《Elasticsearch 源码解析与优化实战》第13章:Snapshot 模块分析
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Elasticsearch 源码解析与优化实战》第13章:Snapshot 模块分析相关的知识,希望对你有一定的参考价值。
文章目录
简介
快照模块是ES备份、迁移数据的重要手段。它支持增量备份,支持多种类型的仓库存储。本章我们先来看看如何使用快照,以及它的一些细节特性,然后分析创建、删除及取消快照的实现原理。
仓库用于存储快照,支持共享文件系统(例如, NFS),以及通过插件支持的HDFS、AmazonS3、Microsoft Azure、Google GCS。
在跨版本支持方面,可以支持不跨大版本的快照和恢复。
- 在6.x版本中创建的快照可以恢复到6.x版本;
- 在2.x版本中创建的快照可以恢复到5.x 版本;
- 在1.x版本中创建的快照可以恢复到2.x版本。
相反,1.x版本创建的快照不可以恢复到5.x版本和6.0版本,2.x版本创建的快照不可以恢复到6.x版本。升级集群前建议先通过快照备份数据。跨越大版本的数据迁移可以考虑使用reindexAPI。
当需要迁移数据时,可以将快照恢复到另一个集群。快照不仅可以对索引备份,还可以将模板一起保存。恢复到的目标集群不需要相同的节点规模,只要它的存储空间足够容纳这些数据即可。
要使用快照,首先应该注册仓库。快照存储于仓库中。
仓库
仓库用于存储创建的快照。建议为每个大版本创建单独的快照存储库。如果使用多个集群注册相同的快照存储库,那么最好只有一个集群对存储库进行写操作。连接到该存储库的其他集群都应该将存储库设置为readonly模式。
使用下面的命令注册一个仓库:
curl -X PUT " localhost: 9200/_ snapshot/my_ backup" -H ' Content-Type: application/json' -d'
{
"type": "fs",
"settings": {
"location": "/mnt/my_backup"
}
}
本例中,注册的仓库名称为my_backup, type 为 fs,指定仓库类型为共享文件系统。共享文件系统支持的配置如下表所示。
| 参数 | 简介 |
|---|---|
| location | 指定了一个已挂载的目的地址 |
| compress | 是否开启压缩。压缩仅对元数据进行(mapping 及settings), 不对数据文件进行压缩,默认为true |
| chunk_ size | 传输文件时数据被分解为块,此处配置块大小,单位为字节,默认为null (无限块大小) |
| max_snapshot_bytes_per_sec | 快照操作时节点间限速值,默认为40MB |
| max_restore_bytes_per_ sec | 从快照恢复时节点间限速值,默认为40MB |
| readonly | 设置仓库属性为只读,默认为false |
要获取某个仓库配置信息,可以使用下面的API:
curl -X GET “localhost:9200/_snapshot/my_backup”
返回信息如下:
{
“my_ backup”: {
“type”: “fs”,
“settings”: {
“location”: “/mnt/my_backup”
}
}
}
要获取多个存储库的信息,可以指定一个以逗号分隔的存储库列表,还可以在指定存储库名称时使用“*”通配符。例如:
curl -X GET "localhost:9200/_snapshot/repo*,*backup*"
要获取当前全部仓库的信息,可以省略仓库名称,使用_ all:
curl -X GET "localhost:9200/_snapshot"
或
curl -X GET "localhost:9200/_snapshot/_all"
可以使用下面的命令从仓库中删除快照:
curl -X DELETE "localhost:9200/_snapshot/my_backup/snapshot_1"
可以使用下面的命令删除整个仓库:
curl -X DELETE "localhost:9200/_snapshot/my_backup"
当仓库被删除时,ES只是删除快照的仓库位置引用信息,快照本身没有删除。
共享文件系统
当使用共享文件系统时,需要将同一个共享存储挂载到集群每个节点的同一个挂载点(路径),包括所有数据节点和主节点。然后将这个挂载点配置到elasticsearch.yml的path.repo字段。 例如,挂载点为 /mnt/my_backup, 那么在elasticsearch.yml中应该添加如下配置:
path.repo: ["/mnt/my_backups"]
path.repo配置以数组的形式支持多个值。如果配置多个值,则不像path.data一样同时使用这些路径,相反,应该为每个挂载点注册不同的仓库。例如,一个挂载点存储空间不足以容纳集群所有数据,可使用多个挂载点,同时注册多个仓库,将数据分开快照到不同的仓库。
path.repo支持微软的UNC路径,配置格式如下:
path.repo: ["MY_SERVERSnapshots"]
当配置完毕,需要重启所有节点使之生效。然后就可以通过仓库API注册仓库,执行快照了。
