MediaPipe Hands: On-device Real-time Hand Tracking 论文阅读笔记
Posted 炼丹狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MediaPipe Hands: On-device Real-time Hand Tracking 论文阅读笔记相关的知识,希望对你有一定的参考价值。
设备端实时手部追踪
论文地址: https://arxiv.org/abs/2006.10214v1
Demo地址:https://hand.mediapipe.dev/
研究机构:Google Research
会议:CVPR2020
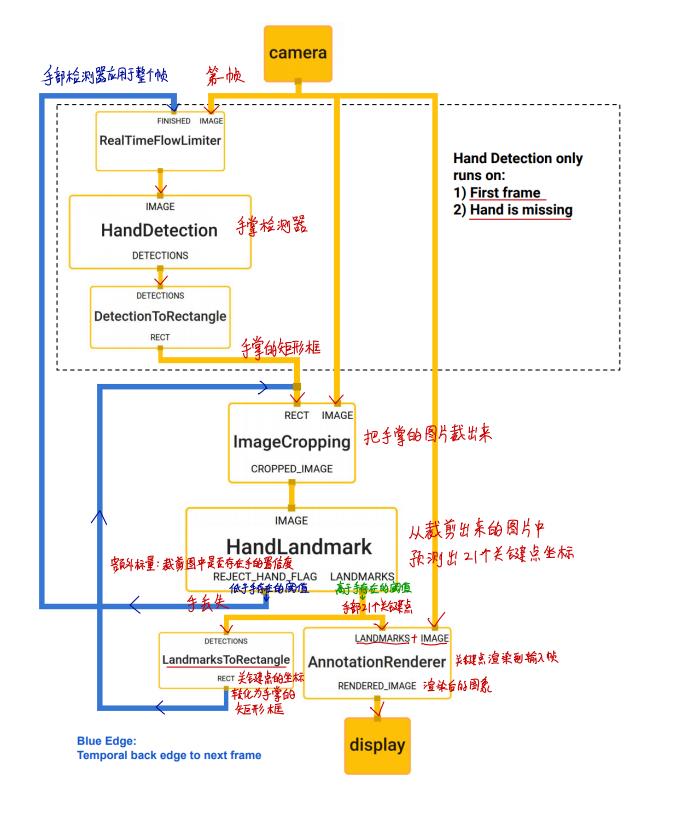
开始介绍之前,先贴一个模型的流程图,让大家对系统架构有个整体的概念
0. 摘要 (Abstract)
We present a real-time on-device hand tracking solution that predicts a hand skeleton of a human from a single RGB camera for AR/VR applications. Our pipeline consists of two models: 1) a palm detector, that is providing a bounding box of a hand to, 2) a hand landmark model, that is predicting the hand skeleton. It is implemented via MediaPipe[12], a framework for building cross-platform ML solutions. The proposed model and pipeline architecture demonstrate real-time inference speed on mobile GPUs with high prediction quality. MediaPipe Hands is open sourced at https://mediapipe.dev
我们提出了一种实时设备上的手部跟踪解决方案,该方案可以从单张的RGB图像中预测人体的手部骨架,并且可以用于AR/VR应用。我们方案的数据处理流水线由两个模型组成:
- (1)手掌检测器:提供手的边界框
- (2)手部坐标估计模型:预测手的骨架
本方案基于MediaPipe(是一个用于构建跨平台机器学习解决方案的框架)实现。
它在移动GPU上具有较高的实时推理速度和预测质量,具体开源代码请参见 MediaPipe Hands
1. 简介 (Introduction)
Hand tracking is a vital component to provide a natural way for interaction and communication in AR/VR, and has been an active research topic in the industry. Vision-based hand pose estimation has been studied for many years. A large portion of previous work requires specialized hardware, e.g. depth sensors . Other solutions are not lightweight enough to run real-time on commodity mobile devices and thus are limited to platforms equipped with powerful processors. In this paper, we propose a novel solution that does not require any additional hardware and performs in real-time on mobile devices. Our main contributions are:
• An efficient two-stage hand tracking pipeline that can track multiple hands in real-time on mobile devices.
