FFmpeg实现音视频同步的精准片段拼接
Posted Jack_Chai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FFmpeg实现音视频同步的精准片段拼接相关的知识,希望对你有一定的参考价值。
本文出处:http://blog.csdn.net/chaijunkun/article/details/116491526,转载请注明。由于本人不定期会整理相关博文,会对相应内容作出完善。因此强烈建议在原始出处查看此文。
音视频开发过程中,经常会遇到多个片段(或者称之为“分镜头”)拼接的问题。下面将列举若干实例,来分别说明。
本文中列举的例子必须满足前提条件:
- 每个片段自身是音视频同步的,只是在拼接后产生了不同步的问题;
- 每个片段的视频流都具有相同的:画面宽度、画面高度、像素宽高比、帧率和时间基;
- 每个片段的音频流都具有相同的:采样率、时间基;
- 每个片段都具有视频流和音频流。
直接concat
FFmpeg为我们提供了concat滤镜,该滤镜不仅可以拼接视频,还可以拼接音频。例如:
ffmpeg -i demo_1.mp4 -i demo_2.mp4 -filter_complex \\
"[0:v][0:a][1:v][1:a]concat=n=2:v=1:a=1[v][a]" \\
-map "[v]" -map "[a]" mix.mp4
关于concat滤镜的详细介绍可参阅我的另外一篇博文:https://blog.csdn.net/chaijunkun/article/details/116237809
这种拼接后若希望音视频同步,先决条件是:每一个片段内的音频流时长都必须与视频流时长相等,
就像这样:
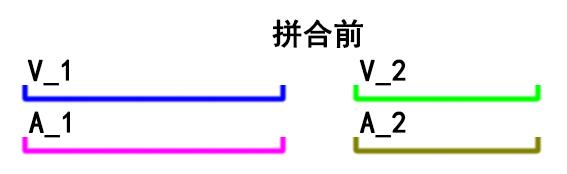
可以通过FFmpeg自带的ffprobe工具查看文件中各个流对应的时长信息:
ffprobe -v quiet -show_entries \\
stream=index,codec_name,time_base,start_pts,start_time,duration_ts,duration \\
-of json demo_1.mp4
输出内容如下所示:
{
...
"streams": [
{
"index": 0,
"codec_name": "h264",
"time_base": "1/12800",
"start_pts": 0,
"start_time": "0.000000",
"duration_ts": 128512,
"duration": "10.040000"
},
{
"index": 1,
"codec_name": "aac",
"time_base": "1/44100",
"start_pts": 0,
"start_time": "0.000000",
"duration_ts": 442764,
"duration": "10.040000"
}
]
}
这里主要关注duration字段。可以看到,示例文件中的音频流和视频流具有相同的时长:10.04秒,因此有多少个这样的视频拼接都不会有音画同步问题。正如下图所示:
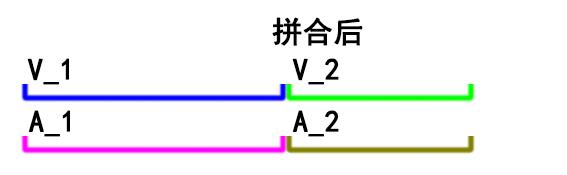
事与愿违,实际处理时,往往片段的音频流、视频流是非等长的。当然时长差别可能会非常小,在几十毫秒的数量级上,单纯拿来一个片段进行播放几乎不会让人感觉到时长有差别。只有通过上述的ffprobe命令才可以看到音视频流的duration可能不相等。
例如:
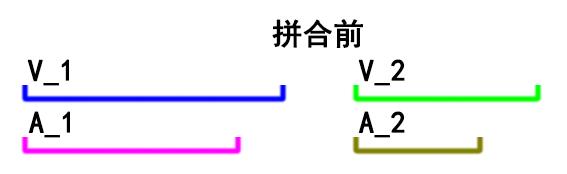
如果直接concat,得到的输出将会变成这样:
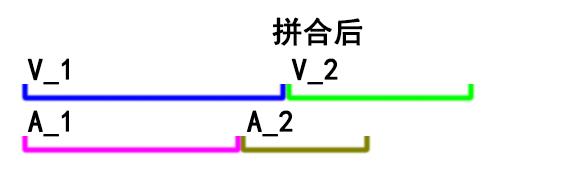
可以看出,微小的误差在多次积累后就会放大。片段数量足够的话,这种误差将在某处开始让人明显感觉到音画不同步。
另外,由于使用了多个文件输入,ffmpeg对多个音视频同时解码,CPU和内存的消耗巨大,笔者曾经在16G内存环境中,尝试对60+个视频流进行concat,刚开始处理几帧就报错:thread_get_buffer() failed,get_buffer() failed,最后异常退出。因此强烈不建议在数量不可预估的情况下使用此滤镜。
xfade和afade滤镜拼接
xfade滤镜能让两个场景切换更加柔和,带有一定的专场特效,但这个滤镜会消耗掉视频的一段时长用于画面过渡。
类似地,afade也是在前一个音频流实现了淡出,后一个音频流实现了淡入,淡出淡入的交集进行了融合,因此也会损失一定的音频时长。
本质上,xfade滤镜和afade滤镜都是直接在视频流、音频流中进行了concat操作,并不涉及音视频同步。
改进的音视频同步
分析这些片段,发现每一个片段的音画是同步的,问题出现在片段的音视频时长有微小的差别。
那我们拼接这些片段的时候,可否借助视频流时长作为参考系呢?
