必成功的Hadoop环境搭建jdk环境搭建-超详细操作
Posted 吃土的程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了必成功的Hadoop环境搭建jdk环境搭建-超详细操作相关的知识,希望对你有一定的参考价值。
Hadoop的文件可以在这里下载:Apache Hadoopb
本次配置的Hadoop环境为hadoop-2.7.7 | jdk配置的环境为jdk-1.8.0_141
一、jdk环境搭配
1.搭配Hadoop环境要先搭配jdk环境,否则无法运行和查看,在/root/wenjian中rz上传jdk文件
[root@master wenjian]# rz 
2.将jdk文件解压到/root目录下
[root@master wenjian]# tar -zxvf jdk-8u141-linux-x64.tar.gz -C /root/3.回到/root下进行修改名称为jdk(因为名字太长了到后面记的太麻烦)
[root@master ~]# mv jdk1.8.0_141/ jdk4.进入/root下的用户变量
[root@master ~]# vim /root/.bash_profile 5.变量jdk环境和路径,wq保存退出
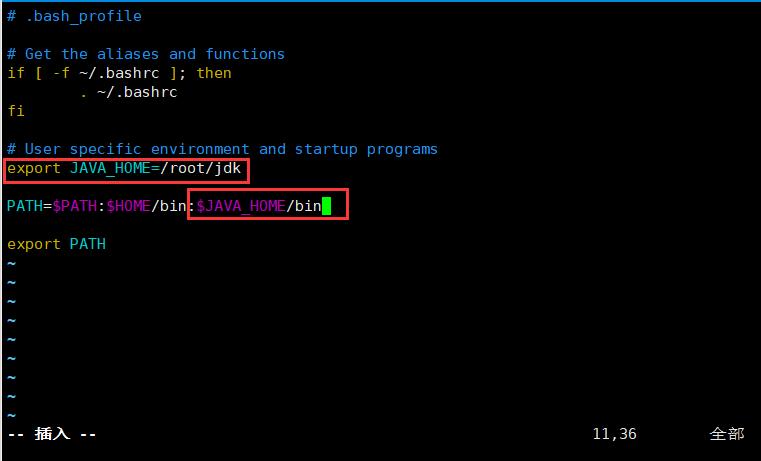
重新开启一下用户变量
[root@master ~]# source /root/.bash_profile 二、开始搭配Hadoop环境
1.进入/root/wenjian,解压hadoop文件到/root目录下
[root@master wenjian]# tar -zxvf hadoop-2.7.7.tar.gz -C /root/2.进入/root目录下修改hadoop名称
[root@master ~]# mv hadoop-2.7.7/ hadoop3.进入hadoop文件下的配置文件/etc/hadoop里面
[root@master ~]# cd hadoop/etc/hadoop/4.复制配置文件下的文件(保留源文件)
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml5.在core-site.xml中添加数据,将第四行的master修改为自己的主机名或者ip,wq保存退出(注意:如果主机名没有映射的话就修改为ip,不然不成功)
[root@master hadoop]# vim core-site.xml <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop/tmp</value>
</property>
</configuration>6.在hdfs-site.xml中插添加数据,将第四行的master修改为自己的主机名或者ip,wq保存退出
[root@master hadoop]# vim hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/tmp/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/tmp/data</value>
</property>
</configuration>7.在yarn-site.xml中添加数据,将第四行的master修改为自己的主机名或者ip,wq保存退出
[root@master hadoop]# vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.在刚刚复制过的mapred-site.xml中添加数据
[root@master hadoop]# vim mapred-site.xml修改第八行和倒数第三行的master修改为自己的主机名或ip
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>9.在hadoop-env.sh中添加上jdk路径
[root@master hadoop]# vim hadoop-env.sh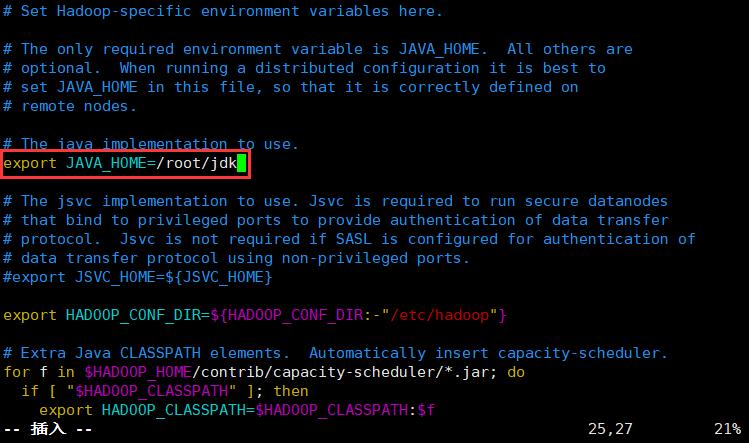
10.在用户下添加hadoop环境变量
[root@master hadoop]# vim /root/.bash_profile 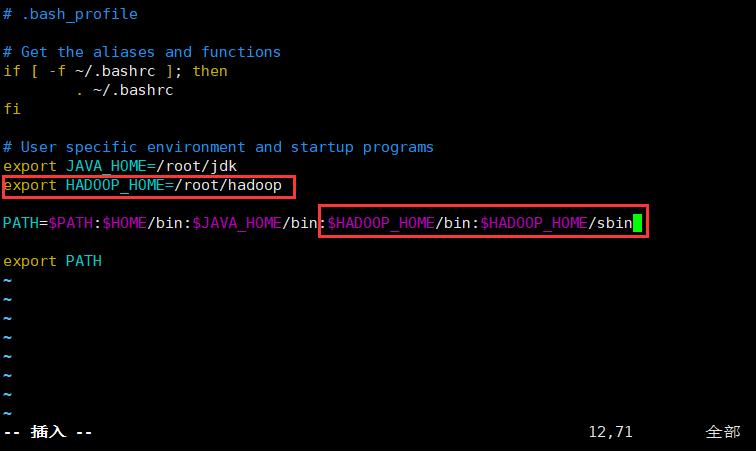 重新生成一下环境变量(重新生成在哪个目录下都可以,因为重新生成针对的是绝对路径)
重新生成一下环境变量(重新生成在哪个目录下都可以,因为重新生成针对的是绝对路径)
[root@master hadoop]# source /root/.bash_profile11.进入hadoop的bin目录下初始化hadoop
[root@master hadoop]# cd /root/hadoop/bin/执行初始化命令(打印出日志文件和出现两排*号就成功初始化了)
[root@master bin]# hdfs namenode -format12.开启hadoop服务,并通过jps查看hadoop服务(中间出现yes和no的时候一律选择yes)
[root@master bin]# start-all.sh 
出现六个服务就代表Hadoop服务开启成功了,如果关闭的话可以输入stop-all.sh关闭Hadoop服务!
可以日常关注一下,会经常出一些用的上的东西,可以直接在主页搜取!
以上是关于必成功的Hadoop环境搭建jdk环境搭建-超详细操作的主要内容,如果未能解决你的问题,请参考以下文章