个对应的输出,那我们希望对应的输出,就是一个二次元人物的脸
那到底generator要输出怎么样的东西,才会变成一个二次元人物的人脸,其实这个问题没有你想象的那么难
一张图片就是一个非常高维的向量,所以generator实际上做的事就是产生一个非常高维的向量。举例来说,假设这是一个 64 × 64 64\\times64 64×64的彩色图片,那你的generator输出就是 64 × 64 × 3 64\\times64\\times3 64×64×3那么长的向量,把那个向量整理一下,就变成一张二次元人物,这就是generator要做的事
当你输入的向量不同的时候,你的输出就会跟著改变,所以你从这个,normal distribution裡面,Sample Z出来 Sample到不同的Z,那你输出来的Y都不一样,那我们希望说不管你这边sample到什麼Z,输出来的都是动画人物的脸
Discriminator
在GAN裡面,一个特别的地方就是,除了generator以外,我们要多训练一个东西,叫做discriminator
discriminator它的作用是,它会拿一张图片作为输入,它的输出是一个数值,这个discriminator本身,也是一个neural network,它就是一个function
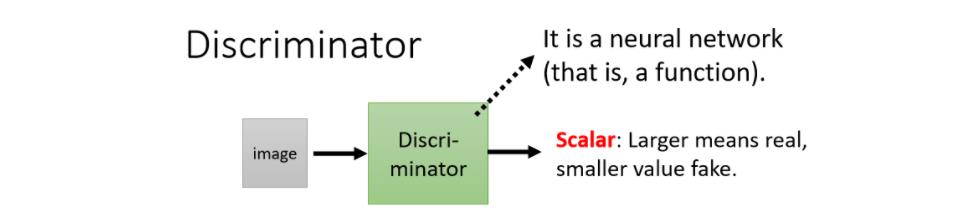
它输入一张图片,它的输出就是一个数字,它输出就是一个scalar,这个scalar越大就代表说,现在输入的这张图片,越像是真实的二次元人物的图像
至于discriminator的neural network的架构,这也完全是你自己设计的,所以generator它是个neural network,Discriminator,也是个neural network,他们的架构长什麼样子,你完全可以自己设计,你可以用CNN,你可以用transformer ,只要你能够产生出你要的输入输出,就可以了
那在这个例子里面,像discriminator,因為输入是一张图片,你很显然会选择CNN对不对,CNN在处理影像上有非常大的优势,既然输入是一张图片,那你的discriminator很有可能,里面会有大量的CNN的架构,那至于实际上要用什么样的架构,完全可以自己决定
Basic Idea of GAN
我们还是以刚刚生成二次元头像为例
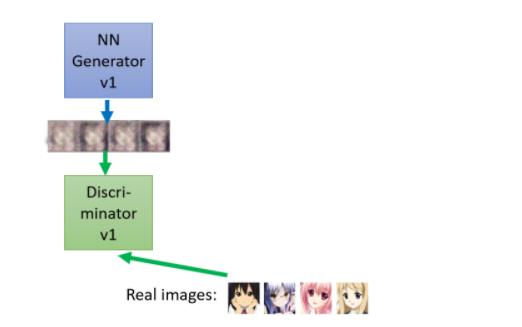
第一代的generator它的参数几乎是,它的参数完全是随机的,所以它根本就不知道,要怎麼画二次元的人物,所以它画出来的东西就是一些莫名其妙的杂讯
那discriminator接下来,它学习的目标是要分辨generator的输出跟真正的图片的不同,那在这个例子里面可能非常的容易,对 discriminator 来说它只要看说,图片里面有没有两个黑黑的圆球,就是眼睛,有眼睛就是真正的二次元人物,没有眼睛就是generator产生出来的东西
接下来generator就调整它的裡面的参数,Generator就进化了,它调整它裡面的参数 它调整的目标,是為了要骗过discriminator,假设discriminator,判断一张图片是不是真实的依据,看的是有没有眼睛,那generator就產生眼睛出来,给discriminator看
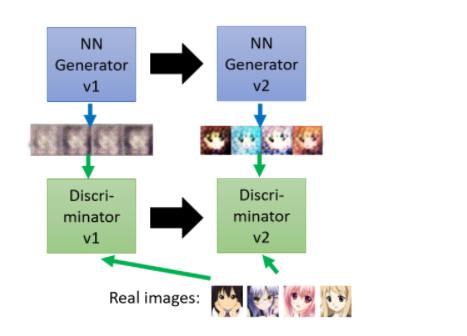
所以 generator 产生眼睛出来,然后他可以骗过第一代的, discriminator,但是discriminator也是会进化的,所以第一代的 discriminator,就变成第二代的 discriminator,第二代的 discriminator,会试图分辨这一组图片,跟真实图片之间的差异,它会试图去找出这两者之间的差异
