HA高可用+hive+hbase+sqoop+kafka+flume+spark安装部署
Posted 慕铭yikm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HA高可用+hive+hbase+sqoop+kafka+flume+spark安装部署相关的知识,希望对你有一定的参考价值。
目录
前言
备战2021 年“湖北省工匠杯”技能大赛——大数据技术应用竞赛,附上资料链接,若有错误之处请指正。相关文章在博客都有写到,大家可以参考参考。

资料
链接:https://pan.baidu.com/s/162xqYRVSJMy_cKVlWT4wjQ
提取码:yikm
HA高可用部署
请移步HA高可用搭建,参考文章完成HA高可用部署。
Hive安装部署
请移步构建数据仓库赛题解析,参考文章完成Hive安装部署。
Hbase安装部署
请移步HBASE安装,参考文章完成Hbase安装部署。
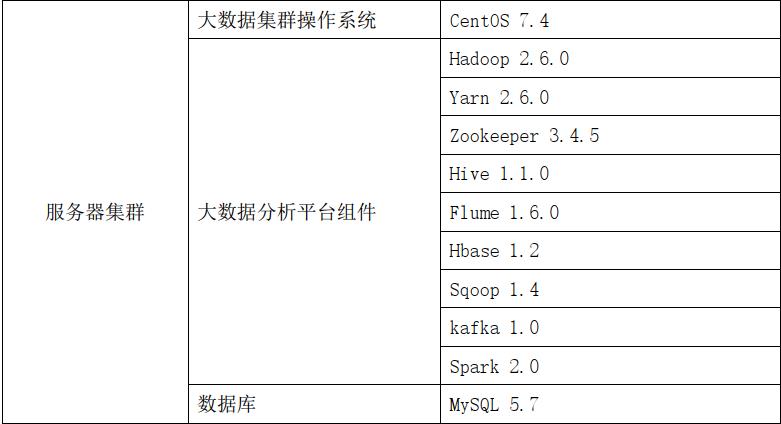
需注意:hbase-site.xml文件
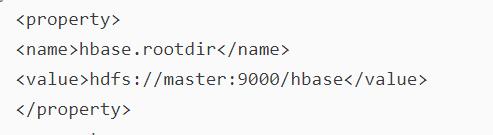 :
:
master:9000应该改为mycluster

sqoop安装部署
解压安装包
mkdir /usr/sqoop
tar -zxvf /usr/package/sqoop-1.4.7.bin.tar.gz -C /usr/sqoop/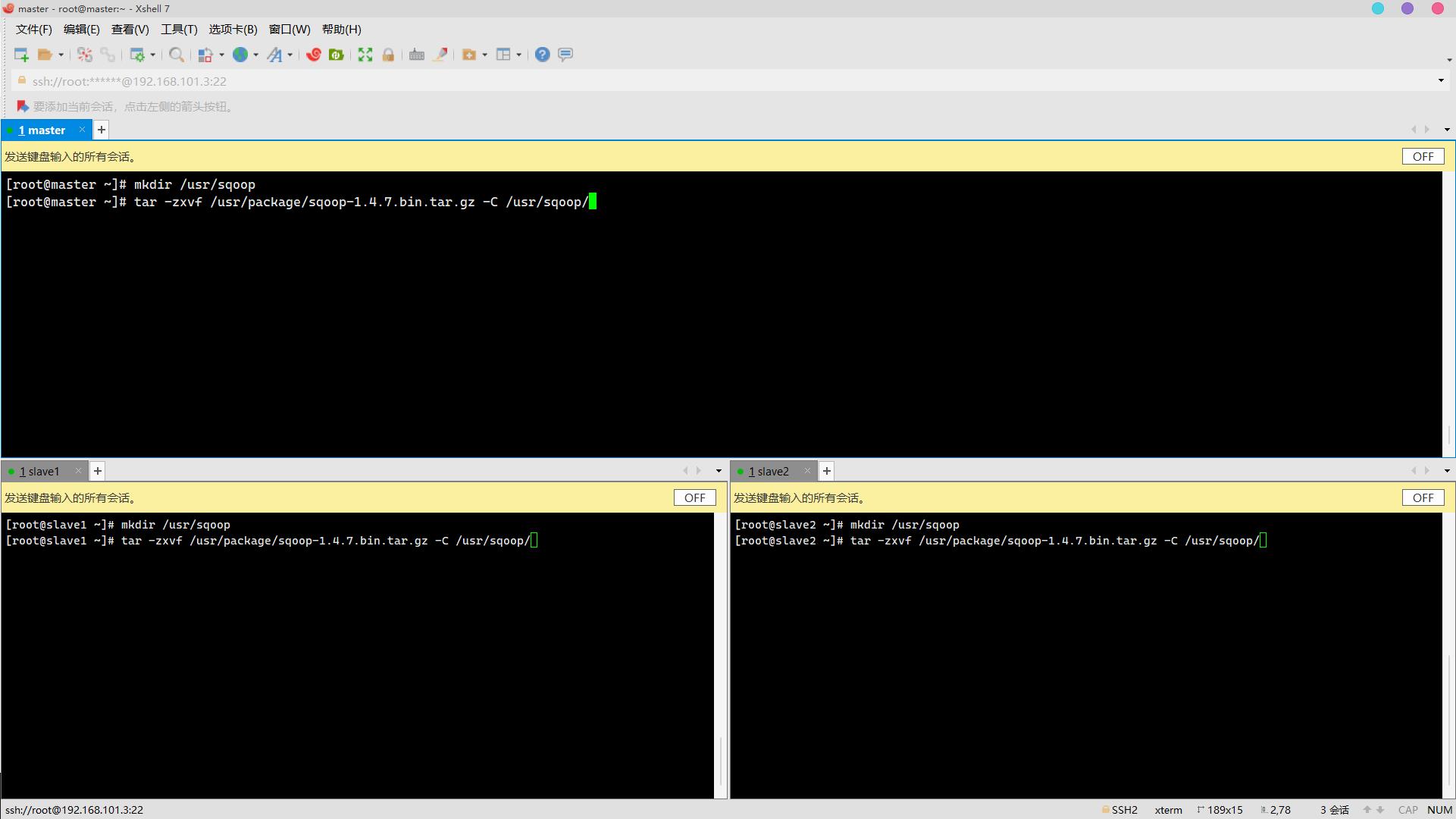
修改配置文件
环境变量
vim /etc/profile添加:
#sqoop
export SQOOP_HOME=/usr/sqoop/sqoop-1.4.7.bin
