JavaWeb 基础知识 --多线程(阻塞队列+生产消费者模型)
Posted RAIN 7
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaWeb 基础知识 --多线程(阻塞队列+生产消费者模型)相关的知识,希望对你有一定的参考价值。
阻塞队列
BlockingQueue 是Java标准库中提供的 阻塞队列,底层是由链表、数组实现的,


实现了Queue接口

所以 BlockingQueue 由Queue 的常见方法 offer、poll、peek等方法
但是我们在使用阻塞队列时,常用到的方法是 put(),take()
put 带有阻塞功能,但是offer 不带有,使用阻塞队列一般是使用 put 入队,take 出队
阻塞队列的使用
阻塞队列如何体现其阻塞功能呢?
当队列为空时,我们再进行出队操作,发生阻塞等待
当队列已满时,我们再进行入队操作,发生阻塞等待
我们来简单使用以下BlockingQueue 的常见方法
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
queue.put("hello");
String elem = queue.take();
System.out.println(elem);
}
在上面的这组代码中,我们只进行了简单的入队出队操作,并没有涉及到线程阻塞的情况
我们来尝试写一下线程阻塞的代码
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class ThreadDemo2 {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
queue.put("hello");
String elem = queue.take();
System.out.println(elem);
String elem2 = queue.take();
System.out.println(elem2);
}
}
我们来看一下运行的结果
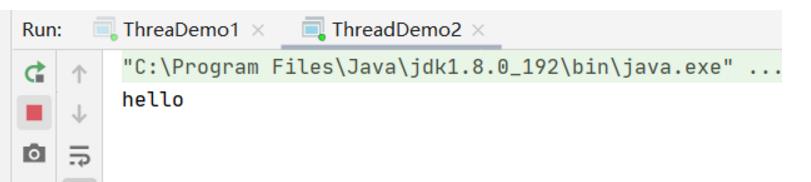
只打印了一个hello,程序一直没有停止运行,在等待状态…
这说明什么呢?
代码执行到这里就不走了,一直等到有其他线程给这个队列中放入新的元素为止
了解了阻塞队列,我们就可以用阻塞队列来完成“生产者消费者模型”
生产消费者模型
我们先通过一个非常形象的例子来展开对这个模型的了解
不知道大家在家里有没有包过饺子
我们将包饺子简化成两步——> 擀皮、包饺子

第一种方式
每个人,擀饺子皮,擀完一个,就包一个,然后在擀一个,再包一个。
第二种方式
一个人专门负责擀,四个人专门负责包
在现实生活中第二种方式更常见吧,第二种方式体现了高效的效率,这种方式其实就是应用了所谓的"生产者消费者模型"
擀饺子皮的人: 生产者
包饺子的人: 消费者
生产者和消费者之间还有一个非常重要的角色,交易场所: 用来放饺子皮的盖帘.
例子举完了,我们来看一下计算机中的模型
计算机中,生产者就是一组线程,消费者也是另外一组线程,交易场所就是这个阻塞队列了.
使用场景
生产者消费者模型是在服务器开发过程中采用的一种非常非常有用的编程手段。
使用的好处
1、解耦合
2、削峰填谷
接下来我们就先来介绍一下这种模型的好处
1.解耦合
大家可能不懂这个意思,我们来看一个场景

我们现在有两台服务器A、B

如果直接传输,此时就要求,要么A向B推送数据,要么B给A拉取数据… 这些都是A、B之间直接交互的,两台服务器之间的依赖程度很高
未来如果需要拓展,扩展成搞一个服务器C,也让A给C传输数据,这个时候的改动就有些复杂了(A向BC推送数据,BC向A拉取数据)
但是如果我们引入了一个生产者消费者模型的话,这样的操作就会变得更简单
我们A和BC之间就会有一个阻塞队列,此时如果想在多加服务器C、D、E… 不需要知道A的存在,直接从队列中取数据,这样就降低了对A的依赖,耦合度降低
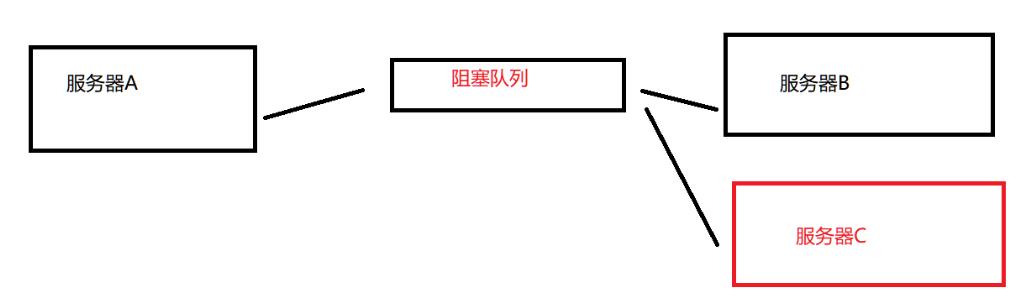
这里的队列相当于中转站的存在
这样的模型下,生产者和消费者之间并不需要对方的存在,也不需要依赖对方是谁,那也就意味着,这里的数据是谁生产的,是谁在消费都不重要,只要能够生产和能够消费就可以了,于是我们的系统也就更加灵活,可以更加随意的替换A、B、C任意模块,这样替换起来更方便,修改起来更方便,我们呢就认为耦合更低
这就是生产者消费者模型的第一个好处,降低代码的耦合程度,让程序维护起来更加方便(涉及到代码设计层次)
2.削峰填谷
第二个好处削峰填谷就更好理解了…
大家应该都听过三峡大坝~
三峡大坝就是削峰填谷的作用