他发现说,这边产生的图片都是比较简单的,举例来说 generator 出来的图片都没有头发也没有嘴巴,而我们的图片是有头发的也有嘴巴
接下来第三代的generator就会想办法去骗过第二代的 discriminator,既然第二代的 discriminator 是看有没有嘴巴来判断是不是真正的二次元人物,那第三代的 generator 就会把嘴巴加上去
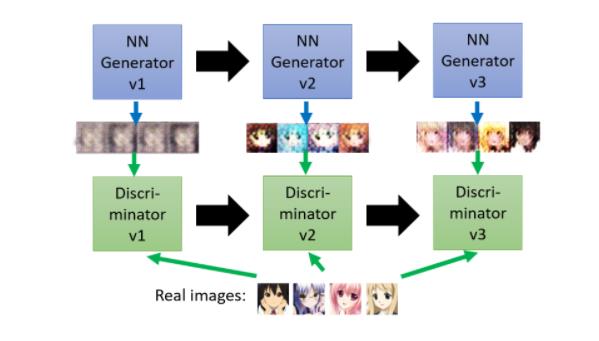
那 discriminator 也会逐渐的进步,他会越来越严苛,然后期待discriminator越来越严苛,Generator产生出来的图片,就可以越来越像二次元的人物,那因为这边有一个generator,有一个discriminator,他们彼此之间是会互动的,是亦敌亦友的关系。

Algorithm
以下就是正式来讲一下,这个演算法实际上是长什么样子,generator跟discriminator,他们就是两个network
network在训练前,你要先初始化它的参数,所以我们这边就假设说,generator跟discriminator,它们的参数 都已经被初始化了
Step 1: Fix generator G, and update discriminator D
初始化完以后,接下来训练的第一步是,顶住你的generator,只train你的discriminator
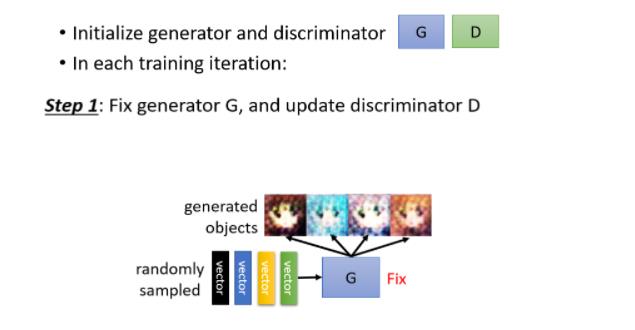
那因为一开始你的generator的参数是随机初始化的,所以你丢一堆向量给它,它的输出都是乱七八糟的图片甚至有可能连图片都产生不出来,那产生出来的就像电视机坏掉的那种杂讯
那你从这个gaussian distribution裡面,去random sample一堆vector,把这些vector丢到generator裡面,它就吐出一些图片 一开始这些图片,会跟正常的二次元人物非常的不像
好那你会有一个database,这个database裡面,有很多二次元人物的头像,这个去网路上爬个图库就有了,从这个图库裡面,去sample一些,二次元人物的头像出来

接下来你就拿真正的二次元人物头像,跟generator產生出来的结果,去训练你的discriminator,discriminator它训练的目标是要分辨,真正的二次元人物,跟generator产生出来的二次元人物它们之间的差异
讲得更具体一点啊,你实际上的操作是这个样子,你可能会把这些真正的人物都标1,Generator產生出来的图片都标0
接下来对於discriminator来说,这就是一个分类的问题,或者是regression的问题
- 如果是分类的问题,你就把真正的人脸当作类别1,Generator產生出来的,这些图片当作类别2,然后训练一个classifier就结束了
- 或者是有人会把它当作regression的问题,那你就教你的discriminator说,看到这些图片你就输出1,看到这些图片你就输出0,都可以 总之discriminator就学著,去分辨这个real的image,跟產生出来的image之间的差异
Step 2: Fix discriminator D, and update generator G
我们训练完,discriminator以后,接下来定住discriminator改成训练generator,怎么训练generator呢
