使用Azure认知服务快速搭建一个目标检测平台
Posted 夏小悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Azure认知服务快速搭建一个目标检测平台相关的知识,希望对你有一定的参考价值。
前言
博主参与了由CSDN和微软共同举办的0元试用Azure人工智能认知服务的活动,体验了一下Azure的计算机视觉方面的服务,在这里记录一下如何基于Azure计算机视觉服务快速搭建一个目标检测平台。
1. 认知服务
认知服务使每个开发人员和数据科学家都可以使用 AI。借助领先的模型,可以解锁各种用例。只需要一个 API 调用,就可以将看、听、说、搜索、理解和加快高级决策制定的能力嵌入到应用中。让所有技能水平的开发人员和数据科学家都能轻松在其应用中添加 AI 功能。
Azure认知服务简介
Azure的计算机视觉服务具体包括以下服务:
| 服务 | 说明 |
|---|---|
光学字符识别 (OCR) | 光学字符识别 (OCR) 服务从图像中提取文本, 可以使用新读取 API 从图像和文档中提取印刷体文本和手写文本。 此 API 使用基于深度学习的模型,并处理各种表面和后台上的文本,包括业务文档、发票、收据、海报、名片、信件和白板,并且支持提取多种语言的印刷体文本 |
图像分析 | 图像分析服务从图像中提取许多视觉特征,例如对象、人脸、成人内容和自动生成的文本说明 |
空间分析 | 空间分析服务会分析视频源上人员的状态和移动,并生成其他系统可以响应的事件 |
本篇主要介绍的是图像分析服务中的目标检测功能。Azure的计算机视觉服务对输入图像的要求如下:
- 图像文件格式必须是
JPEG、PNG、GIF或BMP - 图像的文件大小不能超过
4 MB - 图像的尺寸必须大于
50 x 50像素,对于读取API,图像的尺寸必须介于50 x 50和10000 x 10000像素之间。
2. 环境配置
2.1 创建资源
按照下图所示步骤来添加计算机视觉所需要的资源:




创建完毕后,进入资源可以看到自己的终结点endpoint和密钥subscription key:

2.2 创建python环境
# 安装Azure Computer Vision库
pip install --upgrade azure-cognitiveservices-vision-computervision
# 安装pillow库
pip install pillow
# 安装 matplotlib库
pip install matplotlib
# 安装opencv库
pip install opencv-python
# 安装ffmpeg库
pip install ffmpeg
3. 代码实现
3.1 图片检测
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes
from msrest.authentication import CognitiveServicesCredentials
from PIL import Image
import matplotlib.patches as patches
import matplotlib.pyplot as plt
import numpy as np
import cv2
import glob
subscription_key = "xxxxxxxxxxx" # your subscription key
endpoint = "https://xiaxiaoyou-detection.cognitiveservices.azure.cn/" # your endpoint
# create computer vision client
computervision_client = ComputerVisionClient(endpoint, CognitiveServicesCredentials(subscription_key))
# test image
img_file = 'iu.png'
print("===== Detect Objects - local =====")
# Get local image with different objects in it
local_image_objects = open(img_file, "rb")
# Call API with local image
detect_objects_results_local = computervision_client.detect_objects_in_stream(local_image_objects)
object_dict = {}
count = 0
# Print detected objects results with bounding boxes
print("Detecting objects in local image:")
if len(detect_objects_results_local.objects) == 0:
print("No objects detected.")
