Day442&443.K8s -谷粒商城
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day442&443.K8s -谷粒商城相关的知识,希望对你有一定的参考价值。
K8s
分布式编排管理集群的系统
一、K8s快速入门
1、简介
kubernetes简称k8s。是用于自动部署,扩展和管理容器化应用程序的开源系统。
中文官网:https://kubernetes.io/Zh/
中文社区:https://www.kubernetes.org.cn/
官方文档:https://kubernetes.io/zh/docs/home/
社区文档:https://docs.kubernetes.org.cn/
-
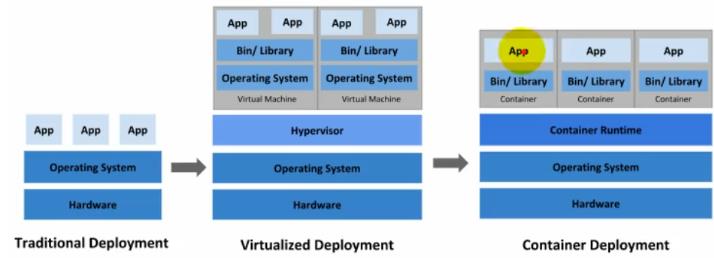
部署方式的进化:
-
传统部署时代:
早期,各个组织机构在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。 例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况, 结果可能导致其他应用程序的性能下降。 一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展, 并且维护许多物理服务器的成本很高。
-
虚拟化部署时代:
作为解决方案,引入了虚拟化。虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)。 虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全,因为一个应用程序的信息 不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器上的资源,并且因为可轻松地添加或更新应用程序 而可以实现更好的可伸缩性,降低硬件成本等等。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
-
容器部署时代:
容器类似于 VM,但是它们具有被放宽的隔离属性,可以在应用程序之间共享操作系统(OS)。 因此,容器被认为是轻量级的。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS
- 好处
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。