使用共享存储的优点是跨版本兼容性好,适合迁移数据。缺点是存储空间较小。如果使用HDFS,则受限于插件使用的HDFS版本。插件版本要匹配ES,而这个匹配的插件使用固定版本的HDFS客户端。一个HDFS客户端只支持写入某些兼容版本的HDFS集群。
快照
创建快照
存储库可以包含同一集群的多个快照。每个快照有唯一的名称标识。通过以下命令在my_backup仓库中为全部索引创建名为snapshot_1的快照:
curl -X PUT "localhost:9200/_snapshot/my_backup/snapshot_1?wait_for_completion=true"
**wait_for_completion** 参数是可选项,默认情况下,快照命令会立即返回,任务在后台执行,如果想等待任务完成API才返回,则可以将wait_for_completion 参数设置为true,默认为false。
上述命令会为所有open状态的索引创建快照。如果想对部分索引执行快照,则可以在请求的indices参数中指定:
curl -X PUT "localhost:9200/_snapshot/my_backup/snapshot_2?wait_for_completion=true" -H 'Content-Type: application/json' -d'
{
"indices": "index_1, index_2",
"ignore_unavailable": true,
"include_global_state": true
}
indices字段支持多索引语法,index_ *完整的语法参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/ multi-index.html
另外两个参数:
**ignore_unavailable**,跳过不存在的索引。默认为false, 因此默认情况下遇到不存在的索引快照失败。**include_global_state**,不快照集群状态。默认为false。注意,集群设置和模板保存在集群状态中,因此默认情况下不快照集群设置和模板,但是一般情况下我们需要将这些信息一起保存。
快照操作在主分片上执行。快照执行期间,不影响集群正常的读写操作。在快照开始前,会执行一次flush,将操作系统内存“cache”的数据刷盘。因此通过快照可以获取从成功执行快照的时间点开始,磁盘中存储的Lucene数据,不包括后续的新增内容。但是每次快照过程是增量的,下一次快照只会包含新增内容。
可以在任何时候为集群创建一个快照过程,无论集群健康是Green、Yellow,还是Red。执行快照期间,被快照的分片不能移动到另一个节点,这可能会干扰重新平衡过程和分配过滤( alocation filtering)。这种分片迁移只可以在快照完成时进行。
快照开始后,可以用快照信息API和status API来监控进度。
获取快照信息
当快照开始后,使用下面的API来获取快照的信息:
curl -X GET "localhost:9200/_snapshot/my_backup/snapshot_1"
返回信息摘要如下:
{
" snapshots": [
{
"snapshot": "snapshot_1",
"version": "6.1.2",
"indices": [
"website"
],
"state": " SUCCESS",
"start_time": "2018-05-15T03:40:06.571Z",
"end_time": "2018-05-15T07:53:40.977Z",
"duration_in_millis": 15214406,
" failures": [] ,
"shards": {
"total": б,
"failed": O,
"successful": 6
}
}
]
}
主要是开始结束时间、集群版本、当前阶段、成功及失败情况等基本信息。快照执行期间会经历以下几个阶段,如下表所示。
| 阶段 | 简介 |
|---|---|
| IN_PROGRESS | 快照正在运行 |
| SUCCESS | 快照创建完成,并且所有分片都存储成功 |
| FAILED | 快照创建失败,没有存储任何数据 |
| PARTIAL | 全局集群状态已储存,但至少有一个分片的数据没有存储成功。在返回的failure字段中包含了关于未正确处理分片的详细信息 |
| INCOMPATIBLE | 快照与当前集群版本不兼容 |
使用下面的命令可以获取多个快照信息:
curl -X GET "localhost: 9200/_snapshot/my_backup/snapshot_*, other_snapshot"
以及获取指定仓库下的全部快照信息:
curl -X GET "localhost:9200/_snapshot/my_backup/_all"
如果一些快照不可用导致命令失败,则可以通过设置布尔参数ignore_unavailable 来返回当前可用的所有快照。
可以使用下面的命令来查询正在运行中的快照:
curl -X GET "localhost:9200/_snapshot/my_backup/_current"
快照status
_status API用于返回快照的详细信息。
可以使用下面的命令来查询当前正在运行的全部快照的详细状态信息:
curl -X GET "localhost:9200/_snapshot/_status"
返回的信息摘要如下:
"stats": {
"number_of_files": 31,
"processed_files": 31,