整体思路
音频流不再直接使用拼接,而是先把子剪辑的音频流延迟一段时间,这段延迟的时间等于之前所有子剪辑视频流的时长总和。
经过延迟处理后,将所有片段的音频流混音到一条主音频流中,这样音频流开始播放的时机就不再和前一个音频长度有关了。
如下图所示:
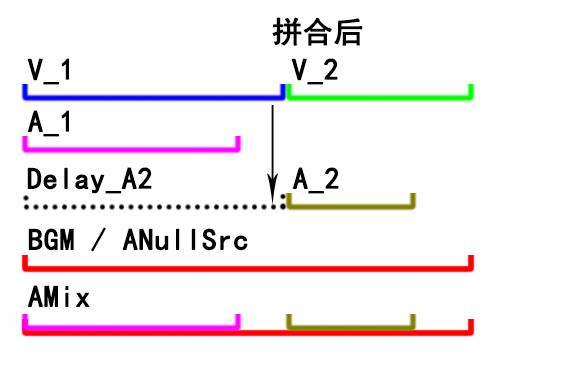
事先要先准备一个足够长的音频流用于最终混音。一般用背景音乐(BGM),如果你的需求中不需要背景音乐,也可以用无限长度的空音频流来代替:
-f lavfi -i anullsrc=r=44100:cl=stereo
实现案例
目前有三个片段,分别为:
| 文件名 | 视频duration_ts | 视频time_base | 视频duration(秒) | 音频duration_ts | 音频time_base | 音频duration(秒) |
|---|---|---|---|---|---|---|
| v_1.mp4 | 128000 | 1/12800 | 10.000000 | 441353 | 1/44100 | 10.008005 |
| v_2.mp4 | 76800 | 1/12800 | 6.000000 | 265306 | 1/44100 | 6.016009 |
| v_3.mp4 | 69120 | 1/12800 | 5.400000 | 235185 | 1/44100 | 5.332993 |
上述视频片段文件的音频流声道布局为:立体声,采样率均为44100Hz(这里注意,上述音频时间基1/44100恰好是采样率的倒数,但只是巧合)。
有一段背景音乐:
| 文件名 | 音频duration_ts | 音频time_base | 音频duration(秒) |
|---|---|---|---|
| bgm.mp3 | 3947396292 | 1/14112000 | 279.719125 |
上述背景音乐声道布局为:立体声,采样率同样为:44100Hz。
FFmpeg拼接命令:
ffmpeg -i v_1.mp4 -i v_2.mp4 -i v_3.mp4 -stream_loop -1 -i bgm.mp3 \\
-filter_complex "[0:v][1:v][2:v]concat=n=3:v=1:a=0;\\
[0:a]anull[a_delay_0]; \\
[1:a]adelay=delays=10000:all=1[a_delay_1]; \\
[2:a]adelay=delays=16000:all=1[a_delay_2]; \\
[3:a]volume=volume=0.2,atrim=end_sample=943740[bgm]; \\
[bgm][a_delay_0][a_delay_1][a_delay_2]amix=inputs=4:duration=first" \\
-b:v 2M \\
-b:a 128k \\
-movflags faststart \\
concat.mp4
虽然示例中的BGM长度是够的,但真实应用场景中,背景音乐可能是用户自定义的,因此长度不一定每次都够。为了避免出现问题,将BGM流无限循环播放。
- 由于第一个输入的音频不存在延时,使用anull滤镜直通成统一的流标签;
- 来自v_2.mp4的音频流[1:a],其延迟的时长来自于v_1.mp4的视频流时长(秒转换为毫秒);
- 来自v_3.mp4的音频流[2:a],其延迟的时长来自于v_1.mp4的视频流+v_2.mp4的视频流时长;
- 来自bgm.mp3的音频流[3:a],对其压低音量后进行了符合视频总长度的剪裁。这里使用了基于采样率的计算。
为什么基于采样率剪裁呢?上文中可知,所有片段的音频采样率必须一致。因此就有了一个常数:44100,也就意味着1秒钟会有44100个采样。已知视频总时长后,可以折算成音频应当含有多少个采样。不用时间基是因为来源背景音乐的时间基可能与片段中音频流的时间基不一致,避免麻烦而已。
至此,所有的基础准备都已完成,剩下的就是混音了,把所有经过延迟的音频流都混音到bgm音频流。注意bgm流标签一定要放在第一个,因为后面amix滤镜的时长算法采用了first,也就是保持第一个流的时长。
至此,输出的是一个严格音视频同步的视频。
如何更加精确计算延迟
为了简化逻辑,上面的示例命令简单写了延迟的毫秒数。但是这个毫秒数应当如何计算呢?