export PATH=$PATH:$SQOOP_HOME/bin
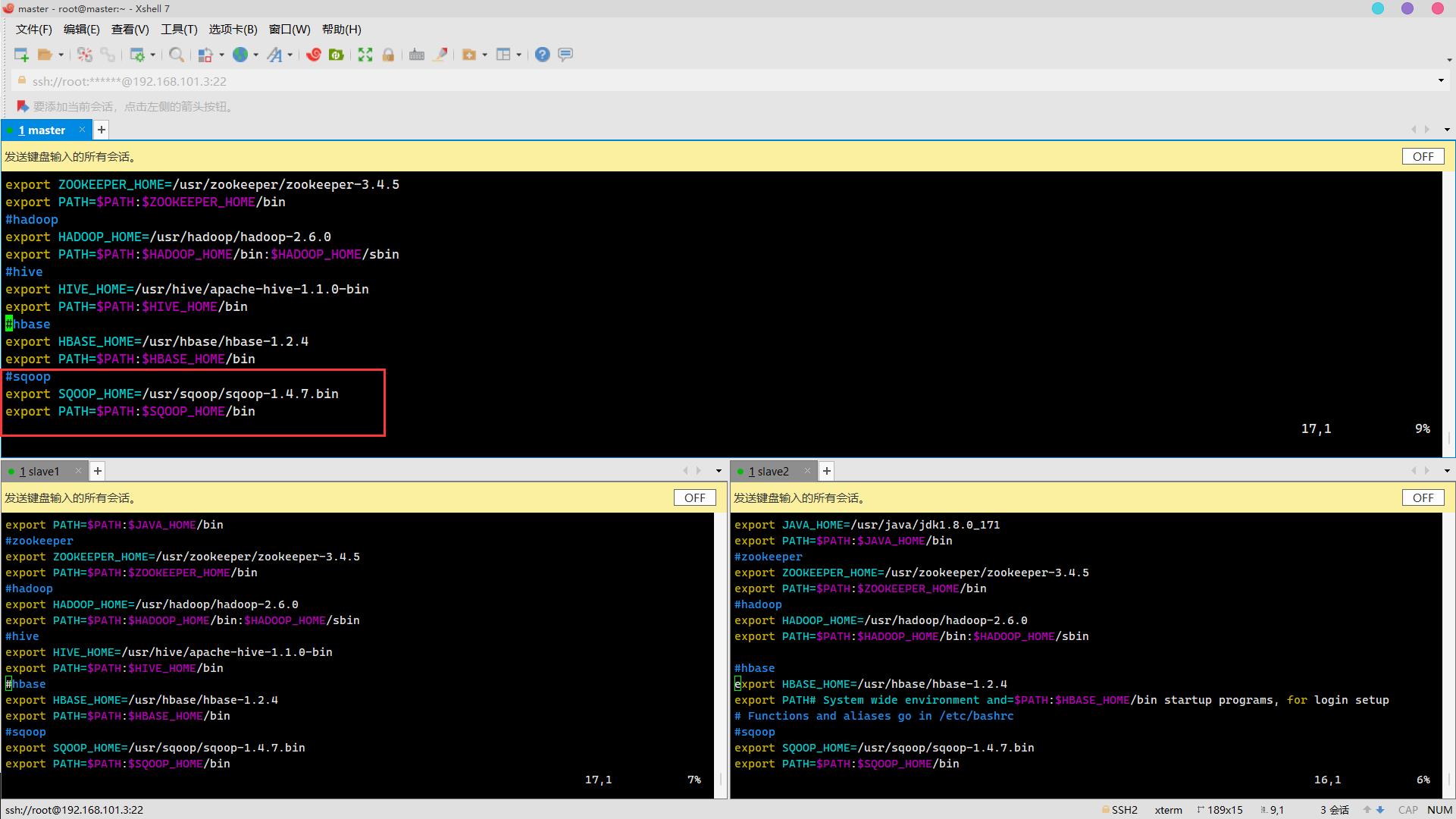
生效环境变量
source /etc/profile
查看
sqoop version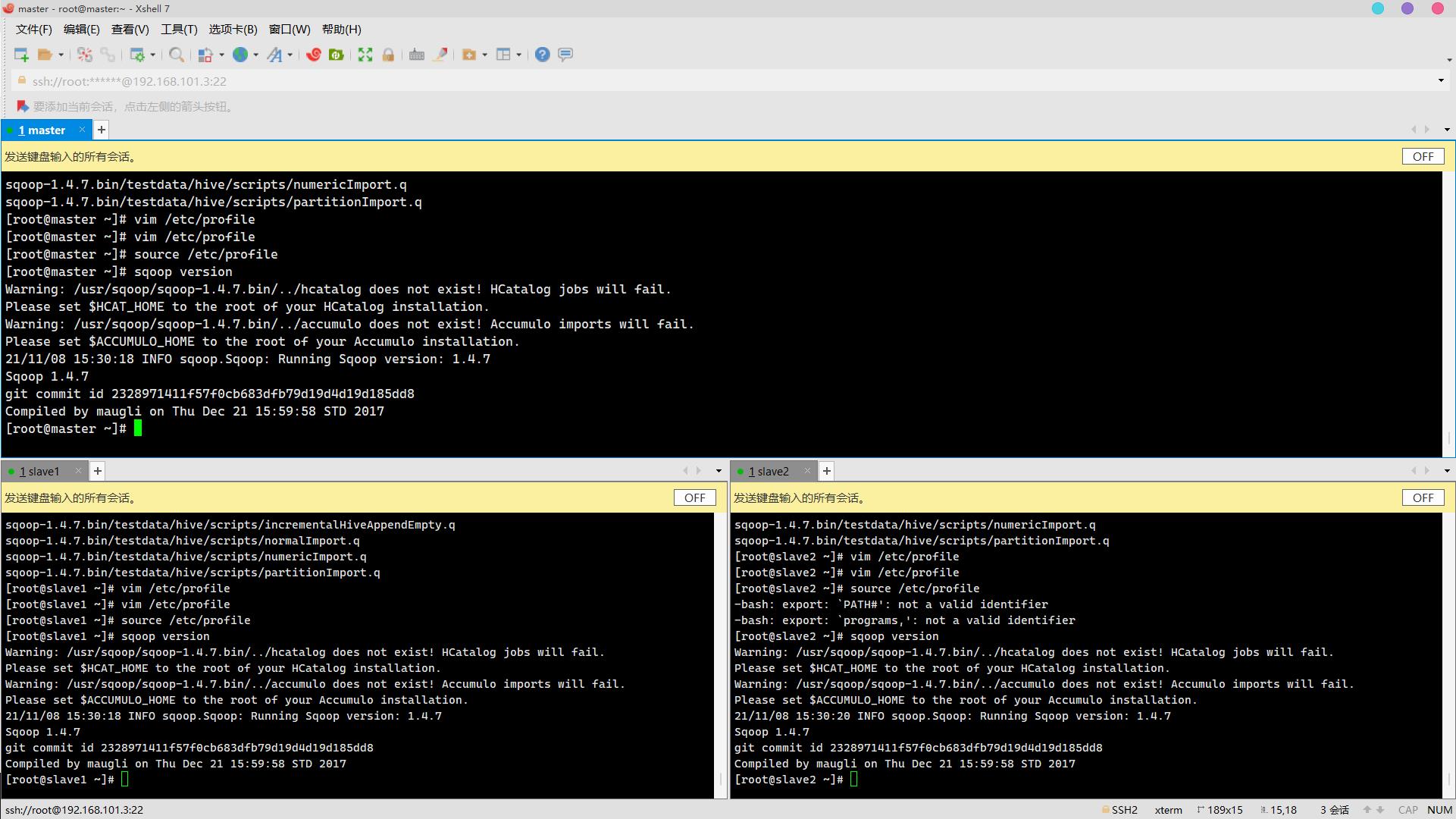
sqoop-env.sh
cd /usr/sqoop/sqoop-1.4.7.bin/conf/
mv sqoop-env-template.sh sqoop-env.sh
echo "export HADOOP_COMMON_HOME=/usr/hadoop/hadoop-2.6.0
export HADOOP_MAPRED_HOME=/usr/hadoop/hadoop-2.6.0
export HIVE_HOME=/usr/hive/apache-hive-1.1.0-bin
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.5
export ZOOCFGDIR=/usr/zookeeper/zookeeper-3.4.5" >> sqoop-env.sh
cat sqoop-env.sh
拷贝JDBC驱动
cp /usr/package/mysql-connector-java-5.1.47-bin.jar /usr/sqoop/sqoop-1.4.7.bin/lib/
测试Sqoop是否能够成功连接数据库
我的集群是slave2作为存储数据库的。
sqoop list-databases --connect jdbc:mysql://slave2:3306/ --username root --password 123456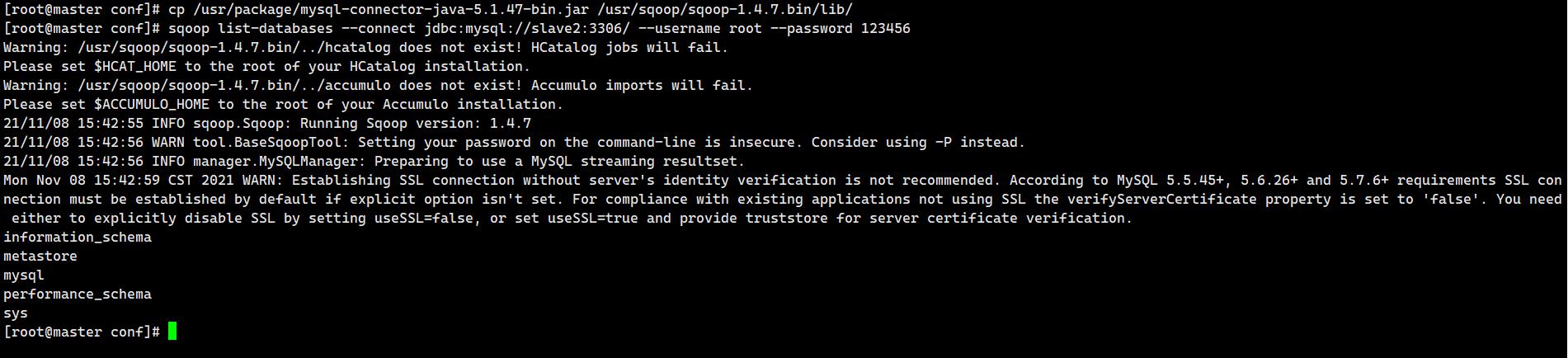