- 关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像, 从而将应用程序与基础架构分离。
可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。 - 跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
- 好处
-
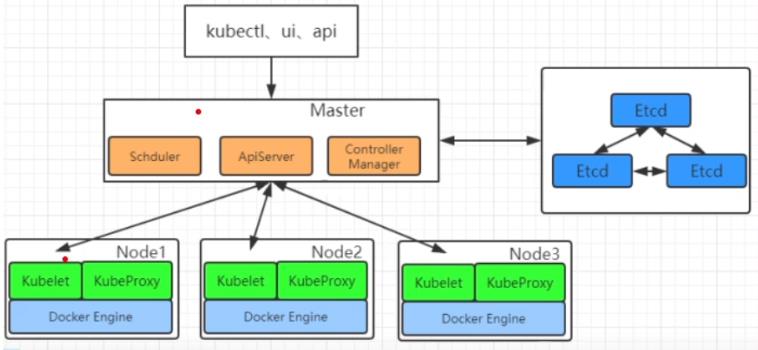
2、架构
- 整体主从方式
Node节点被Master管理,Node节点负责干活,Master负责管理下命令等…
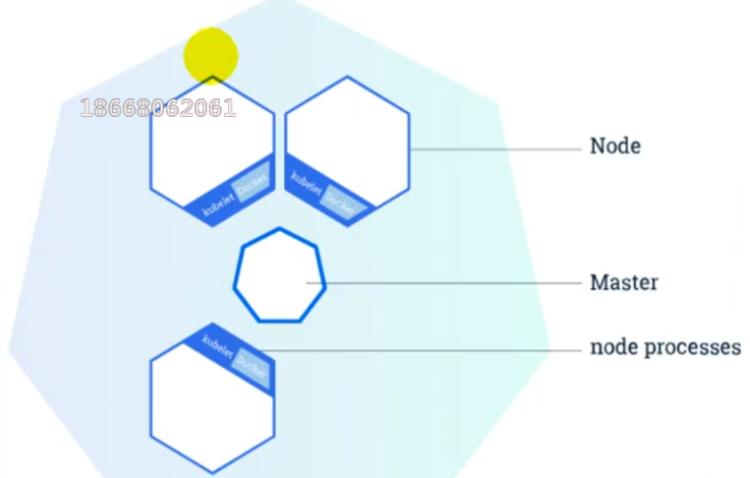
可通过左侧的UI可视化界面或者CLI命令行去发送操作API,API去告诉Master,Master来判断告诉具体是哪个Node节点做什么内容
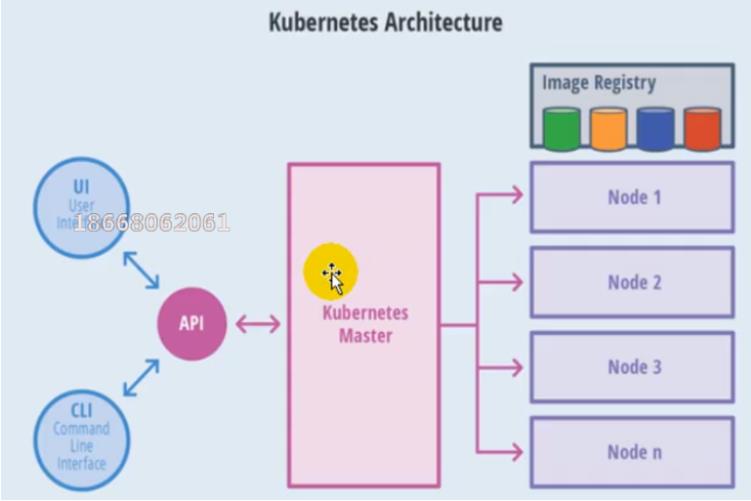
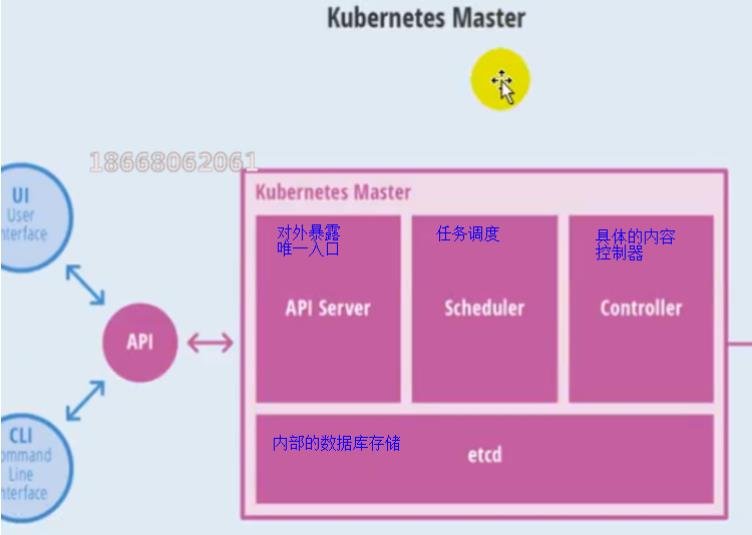
- master节点架构

- Node节点架构
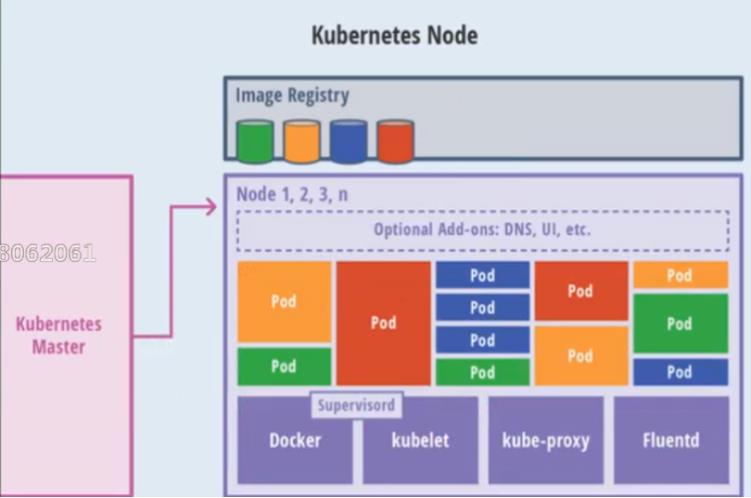
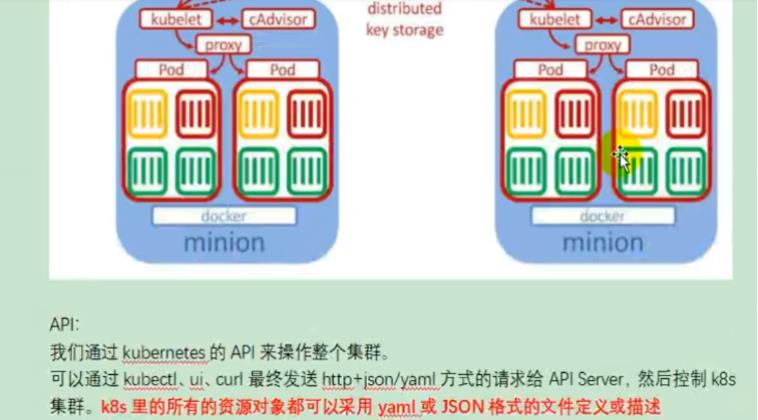
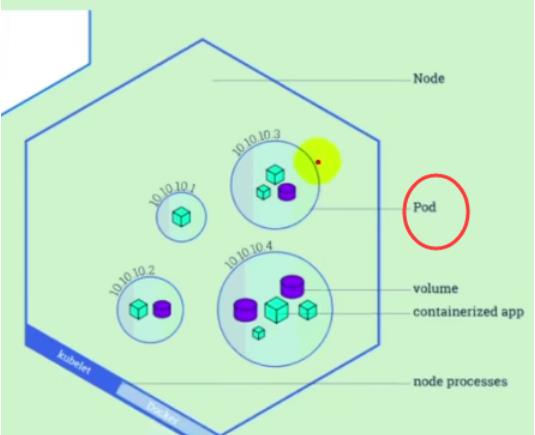
POD是最小的单位
kube-proxy对外代理一个个的Pod
kunelet来管理每个Pod单位

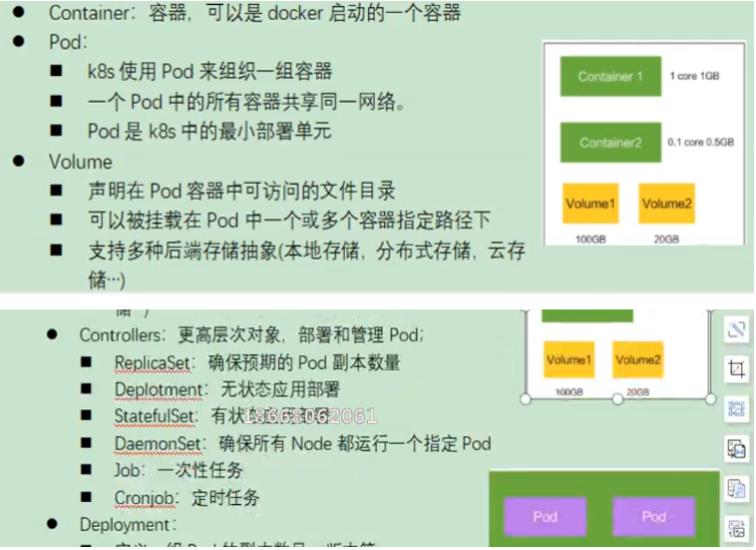
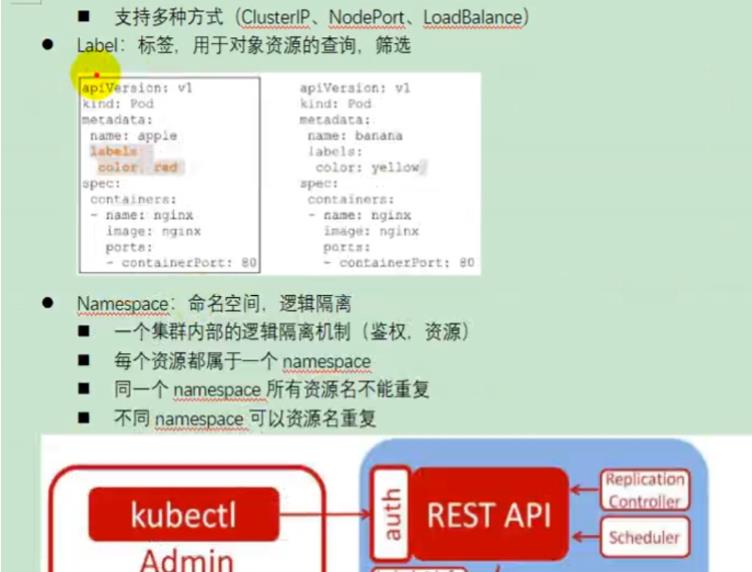
3、概念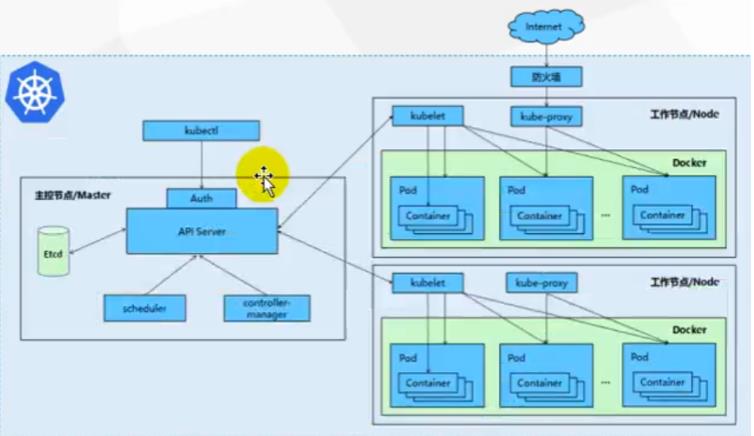


4、快速体验
- 安装minikube
https://github.com/kubernetes/minikube/releases
下载minikuber-windows-amd64.exe 改名为minikube.exe
打开virtualBox,打开cmd
运行
minikube start --vm-driver=virtualbox --registry-mirror=https://registry.docker-cn.com
等待20分钟即可。
- 体验nginx部署升级
提交一个nginx deployment