"total_size_in_bytes": 33802,
"processed_size_in_bytes": 33802,
"start_time_in_millis": 1526355676967,
"time_in_millis": 15144003
}
主要是已处理的文件数和字节数等进度信息,但没有计算成百分比的形式。
使用下面的命令可以返回特定仓库中正在运行的所有快照的信息:
curl -X GET "localhost:9200/_snapshot/my_backup/_status"
如果同时指定仓库名称和快照ID,则此命令将返回指定快照的状态信息,即使它已经执行完成:
curl -X GET "localhost:9200/_snapshot/my_backup/snapshot_1, snapshot_2/status"
取消、删除快照和恢复操作
在设计上,快照和恢复在同一个时间点只允许运行一个快照或一个恢复操作。如果想终止正在进行的快照操作,则可以使用删除快照命令来终止它。删除快照操作将检查当前快照是否正在运行,如果正在运行,则删除操作会先停止快照,然后从仓库中删除数据。如果是已完成的快照,则直接从仓库中删除快照数据。
curl -x DELETE "localhost:9200/_snapshot/my_backup/snapshot_1"
恢复操作使用标准分片恢复机制。因此,如果要取消正在运行的恢复,则可以通过删除正在恢复的索引来实现。注意,索引数据将全部删除。
从快照恢复
要恢复一个快照,目标索引必须处于关闭状态。
使用下面的命令恢复一个快照:
curl -X POST "localhost:9200/snapshot/my_backup/snapshot_1/_restore'
**默认情况下,快照中的所有索引都被恢复,但不恢复集群状态。通过调节参数,可以有选择地恢复部分索引和全局集群状态。索引列表支持多索引语法。**例如:
curl -X POST " localhost:9200/snapshot/mybackup/snapshot_1/_restore" -H 'Content-Type: application/json' -d'
{
"indices": "index_1, index_2" ,
"ignore_unavailable": true,
"include_global_state": true,
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
}
具体参数介绍如下表所示。
| 参数 | 简介 |
|---|---|
| indices | 要恢复的索引列表。支持多索引语法(multi index syntax) |
| ignore_unavailable | 与快照时含义相同 |
| include_global_state | 是否恢复集群状态,默认为false。 设置为true时,快照中的模板被恢复,如果当前集群存在同名的模板,则会被覆盖。集群设置(persistent settings)同样被恢复 |
| rename_pattern | 如下 |
| rename_replacement | 与上一个参数配合,通过正则表达式对恢复的索引重命名 |
| partial | 是否允许在遇到错误时恢复部分数据,默认为false |
恢复完成后,当前集群与快照同名的索引、模板会被覆盖。在集群中存在,但快照中不存在的索引、索引别名、模板不会被删除。因此恢复并非同步成与快照一致。
部分恢复
默认情况下,在恢复操作时,如果参与恢复的一个或多个索引在快照中没有可用分片,则整个恢复操作失败。这可能是因为创建快照时一些分片备份失败导致的。可以通过设置partial参数为true来尽可能恢复。但是,只有备份成功的分片才会成功恢复,丟失的分片将被创建一个空的分片。
恢复过程中更改索引设置
**大多数的索引设置可以在恢复过程中被重写。**例如,下面的指令将在恢复索引index_1时不创建任何副本,以及采用默认的索引刷新间隔:
curl -X POST "localhost:9200/_snapshot/my_backup/snapshot_1/_restore" -H 'Content-Type: application/json' -d'
"indices": "index_ 1",
"index settings": {
" index.number_of_replicas": 0
}
"ignore_index_settings": [
"index.refresh_interval"
]
}
有一些设置不能在恢复时修改,比如index.number_of_shards。
监控恢复进度
恢复过程是基于ES标准恢复机制的,因此标准的恢复监控服务可以用来监视恢复的状态。当执行集群恢复操作时通常会进入Red状态,这是因为恢复操作是从索引的主分片开始的,在此期间主分片状态变为不可用,因此集群状态表现为Red。一旦ES主分片恢复完成,整个集群的状态将被转换成Yellow,并且开始创建所需数量的副分片。一旦创建了所有必需的副分片,集群转换到Green状态。
查看集群的健康情况只是在恢复过程中比较高级别的状态,还可以通过使用indices recovery与cat recovery的API来获得更详细的恢复过程信息与索引的当前状态信息。
创建快照的实现原理
在快照的实现原理中我们重点关注几个问题:快照是如何实现的?增量过程是如何实现的?为什么删除旧快照不影响其他快照?