如果到了汛期的时候没有大坝,那么下游可能引发洪灾
如果到了旱期,下游的水就很少,就会引发旱灾
如果有了大坝,到了汛期,就关闸蓄水~让水按照一定的速率往下游走,避免突然一波就把下游冲毁了
到了旱期,开闸放水,让水也按照一定的速率往下游流,避免下流太缺水
有了这个大坝,就让水有了一定的节奏,不至于水过多流或者过少流引发一定严重的后果
汛期相当于峰 ~ 旱期就相当于谷,三峡大坝就有着削峰填谷的作用
这样的情况在我们计算机里也是非常典型的场景
出现在哪里呢?也是服务器处理数据的情况.
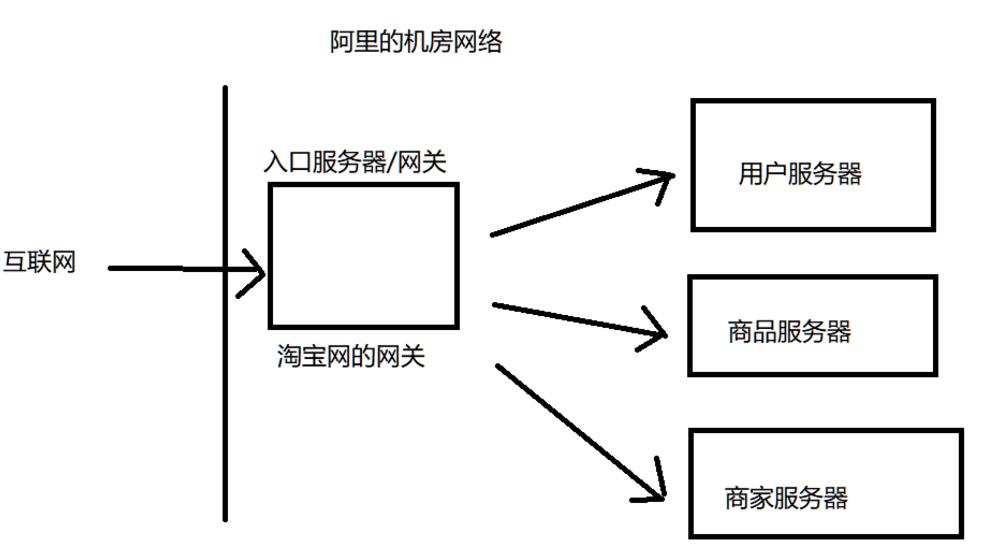
我们假设这是淘宝网络的情况
我们可以知道,从互联网传过来的数据可不知道是多是少,这就相当于上游的水一样,是不可控的,可能平时数据量很少,但是遇到一些突发情况就多了
如果从互联网传来一大波数据,可能我们的网关还能承受的住(网关服务器不提供具体业务,较为轻量),后续的服务器收到很多的请求很可能就会挂掉(因为后续的服务器设计到具体的业务逻辑代码,可能处理一个请求就需要几十毫秒,一旦遇到非常多的数据请求时,就处理不过来了)
所以如果我们的后续服务器只是直接连到网关服务器,那么遇到峰值的情况就很不好处理了,那么实际情况往往是这样的.
网关和其他服务器不是直接相连的,之间还会通过一个阻塞队列进行连接