else:
for object in detect_objects_results_local.objects:
# print(object)
object_dict[count] = {
'object_property': object.object_property,
'rectangle': [(object.rectangle.x, object.rectangle.y), object.rectangle.w, object.rectangle.h],
'confidence': object.confidence
}
count += 1
print("object at location {}, {}, {}, {}".format(
object.rectangle.x, object.rectangle.x + object.rectangle.w,
object.rectangle.y, object.rectangle.y + object.rectangle.h))
# create random color
colors = plt.cm.hsv(np.linspace(0, 1, 10)).tolist()
img = Image.open(img_file)
fig = plt.figure()
plt.imshow(img)
plt.axis('off')
currentAxis = plt.gca()
color_dict = {}
for i, info in enumerate(object_dict.items()):
print(info)
color = color_dict.get(info[1]['object_property'], None)
if not color:
color = colors[i]
color_dict[info[1]['object_property']] = color
rect = patches.Rectangle(*info[1]['rectangle'], edgecolor=color, linewidth=3, fill=False)
currentAxis.add_patch(rect)
currentAxis.text(info[1]['rectangle'][0][0], info[1]['rectangle'][0][1], info[1]['object_property'] + ' ' + str(info[1]['confidence']),
color='white', size=20, weight='bold', backgroundcolor=color, family='cursive')
# remove blank
fig.set_size_inches(img.size[0]/100, img.size[1]/100)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
plt.subplots_adjust(top=1, bottom=0, left=0, right=1, hspace=0, wspace=0)