拟人化的讲法是,我们就让generator想办法去骗过discriminator,因為刚才discriminator,已经学会分辨,真图跟假图的差异,真图跟生成的图片的差异,Generator如果可以骗过,discriminator它可以產生一些图片,Discriminator觉得,是真正的图片的话,那generator產生出来的图片,可能就可以以假乱真
它实际上的操作方法是这样子,你有一个generator,generator吃一个向量作為输入,从gaussian distribution sample,出来的向量作為输入,然后产生一个图片
接下来我们把这个图片丢到,Discriminator裡面,Discriminator会给这个图片,一个分数. Discriminator参数是固定的,我们只会调整generator的参数
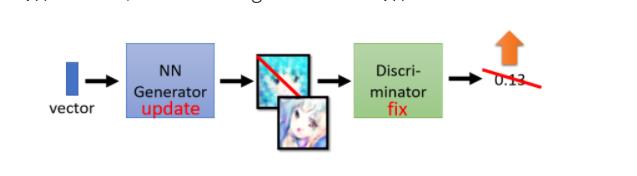
Generator训练的目标,是要Discriminator的输出值,越大越好,那因為Discriminator,它本来训练的时候,它训练的目标它可以做的事情就是,看到好的图片就给它大的分数,如果generator可以调整参数之后,输出来的图片Discriminator,会给予高分,那意味著generator产生出来的图片,是比较真实的
接下来就是反覆的训练,discriminator跟generator,训练完discriminator以后,固定住discriminator,训练generator,训练完generator以后,再用generator去產生更多的,新的产生出来的图片,再给discriminator做训练,训练完discriminator以后,再去训练generator,反覆的去执行
Theory behind GAN
Divergence is hard
我们在训练 Network 的时候,你就是要
- 定一个 Loss Function
- 定完以后用 Gradient Descent 去调你的参数
- 去 Minimize 那个 Loss Function 就结束了
在这个 Generation 的问题里面,我们要 Minimize,或者是 Maximize 什么样的东西,我们要把这些事弄清楚,才能够做接下来的事情
我们想要 Minimize 的东西是这个样子的,我们有一个 Generator
- 给它一大堆的 Vector,给它从 Normal Distribution Sample 出来的东西
- 丢进这个 Generator 以后,会產生一个比较复杂的 Distribution,这个复杂 Distribution,我们叫它 PG
- 然后 我们有一堆的 Data,这个是真正的 Data,真正的 Data 也形成了另外一个 Distribution,叫做 Pdata,我们期待 PG 跟 Pdata 越接近越好
于是,对于
P
G
和
P
d
a
t
a
P_G和P_{data}
PG和Pdata我们希望这两个 Distribution 之间的 Divergence(散度)越接近越好

Divergence 这边指的意思就是,这两个你可以想成是,这两个 Distribution 之间的某种距离
- 如果这个 Divergence 越大,就代表这两个 Distribution 越不像
- Divergence越小,就代表这两个 Distribution 越接近
Divergence就是衡量这两个 Distribution 相似度的一个 Measure
在 Generation 这个问题裡面,我们现在其实也定义了我们的 Loss Function,它就是 PG 跟 Pdata 的 Divergence,就是它们两个之间的距离,它们两个越近,那就代表这个產生出来的 PG 跟 Pdata 越像,所以 PG 跟 Pdata,我们希望它们越相像越好