首先来看下视频的duration是如何计算而来:
duration = duration_ts * time_base
例如有视频流信息为:
"time_base": "1/12800"
"start_pts": 0
"start_time": "0.000000"
"duration_ts": 128000
"duration": "10.000000"
即:
duration = 128000 * 1 / 12800 = 10(秒)
duration_ts为整数,因为引入了除法,duration可能会存在除不尽的情况,在duration字段损失精度。
如果把这样一个不准确的数值不断累加,无异于又引入了误差。
正确的做法是取每一个片段的duration_ts,这个字段是int64类型。由于concat要求每个子剪辑的视频流必须时间基一致,因此可以累加duration_ts。
真正加入延迟时,再把累加到的duration_ts折算成对应的duration,这样将误差一直控制在合理范围。
为什么要增加延迟
在和同事讨论这个方案的时候,有人提出了疑惑:“本来拼接的时候就音视频不同步,加上了延迟不就更不同步了吗?”。后来了解了他的想法后,才知道是个很基础的问题。来看下这张图:
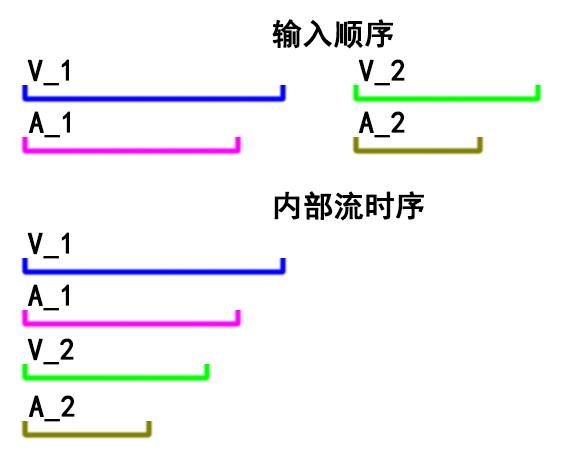
无论输入给FFmpeg多少个源,包含多少个流,在经过demux后,所有的流都是从0时刻开始的,并不会因为输入源的顺序而使得后输入的流就一定会产生某些滞后。
另一种concat实现
ffmpeg中为我们提供了批量合并的功能,首先将准备拼接的文件列表以如下形式进行罗列:
file 'media_1.mp4'
file 'media_2.mp4'
...
以file开头,单引号将文件名包含进去,支持完整文件名和相对文件名,使用UTF-8无BOM方式保存成清单文件,例如manifest.txt。然后使用命令:
ffmpeg -f concat -i manifest.txt -c copy concat.mp4
该方法将自动对齐音视频,对齐算法和上文中提到的逻辑很像,也是通过错位。但不同的是,音频部分直接修改包数据的播放时间(pts)(具体代码请参阅:libavformat/concatdec.c中的concat_read_packet函数实现)。但问题也暴露出来了,正如前文中提到的例子那样,假设两段视频文件的音频流都比各自的视频流短,在播放的时候可能(这里说可能,取决于播放器的支持情况)无法显现出任何问题,观看似乎是正常的。但将这样的文件直接导入类似于Premiere Pro这样的编辑软件就会发现,两段音频紧挨着播放了,就像直接concat那样。即便不是用于视频剪辑软件,当使用FFmpeg命令对这样拼接的视频提取音频流时,也是一样的结果。中间无静音音频。
解决方法:需要在两段音频中间补充静音音频,从而使该音频流从头至尾自然地播放,具体方法有两种:
ffmpeg -f concat -i manifest.txt -filter_complex "[0:a]aresample=async=1000" concat.mp4
或者
ffmpeg -f concat -i manifest.txt -async 1000 concat.mp4
两者都是一样的,自动对中间的空白区域填充静音音频。其中async参数可调,一般取1000即可大致满足要求。
要特别注意的是,填充的只是中间的空白区域,如果最后一个片段的音频流也短于视频流,则不会对其进行填充至视频的结尾。
有的同学可能会想,例子中是两个视频文件,音频流短于视频流。如果长于视频流会怎样呢?以本方法为例,拼接结果为:
- 前一个视频流的最后一帧不断被复制,直到音频流播放完毕(视频流未结束);
- 后一个视频流播放完即停止,常规播放器处理也一般是静止显示(但视频流此时已经结束),音频流继续播放,直到结束。
以上是关于FFmpeg实现音视频同步的精准片段拼接的主要内容,如果未能解决你的问题,请参考以下文章