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
升级 nginx deployment
kubectl apply -f https://k8s.io/examples/application/deployment-update.yaml
扩容
nginx deployment
二、K8s集群安装
1、kubeadm
kubeadm是官方社区推出的一个用于快速部署kuberneters集群的工具。
这个工具能通过两条指令完成一个kuberneters集群的部署
- 创建一个master节点
$ kuberneters init
- 将一个node节点加入到当前集群中
$ kubeadm join <Master节点的IP和端口>
2、前置要求
一台或多台机器,操作系统Centos7.x-86_x64
硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
集群中所有的机器之间网络互通
可以访问外网,需要拉取镜像
禁止Swap分区
3、部署步骤
- 在所有的节点上安装
Docker和kubeadm - 不是Kubernetes Master
- 部署容器网络插件
- 部署Kubernetes Node,将节点加入Kubernetes集群中
- 部署DashBoard web页面,可视化查看Kubernetes资源
4、环境准备
①准备工作
- 可以使用vagrant的Vagrantfile文件快速创建三个虚拟机k8s-node1,k8s-node2和k8s-node3。
Vagrantfile文件内容如下:
Vagrant.configure("2") do |config|
(1..3).each do |i|
config.vm.define "k8s-node#{i}" do |node|
# 设置虚拟机的Box
node.vm.box = "centos/7"
# 设置虚拟机的主机名
node.vm.hostname="k8s-node#{i}"
# 设置虚拟机的IP
node.vm.network "private_network", ip: "192.168.56.#{99+i}", netmask: "255.255.255.0"
# 设置主机与虚拟机的共享目录
# node.vm.synced_folder "~/Documents/vagrant/share", "/home/vagrant/share"
# VirtaulBox相关配置
node.vm.provider "virtualbox" do |v|