但是我们这边遇到一个困难的问题

这个Divergence要怎么算?你可能知道一些 Divergence 的式子, 比如说 KL Divergence, JS Divergence, 这些 Divergence 用在这种 Continues 的 Distribution 上面,这其实是一个你几乎不知道要怎么算的一个积分,那我们根本就无法把这个 Divergence 算出来
而 GAN是一个很神奇的做法,它可以突破,我们不知道怎麼计算 Divergence 的限制
how to deal with divergence
接下来,GAN 这一整个系列的 Work,就是要告诉你说,怎麼在只有做 Sample 的前提之下,我根本不知道 PG 跟 Pdata,实际上完整的 Formulation 长什麼样子,居然就估测出了 Divergence
那我们刚才讲过说 Discriminator是怎麼训练出来的
- 我们有一大堆的 Real Data,这个 Real Data 就是从 Pdata Sample 出来的结果
- 我们有一大堆 Generative 的 Data,Generative 的 Data,就可以看作是从 PG Sample 出来的结果
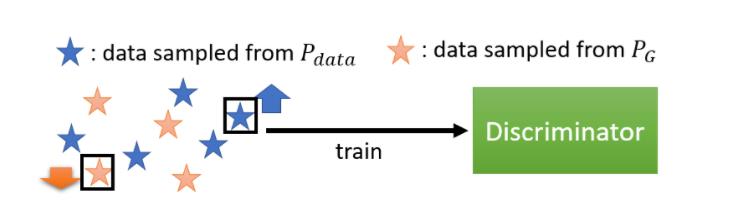
根据 Real 的 Data 跟 Generative 的 Data,我会去训练一个 Discriminator,它的训练的目标是
- 看到 Real Data,就给它比较高的分数
- 看到这个 Generative 的 Data,就给它比较低的分数
实际以上的过程,你也可以把它写成式子,把它当做是一个 Optimization 的问题,这个 Optimization 的问题是这样子的
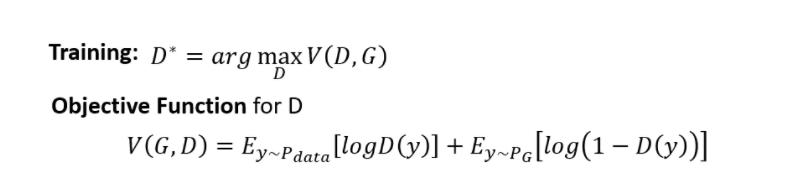
我们现在要找一个 D,它可以 Maximize 这个 Objective Function,这个 Objective Function 长这个样子
- E y ∽ P d a t a [ l o g D ( y ) ] E_{y\\backsim P_{data}}[logD(y)] Ey∽Pdata[logD(y)] 我们有一堆 Y, 它是从 Pdata 里面 sample 出来的, 也就是它们是真正的 Image, 而我们把这个真正的 Image 丢到 D 里面, 得到一个分数再取 l o g D ( y ) logD(y) logD(y)
- E y ∽ P G [ l o g ( 1 − D ( y ) ) ] E_{y\\backsim P_{G}}[log(1-D(y))] Ey∽PG[log(1−D(y))] 我们有一堆 Y, 它是从 PG 里面 sample 出来的, 把这些图片也丢到 Discriminator 里面,得到一个分数,再取 l o g ( 1 − D ( y ) ) log(1-D(y)) log(1−D(y))
我们希望这个 Objective Function V越大越好
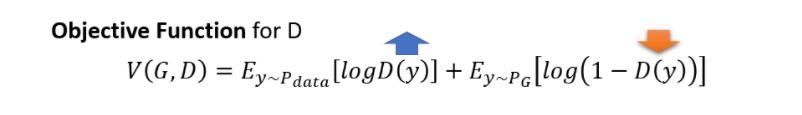
意味著我们希望这边的 D (Y) 越大越好,我们希望 Y 如果是从 Pdata Sample 出来的,它就要越大越好;如果 Y 是从,这个 PG Sample 出来的,它就要越小越好