• A hand pose estimation model that is capable of predicting 2.5D hand pose with only RGB input.
• And open source hand tracking pipeline as a ready-togo solution on a variety of platforms, including android, ios, Web (Tensorflow.js) and desktop PCs.
手部跟踪是AR/VR重要的组成部分,为AR/VR的交互和沟通提供最自然的方式,而且这个方向一直是业界的一个活跃研究课题。
基于视觉的手部姿势估计已经研究了很多年,但是有很多局限性,具体如下:
- (1)大部分工作需要专用硬件,例如深度传感器
- (2)不够轻量化,不能实时的在普通的商用设备上运行,仅能运行在配备了强大处理器的平台上
在本文中我们解决了上述两个局限性,提出了一个不需要额外设备且能在移动设备上实时运行的解决方案,我们的主要贡献如下:
- (1)一个高效的两阶段手部跟踪处理流程,可以实时的在移动设备上跟踪多个手
- (2)一个手部姿态估计模型,可以从RGB图像输入中预测2.5D的手部姿态
- (3)一个跨平台开箱即用的开源手部跟踪处理流程,支持的平台包括安卓、苹果、网页(Tensorflow.js)和桌面PC等
2. 架构 (Architecture)
Our hand tracking solution utilizes an ML pipeline consisting of two models working together:
• A palm detector that operates on a full input image and locates palms via an oriented hand bounding box.
• A hand landmark model that operates on the cropped hand bounding box provided by the palm detector and returns high-fidelity 2.5D landmarks.
Providing the accurately cropped palm image to the hand landmark model drastically reduces the need for data augmentation (e.g. rotations, translation and scale) and allows the network to dedicate most of its capacity towards landmark localization accuracy. In a real-time tracking scenario, we derive a bounding box from the landmark prediction of the previous frame as input for the current frame, thus avoiding applying the detector on every frame. Instead, the detector is only applied on the first frame or when the hand prediction indicates that the hand is lost.
我们的解决方案使用了机器学习的处理流程,该流程包括了两个模型:
- (1)手掌检测器:通过扫描全图,用一个有方向的手部定位框来定位手掌的位置
- (2)手部坐标模型:通过在手掌检测器裁剪的手部定位框上做操作,返回高保真的2.5D坐标
提供给手部坐标模型的是精确裁剪的手掌图片,极大的降低数据增强(例如旋转,平移和缩放)操作,可以使模型的性能都用来提高坐标定位的精度。在实时追踪的场景中,当前帧的手部定位框是从上一帧的手部关键点坐标预测中推导出来,这样可以避免每一帧都使用手掌检测器。 手掌检测器只在第一帧或者当手部丢失情况下才使用。
2.1 手部检测器
To detect initial hand locations, we employ a singleshot detector model optimized for mobile real-time application similar to BlazeFace, which is also available in MediaPipe. Detecting hands is a decidedly complex task: our model has to work across a variety of hand sizes with a large scale span (~20x) and be able to detect occluded and self-occluded hands. Whereas faces have high contrast patterns, e.g., around the eye and mouth region, the lack of such features in hands makes it comparatively difficult to detect them reliably from their visual features alone.
Our solution addresses the above challenges using different strategies.
First, we train a palm detector instead of a hand detector, since estimating bounding boxes of rigid objects like palms and fists is significantly simpler than detecting hands with articulated fingers. In addition, as palms are smaller objects, the non-maximum suppression algorithm works well even for the two-hand self-occlusion cases, like handshakes. Moreover, palms can be modelled using only square bounding boxes , ignoring other aspect ratios, and therefore reducing the number of anchors by a factor of 3~5.
Second, we use an encoder-decoder feature extractor similar to FPN for a larger scene-context awareness even for small objects.
