治理企业“数据悬河”,阿里云DataWorks全链路数据治理新品发布
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了治理企业“数据悬河”,阿里云DataWorks全链路数据治理新品发布相关的知识,希望对你有一定的参考价值。
简介: 10月19日,在2021年云栖大会上,阿里云重磅发布DataWorks全链路数据治理产品体系,基于数据仓库,数据湖、湖仓一体等多种大数据架构,DataWorks帮助企业治理内部不断上涨的“数据悬河”,释放企业的数据生产力。

阿里巴巴集团副总裁 阿里云智能计算平台事业部高级研究员贾扬清现场分享
“当数据量变得越来越大,单位数据的价值会变得越来越小,全链路数据治理让数据从低质低效向高质高效流动。”
阿里巴巴集团副总裁,阿里云智能计算平台事业部高级研究员贾扬清在现场表示。黄河泥沙的淤积使河床不断抬高,形成了河高于地平面的“地上悬河”,在河南开封,最高的悬河达到10米,并且河床每年都会以10厘米的速度增高,而随之而来的,两边的堤坝也在不断地增高。在企业的数字化转型中,数据量变得越来越大,机器变得越来越多,团队变得越来越大,数字化转型真的变得越来越好吗?对于企业来说,表象的繁荣不代表未来不会发生一场“洪水”。在阿里巴巴,双11已经成为了日常,2021年大数据计算服务MaxCompute的日常数据处理的水位线已经超过2020年双11的峰值,不断增长的数据量已经造成了极大的成本与效率的压力。
机器的效率+人的效率=数据的效率
面对每年如此膨胀的数据,阿里巴巴的解法是通过大数据+AI一体化平台的能力,让数据效率成为企业的核心指标。在机器的效率层面,MaxCompute作为离线数仓,单日数据处理量已经达到1.7EB,但是除了数据量,更应该关注的是MaxCompute仅用10%的机器增长,就支撑了75%的数据量增长。这里面是MaxCompute在底层的存储和性能不断地追求极致的优化,并且连续5年打破TPCx-BigBench 100TB规模性能世界记录。同时Hologres作为实时数仓,峰值每秒写入5.96亿条,单表存储高达2.5PB,基于万亿级数据对外提供多维分析和服务,99.99%的查询可以在80ms以内返回结果。Hologres与MaxCompute组成离线、实时、分析、服务一体化的数据仓库,从底层就极大地简化了大数据架构的复杂度。机器层面的效率往往容易被衡量,但是人的效率却很难被量化。DataWorks从2009年开始成为阿里巴巴集团统一的大数据开发治理平台,完成阿里巴巴数据中台的搭建。对一个平台的完善性与易用性,用户往往会用脚投票。目前在DataWorks上构建的大规模协同数据中台的每日活跃用户数已经超过5万,平均每3个阿里巴巴员工就有1个在使用DataWorks,服务阿里巴巴内部几乎所有部门,沉淀的全链路数据治理核心能力超过数百项。FY2020,阿里巴巴通过数据治理的综合收益超过10亿元,可以说大数据开发治理平台DataWorks与计算引擎MaxCompute、Hologres组成了大数据架构下的“Wintel联盟”,共同提高企业数据的效率。

建设经验:从小作坊到大平台到敏捷制造
数据治理也好、数据中台也好,从来也不是一个从象牙塔里想出来的产品,而是经过很多年磨出来的。阿里巴巴的数字化转型也经历过刀耕火种的年代,每个业务团队维护多套Hadoop集群,像一个个小作坊:有什么用什么,需要什么加什么,各种技术组件像搭积木一样逐渐堆砌起来。而在这个过程中,经常会非常痛苦,平台发布了一个新的功能,不知道什么原因把另一个组件搞挂了,然后技术人员花很长时间去排查另一个组件有什么问题,修复了一个组件,发布了一下,又把另一个搞挂了,问题不断冒出就像“按下葫芦浮起瓢”,好像永远没有尽头。于是,阿里巴巴开始轰轰烈烈的平台统一计划,搭建起了大平台,把开源的架构改成自研的架构,数据逐渐都迁移到MaxCompute上。这个时候数据中台的概念也开始在集团内推广,逐渐将3个ONE的数据中台方法论落地到DataWorks,完成了阿里巴巴整个数据中台的搭建。至此,从核心的电商天猫淘宝,到饿了么、优酷、盒马等各个业务团队都在同一套大平台上进行一站式的协同数据开发。但是随着大平台的普及,使用的人数越来越多,数据的治理也会越变得更加复杂。在不断产生成千上万张表中,企业无法知道有多少条不规范的语句像白蚁一样正在消耗大量的计算资源;有多少张表正在重复地被复制,制造表象的“数据繁荣”;有多少脏数据在不断生产污染数据的质量;有多少张表正在被不断申请权限使用,面临数据安全的风险。这些问题都对大平台提出了严峻的挑战。于是,大平台逐渐往敏捷制造不断演进,通过全链路的数据治理能力,以全局的视角进行管控,并同时实现数据的决策的下放。