ES的快照创建是基于Lucene快照实现的。但是Lucene中的快照概念与ES的并不相同。Lucene快照是对最后一个提交点的快照,一次快照包含最后一次提交点的信息,以及全部分段文件。因此这个快照实际上就是对已刷盘数据的完整的快照。注意Lucene中没有增量快照的概念。每一次都是对整个Lucene索引完整快照,它代表这个Lucene索引的最新状态。之所以称为快照,是因为从创建一个Lucene快照开始,与此快照相关的物理文件都保证不会删除。 在Lucene中,快照通过SnapshotDeletionPolicy实现。从Lucene 2.3版本开始支持。
你可能还记得,在副分片的恢复过程中,也需要对主分片创建Lucene快照,然后复制数据文件。
因此总结来说:
- Lucene 快照负责获取最新的、已刷盘的分段文件列表,并保证这些文件不被删除,这个文件列表就是ES要执行复制的文件。
- ES负责数据复制、仓库管理、增量备份,以及快照删除。
创建快照的整体过程如下图所示。

ES创建快照的过程涉及3种类型的节点:
- 协调节点:接收客户端请求,转发到主节点。
- 主节点:将创建快照相关的请求信息放到集群状态中广播下去,数据节点收到后执行数据复制。同时负责在仓库中写入集群状态数据。
- 数据节点:负责将Lucene文件复制到仓库,并在数据复制完毕后清理仓库中与任何快照都不相关的文件。由于数据分布在各个数据节点,因此复制操作必须由数据节点执行。每个数据节点将快照请求中本地存储的主分片复制到仓库。
快照过程是对Lucene物理文件的复制过程,一个Lucene索引由许多不同类型的文件组成。 完整的介绍可以参考Lucene 官方手册,当前版本的地址为: http://lucene.apache.org/core/7_3_1/index.html。
如果数据节点在执行快照过程中异常终止,例如,I/O 错误,进程被“kill", 服务器断电等异常,则这个节点上执行的快照尚未成功,当这个节点重新启动,不会继续之前的数据复制流程。对于整个快照进程来说,最终结果是部分成功、部分失败。快照信息中会记录失败的节点和分片,以及与错误相关的原因。
Lucene文件格式简介
1.定义
Lucene中基本的概念包括index、document、field和term。一个index包含一系列的document:
- 一个document是一系列的fields
- 一个field是一系列命名的terms
- 一个term是一系列bytes
2.分段
Lucene索引可能由多个分段(segment) 组成,每个分段是一个完全独立的索引,可以独立执行搜索。有两种情况产生新的分段:
- refresh操作产生一个Lucene分段。为新添加的documents创建新的分段。
- 已存在的分段合并,产生新分段。
一次对Lucene索引的搜索需要搜索全部分段。
3.文件命名规则
属于一个段的所有文件都具有相同的名称和不同的扩展名。当使用复合索引文件(默认)时,除.si write.lock .del外的其他文件被合并压缩成单个.cfs文件。
文件名不会被重用,也就是说,任何文件被保存到目录中时,它有唯一的文件名。 这是通过简单的生成方法实现的,例如,第一个分段文件名为segments_1,接下来是segments_2。
4.文件扩展名摘要