通过这个队列呢,我们来实现生产者消费者模型的这种情况,网关服务器作为生产者把互联网收到的请求传到队列中,后续服务器作为消费者从这个队列中取出对应的请求,这个时候,即使上游有一大波数据请求来临,冲击到的也只是队列而已,相当于这个队列把这一大波请求都缓存下来了,然后呢,这些消费者服务器还是按照自己一定的速率进行处理请求
削峰
即使网络这边过来一大波请求,这些请求只是冲击了队列服务器,对于后续的业务服务器,仍然是按照固定的速率来消费数据,。海量数据对业务服务器冲击也没那么大了,相当于削峰的效果
填谷
如果互联网这边的数据突然少了,此时呢,后面的服务器也不会闲着,他会处理队列积压的请求,也就不会至于说这些服务器干在这等着,达到一个填谷的效果
说了这么多,对于我们的生产者消费者模型有一个较为清楚的认识,这是以后在后端开发中非常重要的开发方式
既然我们了解了生产者消费者模型,那么我们就可以通过阻塞队列来实现一个简单的生产消费者模型的代码
简单模型代码
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class ThreadDemo {
public static void main(String[] args) {
// 创建一个阻塞队列作为生产消费的交易场所
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();
// 创建一个线程作为生产者模型
Thread producer = new Thread(){
@Override
public void run() {
for (int i = 0; i <100 ; i++) {
try {
// 生产者每生产一个元素,sleep 1s
// 生产元素后立马被消费,在等待的1s中 队列为空线程阻塞等待
queue.put(i);
System.out.println("生产者生产了元素: "+i);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
// 创建一个线程作为消费者模型
Thread custom = new Thread(){
@Override
public void run() {
while(true){
try {
// 只要交易场所有生产的元素,我们就不断地消费
Integer value = queue.take();
System.out.println("消费者消费了元素: "+value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
custom.start();
try {
producer.join();
custom.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在生产者的线程中加了 sleep方法,这说明 消费者消费的速度要远大于 生产的速度,只要队列中有元素,就会被消费掉,而我们生产者呢,其实生产的并不算慢,每隔一秒生产一个元素,这个时候我们就可以很清楚的看到生产者消费者模型的一个效果,每次生产的元素被消费之后,消费者就会进入线程等待,直到生产者生产出新的元素才会停止等待…
看一看代码的运行效果:
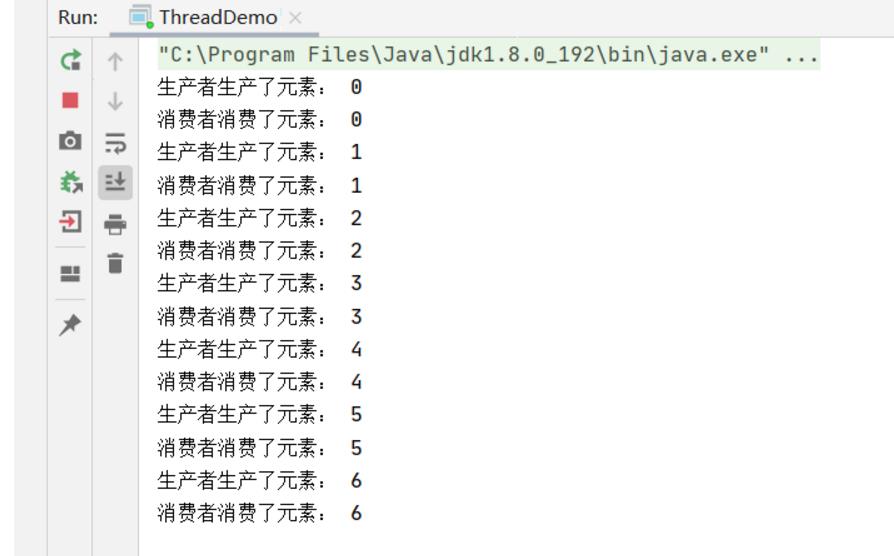
不断的在生产消费元素 ,在这个运行的结果中我们可以很清楚的看到,生产者每生产一个元素,消费者都会立刻的去消费,在生产者生产出新的元素之前,消费者并不会停止运行,而是在阻塞等待.这就是一个典型的生产者消费者模型的一个代码
BlockingQueue的具体实现
接下来,我们重点研究一下,BlockingQueue 代码内部是如何实现的.尤其是线程安全 和阻塞等待,分别都是怎么搞的.
接下来的操作就涉及到了 synchronized wait notify
自己写一个简单版本的BlockingQueue
static class BlockingQueue{
private int front;
private int rear;
private int[] elem;
private int size;
private Object locker = new Object();
public BlockingQueue() {
this.front = 0;
this.rear = 0 ;
this.elem = new int[10000];
this.size = 0;
}
// 入队操作
