[人工智能-深度学习-38]:英伟达GPU CUDA 编程框架简介
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-38]:英伟达GPU CUDA 编程框架简介相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121220362
目录
第1章 什么CPU与GPU?
1.1 深度学习的硬件选择
 https://blog.csdn.net/HiWangWenBing/article/details/121207211
https://blog.csdn.net/HiWangWenBing/article/details/1212072111.2 CPU与GPU比较
CPU的全称是Central Processing Unit,
而GPU的全称是Graphics Processing Unit。
在命名上。这两种器件相同点是它们都是Processing Unit——处理单元;
不同点是CPU是“中央”控制器,而GPU是用于“图像”处理器。
(1)CPU的强项
因此,CPU的强项在于对复杂问题的分解与控制, CPU可以用来处理非常复杂的控制逻辑,预测分支、乱序执行、多级流水等等CPU做得非常好,这样对串行程序的优化做得非常好.
CPU擅长完成多重复杂任务,重在逻辑,重在串行程序;
CPU就像是一个博士,适合处理非常复杂的任务。
(2)GPU的强项
GPU的强项在于对于简单为题的重复与并行计算。
GPU的核心擅长完成具有简单的控制逻辑的任务,重在计算,重在并行。
GPU就像是一群的小学生,适合处理大量的简单任务(比如加减乘除)。让一名博士去处理大量的加减乘除,速度不一定有大量的小学生同时计算加减乘除来得快。
1.3 CPU功能的硬件基础

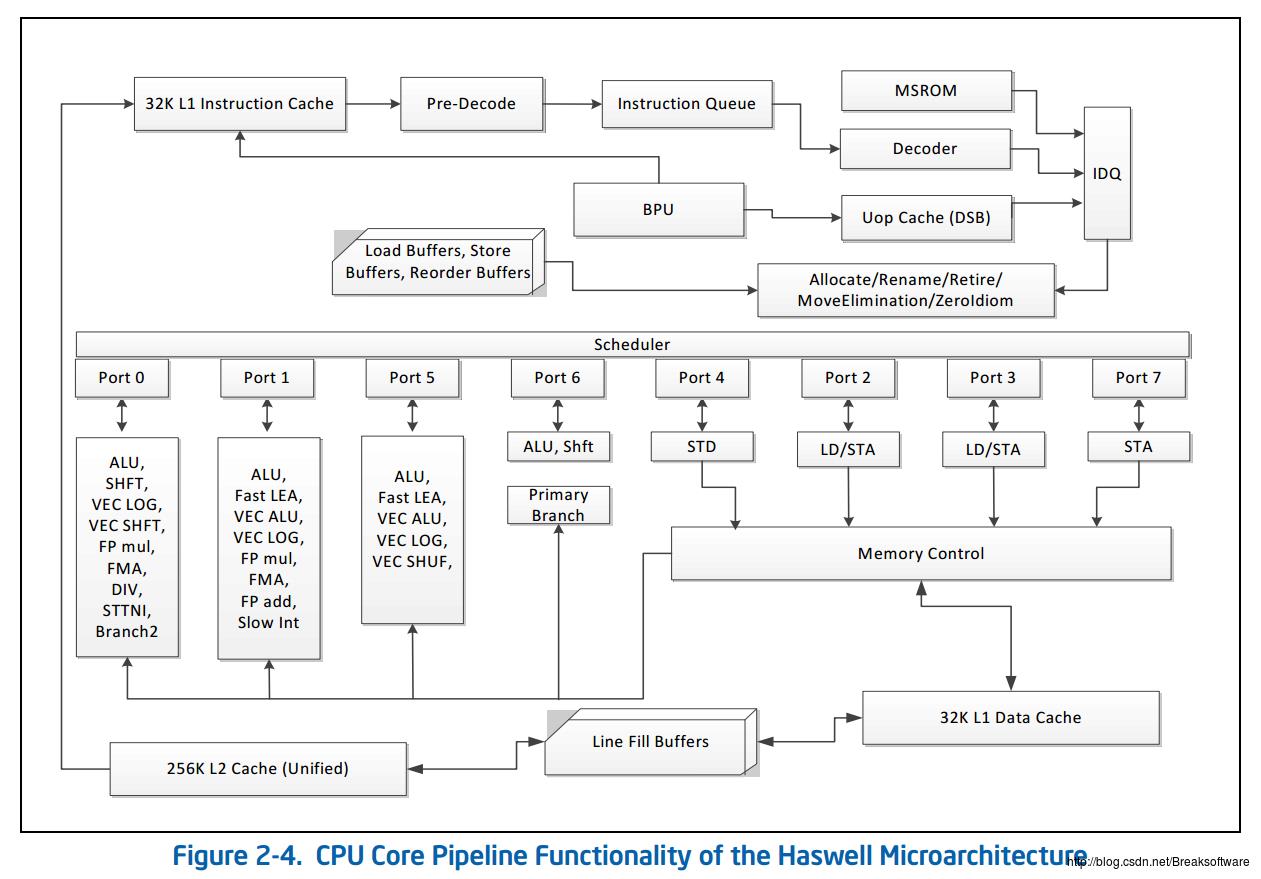
CPU有多种“执行单元”(Execution Units), 如通用的算术单元:ALU、浮点运算单元:FMA、FP add和FP mul等,浮点运算单元就是用于克服通用算术单元ALU在处理乘法和除法等浮点运算能力不足,从而提升他们的能力。
CPU比较常见的核数有:4核、8核、16核等。