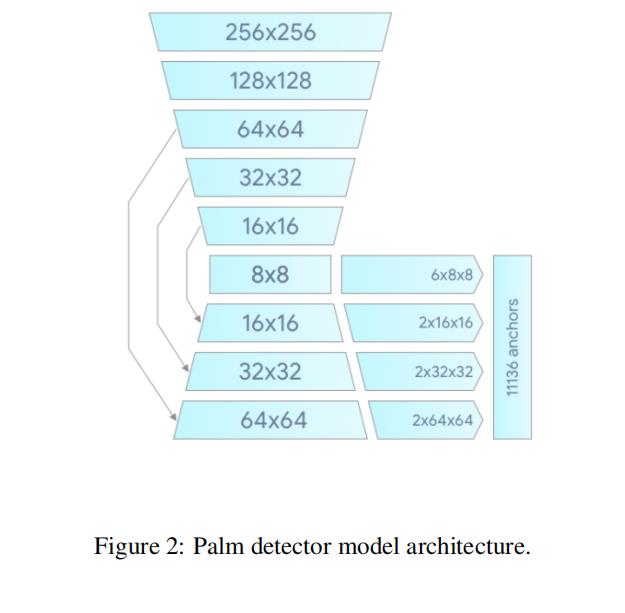
Lastly, we minimize the focal loss during training to support a large amount of anchors resulting from the high scale variance. High-level palm detector architecture is shown in Figure 2. We present an ablation study of our design elements in Table 1.
为了检测出初始的手部位置,我们使用了类似于BlazeFace的在移动端做了实时优化的单一检测模型,其中BlazeFace在MediaPipe也有具体实现。检测手是一项非常复杂的任务,原因有以下几点:
- (1)手部的大小有很大的跨度,最大的有20倍的差别
- (2)手部有遮挡和自遮挡的情况
- (3)手部缺乏和脸一样高对比度的模式,例如在脸和嘴周围有相对明显的特征
因此只依赖视觉特征来检测手相对困难,但是我们使用不同的策略解决了上述挑战,具体方法如下:
- (1)训练了一个手掌检测器来代替手部检测器:因为估计手掌和拳头等刚性物体的边界框比检测包含铰接手指的手要明显简单的多
- (2)使用非极大值抑制算法:因为手掌是小物体,即使在如握手等双手自遮挡的情况下NMS都可以工作的很好。
- (3)只使用正方形的边界框来建模手掌:因为手掌是正方形的,这样就可以减少3到5倍的其他比列的锚框
- (4)使用了类似于FPN(特征金字塔网络)编解码特征提取器:因为这样可以在更大的场景下对上下文进行感知,这样大物体和小物体都能在不同尺度的特征下被感受到(Tips:YOLOV3也是使用了FPN的思想提高了小目标的检测能力,因为大特征图里面的一个元素的值的感受野比较小,适合检测小物体。小特征图每个元素的感受野大,适合检测大物体。)
- (5)训练过程中使用了FocalLoss:因为能够支撑由大尺度方差产生出来的锚框。
- (6)高层的手掌检测器架构显示在图2
- (7)通过消融对比试验发现FocalLoss 比CrossEntropyLoss 要好

2.2 手部坐标预测模型 (Hand LandMark Model)
After running palm detection over the whole image, our subsequent hand landmark model performs precise landmark localization of 21 2.5D coordinates inside the detected hand regions via regression. The model learns a consistent internal hand pose representation and is robust even to partially visible hands and self-occlusions. The model has three outputs (see Figure 3):
- 21 hand landmarks consisting of x, y, and relative depth.
- A hand flag indicating the probability of hand presence in the input image.