DataWorks全链路数据治理新品发布
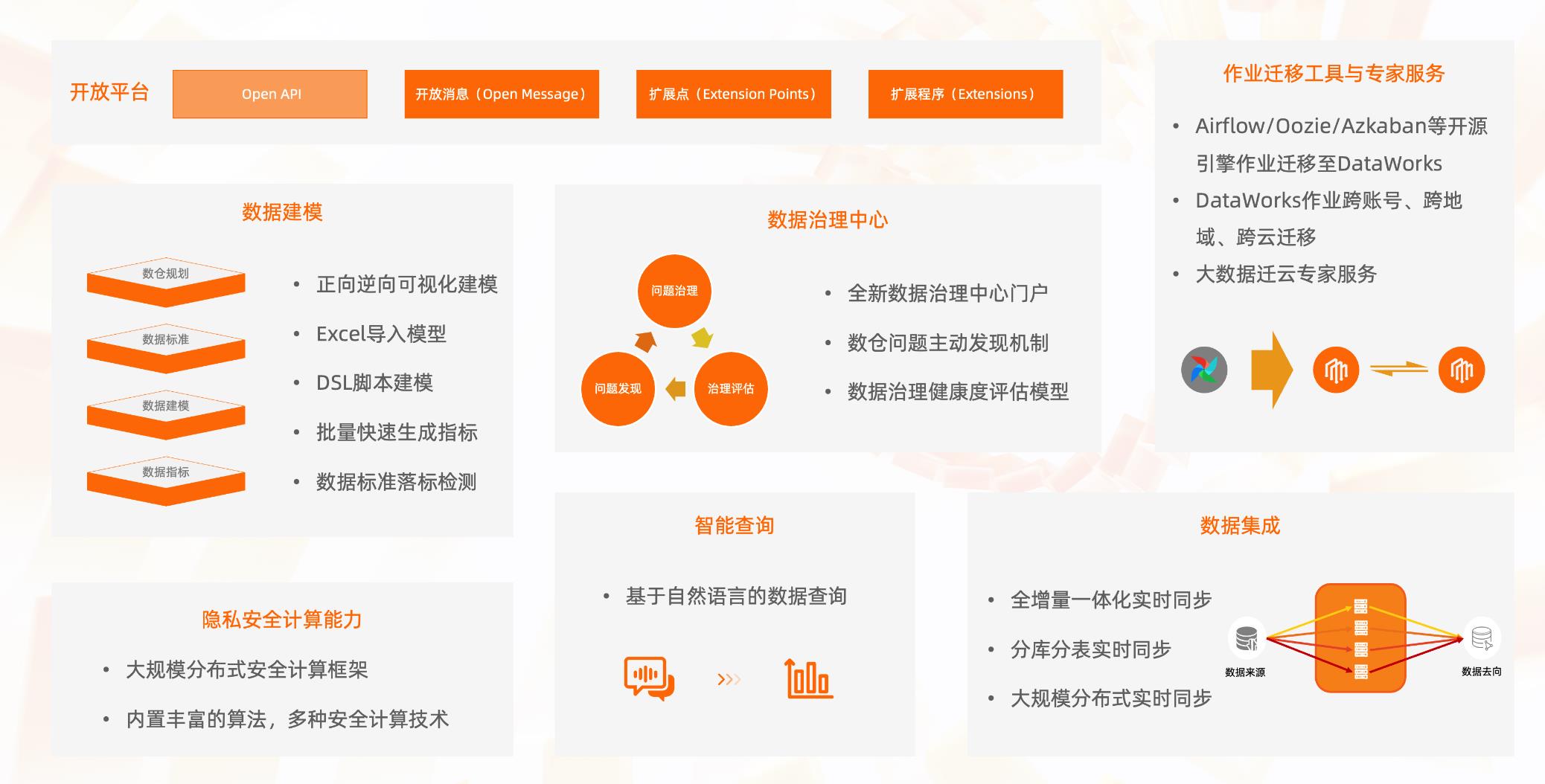
2021云栖大会全链路数据治理峰会,DataWorks在十二年积累的数百项数据开发治理能力之上,重磅发布全链路数据治理系列新品。
数据治理中心
数据治理对于企业的大数据团队,不单是一个技术问题,更是组织和管理问题。对于整个组织来说,如何来衡量数据治理最终的效果?如何更好地发挥组织的主动性?在一些企业当中,会成立了专门的数据委员会,制定一些数据治理的规范,但是发现平台并不能很好地支持这些规范,又或者说企业购买了一个数据平台,但是却不知道如何通过平台来完成数据治理的工作。在阿里巴巴内部经常会参考一个健康分的概念,从组织设计上,数据委员会下面有平台团队,业务团队,以及风控、财务等协同团队。那对于某个业务团队来说,会制定一个今年的目标比如说把健康分从80分提升为90分,从计算、存储等方面入手,不单从业务侧、生产侧开展治理优化工作,有需求也会提给数据平台团队,对引擎和数据平台产品进行优化演进,大家一起朝这个目标努力。组织有了可测量的方式,这些部门就可以把这些数字放到自己的目标里去。同时各类的数据治理战役,各个团队的比武等等长效的运营工作,也可以通过健康分做不断地延展,达到组织数据协同的目的,发挥数据治理组织的主动性。

