Python爬虫实战:1000图库大全别轻易点进来
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战:1000图库大全别轻易点进来相关的知识,希望对你有一定的参考价值。
大家好,我是辣条。
今天给大家带来【爬虫实战100例】之41篇,爬虫之路永无止境。
爬取目标
网址:尺度有点大,遭不住...
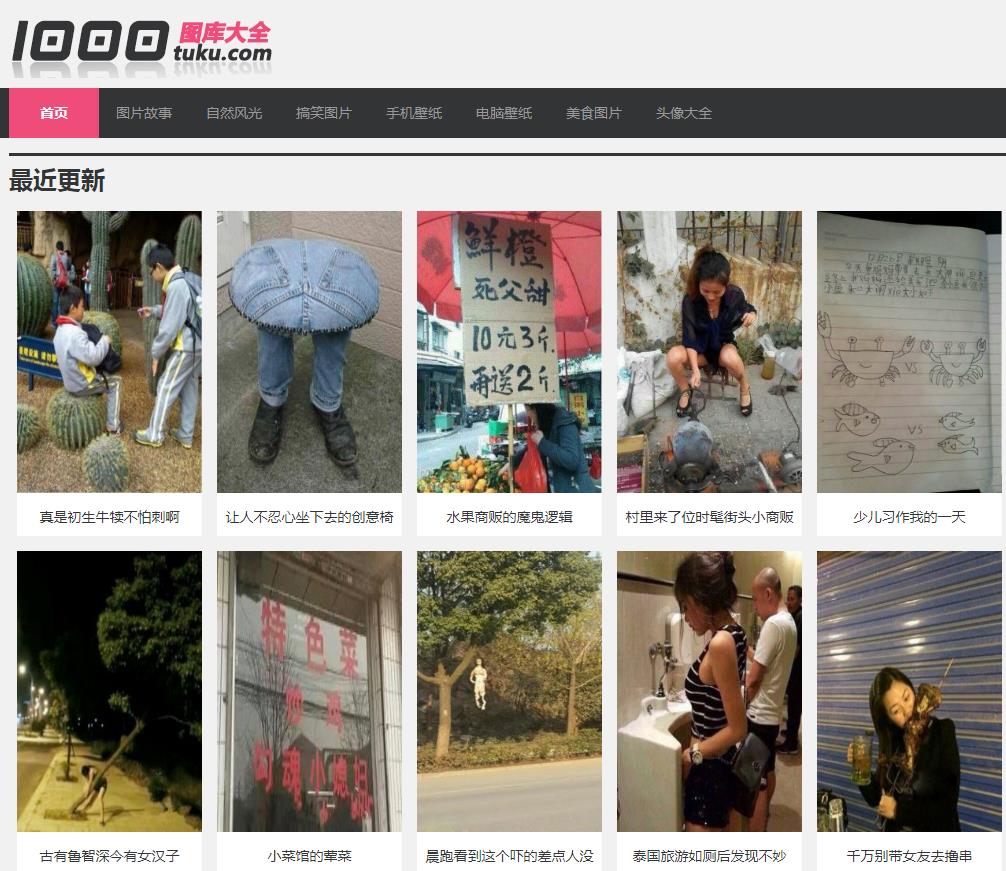
效果展示
工具准备
开发工具:pycharm 开发环境:python3.7, Windows11 使用工具包:requests
项目解析思路
获取当当前网页的跳转地址,当前页面为主页面数据,我们需要的数据别有一番天地,获取到网页信息提取出所有的跳转地址,获取到源码里的a标签就行当前网页的加载方式为静态数据,直接请求网页地址;
url = 'https://www.xxxx.com/
从源代码里提取到所以的跳转地址
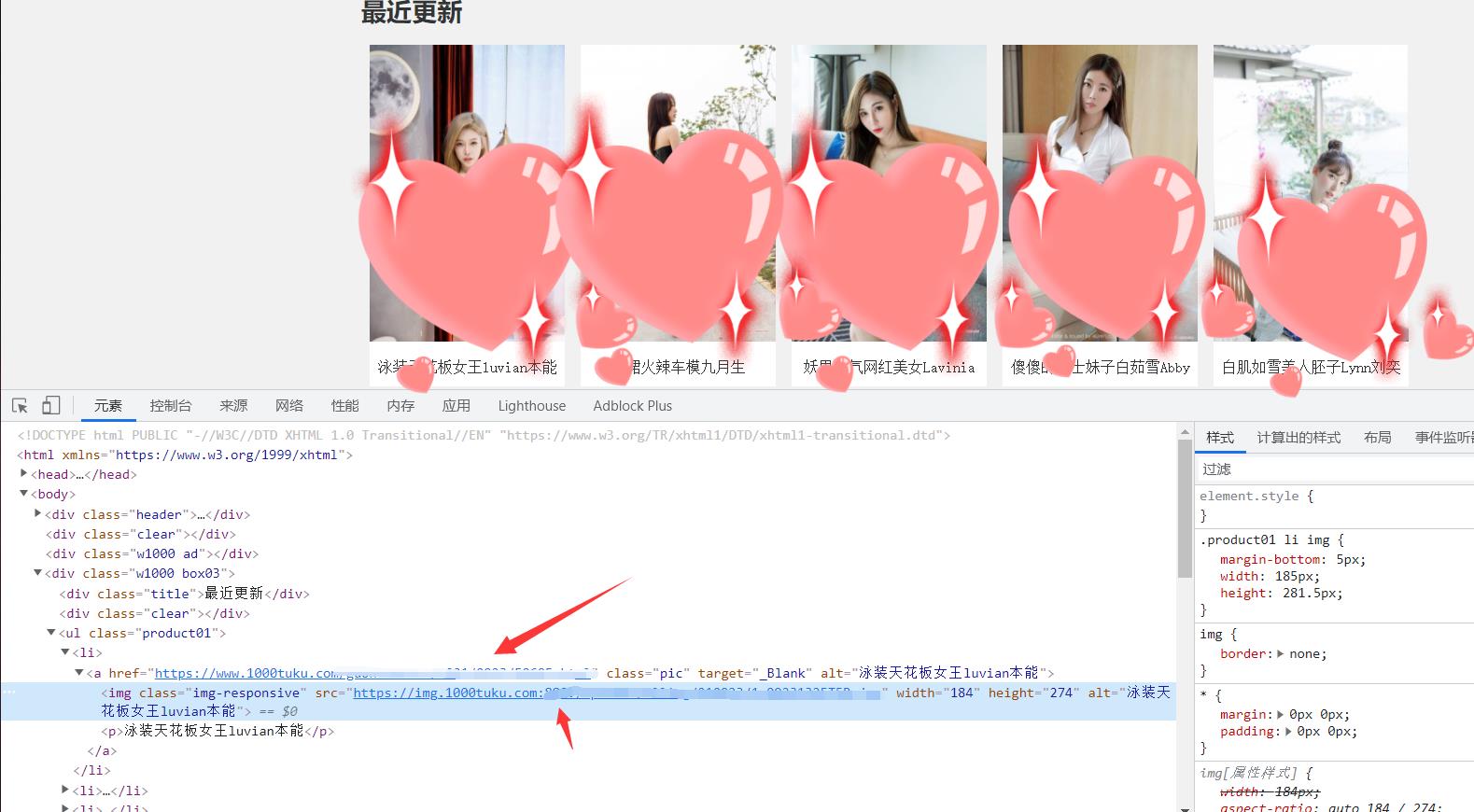
提取的方式可自行选择,小编这里使用正则的方式提取数据,提取详情页面的地址以及标题,用来保存图片起名字,获取到进入详情页面的地址后对地址发送请求,详情页面的数据也分为很多的页面,每个页面有好几张图片,需要对网址进行拼接,构造出新的地址信息,
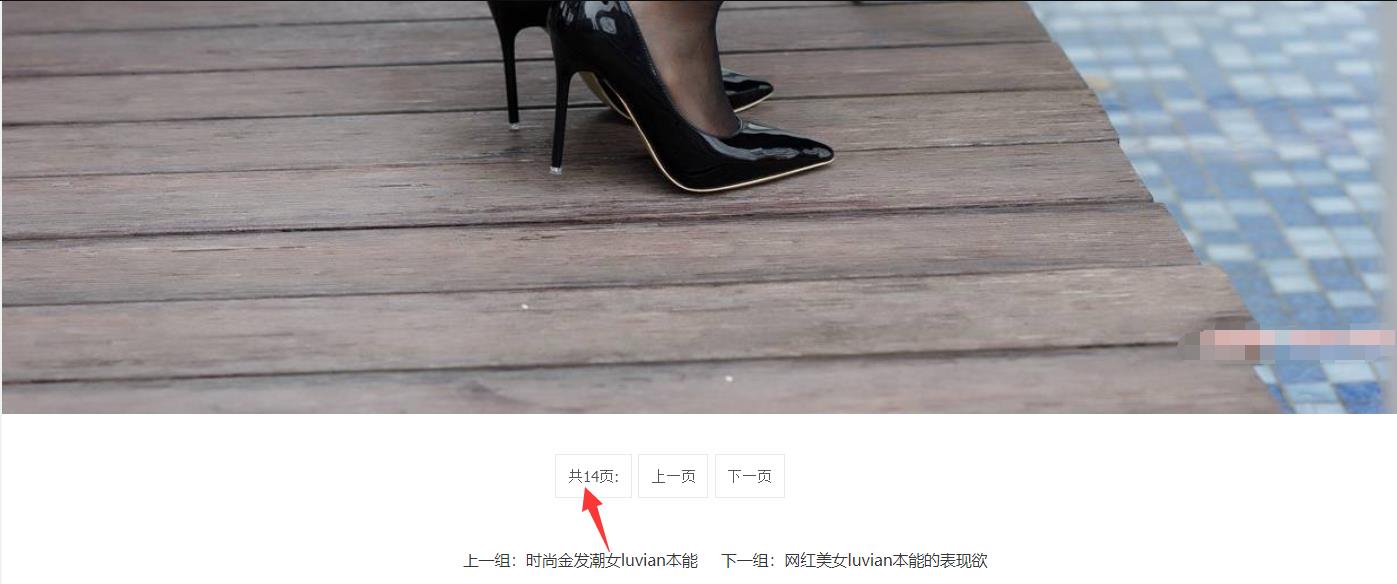
for i in range(1, int(page_num[0]) + 1):
if i == 1:
new_url = info_url
else:
new_url = info_url.replace('.html', f'_{i}.html')
# print(new_url)
jpg_data = requests.get(new_url, headers=headers).content.decode('gbk')请求之后提取出所有的图片地址在对图片地址发送请求,保存数据大功告成!!
简易源码分享
import requests
import re
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
for i in range(1, 20):
url = 'https://www.xxxx.com/guoneimeinv/list_5_{}.html'.format(i)
response = requests.get(url, headers=headers)
# print(response.content.decode('gbk'))
# 提取想要的数据信息
data_list = re.findall('</a> </li><li><a href="(.*?)" class="pic" target="_Blank" alt="(.*?)">', response.content.decode('gbk'))
# print(data_list)
num = 0
for info_url, title in data_list:
# print(info_url)
# print(title)
res = requests.get(info_url, headers=headers).content.decode('gbk')
# print(res)
page_num = re.findall('<li><a>共(.*?)页: </a></li><li>', res)
# print(page_num)
for i in range(1, int(page_num[0]) + 1):
if i == 1:
new_url = info_url
else:
new_url = info_url.replace('.html', f'_{i}.html')
# print(new_url)
jpg_data = requests.get(new_url, headers=headers).content.decode('gbk')
# print(jpg_data)
jpg_url_list = re.findall('<p align="center"><img src="(.*?)" /></p><br/>', jpg_data)
# print(jpg_url_list)
for jgp_url in jpg_url_list:
result = requests.get(jgp_url, headers=headers).content
f = open('1000图库/' + title + "-" + str(num) + ".jpg", 'wb')
f.write(result)
num += 1
print(f"正在下载{title}第{num}张")👇🏻 疑难解答、学习资料、路线图可通过搜索下方 👇🏻
以上是关于Python爬虫实战:1000图库大全别轻易点进来的主要内容,如果未能解决你的问题,请参考以下文章