下表总结了Lucene中文件的名称和扩展名。
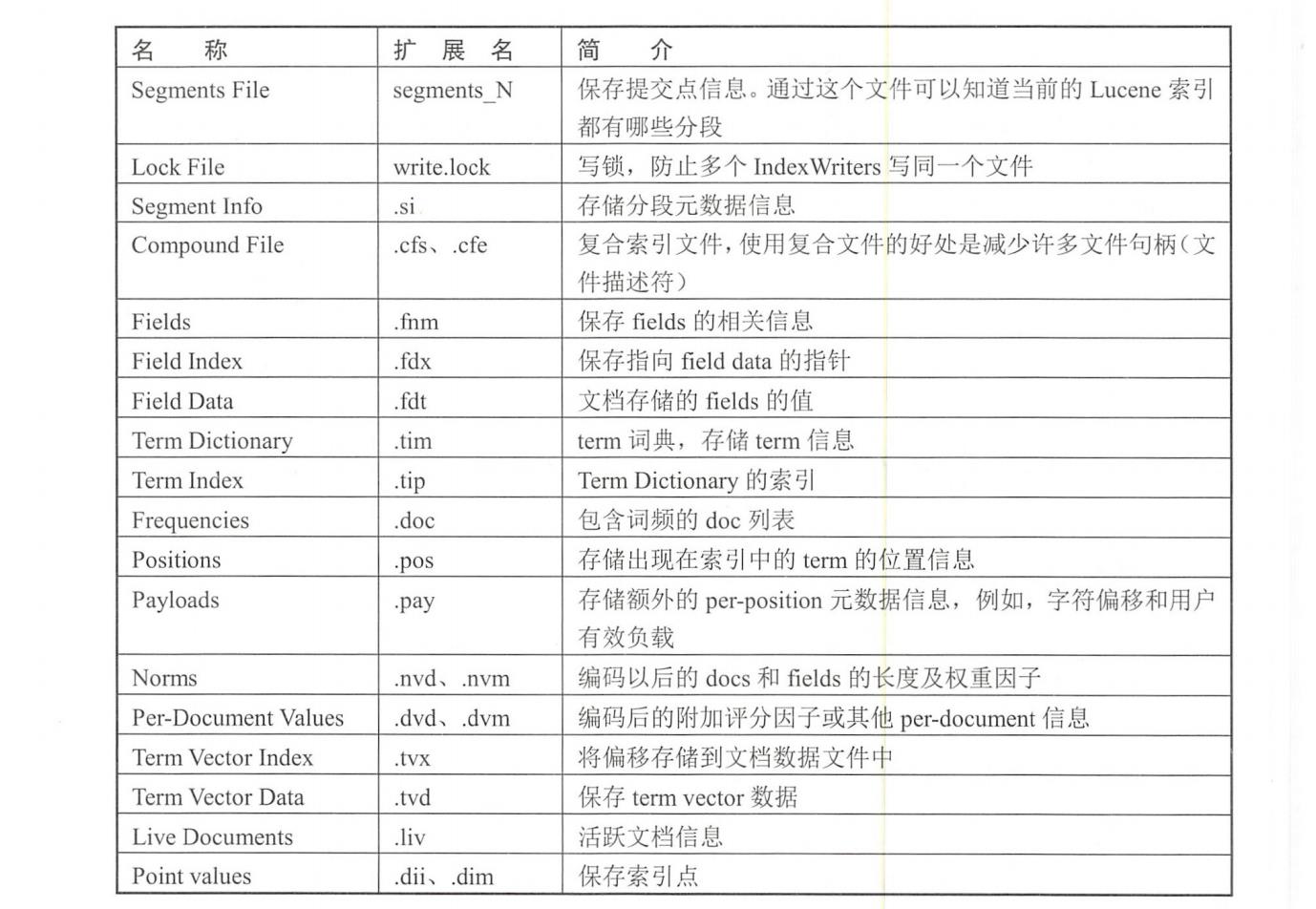
下面我们开始分析三种类型节点各自的执行流程。
协调节点流程
协调节点负责解析请求,将请求转发给主节点。
处理线程: http_server_worker。
协调节点注册的REST action 为create_snapshot_action,相应的Handler 为RestCreate-SnapshotAction类。当协调节点收到客户端请求后,在BaseRestHandler#handleRequest中处理请求,调用RestCreateSnapshotAction#prepareRequest解析REST请求,将请求封装为CreateSnapshotRequest结构,然后将该请求发送到Master节点。
public RestChannelConsumer prepareRequest (final RestRequest request, final NodeClient client) throws IOException {
//将请求封装为CreateSnapshotRequest结构
CreateSnapshotRequest createSnaps hotRequest = createSnapshotRequest(request.param ("repository"), request.param("snapshot"));
request.applyContentParser(p -> createSnapshotRequest.source(p.mapOrdered()));
//设置超时wait_for_completion 等待参数信息
createSnapshotRequest.masterNodeTimeout(request.paramAsTime("master_timeout", createSnapshotRequest.masterNodeTimeout()));
createSnapshotRequest.waitForCompletion(request.par amAsBoolean("wait_for_completion", false));
return channel -> client.admin().cluster().createSnapshot(createSnapshotRequest, new RestToXContentListener<> (channel));
}
在TransportMasterNodeAction.AsyncSingleAction#doStart 方法中,判断本地是否是主节点,如果是主节点,则转移到snapshot线程处理,否则发送action为cluster:pdmin/snapshot/create的 RPC请求到主节点,request 为组装好的CreateSnapshotRequest结构。
代码摘要如下:
protected void doStart (ClusterState clusterState) {
if (nodes. isLocalNodeElectedMaster () ll localExecute (request) ) {