- A binary classification of handedness, e.g. left or right hand
We use the same topology as [14] for the 21 landmarks. The 2D coordinates are learned from both real-world images as well as synthetic datasets as discussed below, with the relative depth w.r.t. the wrist point being learned only from synthetic images. To recover from tracking failure, we developed another output of the model similar to [8] for producing the probability of the event that a reasonably aligned hand is indeed present in the provided crop. If the score is lower than a threshold then the detector is triggered to reset tracking. Handedness is another important attribute for effective interaction using hands in AR/VR. This is especially useful for some applications where each hand is associated with a unique functionality. Thus we developed a binary classification head to predict whether the input hand is the left or right hand. Our setup targets real-time mobile GPU inference, but we have also designed lighter and heavier versions of the model to address CPU inference on the mobile devices lacking proper GPU support and higher accuracy requirements of accuracy to run on desktop, respectively
手掌检测器在全图上检测完之后,检测关键点坐标的模型通过回归来预测手部2.5D的关键点坐标。关键点坐标回归模型学到了内在的一致性手部姿态表示,因此在手部部分缺失或者自遮挡的情况下表现出非常好的鲁棒性,模型有三个输出(参见下图)
- (1)手部关键点坐标 X,Y和相对深度
- (2)输入图片包含收的置信度
- (3)左右还是右手二分类
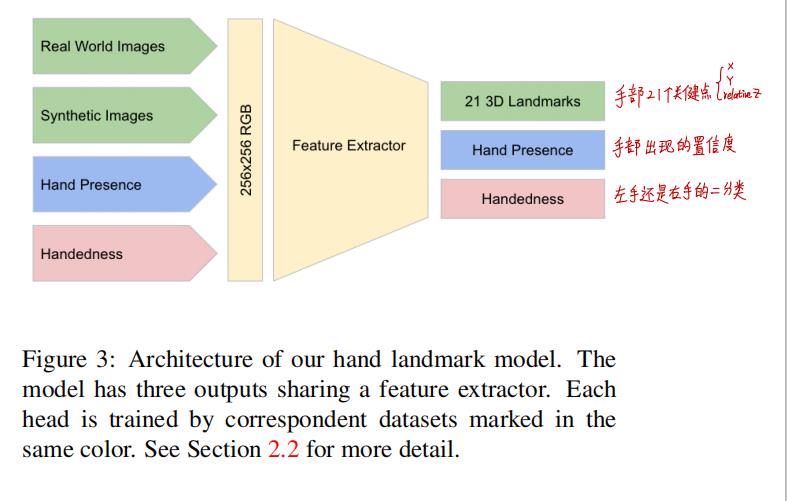
下面分别讨论模型的三类输出 - (1)手部21个关键点坐标
- 使用了和14号文献一样的拓扑结构
- 从真实世界的图片和合成的图片中学习到二维坐标 X,Y
- 从合成数据中学习到相对于手腕的三维深度坐标 Z
- (2)手存在的置信度
- 目的:为了从跟踪失败中恢复
- 来源:手部跟踪模型会额外输出这个手是否出现的置信度
- 使用:当输出的置信度低于阈值,则重置跟踪,重新使用手掌检测器;如果高于置信度,继续执行下面的手部关键点坐标的输出
- (3)左右手的二分类
- 意义:
- AR/VR有效交互中的重要属性
- 在每只手都有独特功能的一些应用中,分清左右手很重要
- 实现方法:开发了一个二分类的分类头来判断输入的手是左手还是右手
- 意义:
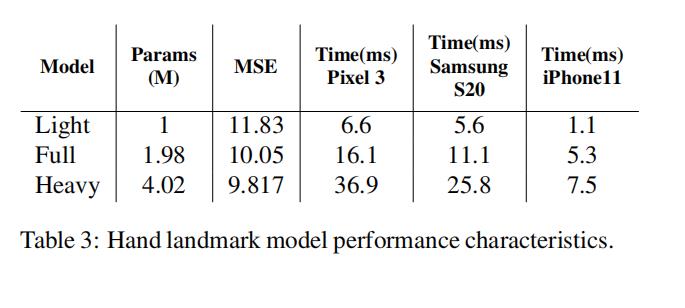
虽然我们的初始目标是在移动GPU上进行推理,但是我们也设计了更轻量级和更重量级的模型版本。更轻量级的模型可以在缺乏GPU支持的移动设备上运行,如果想获得更高的精度可以使用更重量级的模型来获得更高的精度。(不同类型模型的参数量、运行时间和测试设备等信息可参见下面的表3 ↓)
3. 数据集和标注 (DataSet And Annotation)
To obtain ground truth data, we created the following datasets addressing different aspects of the problem:
• In-the-wild dataset: This dataset contains 6K images of large variety, e.g. geographical diversity, various lighting conditions and hand appearance. The limitation of this dataset is that it doesn’t contain complex articulation of hands.