事实上这个 Objective Function,它就是 Cross Entropy 乘一个负号,我们知道我们在训练一个 Classifier 的时候,我们就是要 Minimize Cross Entropy,所以当我们Maximize Cross Entropy 乘一个负号的时候,其实等同於 Minimize Cross Entropy,也就是等同於是在训练一个 Classifier
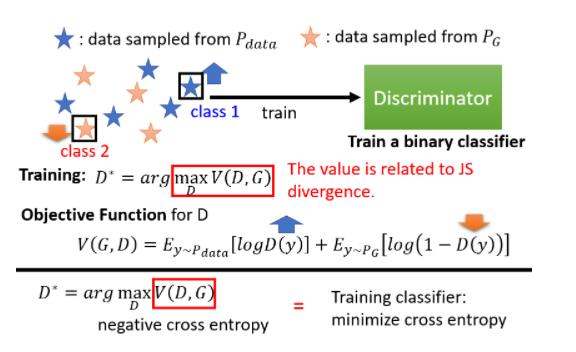
那这边最神奇的地方是这一个式子,这个红框框裡面的数值,它跟 JS Divergence 有关
所以真正神奇的地方就是,这一个 Objective Function 的最大值,它跟 Divergence 是有关的,所以我们刚才说,我们不知道怎麼算 Divergence没关係,Train 你的 Discriminator,Train 完以后,看看它的 Objective Function 可以到多大,那个值就跟 Divergence 有关
这边我们并没有把证明拿出来跟大家讲了,但是我们还是可以从直观上来理解一下,為什麼这个 Objective Function 的值,会跟 Divergence
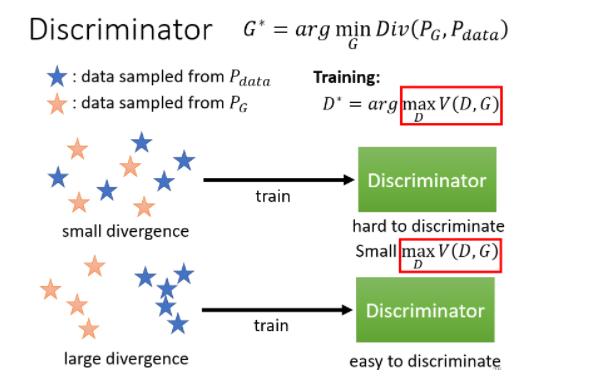
假设 PG 跟 Pdata,它的 Divergence 很小. 这个时候Discriminator 就是在 Train 一个,Binary 的 Classifier,对 Discriminator 来说,既然这两堆资料是混在一起的,那就很难分开,这个问题很难,所以你在解这个 Optimization Problem 的时候,你就没有办法让这个 Objective 的值非常地大
如果今天,你的两组 Data 很不像,它们的 Divergence 很大,那对 Discriminator 而言,就可以轻易地把它分开。当 Discriminator 可以轻易把它分开的时候,这个 Objective Function 就可以冲得很大,那所以当你有大的 Divergence 的时候,这个 Objective Function 的 Maximum 的值,就可以很大
这也就从直观上看出 Divergence 跟我们这里 Objective Function 是相关的
所以我们说我们本来的目标是要找一个 Generator,去 Minimize PG 跟 Pdata 的 Divergence
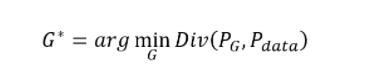
但我们卡在不知道怎麼计算 Divergence,那我们现在要知道,我们只要训练一个 Discriminator,训练完以后,这个 Objective Function 的最大值,就是这个 Divergence,就跟这个 Divergence 有关

那我们何不就把红框框裡面这一项,跟 Divergence 做替换,我们何不就把 Divergence,替换成红框框裡面这一项,所以我们就有了这样一个 Objective Function
然后我们要找一个 G,让红框框裡面的值最小,这个 G 就是我们要的 Generator,而刚才我们讲的这个 Generator 跟 Discriminator,互动 互相这个过程,其实就是想解这一个既有 Minimize,又有 Maximize 这个 Min Max的问题,就是透过下面这一个,我们刚才讲的 GAN 的 Argument 来解的

Tips for GAN
Evaluation of Generative Models
Connditional Generation
Learning from unpaired data
以上是关于GAN简介的主要内容,如果未能解决你的问题,请参考以下文章