kafka安装部署
解压安装包
mkdir /usr/kafka
tar -zxvf /usr/package/kafka_2.11-1.0.0.tgz -C /usr/kafka/环境变量
vim /etc/profile添加 :
#kafka
export KAFKA_HOME=/usr/kafka/kafka_2.11-1.0.0
export PATH=$PATH:$KAFKA_HOME/bin

生效环境变量
source /etc/profile配置文件
创建logs文件夹
cd /usr/kafka/kafka_2.11-1.0.0/
mkdir logszookeeper.properties
修改dataDir与zookeeper中zoo.cfg一致
cd /usr/kafka/kafka_2.11-1.0.0/config
vim zookeeper.properties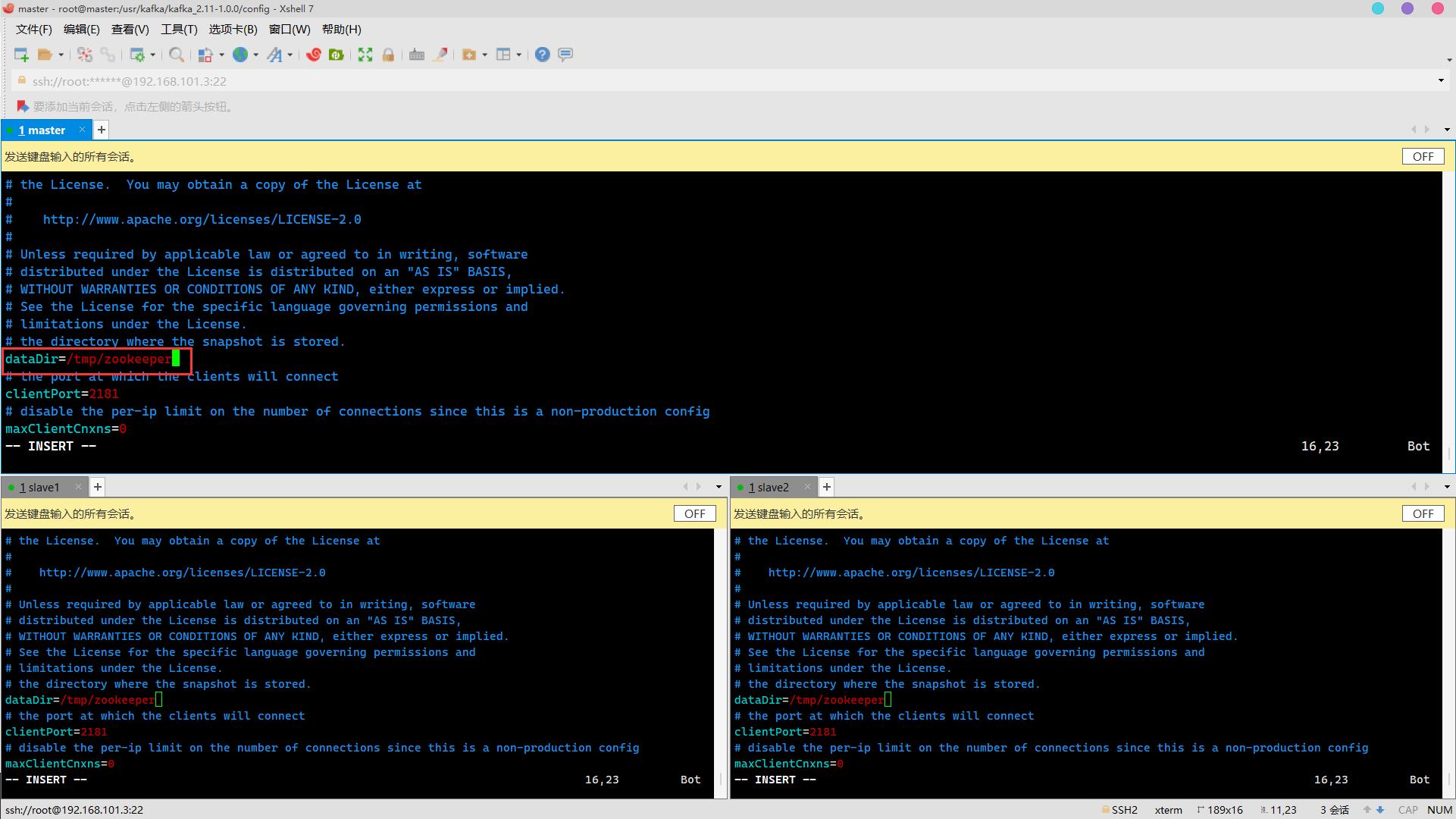
修改为
dataDir=/usr/zookeeper/zookeeper-3.4.5/zkdata

server.properties
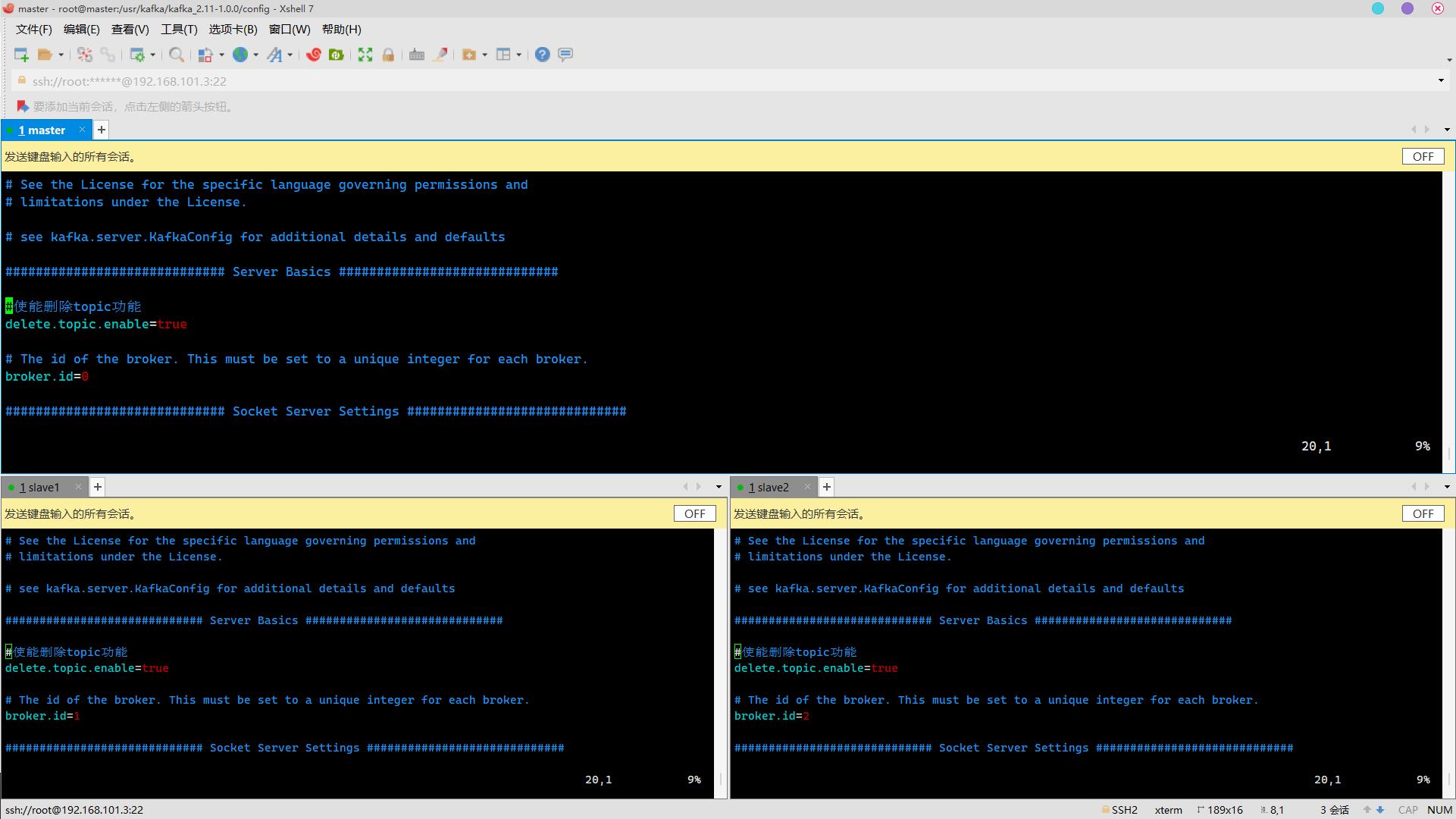
vim server.propertiesbroker.id修改
master上为0,slave1上为1,slave2上为2

注:broker.id不得重复
log.dirs修改

修改为
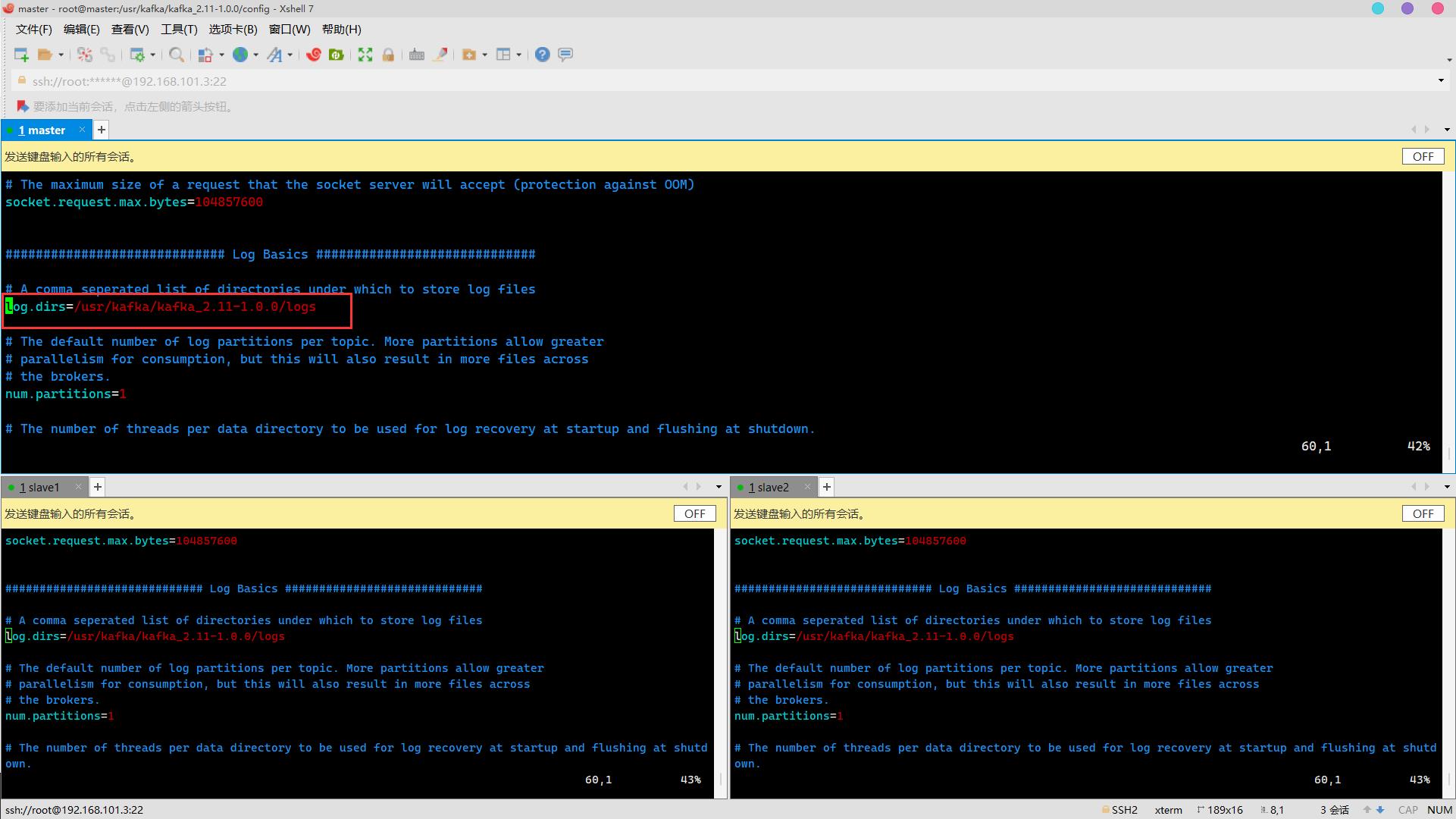
使能删除topic功能