//本地是主节点,在新的线程池中处理请求
threadPool.executor(executor).execute(new ActionRunnable (delegate) {
protected void doRun() throws Exception {
masterOperation(task, request, clusterState, delegate) ;
}
]);
} else { //转发到主节点。request为组装好的CreateSnapshotRequest结构
transportService.sendRequest (masterNode, actionName, request, new ActionLi stenerResponseHandler <Response> (listener,
TransportMasterNodeAction.this::newResponse)
}
}
从实现角度来说,协调节点和主节点都会执行TransportMasterNodeAction.AsyncSingleActiont#doStart 方法,只是调用链不同。
主节点流程
主节点的主要处理过程是将请求转换成内部需要的数据结构,提交一个集群任务进行处理,集群任务处理后生成的集群状态中会包含请求快照的信息,主节点将新生成的集群状态广播下去,数据节点收到后执行相应的实际数据的快照处理。
执行本流程的线程池: http_server_worker->snapshot->masterService#updateTask。
如上一节所述,主节点收到协调节点发来的请求也是在TransportMasterNodeAction。AsyncSingleAction#doStart方法中处理的,在snapshot 线程池中执行TransportCreateSnapshot-Action#masterOperation方法。将收到的CreateSnapshotRequest 请求转换成SnapshotsService.SnapshotRequest结构,调用snapshotsService.createSnapshot 方法提交一个集群任务。
protected void masterOperation(.. .) {
snapshotsService.createSnapshot (snapshotRequest, new SnapshotsService.CreateSnapshotListener () {
public void onResponse () {
//根据需要注册一个Listener, 快照执行完毕才返回响应给客户端.
if (request.waitForCompletion()) {
snapshotsService.addListener (new SnapshotsService.SnapshotCompletionListener () {
public void onSnapshotCompletion (Snapshot snapshot, SnapshotInfo snapshotInfo) {
......
}
public void onSnapshotFailure (Snapshot snapshot, Exception e) {
......