# 设置虚拟机的名称
v.name = "k8s-node#{i}"
# 设置虚拟机的内存大小4G
v.memory = 4096
# 设置虚拟机的CPU个数
v.cpus = 4
end
end
end
end
- 网卡
在VirtualBox的“主机网络管理器”中,有两个网卡,网卡1是“网络地址转换”:是为了方便本机和虚拟机同样都能访问到外界互联网。
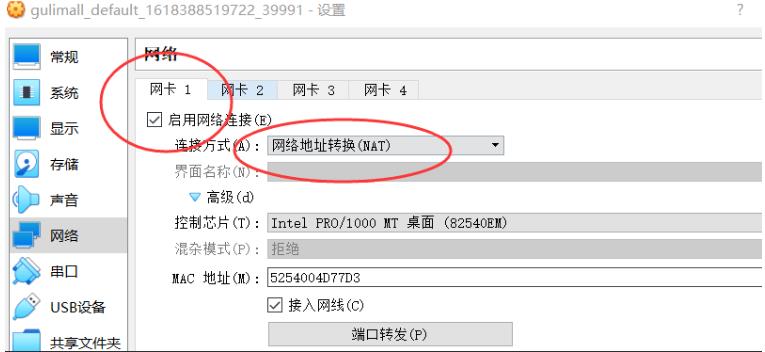
网卡2是仅主机网络,是内部的私有网络,在配置时我们仅保留一个主机网卡:

- 常规
需要装3个节点,需要消耗很大内存以此磁盘空间,选择它存储虚拟机的所有文件:
②创建三个虚拟机
- 执行Vagrantfile文件,创建三个虚拟机k8s-node1、k8s-node1和k8s-node3
- 按照博客链接开启远程ssh密码访问
https://blog.csdn.net/weixin_43334389/article/details/115697067
③NAT网络和前置环境
- 添加NAT网络
在网络地址转换(NAT)的模式下,三个节点的eth0,IP地址相同。而这些地址是供kubernetes集群通信用的,不能相同。
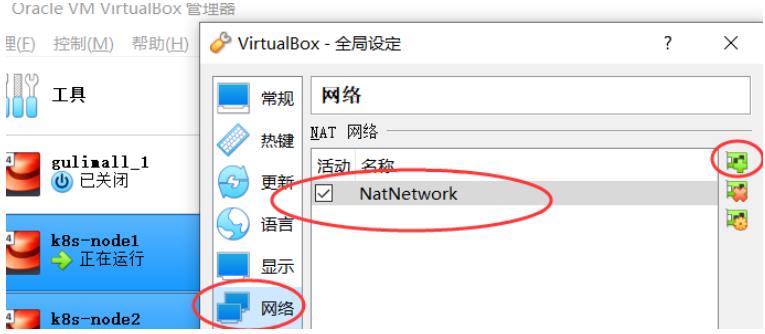
为每个虚拟机添加NAT网络:
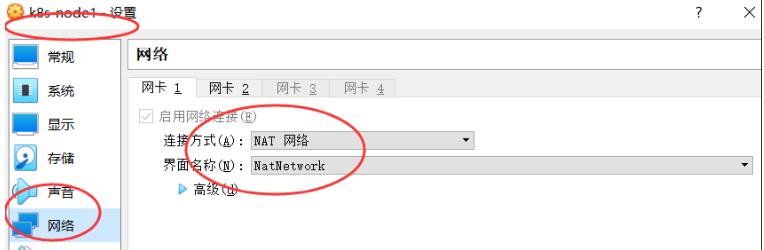
在“高级”选项中,刷新一下生成新的MAC地址,此时三者的eth0的IP地址为:
ip addr#查看eth0对应的ip地址
10.0.2.15
10.0.2.4
10.0.2.55
④设置Linux环境
- 关闭防火墙
在开发模式下,将其关闭,不用配置各种进出规则了。
systemctl stop firewalld
systemctl disable firewalld
- 关闭selinux安全规则检查
# 全局禁掉
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 关闭当前会话窗口
setenforce 0
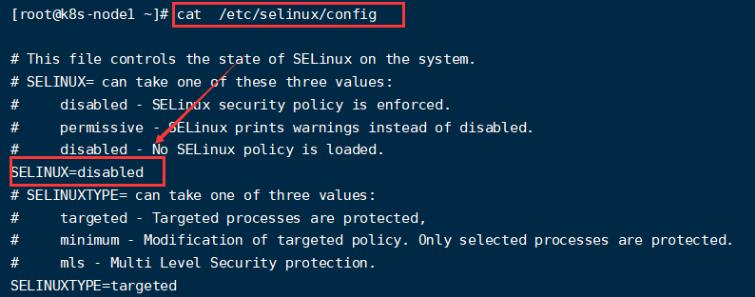
- 关闭swap内存交换分区
该分区会影响kubernetes的性能。
#临时关闭,当前会话
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭
free -g #验证,swap必须为0

- 添加主机名和ip映射关系
vi /etc/hosts
10.0.2.15 k8s-node1
10.0.2.4 k8s-node2
10.0.2.5 k8s-node3
三个虚拟机能够互相ping通,且能够ping通外网baidu.com.。
- 桥接的IPV4流量传递到iptables的链
不执行的话,会有一些流量统计指标的消失。
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
应用规则:
sysctl --system
- 同步最新时间
yum -y install ntpdate
ntpdate time.windows.com #同步最新时间
- 对系统进行备份
5、所有节点安装docker、kubeadm、kubelet、kubectl
Kubenetes默认CRI(容器运行时)为Docker,因此先安装Docker。
①安装Docker
- 卸载之前的docker
$ sudo yum remove docker \\
docker-client \\
docker-client-latest \\
docker-common \\
docker-latest \\
docker-latest-logrotate \\
docker-logrotate \\
docker-engine
- 安装Docker -CE
# 前置依赖
$ sudo yum install -y yum-utils \\
device-mapper-persistent-data \\
lvm2
# 设置docker repo 的yum 位置
$ sudo yum-config-manager \\
--add-repo \\
https://download.docker.com/linux/centos/docker-ce.repo
# 安装docker,以及docker-cli
$ sudo yum -y install docker-ce docker-ce-cli containerd.io
- 配置docker加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://eeqh66oo.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
- 启动docker&设置docker开机自启
kubernetes运行时全靠docker的运行时环境,需要开机自启。