public void put(int value) throws InterruptedException {
synchronized (locker) {
// 如果队列中的元素已经放满了,那么在BlockingQueue中我们会进行阻塞等待
// 此处的条件最好写作 while 而不是 if
// 如果有多个线程在阻塞等待的时候,万一同时唤醒了多个线程
// 就有可能出现,第一个线程放入元素之后,第二个元素想放,就又满了的情况
// 虽然take中 的 notify 只唤醒了一个等待的线程,用if也不算错
// 但是 我们如果用 while,在wait之前可以判断一次,如果为满,那么wait
// 在 notify唤醒之后,再次判断是否为满 ,起到一个确认的作用,如果不满,那么继续入队
while(size == this.elem.length){
// 如果队列是满的,那么就进入线程阻塞等待
locker.wait();
}
this.elem[this.rear] = value;
this.rear++;
if(this.rear>=this.elem.length){
this.rear = 0;
}
this.size++;
locker.notify();
}
}
// 出队操作
public int take() throws InterruptedException {
int ret = 0;
synchronized (locker) {
// 出队时,如果队列为空,那么在BlockingQueue中要进行阻塞等待
while (size == 0) {
locker.wait();
}
ret = this.elem[this.front];
this.front++;
if (this.front >= this.elem.length) {
this.front = 0;
}
this.size--;
// 此处的notify 用来唤醒 put 中的 wait
locker.notify();
}
return ret;
}
}
put 和 take 都有可能出现阻塞的情况(wait)
由于这两个代码中的阻塞条件是对立的,因此这两边的 wait 不会同时触发
put 来唤醒 take 的阻塞, put操作就破坏了 take 的阻塞条件(队列为空)
take 来唤醒 put 的阻塞 ,take操作就破坏了 put的阻塞条件(队列为满)
使用 while 就是为了让 wait 被唤醒之后,再次确认下条件是否成立.
我们再写一个生产者消费者模型来使用我们自己写的阻塞队列来进行实现
public static void main(String[] args) throws InterruptedException {
// 创建一个阻塞队列
BlockingQueue queue = new BlockingQueue();
// 创建一个线程作为生产者模型
Thread producer = new Thread(){
@Override
public void run() {
for(int i =0;true;i++) {
try {
queue.put(i);
System.out.println("生产者生产了元素: "+i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
// 创建一个生产者模型的线程
Thread custom = new Thread(){
@Override
public void run() {
while(true){
try {
int ret = queue.take();
System.out.println("消费者消费了元素: "+ret);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
custom.start();
producer.join();
custom.join();
}
看一下运行效果:
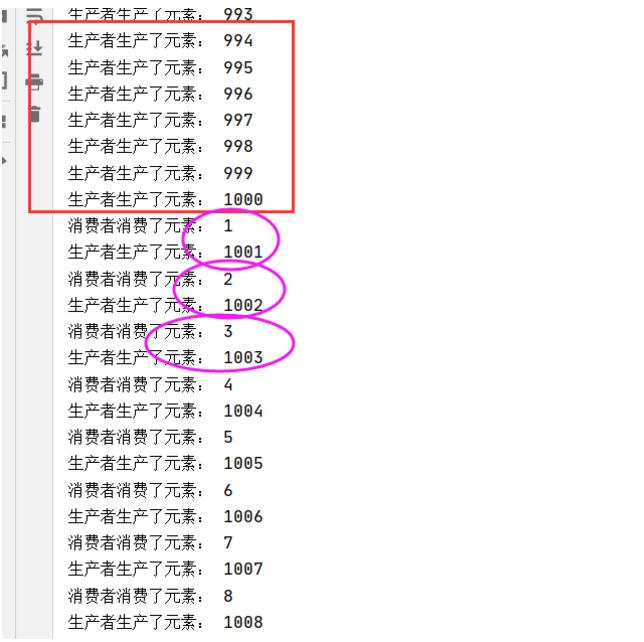
首先因为我们设定的阻塞队列的长度为1000,所以快速的生产了1000个元素,到1001个队列满,生产者开始阻塞等待,直到消费者取出一个元素,等待结束,继续入队,出一个元素,入一个元素,成功实现了阻塞队列的相关功能.
我们自己实现的阻塞队列也成功运用到了生产消费者模型上,运行效果成功.
这节的内容就到这里了,希望大家多多练习,谢谢大家的阅读与欣赏…
以上是关于JavaWeb 基础知识 --多线程(阻塞队列+生产消费者模型)的主要内容,如果未能解决你的问题,请参考以下文章