}
]) ;
} else {//给客户端返回结果,快照任务后台执行
listener.onResponse (new CreateSnapshotResponse());
}
}
//对执行失败的处理
public void onFailure (Exception е) {
listener. onFailure (е) ;
}
}) ;
我们忽略对请求的验证和超时处理,以及失败处理等不重要的细节,摘取snapshotsService.createSnapshot的主要实现如下:
public void createSnapshot (final SnapshotRequest request, final CreateSnapshotListener listener) {
clusterService.submitStateUpdateTask (request.cause(),new ClusterStateUpdateTask() {
//定义要执行的任务
public ClusterState execute (ClusterState currentState) {
//快照任务不能并行,同一时间只能有一个快照在执行
if (snapshots == null || snapshots.entries().isEmpty()) {
//要快照的索引列表
List<IndexId> snapshotIndices = repositoryData.resolveNewIndices (indices);
newSnapshot = new SnapshotsInProgress.Entry (new Snapshot(repositoryName,snapshotId),
request.includeGlobalState(),
request.partial(),
State.INIT, //初始状态为INIT
snapshotIndices,
System.currentTimeMillis(),
repositoryData.getGenId(),
null) ;
snapshots = new SnapshotsInProgress (newSnapshot);
} else {
throw new ConcurrentSnapshotExecut ionException (repositoryName, snapshotName," a snapshot is already running");
//根据snapshots信息生成新的集群状态
return ClusterState.builder (currentState).putCustom(SnapshotsInProgress.TYPE,snapshots).build();
}
//待state为INIT 集群状态处理成功后,发送State为START的集群状态
public void clusterStateProcessed(String source, ClusterState oldState, final ClusterState newState) {
if (newSnapshot != null) {
threadPool.executor(ThreadPool.Names.SNAPSHOT).execute(() ->
beginSnapshot (newState, newSnapshot, request.partia (), listener)
);
}
}
}
}
提交的任务在masterService#updateTask线程中执行。在任务中对请求做非法检查,以及是否已经有快照在执行等验证操作,然后将快照请求的相关信息放入集群状态中,广播到集群的所有节点,触发数据节点对实际数据的处理。快照信息在集群状态的customs字段中,其组织结构如下图所示。
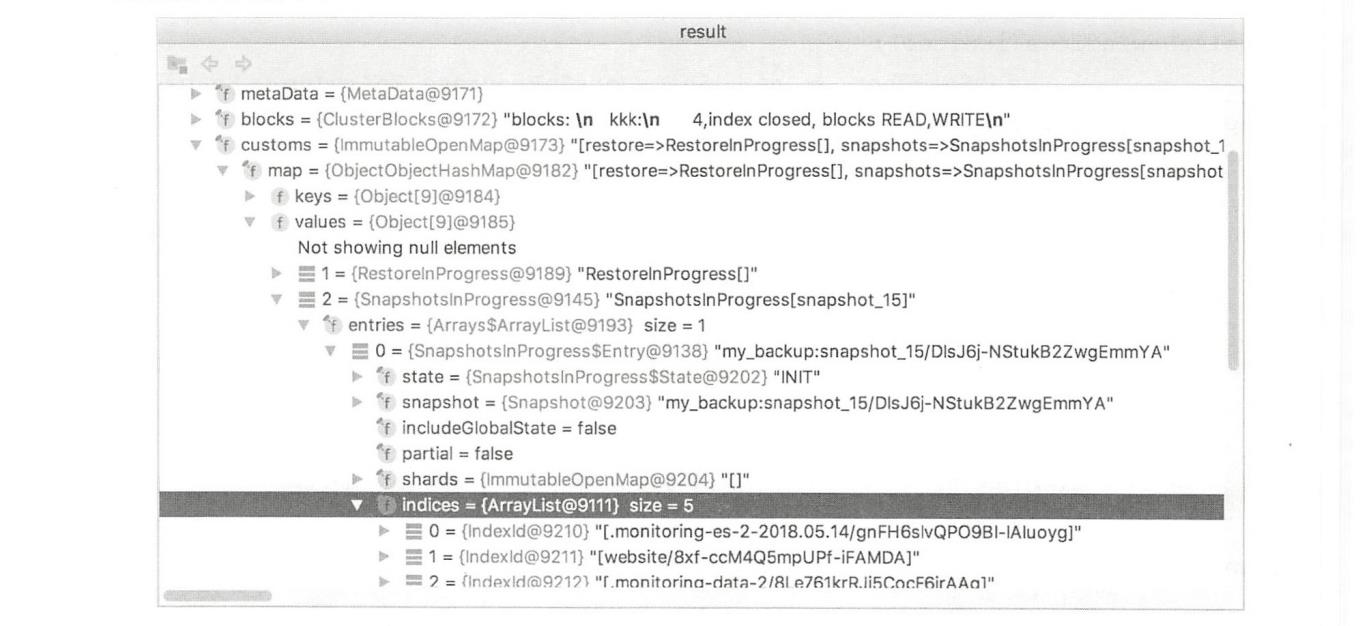
主节点控制数据节点执行快照的方式,就是通过把要执行的快照命令放到集群信息中广播下去。在执行快照过程中,主节点分成两个步骤,下发两次集群状态。首次发送时,快照信息中的State设置为INIT,数据节点进行一些初始化操作。待数据节点将这个集群状态处理完毕后,主节点准备下发第二次集群状态。第二次集群状态在SnapshotsService#beginSnapshot方法中构建。
在下发第二次集群状态前,主节点会先将全局元信息和索引的元数据信息写入仓库。
public void initializeSnapshot (SnapshotId snapshotId, List<IndexId> indices, MetaData clusterMetaData) {
try {
//写全局元信息
globalMetaDataFormat.write (clusterMetaData, snapshotsBlobContainer, snapshotId.getUUID());
//为快照的每个索引写索引级元信息