• In-house collected gesture dataset: This dataset contains 10K images that cover various angles of all physically possible hand gestures. The limitation of this dataset is that it’s collected from only 30 people with limited variation in background. The in-the-wild and in-house dataset are great complements to each other to improve robustness.
• Synthetic dataset: To even better cover the possible hand poses and provide additional supervision for depth, we render a high-quality synthetic hand model over various backgrounds and map it to the corresponding 3D coordinates. We use a commercial 3D hand model that is rigged with 24 bones and includes 36 blendshapes, which control fingers and palm thickness. The model also provides 5 textures with different skin tones. We created video sequences of transformation between hand poses and sampled 100K images from the videos. We rendered each pose with a random high-dynamic-range lighting environment and three different cameras. See Figure 4 for examples.
For the palm detector, we only use in-the-wild dataset, which is sufficient for localizing hands and offers the highest variety in appearance. However, all datasets are used for training the hand landmark model. We annotate the realworld images with 21 landmarks and use projected groundtruth 3D joints for synthetic images. For hand presence, we select a subset of real-world images as positive examples and sample on the region excluding annotated hand regions as negative examples. For handedness, we annotate a subset of real-world images with handedness to provide such data.
为了获得实况数据,我们创建了下面的三种数据集来解决问题的不同方面:
- (1)室外数据集:
- 简介:包含6千张不同类型的图片,例如不同几何形状、不同光照条件、不同手部外观
- 局限性:不包含复杂的手部的手指铰连。
- (2)室内收集的手势数据集:
- 简介:包含1万张图片,涵盖所有物理上可能的手势的不同角度
- 局限性:只收集了30个人的数据,并且背景变化有限。
- 解决办法:结合室内和室外的数据,他们可以互相补充对方的缺点,因此可以提高鲁棒性
- (3)合成数据集:
- 简介:包含从不同手部姿势的视频中采集的10万张图片
- 原因:为了更好的覆盖不同手部姿势并提供额外的深度监督信息
- 方法:我们使用了一个商用的3D手部模型,该模型由24块骨骼组成,包括36个混合形状,模型的手指和手掌的厚度可以单独控制,并且提供了5种不同肤色和纹理。我们使用这个工具在不同的背景下渲染了一个高质量的合成的手部模型,然后把相应的三维坐标映射到上面。
我们使用随机的高动态范围照明环境和三个不同的摄影机渲染每个姿势。有关示例,请参见下面的图4 ↓
第一排的四张图片是在室外图片上进行标注,第二排的四张图片是合成的图片上进行标注 ↓

4. 试验结果 (Result)
For the hand landmark model, our experiments show that the combination of real-world and synthetic datasets provides the best results. See Table 2 for details. We evaluate only on real-world images. Beyond the quality improvement, training with a large synthetic dataset leads to less jitter visually across frames. This observation leads us to believe that our real-world dataset can be enlarged for better generalization.