增加
#使能删除topic功能
delete.topic.enable=true
配置连接Zookeeper集群地址
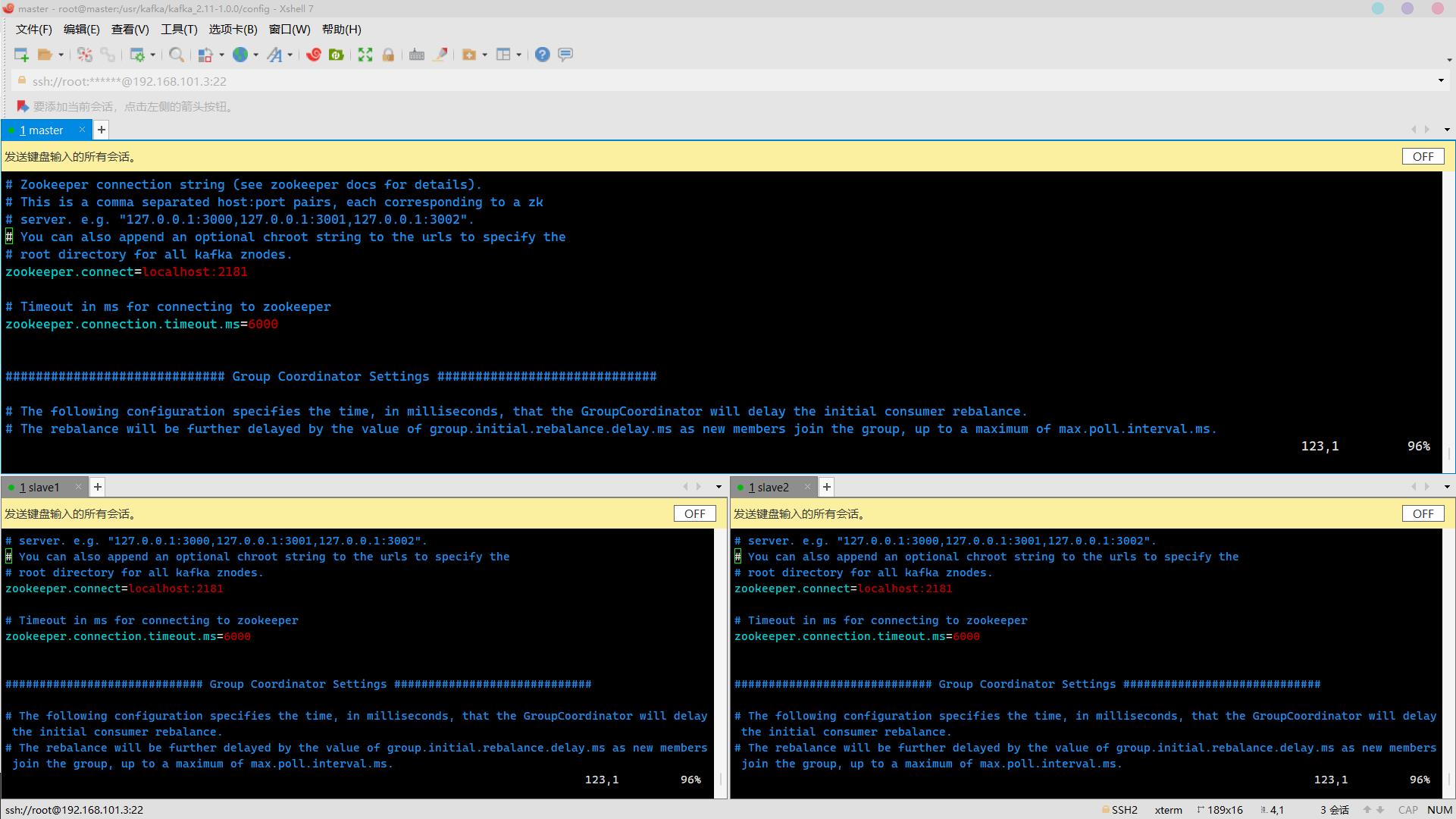
修改为
zookeeper.connect=master:2181,slave1:2181,slave2:2181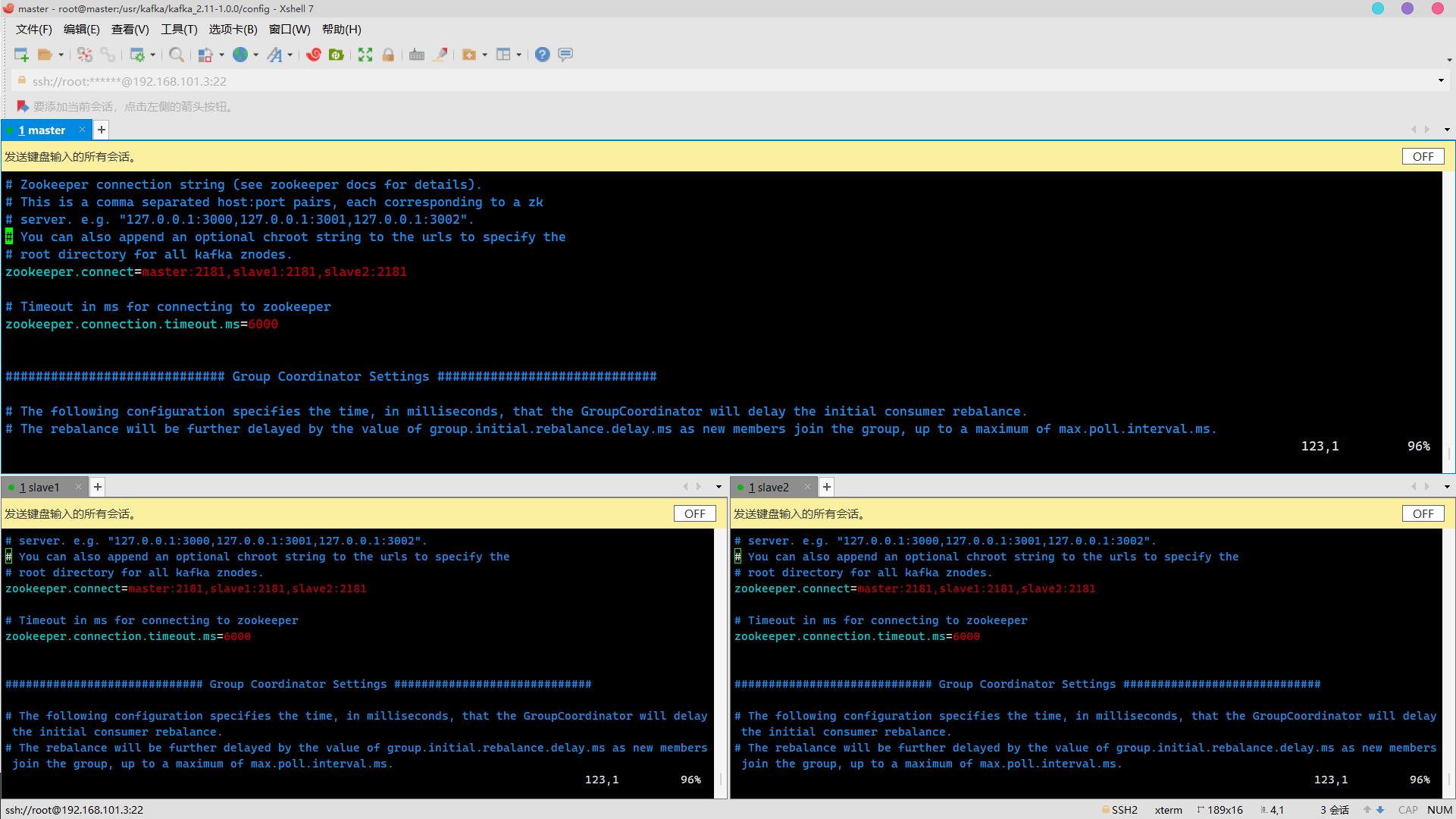
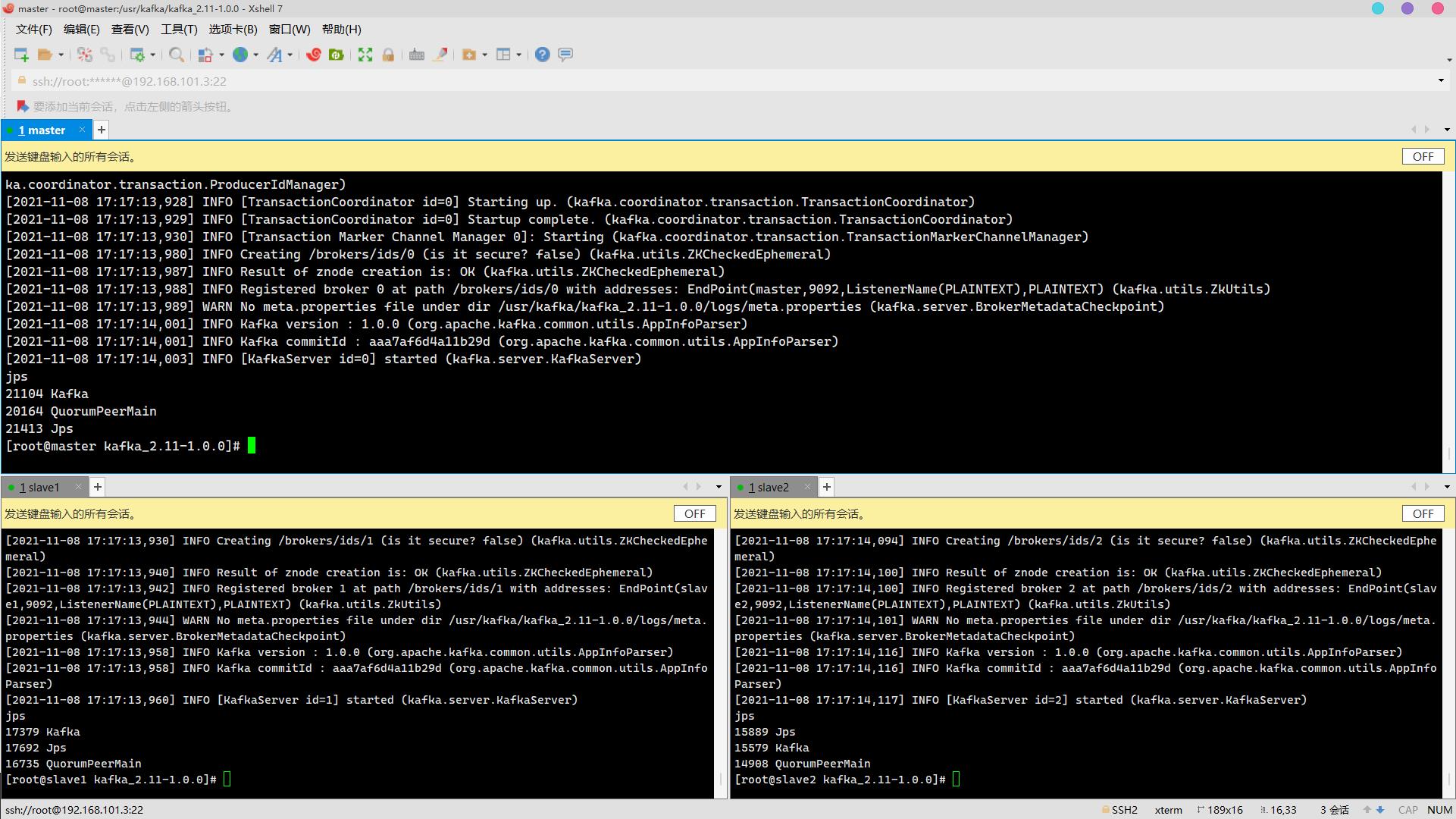
启动集群
启动zookeeper
/usr/zookeeper/zookeeper-3.4.5/bin/zkServer.sh start启动kafka
cd /usr/kafka/kafka_2.11-1.0.0/
bin/kafka-server-start.sh config/server.properties &
jps
验证
仅在master下
查看当前服务器中的所有topic
bin/kafka-topics.sh --zookeeper master:2181 --list创建topic
bin/kafka-topics.sh --zookeeper master:2181 --create --replication-factor 3 --partitions 1 --topic first选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数

关闭集群
bin/kafka-server-stop.sh stop
//等待消息弹出停止再输入
jps
/usr/zookeeper/zookeeper-3.4.5/bin/zkServer.sh stop