for (IndexId index : indices) {
final IndexMetaData indexMetaData = clusterMetaData.index.(index.getName());
final BlobPath indexPath = basePath().add ("indices").add(index.getId());
final BlobContainer indexMetaDataBlobContainer = blobStore().blobContainer(indexPath) ;
indexMetaDataFormat.write (indexMetaData, indexMetaDataBlobContainer, snapshotId.getUUID());
} catch (IOException ех) {
throw new SnapshotCreationException (metadata.name(), snapshotId, ex);
}
}
}
在新的集群状态中,将State设置为STARTED,并且根据将要快照的索引列表计算出分片 列表(注意全是主分片),数据节点收到后真正开始执行快照。
数据节点流程
数据节点负责实际的快照实现,从全部将要快照的分片列表中找出存储于本节点的分片,对这些分片创建Lucene快照,复制文件。
1. 对ClusterState的处理
对收到的集群状态的处理在clusterApplierService#updateTask 线程池中。启动快照时,在snapshot线程池中。
数据节点对主节点发布的集群状态( ClusterState)的统一处理在ClusterApplierService#callClusterStateListeners方法中,clusterStateListeners 中存储了所有需要对集群状态进行处理的模块。当收到集群状态时,遍历这个列表,调用各个模块相应的处理函数。快照模块对此的处理在SnapshotShardsService#clusterChanged方法中。在该方法中,在做完一些简单的验证之后,调用SnapshotShardsServicet#processIndexShardSnapshots进入主要处理逻辑。数据节点对第一次集群状态的处理实际上没做什么有意义的操作。对第二次集群状态的处理是真正快照的核心实现。主节点第二次下发的集群状态中包含了要进行快照的分片列表。数据节点收到后过滤一下本地有哪些分片,构建一个新的列表,后续要进行快照的分片就在这个列表中。
for (Obj ectObjectCursor<ShardId, ShardSnapshotStatus> shard : entry.shards ()) {
//准备本节点要处理的分片
if (localNodeId. equals (shard. value.nodeId())) {
if (shard. value.state() == State. INIT && (snapshotShards == null || ! snapshotShard .shards.containsKey(shard.key))) {
logger.trace("[(]] - Adding shard to the queue", shard.key);
startedShards.put (shard.key, new IndexShardSnapshotStatus());
}
}
}
//本节点要处理的分片列表
newSnapshots.put(entry.snapshot(), startedshards) ;
然后遍历本地要处理的分片列表,在snapshot线程池中对分片并行执行快照处理。并行数量取决于snapshot线程池中的线程个数,默认的线程数最大值为: min(5,(处理器数量) /2)
处理完毕后,向主节点发送RPC请求以更新相应分片的快照状态。
if (newSnapshots. isEmpty() == false) {
Executor executor.= threadPool.executor (ThreadPool.Names.SNAPSHOT);
for (final Map. Entry<Snapshot, Map<ShardId, IndexShardSnapshotStatus>> entry : newSnapshots.entrySet()) {
//shard级并发执行快照
for (final Map.Entry<ShardId, IndexShardSnapshotstatus> shardEntry : entry.getValue().entrySet()) {
executor.execute (new Abs tractRunnable () {
public void doRun() {
//对特定分片执行快照
snapshot (indexShard, snapshot, indexId, shardEntry.