这样的Python爬虫实战项目谁不爱呢——Python实现抓取知乎弹幕
Posted python 封神榜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这样的Python爬虫实战项目谁不爱呢——Python实现抓取知乎弹幕相关的知识,希望对你有一定的参考价值。
前言
利用Python实现抓取知乎热点话题,废话不多说。
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
requests模块;
re模块;
pandas模块;
lxml模块;
random模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
思路分析
本文以爬取知乎热点话题《如何看待网传腾讯实习生向腾讯高层提出建议颁布拒绝陪酒相关条令?》为例
目标网址
https://www.zhihu.com/question/478781972
网页分析
经过查看网页源代码等方式,确定该网页回答内容为动态加载的,需要进入浏览器的开发者工具进行抓包。进入Noetwork→XHR,用鼠标在网页向下拉取,得到我们需要的数据包
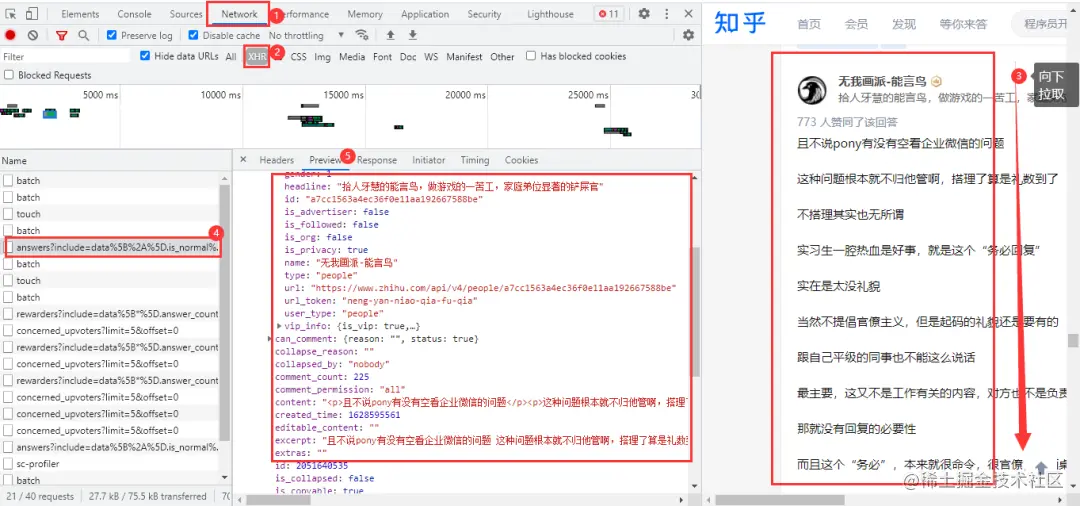
得到的准确的URL
https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&platform=desktop&sort_by=default
https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=5&platform=desktop&sort_by=default
URL有很多不必要的参数,大家可以在浏览器中自行删减。两条URL的区别在于后面的offset参数,首条URL的offset参数为0,第二条为5,offset是以公差为5递增;网页数据格式为json格式。
代码实现
import requests\\
import pandas as pd\\
import re\\
import time\\
import random\\
\\
df = pd.DataFrame()\\
headers = {\\
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/81.0.4044.138 Safari/537.36'\\
}\\
for page in range(0, 1360, 5):\\
url = f'https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={page}&platform=desktop&sort_by=default'\\
response = requests.get(url=url, headers=headers).json()\\
data = response['data']\\
for list_ in data:\\
name = list_['author']['name'] # 知乎作者\\
id_ = list_['author']['id'] # 作者id\\
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # 回答时间\\
voteup_count = list_['voteup_count'] # 赞同数\\
comment_count = list_['comment_count'] # 底下评论数\\
content = list_['content'] # 回答内容\\
content = ''.join(re.findall("[\\u3002\\uff1b\\uff0c\\uff1a\\u201c\\u201d\\uff08\\uff09\\u3001\\uff1f\\u300a\\u300b\\u4e00-\\u9fa5]", content)) # 正则表达式提取\\
print(name, id_, created_time, comment_count, content, sep='|')\\
dataFrame = pd.DataFrame(\\
{'知乎作者': [name], '作者id': [id_], '回答时间': [created_time], '赞同数': [voteup_count], '底下评论数': [comment_count],\\
'回答内容': [content]})\\
df = pd.concat([df, dataFrame])\\
time.sleep(random.uniform(2, 3))\\
df.to_csv('知乎回答.csv', encoding='utf-8', index=False)\\
print(df.shape)
效果展示
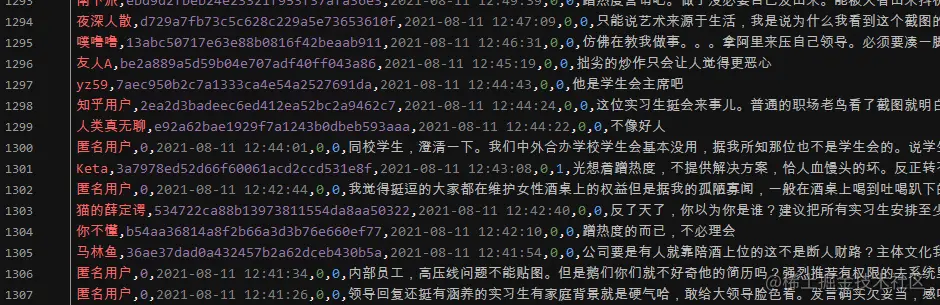
————————————————————————————————————————————
以上是关于这样的Python爬虫实战项目谁不爱呢——Python实现抓取知乎弹幕的主要内容,如果未能解决你的问题,请参考以下文章