tensorflow学习2----tensorflow2基础知识介绍
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow学习2----tensorflow2基础知识介绍相关的知识,希望对你有一定的参考价值。
基础概念介绍
人工智能:简单理解就是让机器具有人的思维和意识
人工智能三学派:
- 行为主义:基于控制论构建感知–控制体系
- 符号主义:基于算数逻辑表达式,求解问题先把问题描述为表达式,再求解表达式
- 连接主义:仿生学,模仿神经元连接关系
数据类型
tensorflow基本的数据类型:int8/16/32/64, float16/32/64, bool, string
张量的生成
张量:与numpy中的数组,python中的列表是一个东西,只不过再tensorflow中叫做张量(tensor)
使用tensorflow自带的生成数据的方式,与numpy的使用方式基本一致
关于numpy的使用可以看这篇文章
import tensorflow as tf
import numpy as np
# 直接创建tensor
a = tf.constant(value=[1, 2, 3, 4], dtype=tf.float32, shape=(2, 2), name="a")
# value: 张量中的数据,必填
# dtype:张量的数据类型,可选的,不指定则根据数据自动选择合适的类型
# shape: 张量的形状,可选。不设置则张量为value的shape
# name:张量的名字,可选
print(a)
print(a.shape)
print(a.dtype)

# 通过numpy创建, 通过tf.convert_to_tensor实现转换
# 转换后的shape与numpy的shape一致
b = np.linspace(1, 4, 5)
print(b)
a = tf.convert_to_tensor(value=b, dtype=tf.float32, name="aa")
print(a)
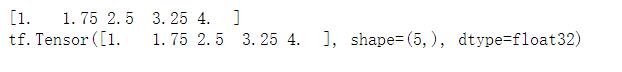
# 创建全为0的张量
tf.zeros(shape=(3, 4))

# 创建全为1的tensor
tf.ones(shape=(3, 4))

# 创建全为指定值的张量
tf.fill(dims=(3, 4), value=9)

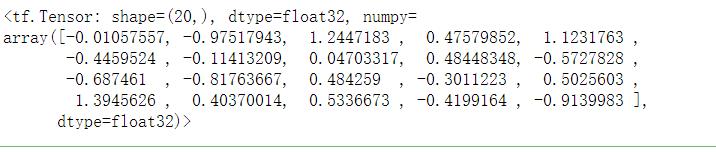
# 生成正态分布的tensor
tf.random.normal(shape=(20,), mean=0, stddev=1)
# 默认生成均值为0,标准差为1的标准正态分布
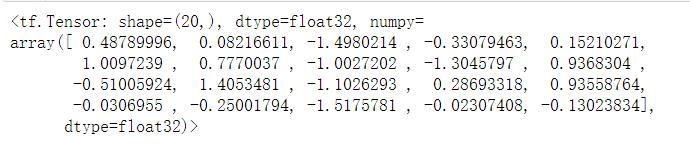
# 生成截断式的镇泰分布
tf.random.truncated_normal(shape=(20,), mean=0, stddev=1)
# 截断式生成的数据分布在(u-2q, u+2q)之间
# u:均值,q:标准差
常用函数
# 强制将tensor转换为相应的数据类型
a = tf.constant(value=[1, 2, 3], dtype=tf.int32)
print(a)
b = tf.cast(x=a, dtype=tf.float64)
print(b)
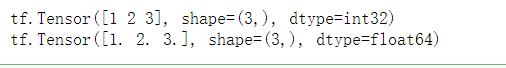
# tensor最大值与最小值
a = tf.constant(value=[[1, 3, 4], [2, 2, 5]], dtype=tf.float32)
print(a)
tensor_min = tf.reduce_min(a) # 默认获得整个张量的最小值
print(tensor_min)
tensor_max = tf.reduce_max(a) # 默认获得整个张量的最大值
print(tensor_max)
# 通过axis来指定获得的最值的方向
# axis=0表示获得每一列的最值,axis=1表示获得每一行的最值
tensor_col_min = tf.reduce_min(a, axis=0)
print(tensor_col_min)
# 同样的函数还有reduce_mean, reduce_sum,这里不展示了

# 将变量标记为可训练,被标记的变量会在反向传播中记录梯度信息
# 神经网络训练中,常用该方法标记待训练参数
w = tf.Variable(tf.random.normal(shape=(2, 2)))
print(w)
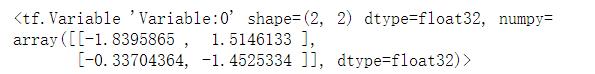
张量的计算
四则运算需要要求参与运算的tensor有相同的shape
矩阵运算需要满足矩阵的运算要求(m,n) x (n,k)这样的类型
# 加法运算
a = tf.constant(value=[[1, 1], [1, 1]])
b = tf.constant(value=[[2, 2], [2, 2]])
tf.add(a, b)

# 减法运算
tf.subtract(a, b)

# 乘法运算
tf.multiply(a, b)

# 除法运算
tf.divide(a, b)

# 次方运算
tf.pow(b, 3)

# 开放运算,不支持int32的数据类型,所以需要进行数据转换
tf.sqrt(tf.cast(b, dtype=tf.float32))

a = tf.constant(value=[[1,1], [1, 1]])
b = tf.constant(value=[[2,2,2], [2,2,2]])
tf.matmul(a, b)

特征标签组合
神经网络的传入数据是特征标签配对的数据。所以需要将特征标签组合
feature = np.array([1, 2, 3, 4])
labels = np.array([0, 1, 1, 1])
# 该方法接收的参数对tensor格式和numpy格式的数据都适用
data = tf.data.Dataset.from_tensor_slices((feature, labels))
print(data)
for ele in data :
print(ele)

将输出转换为符合每个类别的概率分布
采用softmax函数来计算输入的每个数据对应每一个类别的概率分布
s
o
f
t
m
a
x
(
y
i
)
=
e
y
i
∑
j
=
0
n
e
y
j
softmax(y_i) = \\frac {e^{y_i}} {\\sum^n_{j=0} e^{y_j}}
softmax(yi)=∑j=0neyjeyi
# 对于三分类的数据,神经网络的输出值为1,2,3
# 通过softmax来计算每个类别的概率
y = tf.constant([1, 2, 3], dtype=tf.float32)
tf.nn.softmax(y)
# <tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.09003057, 0.24472848, 0.66524094], dtype=float32)>
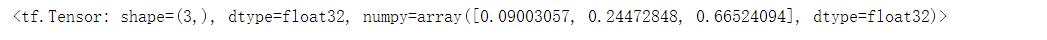
梯度的计算
以loss = (w+1)^2来展示用法
loss对w的导数为2*w + 2
# 初始参数w,并标记为可训练的
# 在with结构中使用tf.GradientTape来实现对某个函数的指定参数求导
w = tf.Variable(tf.constant(value=5, dtype=tf.float32))
with tf.GradientTape() as tape :
loss = tf.square(w+1) # 设置需要求导的目标函数
grad = tape.gradient(loss, w) # 计算导数的值
print(grad) # tf.Tensor(12.0, shape=(), dtype=float32)
# 将上述的过程封装到for循环中,就是一个梯度下降的过程
总结
本篇文章介绍了tensorflow常用的函数。是一篇基础的入门文章。文中的很多方法都可以通过别的手段实现,比如numpy,pandas等工具实现。具体选择什么方式,看个人的喜好,我的建议是学习tensorflow就使用他自带的方法,这样能加深我们对tensorflow的记忆。
以上是关于tensorflow学习2----tensorflow2基础知识介绍的主要内容,如果未能解决你的问题,请参考以下文章