EDG夺冠,Python分析一波B站评论,总结:EDG,nb
Posted Dream丶Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EDG夺冠,Python分析一波B站评论,总结:EDG,nb相关的知识,希望对你有一定的参考价值。
前言
2012,一个卡牌,一个雷恩加尔,一群红衣少年的欢声笑语。
2013,一个杰斯,一个扎克,一场支离破碎的梦境。
2014,一个螳螂,一个兰博,一座摇摇欲坠的基地。
2015,一个寡妇,一个妖姬,一本永远叠不上去的梅贾窃魂卷。
2016,一个盲僧,一个奥拉夫,一串耻辱的数字。
2017,一个克格莫,一个青钢影,一个赛区绝境中最后的救赎。
2018,一个刀妹,一个剑魔,一个至高无上的尊严。
2019,一个泰坦,一个盲僧,一个浴火重生的凤凰。
2020,一个船长,一个剑姬,一个杀戮无法弥补的遗憾。
2021,一个皇子,一个佐伊,一个挽大厦于将倾的骑士。
今天的主角就是2021年英雄联盟全球总决赛冠军——EDG,当天夺冠消息一出,立马登顶各大媒体平台热搜榜,引发巨大反响,本文以B站官方赛事评论为例,来看看能不能发现什么有趣的内容!
探寻网页规律
待爬取链接:https://www.bilibili.com/video/BV1EP4y1j7kV?p=7
F12打开抓包工具–>选择network–>向下滑动评论–>寻找对应数据包
数据包链接如下:
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172020429646890840103_1636422926026&jsonp=jsonp&next=2&type=1&oid=891511588&mode=3&plat=1&_=1636423918172
直接打开会发现并不是对应的 json 文件。
仔细观察链接会发现有 “callback=jQuery172020429646890840103_1636422926026” 这个参数,根据字面意思应该是回调参数,我们尝试将它删掉,重现打开。
现在数据包就可以得到了,下一步找到控制“页数”的参数即可,经测试发现就是 next=2 这个参数。
数据抓取
获取url列表
通过 url 模板,格式化 url ,保存到待抓取列表中。
def get_url_list():
url_list = []
# url模板
url = f'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=%d&type=1&oid=891511588&mode=3&plat=1&_=1636423918172'
for i in range(1, 10):
# 将格式化的url添加到字符串中
url_list.append(url%i)
return url_list
抓取程序
因为待抓取的数据还是有些多,整个抓取采用 异步协程 的方式,使用时要替换请求头 headers 中的 cookie ,本次的代码只对网页请求进行异步操作,文件读写这部分并未设计异步。
async def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'cookie': "填写自己对应的网页cookie"
}
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
async with session.get(url=url, headers=headers, timeout=8) as response:
# 更改相应数据的编码格式
response.encoding = 'utf-8'
# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。
page_text = await response.text()
print(f"{url.split('=')[-1]}爬取完成!")
break
return save_to_csv(page_text)
数据解析与存储
从上面图中的内容可以看到,数据结构还是有点复杂的,这里我根据个人兴趣提取了一部分感兴趣的字段,大部分评论具有回复内容,这里只采集第一级评论的回复,数据保存时要注意 DataFrame 的表头不要重复保存。
def save_comment(df, dic, rep=False):
message = dic['content']['message'] if not rep else dic['content']['message'].split(':', 1)[-1]
df = df.append({'ctime':dic['ctime'],
'like':dic['like'],
'uname':dic['member']['uname'],
'sex':dic['member']['sex'],
'current_level':dic['member']['level_info']['current_level'],
'message':message},
ignore_index=True)
def save_to_csv(page_text):
df = pd.DataFrame({'ctime': [], 'like': [], 'uname': [], 'sex': [],
'current_level': [], 'message': []})
data = json.loads(page_text)
comment = data['data']['replies']
for dic in comment:
save_comment(df, dic)
if dic['replies'] != None:
for reply in dic['replies']:
save_comment(df, reply, rep=True)
header = False if Path(r'C:\\Users\\pc\\Desktop\\bilibili.csv').is_file() else True
df.to_csv(r'C:\\Users\\pc\\Desktop\\bilibili.csv', header=header, index=False, mode='a')
print('成功保存:' + str(len(df)) + '条')
完整源码文末获取
数据可视化
写文时间确实不多,只有用 Tableau 简单可视化一下了!