systemctl enable docker

基础环境准备好后,可以给三个虚拟机备份一下。
②添加阿里云yum源
- 添加yum源
告诉kubernetes这些yum源地址,需要的东西在哪里安装。
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
③安装kubeadm,kubelet和kubectl
- 指定版本安装
# 检查yum源中是否有kuber有关的yum源
yum list|grep kube
yum install -y kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3
# 开机启动并启动
systemctl enable kubelet
systemctl start kubelet
- 查看kubelet启动状态
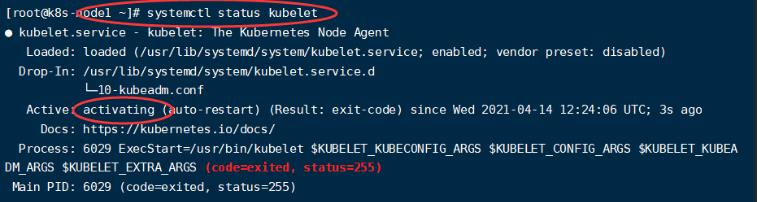
systemctl status kubelet
启动中,由于我们还有一些东西没有配置,启动不起来很正常。
④部署k8s-master
- 使用下面的命令,那个镜像下失败后,需要等待很长时间。
apiserver-advertise-address是master机的ip地址
service-cidr是service子网
pod-network-cidr是pod子网
kubeadm init \\
--apiserver-advertise-address=10.0.2.15 \\
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \\
--kubernetes-version v1.17.3 \\
--service-cidr=10.96.0.0/16 \\
--pod-network-cidr=10.244.0.0/16
kubeadm init \\
--apiserver-advertise-address=172.22.30.3 \\
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \\
--kubernetes-version v1.17.3 \\
--service-cidr=10.96.0.0/16 \\
--pod-network-cidr=10.244.0.0/16
因此,暂时不使用上面的初始化命令,首先使用下面的master_images.sh命令进行执行下载镜像,还可以查看进度,文件内容如下:
#!/bin/bash
images=(
kube-apiserver:v1.17.3
kube-proxy:v1.17.3
kube-controller-manager:v1.17.3
kube-scheduler:v1.17.3
coredns:1.6.5
etcd:3.4.3-0
pause:3.1
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
done
然后再运行初始化命令:
$ kubeadm init \\
--apiserver-advertise-address=10.0.2.15 \\
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \\
--kubernetes-version v1.17.3 \\
--service-cidr=10.96.0.0/16 \\
--pod-network-cidr=10.244.0.0/16
–apiserver-advertise-address=10.0.2.15 :这里的IP地址是master主机的地址,为上面的eth0网卡的地址;
运行命令之后,会有下面的提示, (Kubernetes control-plane)Kubernetes控制面板初始化成功:
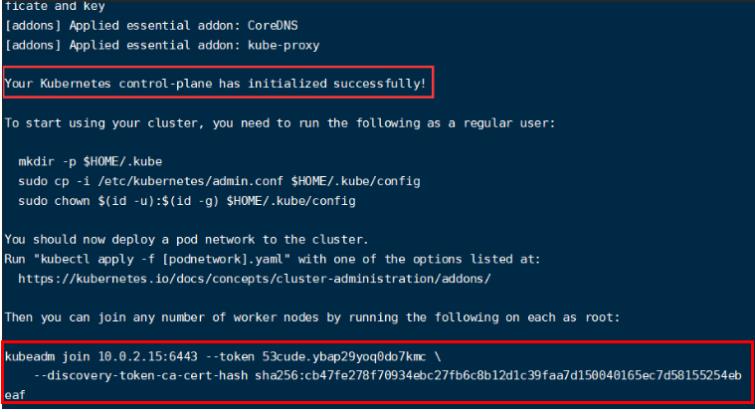
然后,按照提示创建一个用户:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
可以参考下面网址:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
- 在
node2/3中执行下面命令,为kubernetes添加节点:
kubeadm join 10.0.2.15:6443 --token mmm5wg.30nuvjon44z9a22h \\
--discovery-token-ca-cert-hash sha256:62e44803f6c1e30e86a9d2a1f58f3636aae09850cb5feb5d2c7fd949c5d7d5c4
kubeadm join 172.22.30.3:6443 --token ywh9li.cd9rwd6mhmqyxghr \\
--discovery-token-ca-cert-hash sha256:83e0d249a4760c59b13be6b8e08b4701267bf998d1361747be5be42dd59aa60b