jps
flume安装部署
解压安装包
mkdir /usr/flume
tar -zxvf /usr/package/apache-flume-1.6.0-bin.tar.gz -C /usr/flume/
配置环境变量
vim /etc/profile添加:
#flume
export FLUME_HOME=/usr/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin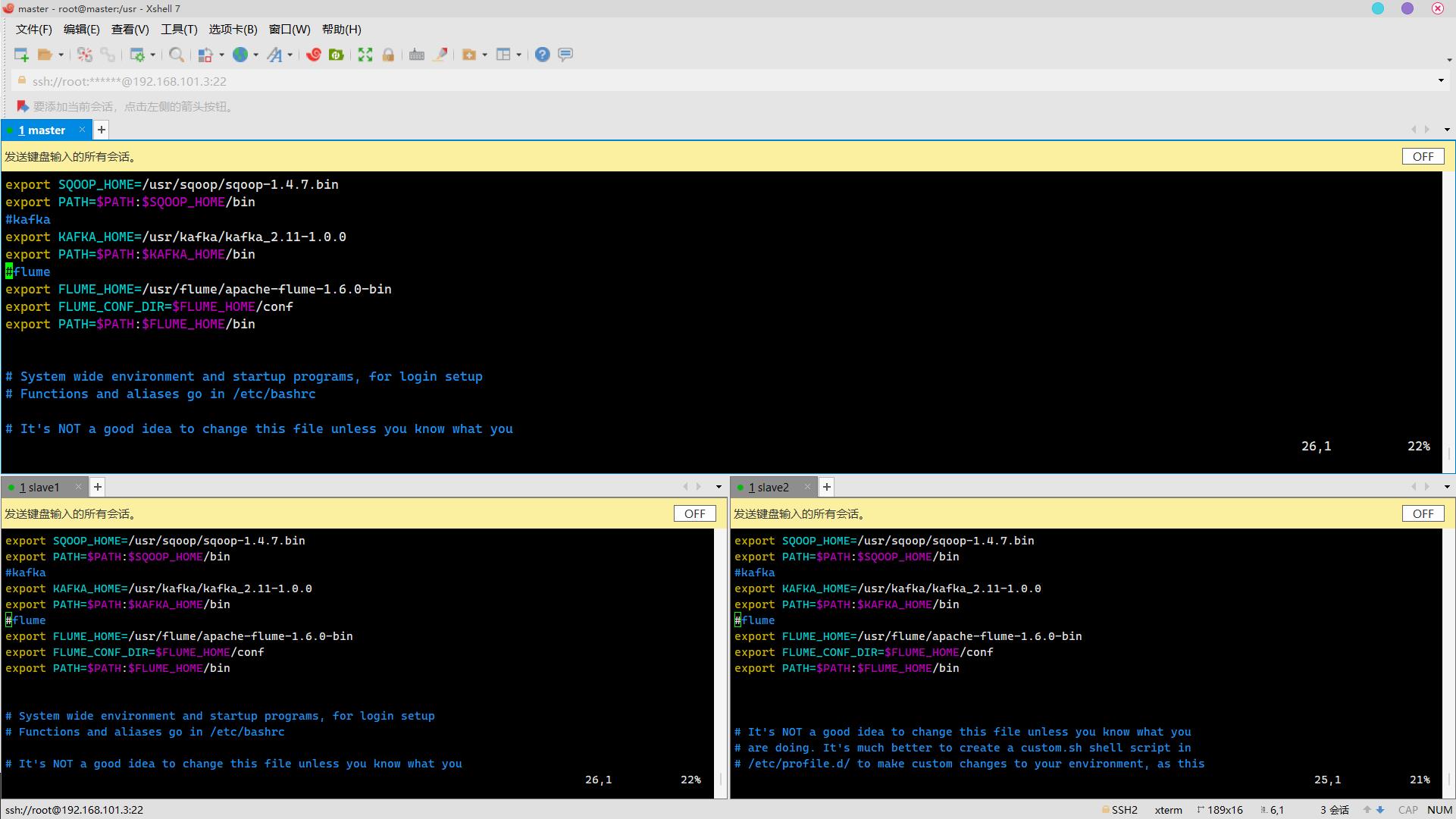
生效环境变量
source /etc/profileflume-env.sh
cd /usr/flume/apache-flume-1.6.0-bin/conf/
mv flume-env.sh.template flume-env.sh
echo "export JAVA_HOME=/usr/java/jdk1.8.0_171" >> flume-env.sh
cat flume-env.sh
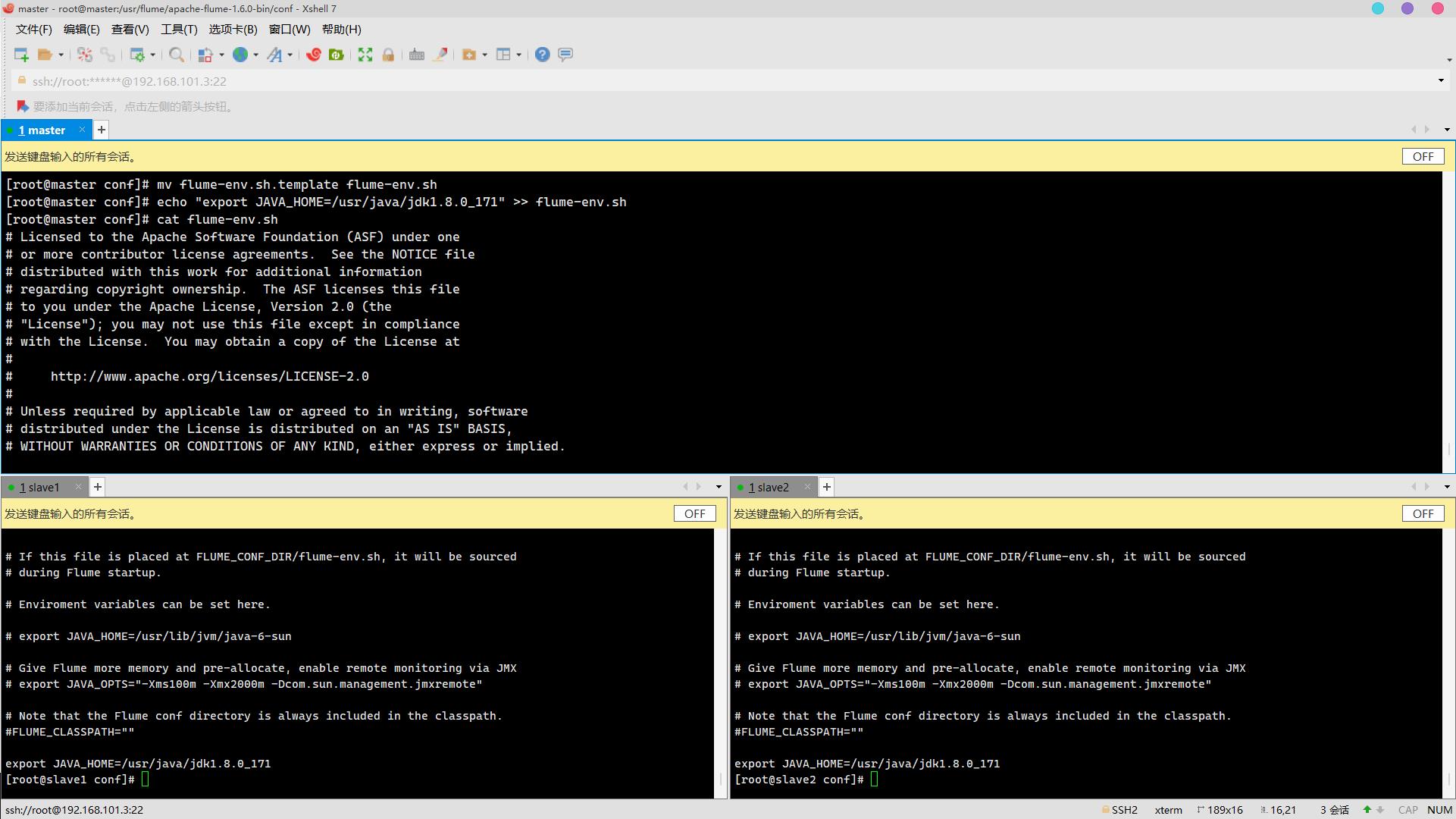
查看
flume-ng version报错
Error: Could not find or load main class org.apache.flume.tools.GetJavaProperty
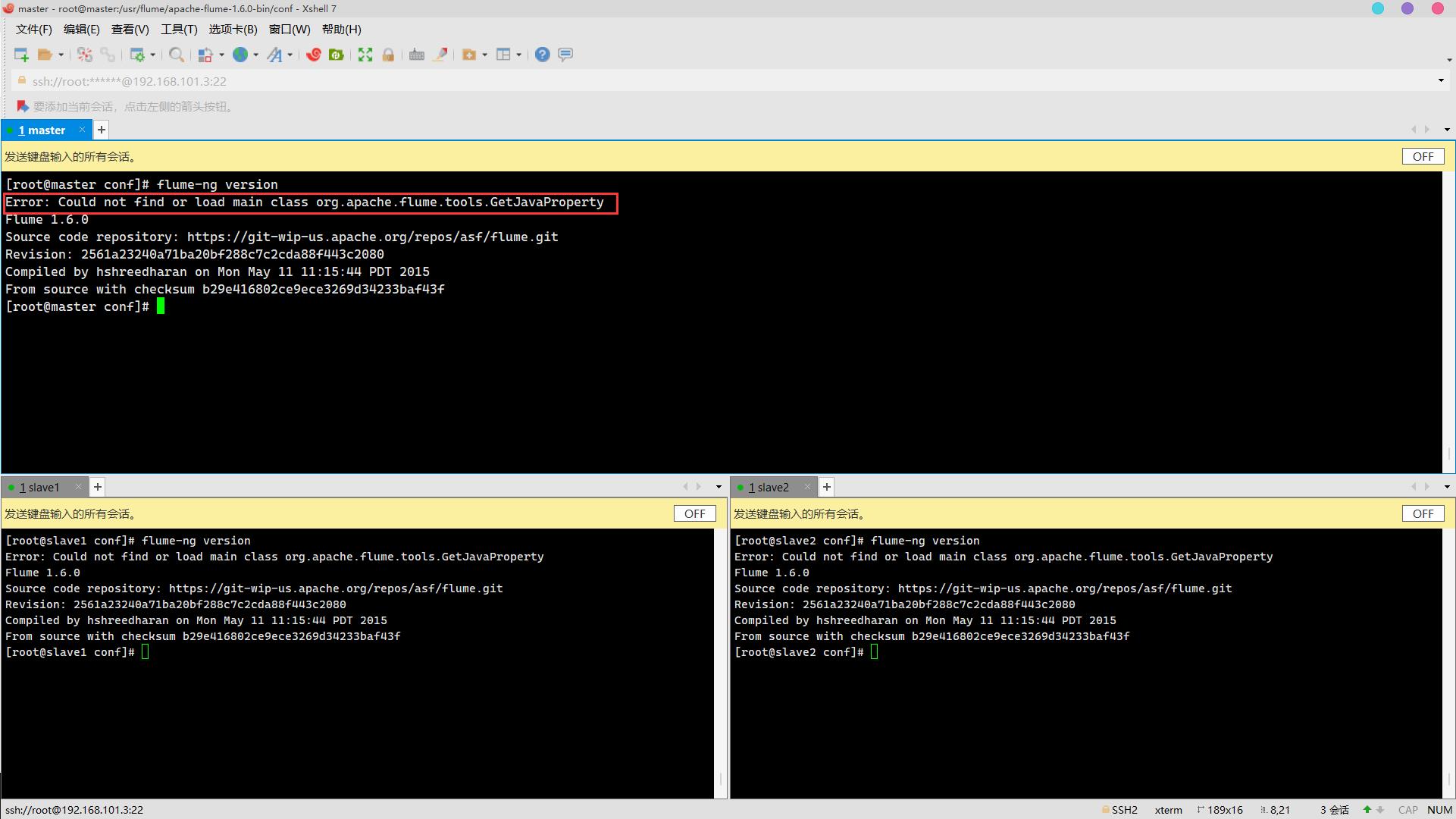
解决方案
flume-ng脚本问题
解决办法
cd /usr/flume/apache-flume-1.6.0-bin/bin/
vim flume-ng
//在124行增加以下内容