Our target is to achieve real-time performance on mobile devices. We experimented with different model sizes and found that the “Full” model (see Table 3) provides a good trade-off between quality and speed. Increasing model capacity further introduces only minor improvements in quality but decreases significantly in speed (see Table 3 for details). We use the TensorFlow Lite GPU backend for ondevice inference
通过各种不同的试验,我们得出了以下的结果:
- (1)对于手部关键点预测模型来说,结合真实数据集和合成数据集结果最好
试验步骤:详见下表2 (只使用了室外的图片进行模型评估)
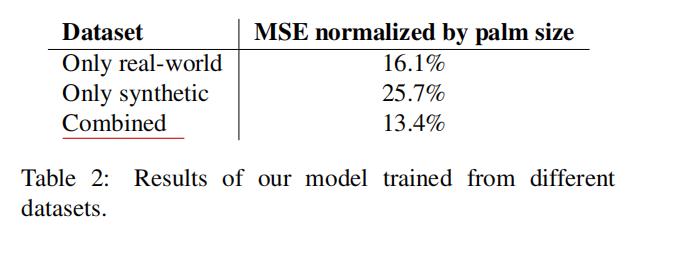
- (2)使用大型的合成数据集进行训练除了可以提高模型性能外,还能减少视频的帧间视觉抖动。
- (3)扩大真实世界的数据集可以增强模型的泛化能力
我们的目标是在移动设备上实现实时的性能,因此我们在不同模型大小上做了实验,这些模型在质量和速度方面做了不同的权衡,详见表格3 ↓
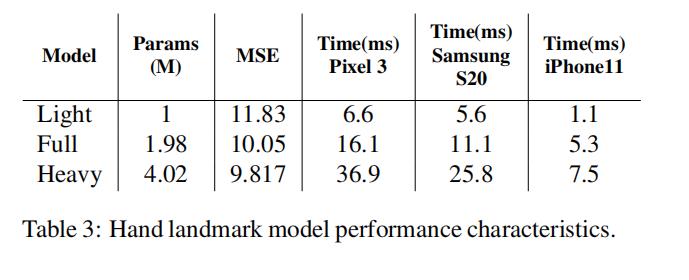
实验结果表明:增大模型容量可以提高模型精度,但是显著的降低推理速度。
Tips:以上实验我们使用TensorFlow Lite GPU 作为后端,进行实时的推理。
5. 使用MediaPipe的具体实现 (Implementation In MedisPipe)
With MediaPipe[12], our hand tracking pipeline can be built as a directed graph of modular components, called Calculators. Mediapipe comes with an extensible set of Calculators to solve tasks like model inference, media processing, and data transformations across a wide variety of devices and platforms. Individual Calculators like cropping, rendering and neural network computations are further optimized to utilize GPU acceleration. For example, we employ TFLite GPU inference on most modern phones.
Our MediaPipe graph for hand tracking is shown in Figure 5. The graph consists of two subgraphs one for hand detection and another for landmarks computation. One key optimization MediaPipe provides is that the palm detector only runs as needed (fairly infrequently), saving significant computation. We achieve this by deriving the hand location in the current video frames from the computed hand landmarks in the previous frame, eliminating the need to apply the palm detector on every frame. For robustness, the hand tracker model also outputs an additional scalar capturing the confidence that a hand is present and reasonably aligned in the input crop. Only when the confidence falls below a certain threshold is the hand detection model reapplied to the next frame.
在MediaPipe中,我们的手部追踪流水线是由被称为算子的模块化组件构成的有向图。MediaPipe附带一组可扩展的算子,这些算子可以在各种设备和平台上解决像模型推理,多媒体处理,数据转换等操作。独立的算子像裁剪,渲染和神经网络计算等,可以通过GPU进行优化。例如,我是使用在移动设备上使用TFLite GPU 进行推理。
我们手部跟踪方案在MediaPipe中实现的架构图如下:
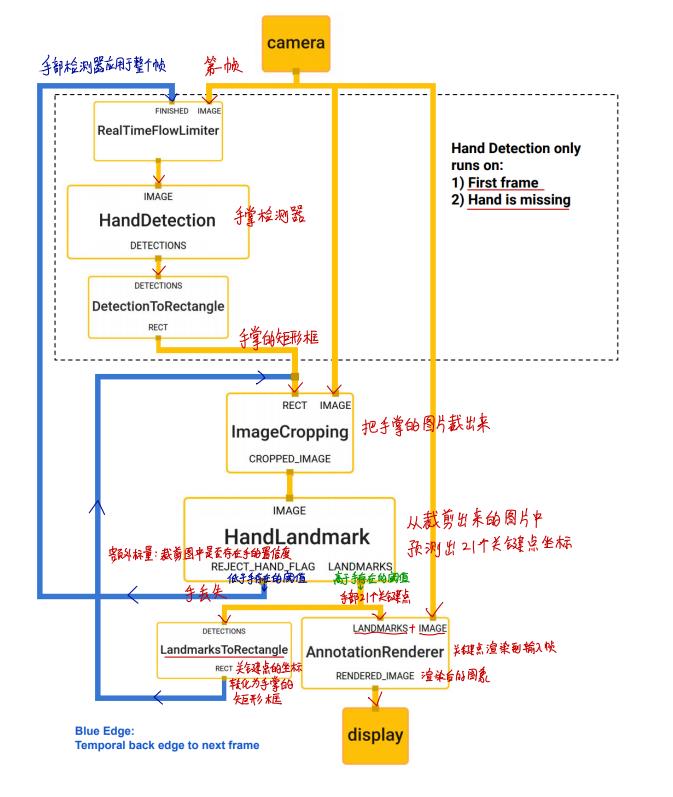
该架构图由2个子图构成:一个是手部检测图,另外一个计算手部关键点坐标。
下面介绍整个架构图:
- (1)概述:架构图由2个子图构成
- 手部检测子图
- 手部关键点计算子图
- (2)优化方向:
- 手掌检测器可以只在需要的时候才运行,这样可以节省大量的计算资源
- (3)实现方法:
- 从前一帧计算出来的关键点中导出手掌的定位,这样就会避免在每一帧上运行手掌检测器
为了增强模型的鲁棒性,手部跟踪模型还会多输出一个额外标量,该标量表示当前帧对齐的手部裁剪图片中出现手的概率。只有当这个置信度低于某个阈值的时候,手部检测模型才会在下一帧中使用(架构图中有相应的标注)
6. 应用举例 (Application examples)
Our hand tracking solution can readily be used in many applications such as gesture recognition and AR effects. On top of the predicted hand skeleton, we employ a simple algorithm to compute gestures, see Figure 6. First, the state of each finger, e.g. bent or straight, is determined via the accumulated angles of joints. Then, we map the set of finger states to a set of predefined gestures. This straightforward, yet effective technique allows us to estimate basic static gestures with reasonable quality. Beyond static gesture recognition, it is also possible to use a sequence of landmarks to predict dynamic gestures. Another application is to apply AR effects on top of the skeleton. Hand based AR effects currently enjoy high popularity. In Figure 7, we show an example AR rendering of the hand skeleton in neon light style.
我们的手部跟踪方法是开箱即用的,可以广泛应用在比如手势识别、AR/VR效果展示上。预测出手部骨架后,我们使用一种简单算法来推导手势,如图6。

首先,关节的弯曲角度决定每根手指的状态(弯曲或伸直)。随后,我们将这组手指状态映射为一组预定义的手势。利用这种直接而有效的方法,我们可以估算出基本的静态手势,同时保证检测质量。现有流水线支持计算多种文化背景(如美国、欧洲和中国)下的手势,以及各种手势标志,包括 “非常棒”、握拳、“好的”、“摇滚” 和 “蜘蛛侠”。
另一个应用是在骨架上使用AR特效,这种基于手的AR效果目前很受欢迎。在图7中,我们以霓虹灯样式显示手骨架的AR渲染示例。

7. 结论 (Conclution)
In this paper, we proposed MediaPipe Hands, an end-toend hand tracking solution that achieves real-time performance on multiple platforms. Our pipeline predicts 2.5D landmarks without any specialized hardware and thus, can be easily deployed to commodity devices. We open sourced the pipeline to encourage researchers and engineers to build gesture control and creative AR/VR applications with our pipeline.
在本文中,我们提出了MediaPipe Hands,这是一种端到端的手跟踪解决方案,可在多个平台上实现实时性能。我们的流水线模型可以在无需任何专用硬件情况下预测2.5D的关键点坐标,并且可以轻松部署到商品设备上。我们将流水线开源,以鼓励研究人员和工程师利用我们的流水线构建手势控制和创造性的AR/VR应用程序。
参考文献:
[1]. 使用 MediaPipe 实现设备端实时手部追踪
如果有人感兴趣,可以参考我在原文PDF上写的标注,下载地址
以上是关于MediaPipe Hands: On-device Real-time Hand Tracking 论文阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章
OpenCV+Mediapipe手势动作捕捉与Unity引擎的结合
MediaPipe上手案例,手部骨架识别,用视频替换代码摄像头采集