plt.margins(0, 0)
plt.savefig('object-detection-iu.png')
plt.show()
3.2 视频检测
相比图片检测,视频检测多了两个视频转图片和图片转视频的操作,具体如下:
def toimg(video_file):
if not os.path.exists('imgs'):
os.mkdir('imgs')
cap = cv2.VideoCapture(video_file)
isopened = cap.isOpened
fps = cap.get(cv2.CAP_PROP_FPS) # 帧率
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print('fps: {0}, width: {1}, height: {2}'.format(fps, width, height))
i = 0
while isopened:
if i == 1000:
break
(flag, frame) = cap.read() # 读取每一张 flag frame
filename = 'imgs/' + str(i).zfill(5) + '.png'
if flag == True:
cv2.imwrite(filename, frame, [cv2.IMWRITE_JPEG_QUALITY, 100])
i += 1
cap.release()
def tovideo(img_path):
if not os.path.exists('video'):
os.mkdir('video')
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
videoWrite = cv2.VideoWriter('video/iu.mp4', fourcc, 30, (1920, 1080))
files = sorted(glob.glob(os.path.join(img_path, '*.png')))
for file in files:
img = cv2.imread(file)
videoWrite.write(img)
videoWrite.release()
4. 检测效果
博主测试了几张图片,效果还是非常不错的:
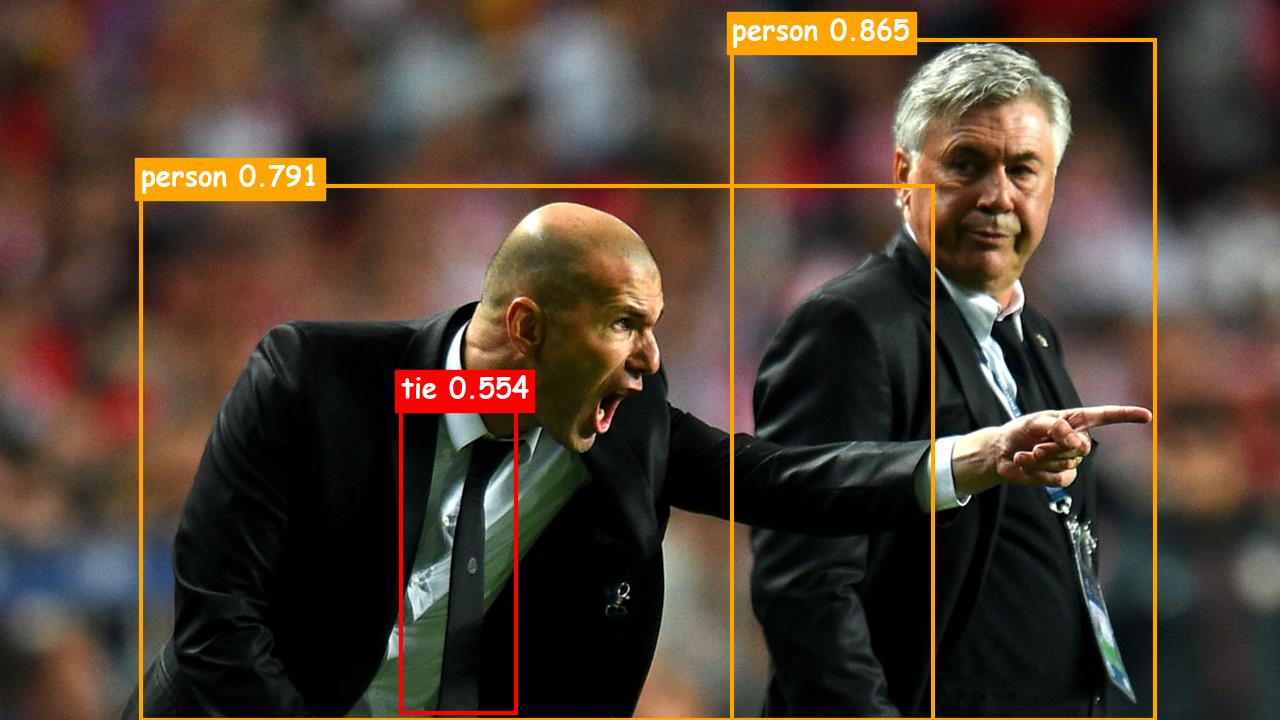

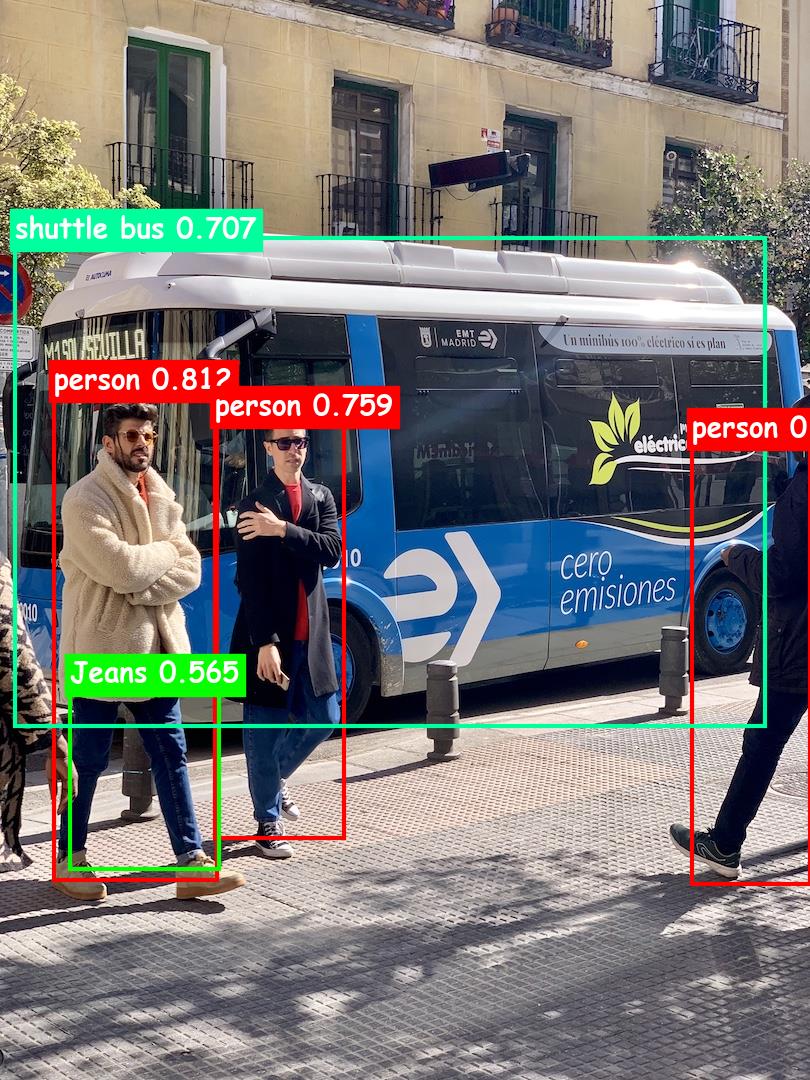
德鲁纳酒店-目标检测
结束语
总体感觉检测的准确率还是挺高的,虽然不知道Azure基于的什么模型,但就某些细节来看,种类还挺丰富,比如上述图片的牛仔裤,视频中IU的唇膏(化妆品)都可以检测到,而且速度也很棒,可能这就是商用的叭,很不戳!!!!
以上是关于使用Azure认知服务快速搭建一个目标检测平台的主要内容,如果未能解决你的问题,请参考以下文章
Azure/Microsoft 认知服务自定义视觉 - 啥是对象检测模型输出张量规范?
微软认知服务应用秘籍 – 搭建基于云端的中间层以支持跨平台的智能视觉服务