2>/dev/null | grep hbase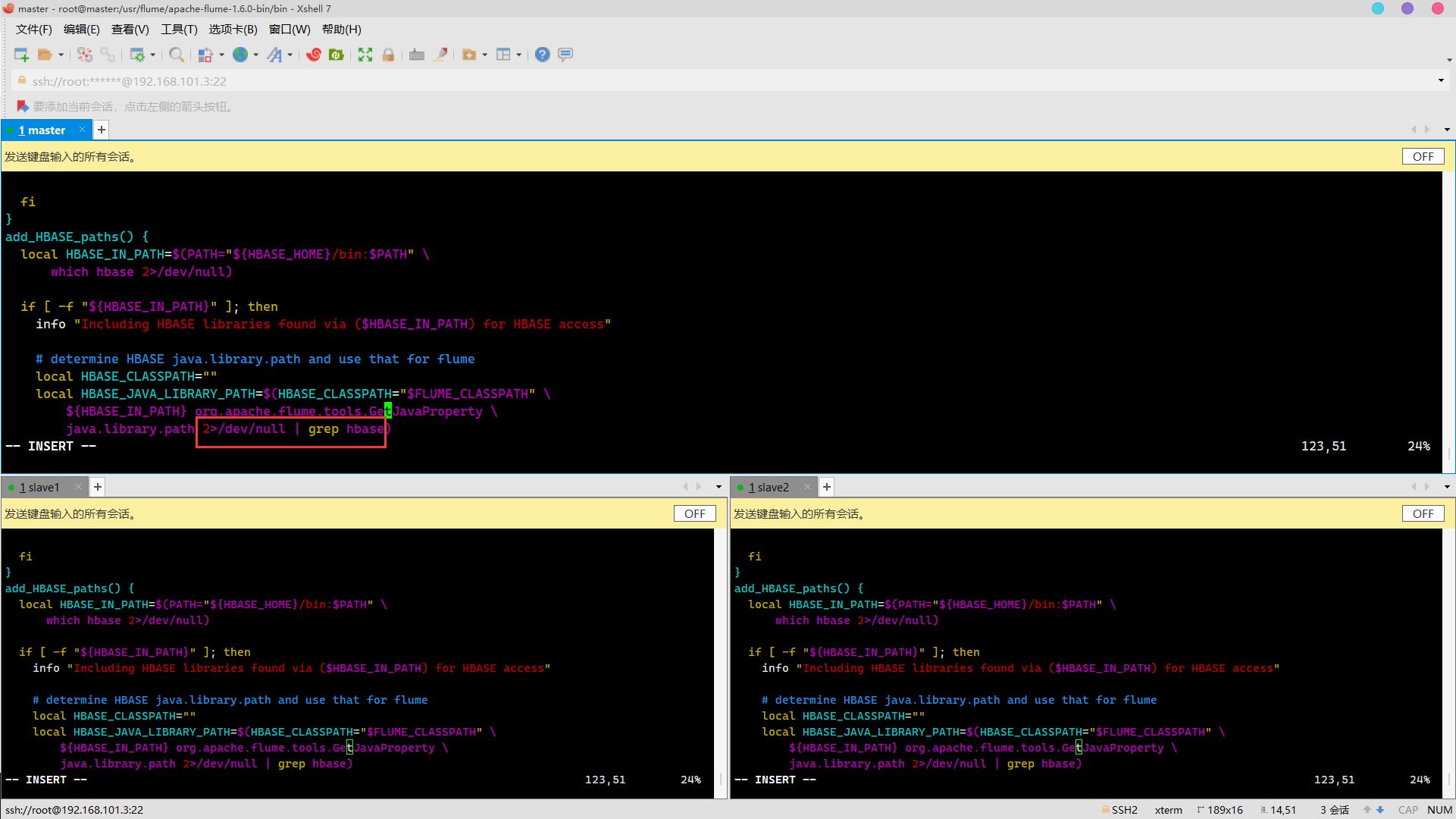
成功解决
配置flume与kafka连接
cd /usr/flume/apache-flume-1.6.0-bin/conf/
echo "#配置flume agent的source、channel、sink
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /tmp/logs/kafka.log
#配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#配置sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#配置Kafka的Topic
a1.sinks.k1.kafka.topic = mytest
#配置kafka的broker地址和端口号
a1.sinks.k1.brokerList = matser:9092,slave1:9092,slave2:9092
#配置批量提交的数量
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
#绑定source和sink到channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1" >> kafka.properties
踩坑
报错
(conf-file-poller-0) [ERROR - org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:427)] Sink k1 has been removed due to an error during configuration
