Python机器学习之垃圾短信分类(用朴素贝叶斯算法的伯努利模型和多项式模型分类垃圾短信数据集SMSSpamCollection.txt)
Posted 港来港去
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python机器学习之垃圾短信分类(用朴素贝叶斯算法的伯努利模型和多项式模型分类垃圾短信数据集SMSSpamCollection.txt)相关的知识,希望对你有一定的参考价值。
一. 数据集下载地址
SMSSpamCollection.txt
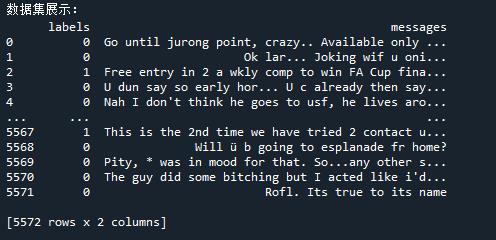
二. 打开下载的.txt文件,可以看到数据集长这样,标签(ham和spam,spam就是指垃圾短信)与文本之间的分隔符是一个tab键,也就是‘\\t’

三. 首先用pd.read_csv函数读取该数据集时要注意设置分隔符sep=’\\t’,然后用replace方法把“ham”标签用0替代,“spam”用1替代,方便看预测结果。
data=pd.read_csv(path,sep='\\t', header=None, names=Cnames)
data=data.replace({'ham':0,'spam':1}) #替换标签值
print('数据集展示:')
print(data)
读取出来像这样:
朴素贝叶斯算法分类垃圾短信,就是要找出哪些单词最常出现在垃圾短信中,将这些最常出现的单词,作为特殊单词,用来过滤短信。接下来就是用词袋方法处理文本信息,也就是统计一大段话里的不同单词的出现次数,最后得到一个频率矩阵,矩阵的行就是数据集里的每一行短信,矩阵的列就是短信里每个单词,元素值就是该单词的出现频率。有了频率,那么特殊单词也就能找到了。可以用sklearn库提供的CountVectorizer()方法实现词袋处理。
from sklearn.feature_extraction.text import CountVectorizer
#random_state等于哪个正整数随意
x_train,x_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=123)
vector_nomial=CountVectorizer() #实现词袋模型
train_matrix=vector_nomial.fit_transform(x_train)
test_matrix=vector_nomial.transform(x_test)
四. 将训练数据和测试数据输入到词袋模型里,就可以得到对应的频率矩阵。最后分别运用sklearn提供的伯努利模型和多项式模型对垃圾短信进行分类。
from sklearn.naive_bayes import BernoulliNB,MultinomialNB
polynomial=MultinomialNB()
clm_nomial=polynomial.fit(train_matrix,y_train)
result_nomial=clm_nomial.predict(test_matrix)
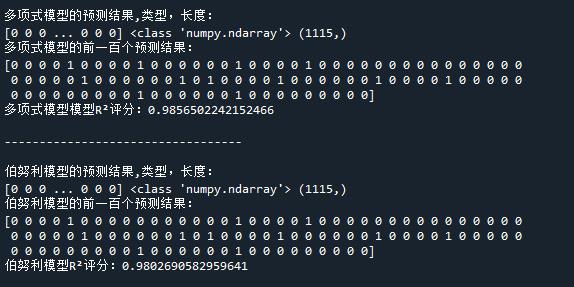
两个模型返回的分类结果都是长度为1115(我设置的训练集占比为80%),类型为ndarray的列表。最终,多项式模型的R²分值(决定系数)为0.986,伯努利模型的R²分值为0.980。二者的分类结果几乎是相同的。
五. 完整代码
from sklearn.naive_bayes import BernoulliNB,MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
import pandas as pd
path = 'E:/Python_file/zuoye/SMSSpamCollection.txt'
Cnames=['labels','messages']
data = pd.read_csv(path,sep='\\t', header=None, names=Cnames) #读取数据集,分隔符是\\t
data=data.replace({'ham':0,'spam':1}) #替换标签值
print('数据集展示:')
print(data)
print('\\n----------------------------------\\n')
X=data['messages']
y=data['labels']
x_train,x_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=123)
vector_nomial=CountVectorizer() #实现词袋模型
vector_bernou=CountVectorizer()
#多项式模型分类垃圾短信
train_matrix=vector_nomial.fit_transform(x_train)
test_matrix=vector_nomial.transform(x_test)
polynomial=MultinomialNB()
clm_nomial=polynomial.fit(train_matrix,y_train)
result_nomial=clm_nomial.predict(test_matrix)
#伯努利模型分类垃圾短信
train_matrix=vector_bernou.fit_transform(x_train)
test_matrix=vector_bernou.transform(x_test)
Bernoulli=BernoulliNB()
clm_bernoulli=Bernoulli.fit(train_matrix,y_train)
result_bernou=clm_bernoulli.predict(test_matrix)
print('多项式模型的预测结果,类型,长度:')
print(result_nomial,type(result_nomial),result_nomial.shape)
print('多项式模型的前一百个预测结果:')
print(result_nomial[0:100])
print('多项式模型模型R²评分:'+ str(clm_nomial.score(test_matrix,y_test)))
print('\\n----------------------------------\\n')
print('伯努利模型的预测结果,类型,长度:')
print(result_bernou,type(result_bernou),result_bernou.shape)
print('伯努利模型的前一百个预测结果:')
print(result_bernou[0:100])
print('伯努利模型R²评分:'+ str(clm_bernoulli.score(test_matrix,y_test)))
以上是关于Python机器学习之垃圾短信分类(用朴素贝叶斯算法的伯努利模型和多项式模型分类垃圾短信数据集SMSSpamCollection.txt)的主要内容,如果未能解决你的问题,请参考以下文章