1.4 GPU功能的硬件基础


GPU用于浮点计算的核数,高达成百上千。
如何有效的GPU提供的如此多的计算单元呢? 这就需要用到GPU的硬件驱动程序以及在硬件驱动程序之上的并行计算的编程框架了。
1.5 带GPU的计算机系统架构

在上述架构中,GPU是通用计算机的一个外设,通过PCIe与主机进行连接。
CPU负责把需要计算的任务分配给外设执行,
第2章 什么GPU CUDA 编程框架?
2.1 CUDA在操作系统中的位置

CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。
CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
CUDA提供了应用程序的编程接口API,供程序员,把自己的应用程序分配到GPU上执行。
不过,在深度学习的学习中,并不需要关注这个接口,因为工作已经由深度学习的框架完成了。
作为深度学习的学习者,这需要关注:
- CUDA有哪些库需要安装
- 如何使用深度学习框架提供的接口,把自己的任务指派到GPU上执行。
2.2 编程模型:Host + Device
CUDA程序构架分为两部分:Host和Device。
一般而言,Host指的是CPU,Device指的是GPU。
在CUDA程序构架中,CUDA 会把主程序还分配给CPU 来执行,而当遇到数据并行处理的部分,CUDA 就会将程序编译成 GPU能执行的程序,并传送到GPU。而执行这个程序的硬件,在CUDA里称做核(kernel)。
CUDA允许程序员定义称为核的C语言函数,从而扩展了C语言,在调用此类函数时,它将由N个不同的CUDA线程并行执行N次,这与普通的C语言函数只执行一次的方式不同。
执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。
在 CUDA 程序中,主程序在调用任何 GPU内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。
CUDA假设线程可在GPU物理上设备上独立执行,此类GPU设备作为运行C语言程序的主机CPU的协处理器操作。部分并行计算性代码在GPU上执行,而C语言程序的其他部分在CPU上执行(即串行代码在主机上执行,而并行代码在设备上执行)。
2.3 线程模型
在GPU中要执行的线程,根据最有效的数据共享来创建块(Block),其类型有一维、二维或三维。在同一个块内的线程可彼此协作,通过一些共享存储器来共享数据,并同步其执行来协调存储器访问。一个块中的所有线程都必须位于同一个GPU处理器中。因而,一个GPU处理器的有限存储器资源制约了每个块的线程数量。在多GPU的环境中,每个块,代表一个GPU或一个GPU的一部分,即一个块不能跨越多个GPU。
在早起的NVIDIA 架构中,一个线程块最多可以包含 512个线程,而在后期出现的一些设备中则最多可支持1024个线程。一般 GPU程序线程数目是很多的,所以不能把所有的线程都塞到同一个块里。但一个内核可由多个大小相同的线程块同时执行,因而线程总数应等于每个块的线程数乘以块的数量。
这些同样维度和大小的块将组织为一个一维或二维线程块网格(Grid)。
具体框架如图9所示

2.4 内存模型
CUDA还假设主机和设备均维护自己的DRAM,分别称为主机存储器和设备存储器。因而,一个程序通过调用CUDA运行库来管理对内核可见的全局、固定和纹理存储器空间。这种管理包括设备存储器的分配和取消分配,还包括主机和设备存储器之间的数据传输。
CUDA设备拥有自己的、多个独立于CPU内存的存储空间,其中包括:全局存储器、本地存储器、共享存储器、常量存储器、纹理存储器和寄存器,如图所示:
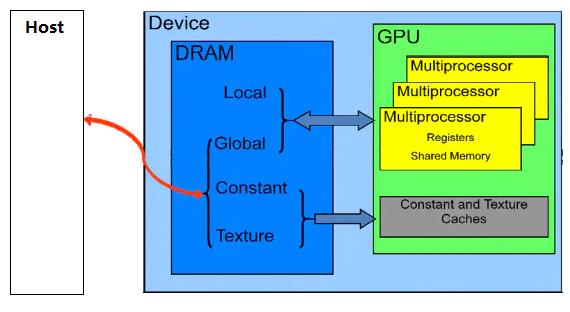
CUDA线程可在执行过程中访问多个存储器空间的数据,如图 下图所示其中:

- 每个线程都有一个私有的本地存储器。
- 每个线程块都有一个共享存储器,该存储器对于块内的所有线程都是可见的,并且与块具有相同的生命周期。
- 所有线程都可访问相同的全局存储器。
- 此外还有两个只读的存储器空间,可由所有线程访问,这两个空间是常量存储器空间和纹理存储器空间。全局、固定和纹理存储器空间经过优化,适于不同的存储器用途。纹理存储器也为某些特殊的数据格式提供了不同的寻址模式以及数据过滤,方便Host对流数据的快速存取。
2.5 GPU常见术语
由于CUDA中存在许多概念和术语,诸如SM、block、SP等多个概念不容易理解,将其与CPU的一些概念进行比较,如下表所示。
| CPU | GPU | 层次 |
|---|---|---|
| 算术逻辑和控制单元 | 流处理器(SM) | 硬件 |
| 算术单元 | 批量处理器(SP) | 硬件 |
| 进程 | Block | 软件 |
| 线程 | thread | 软件 |
| 调度单位 | Warp | 软件 |

第3章 CPU与GPU的性能比较:案例分析(来自于网络)
3.1 创建任务
(1)创建CPU的串行执行的任务
使用Python的numpy包来表示CPU模式下对矩阵进行求逆。

(2)创建GPU的并行执行的任务
用tensorflow-gpu版本计算矩阵的逆。

3.2 任务执行
(1)任务说明
- n表示矩阵的规模,用横轴表示。n越大,计算量越大。
- t表示执行时间,用纵轴表示。
- 使用上面的代码对n从0到10000进行了计算,并计算了每一个n值条件下,CPU与GPU所花费的时间t,然后进行比较。
(2)n = 2
一开始,GPU花的时间比CPU多很多,当n = 2时。
GPU用时0.0053s,CPU用时0.0001s,GPU用时是CPU的53倍。如下图所示:

(3)n = 400时
随着计算量的增加GPU所花费的时间和CPU相差无几,当矩阵的行列数增加到400时,GPU与CPU计算所花费的时间相差无几,gpu所花时间为0.00,85s,cpu所花时间为0.0104s。

(4)n到4000时
随着计算量的不断增加,GPU所花费的时间增长呈现线性规律,而CPU所花费的时间曲线存在一些毛刺(可能是因为CPU同时在运行其他程序,容易受到影响)。

(5)当n到7000时
当矩阵行列值增加到7000时,可以看出,GPU所花时间的增长缓慢,而CPU的时间曲线则越来越陡峭。此时CPU与GPU消耗时间的比例为40倍!,也就是说GPU一个小时完成的任务,CPU需要40个小时。

(5) n= 10000时
n继续增加,当n加大到10000时,gpu所花时间为1.0294s,cpu所花时间为52.6677s,CPU花费的时间大约是GPU的50倍!也就是说GPU一个小时完成的任务,CPU需要50个小时。

3.3 任务结果分析
GPU的处理速度之快得益于它可以高效地处理矩阵乘法和卷积,有一块好的GPU能极大地加大计算速度。
CPU与GPU就像法拉利与卡车,两者的任务都是从随机位置A提取货物(即数据包),并将这些货物传送到另一个随机位置B,法拉利(CPU)可以快速地从RAM里获取一些货物,而大卡车(GPU)则慢很多,有着更高的延迟。但是,法拉利传送完所有货物需要往返多次:
相比之下,大卡车虽然起步没有法拉利快,但它可以一次提取更多的货物,减少往返次数。
如果把机器学习的成果比作仙丹,那么,用于训练模型的计算机就是丹炉。显然,好的丹炉是可以缩短模型训练的时间从而节约炼丹者(机器学习爱好者)的生命的。
第4章 如何使用CUDA
cuda的使用应用程序的层次相关,对于深度学习,则与深度学习的框架相关,通常深度学习的应用程序,不需要直接访问CUDA的编程接口API, 而是通过深度框架提供的接口配置、访问GPU。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121220362
以上是关于[人工智能-深度学习-38]:英伟达GPU CUDA 编程框架简介的主要内容,如果未能解决你的问题,请参考以下文章
[人工智能-深度学习-41]:开发环境 - GPU进行训练安装与搭建(PytrochTensorFlowNvidia CUDA)详细过程
深度 | 英伟达Titan Xp出现后,如何为深度学习挑选合适的GPU?这里有份性价比指南