org.apache.flume.conf.ConfigurationException: brokerList must contain at least one Kafka broker
at org.apache.flume.sink.kafka.KafkaSinkUtil.addDocumentedKafkaProps(KafkaSinkUtil.java:55)
at org.apache.flume.sink.kafka.KafkaSinkUtil.getKafkaProperties(KafkaSinkUtil.java:37)
at org.apache.flume.sink.kafka.KafkaSink.configure(KafkaSink.java:211)
at org.apache.flume.conf.Configurables.configure(Configurables.java:41)
解决方法
kafka.properties文件中配置
a1.sinks.k1.kafka.bootstrap.servers(1.7+版本的写法)
a1.sinks.k1.brokerList (1.6版本的写法)
创建目录
mkdir -p /tmp/logs
touch /tmp/logs/kafka.log创建脚本
cd
vim kafkaoutput.sh
//加入以下内容
#!/bin/bash
for((i=0;i<=1000;i++))
do
echo "kafka_test-"+$i >> /tmp/logs/kafka.log
done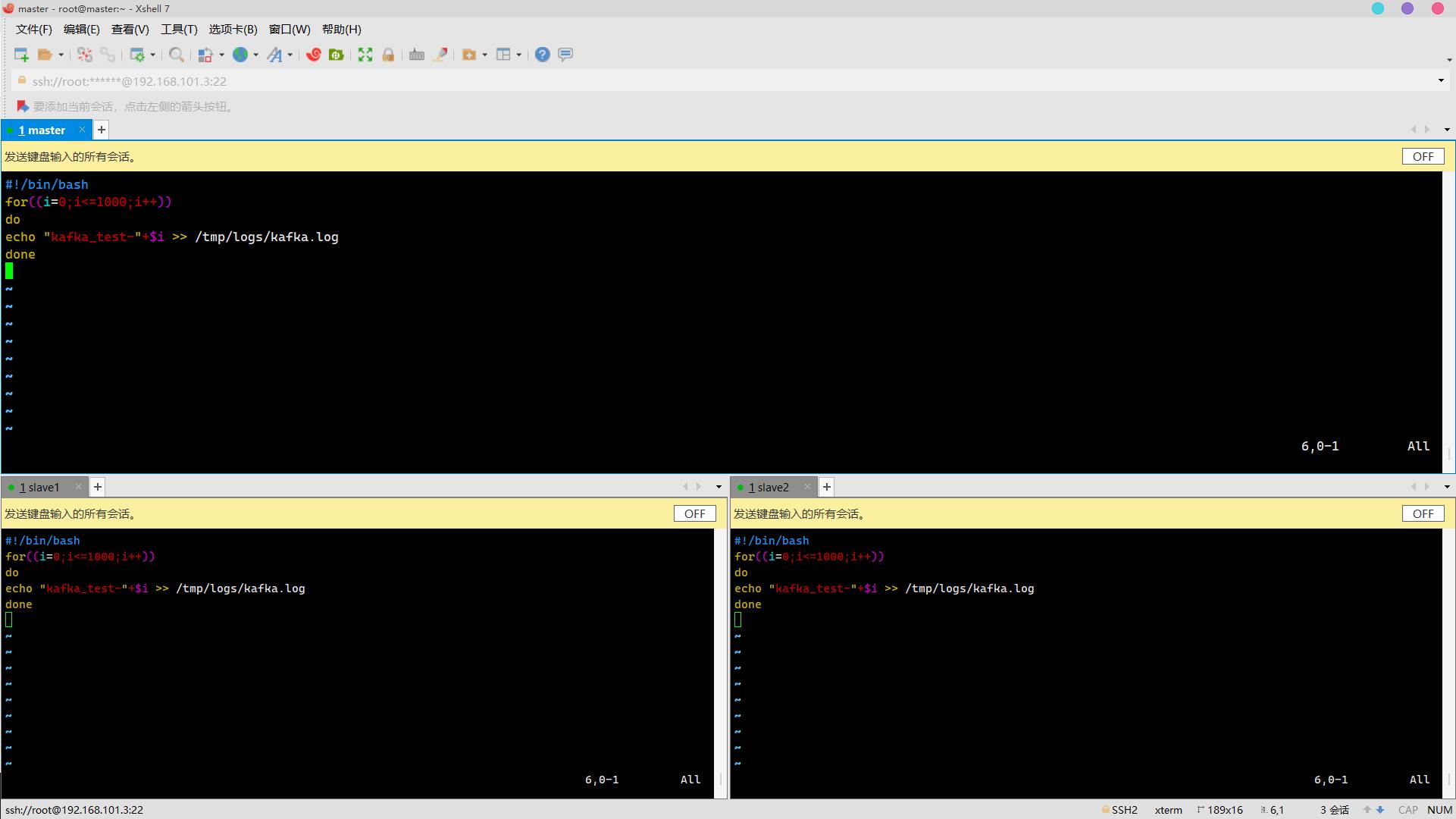 脚本赋权