DataWorks全新发布的数据治理中心,针对企业计算、存储、研发、质量、安全五个方面形成企业数据治理健康分,以问题驱动的理念,覆盖事前、事中、事后的全链路主动式数据治理和数据治理健康度评估。企业的数据治理不再一个 “阶段性项目”,而是一个“可持续的运营项目”。

智能数据建模
企业建了一个平台,做了很多规范治理,对于业务人员的价值到底是什么?省了多少成本,治理了多少问题,对于业务人员相对是无感的。业务方只希望更快地拿到想要的数据,于是原先的数据仓库建设方式更多的是自底向上小步快跑,快速满足需求为先。而如今的全链路数据治理,让数据仓库的建设向规范化,可持续发展方向演进,强调面向业务视角自顶向下进行规范建模与面向开发视角自底向上构建数仓双管齐下。

DataWorks全新发布智能数据建模,沉淀阿里巴巴数据中台建设方法论,从数仓规划、数据标准、维度建模、数据指标四个方面,以业务视角对业务的数据业务进行诠释。智能数据建模支持快速数据建模,包含正向建模与逆向建模,提供分钟级的模型创建能力。同时打通数据开发,可以直接将数据模型发布到多个引擎,一键生成质量规则,直接发布表并自动生成ETL简代码。企业的业务人员可以方便地了解数据全貌,快速获取所需的数据指标以及基于数据模型进行数据分析和探查,企业内所有的员⼯可以实现“数同⽂”的快速理解与流通,让数据决策可以实现真正有效的下放!

盒马鲜生通过DataWorks智能数据建模落地新零售行业数据模型Rex-LDM
同时,现场还发布了DataWorks数据集成实时同步能力、智能数据查询、隐私安全计算、DataWorks开放平台、数据作业迁云工具与迁云专家服务等多项功能。
中国信通院在2021年9月发布的《全球数字经济白皮书》报道,去年我国的数字经济规模已经达到5.4万亿美元,占比GDP近1/3。在数字经济时代,数据已经成为关键生产要素,就像在农业经济时代和工业经济时代中,土地、劳动力是关键的生产要素。DataWorks通过智能数据建模、全域数据集成、高效数据生产、主动数据管理、全面数据安全、快速数据服务六大全链路数据治理的能力,承载千行百业数字化转型的可能。目前,DataWorks已经在数字政府、新金融、新零售、能源、工业、交通、游戏、教育、数字营销等行业落地数千家客户。
国家电网大数据中心通过DataWorks实现总部+27家省(市)公司PB级数据的统一管理,通过全链路数据中台的治理与监测运营体系,加快电网整体数字化转型升级。
创梦天地基于开源的EMR引擎,用DataWorks替换自研调度系统,企业内部的技术人员可以更加专注业务,助力游戏行业的数据化运营。
亿滋中国通过DataWorks智能数据建模进行全链路的数据模型治理,极大提升数据中台的自服务能⼒,让企业数据决策实现下放,释放新零售的数字化力量。

企业数字化转型正在进入的深水区,“数据悬河”将逐渐成为企业的“达摩克斯之剑”,阿里云正在与各行各业的客户与合作伙伴一起,通过全链路数据治理,管得好数据、用得好数据,让数据向先进生产力集聚!
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于治理企业“数据悬河”,阿里云DataWorks全链路数据治理新品发布的主要内容,如果未能解决你的问题,请参考以下文章