热评发布时间分布
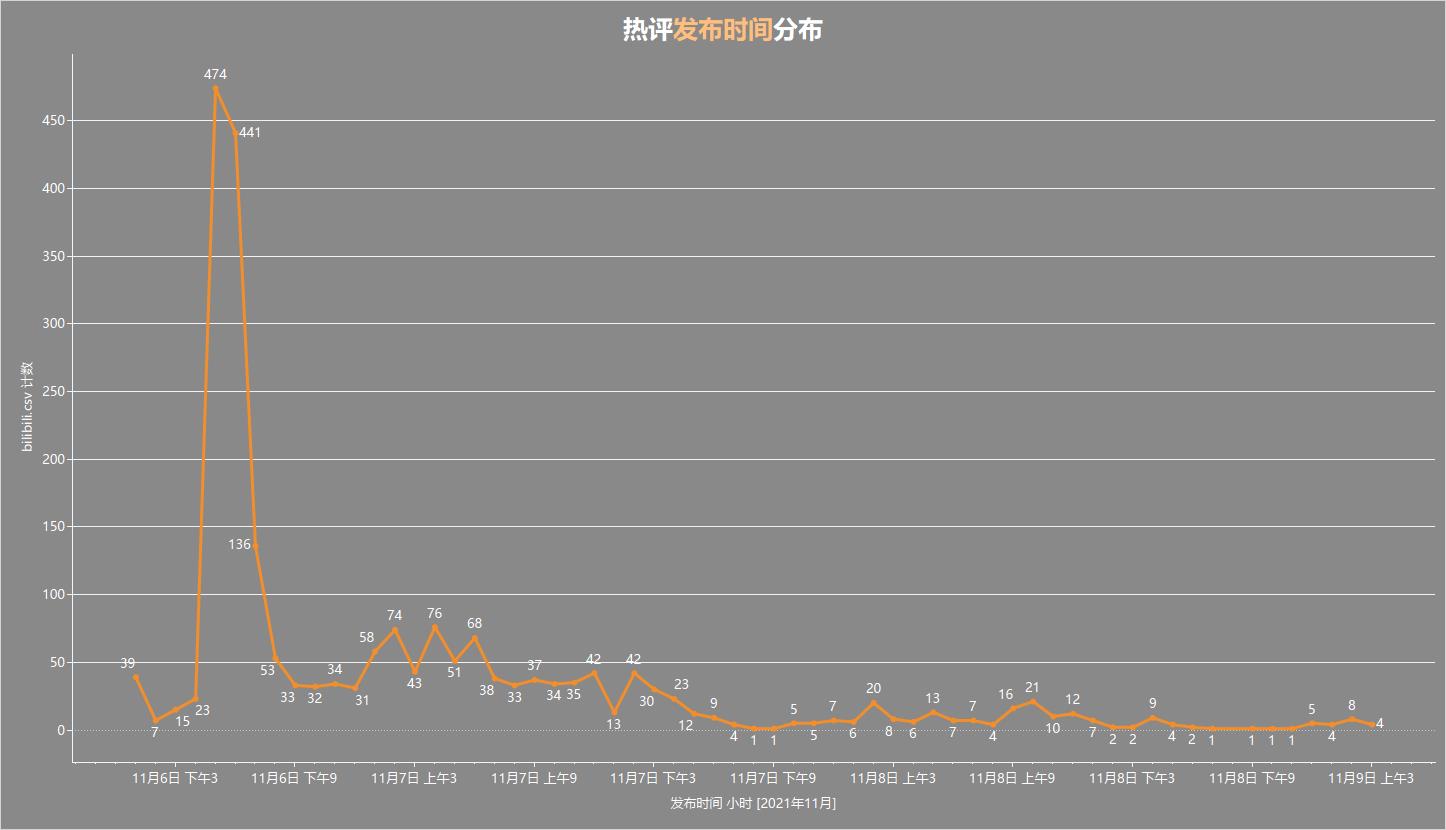
可以看到热评发布时间集中在 11月6日下午5-6点,基本占了整个热评池的一半左右。