脚本赋权
chmod 777 kafkaoutput.sh在kafka节点创建topic
前提zookpeer,kafka启动
创建topic
仅在master上
kafka-topics.sh --create --zookeeper master:2181 --replication-factor 3 --partitions 1 --topic mytest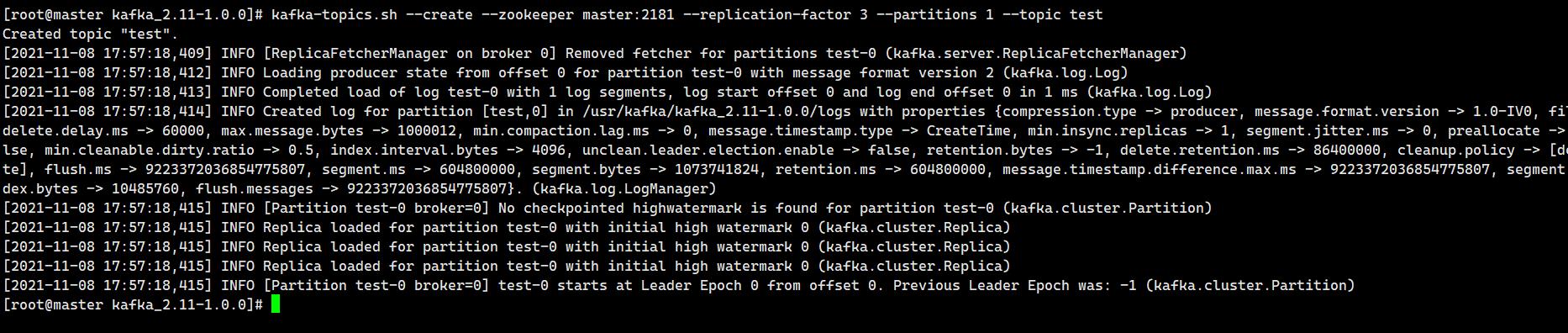 打开console
打开console
kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --from-beginning --topic mytest启动测试
flume-ng agent --conf /usr/flume/apache-flume-1.6.0-bin/conf/ --conf-file /usr/flume/apache-flume-1.6.0-bin/conf/kafka.properties -name a1 -Dflume.root.logger=INFO,console
成功!
执行脚本
sh kafkaoutput.sh在kafka中查看
cat /tmp/logs/kafka.log 
spark安装部署
请移步spark安装,参考完成spark安装部署。
全文完,爆肝一天,第一次接触这么多组件部署在集群上,而且还有相互对接配置,不停地报错,排错,总算完成啦!
眼睛疼!!!
接下来一段时间好好准备比赛啦!加油!
以上是关于HA高可用+hive+hbase+sqoop+kafka+flume+spark安装部署的主要内容,如果未能解决你的问题,请参考以下文章