评论热度排行
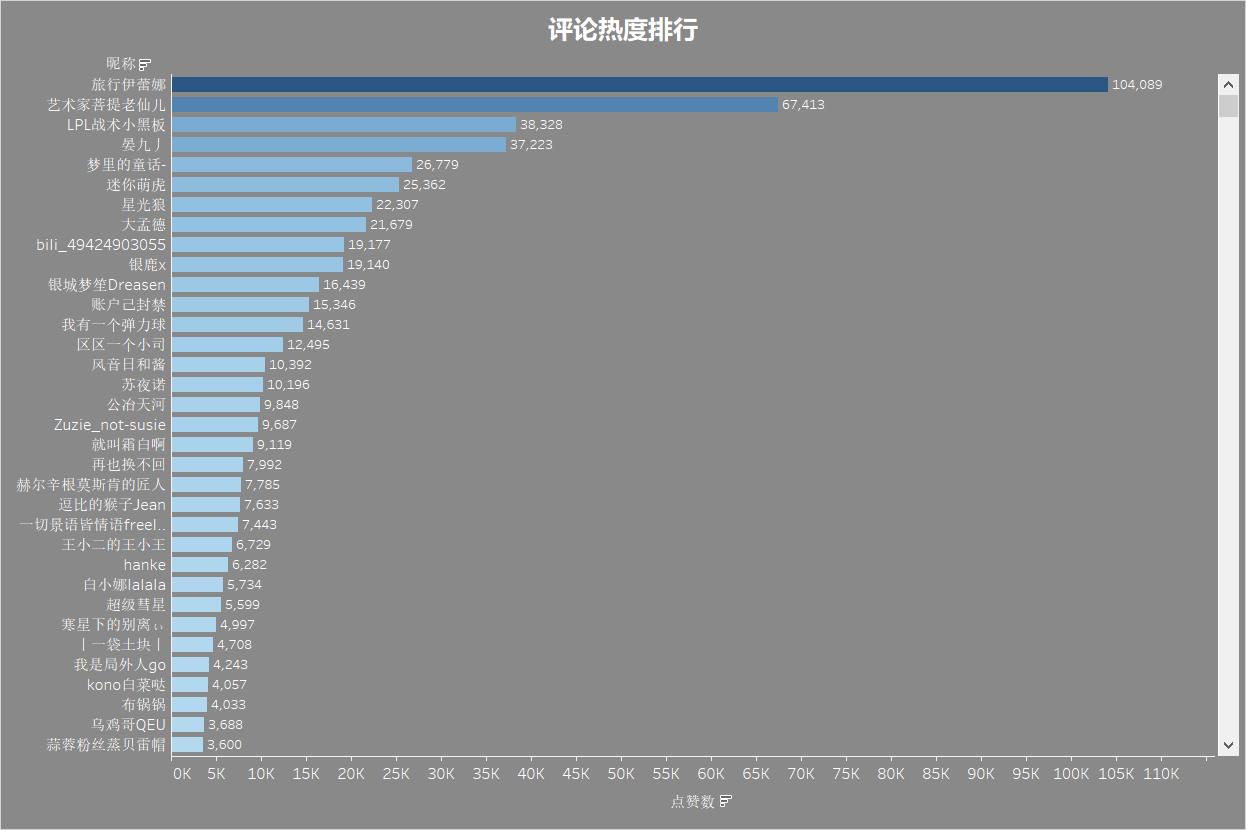
下面看一下热度排名前三的评论:
jiejie:像scout说实话,我真的很想给他一个冠军你知道吗?
他在edg打了那么久,我很想去给他一个冠军,我其实我是幻想过,我们一起在冰岛打到最后,我们一起捧奖杯的那个画面,我们六个,芙兰朵,viper,妹扣,俊嘉,如果厂长小象能来的话,我们八个人一起捧起召唤师奖杯。
lpl是最牛逼的,没有之一!
————点赞数104089
也许有一天,我说也许,也许有一天,我们再次对英雄联盟电子竞技失去了信心。因为韩国的宰治,从四强赛看来,已卷土重来。
但我觉得不是今天。
也许有一天,这些我们所熟知的热爱的选手,没有办法坚持在舞台上了。
但也不是今天。
今天,EDG浴血奋战!不破不立!来迎战LCK一号种子DK战队,我们准备进入召唤师峡谷!77777!!![打call][打call][打call]
————点赞数67413
骑士拔剑,攘除外敌,重建王朝。
我懂了是亚瑟王传说!
————点赞数37223
评论人群等级
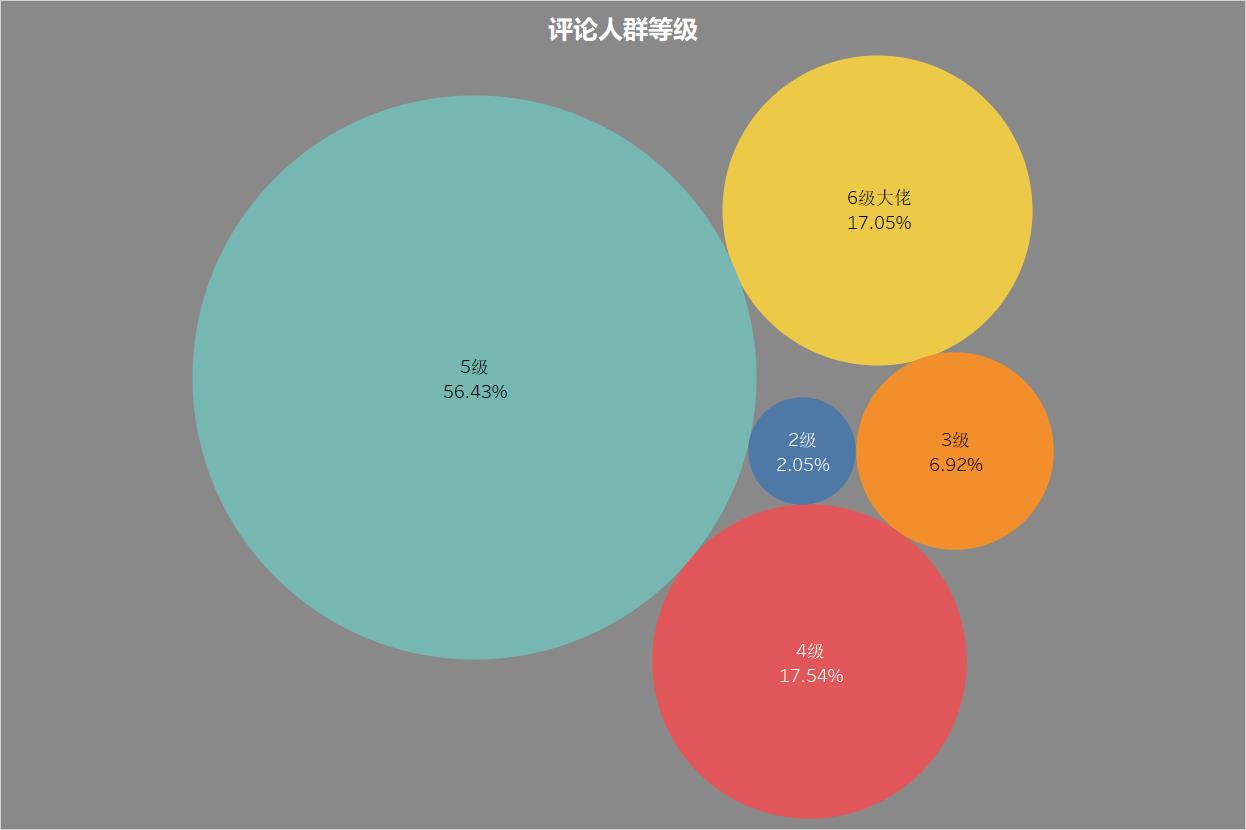
大佬是真的多呀,2级的只有2%左右!5级6级大佬占了73%,4级的我瑟瑟发抖。。
评论人群性别比例
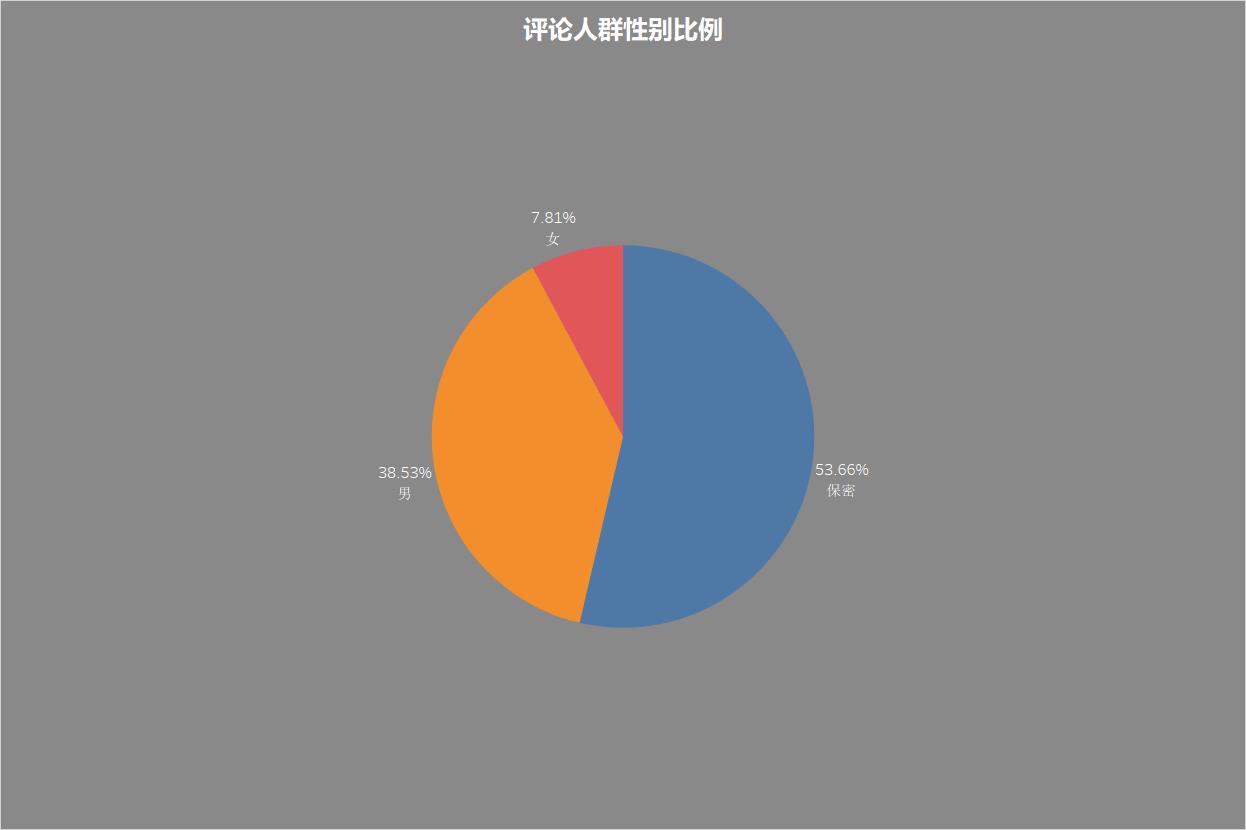
评论中男女占比 5:1 ,男生还是主力军!
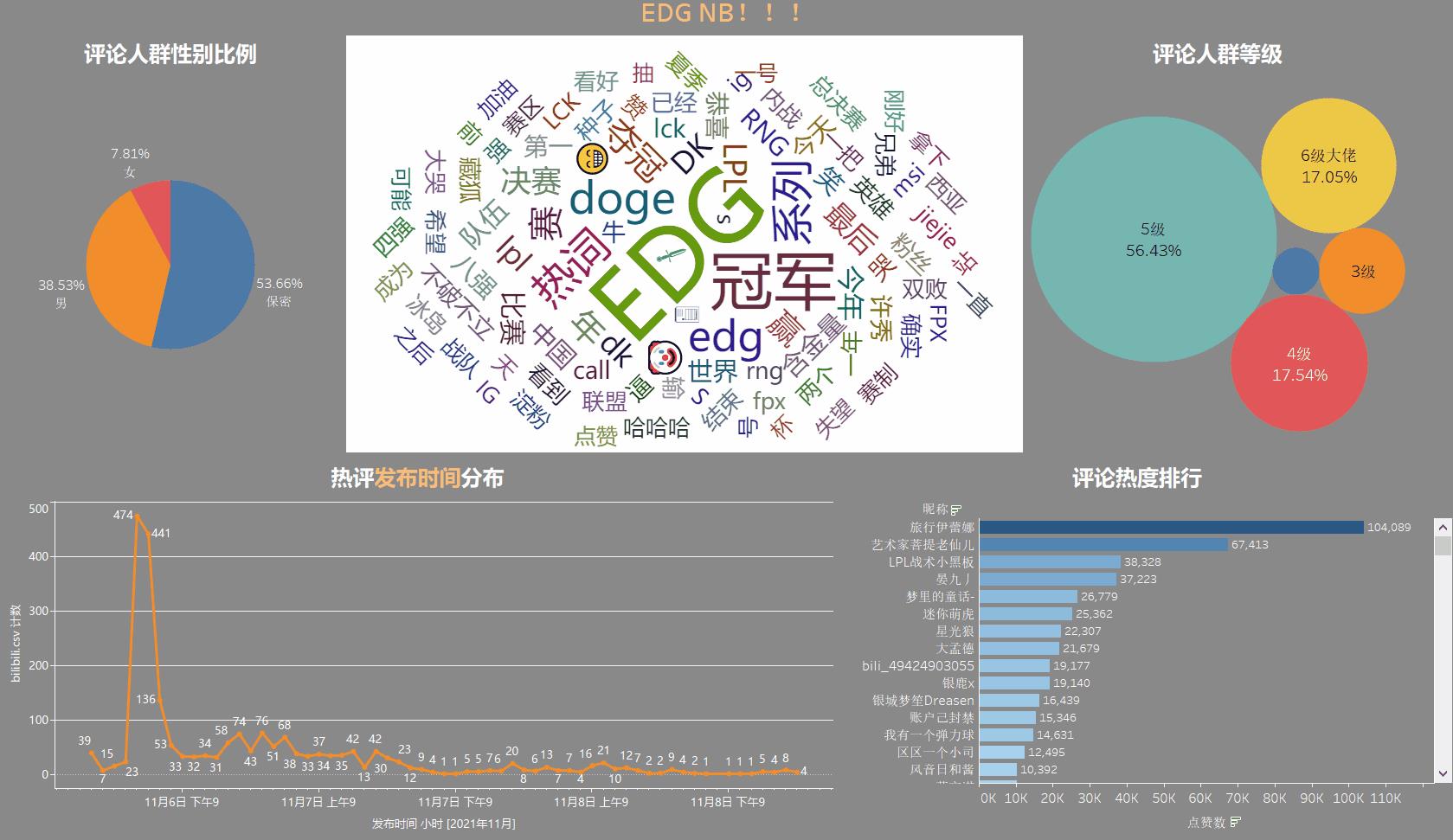
合成看板

源码获取
以上是关于EDG夺冠,Python分析一波B站评论,总结:EDG,nb的主要内容,如果未能解决你的问题,请参考以下文章