我们需要按照下面的(3)首先部署一个网络,有网络之后其他人才能够进来构成网络,然后在两个slave节点(k8s-node2、k8s-node3)执行上述命令:
在k8s-node2节点显示:
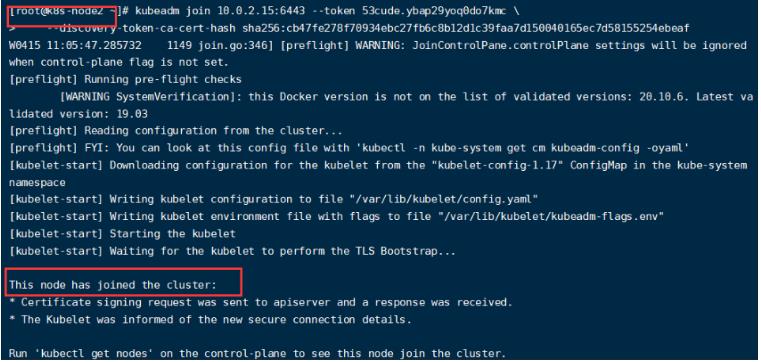
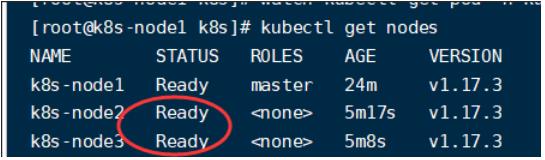
在master节点中使用下面命令查看节点加入状况:
#获取所有节点
kubectl get nodes
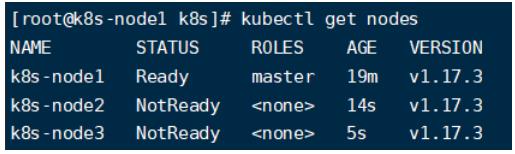
使用下面命令监控pods运行状态:
watch kubectl get pod -n kube-system -o wide
当flannel文件运行起来后,集群中加入的节点就会ready状态:
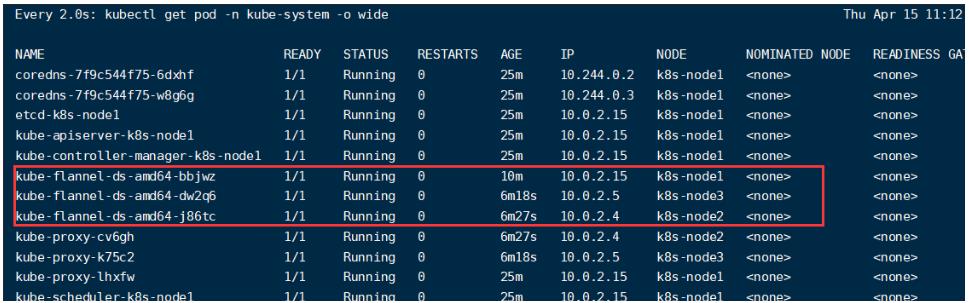
- 安装Pod网络插件(CNI)
# 部署一个应用
kubectl apply -f kube-flannel.yml
# 删除这个文件中指定的所有资源
kubectl delete -f kube-flannel.yml
该命令会为整个集群安装非常多的规则和组件。
通过下面指令查看pods:
# 查看指定名称空间的pods
kubectl get pods -n kube-system
# 查看指定所有名称空间的pods
kubectl get pods --all-namespaces
# 监控pod进度
watch kubectl get pod -n kube-system -o wide
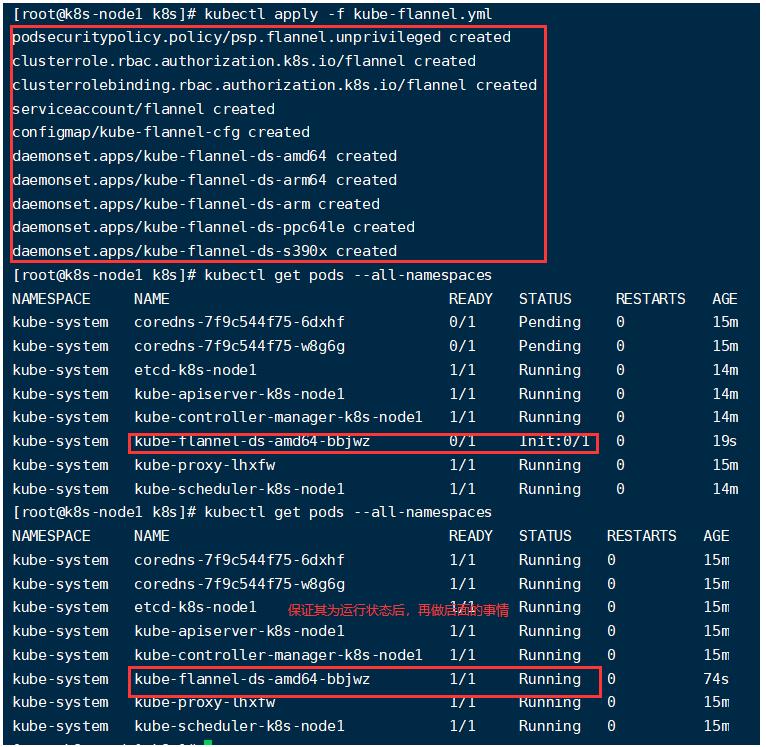
6、使用
①基本操作
- 操作
部署一个tomcat
# 创建一个部署
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8
# 可以获取到tomcat信息
kubectl get pods -o wide
容器创建中:

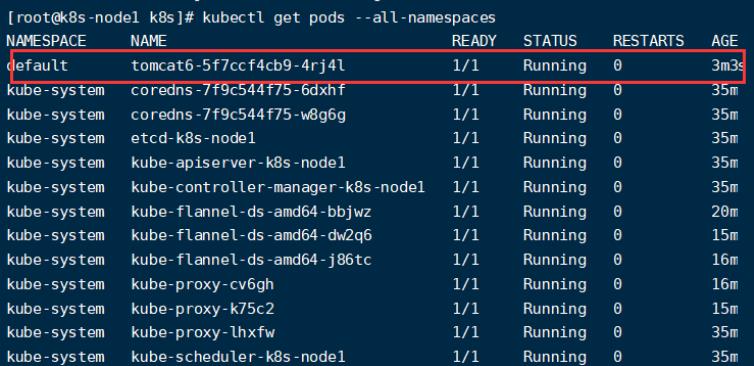
创建四个文件,在第一个文件中,可以看到tomcat创建在node2节点:
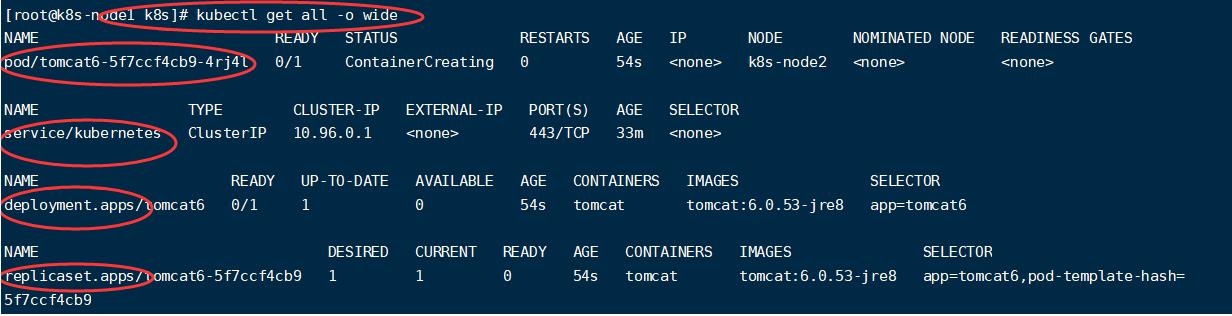
查看node2节点相关镜像,可以看到该节点下载和运行了tomcat镜像:
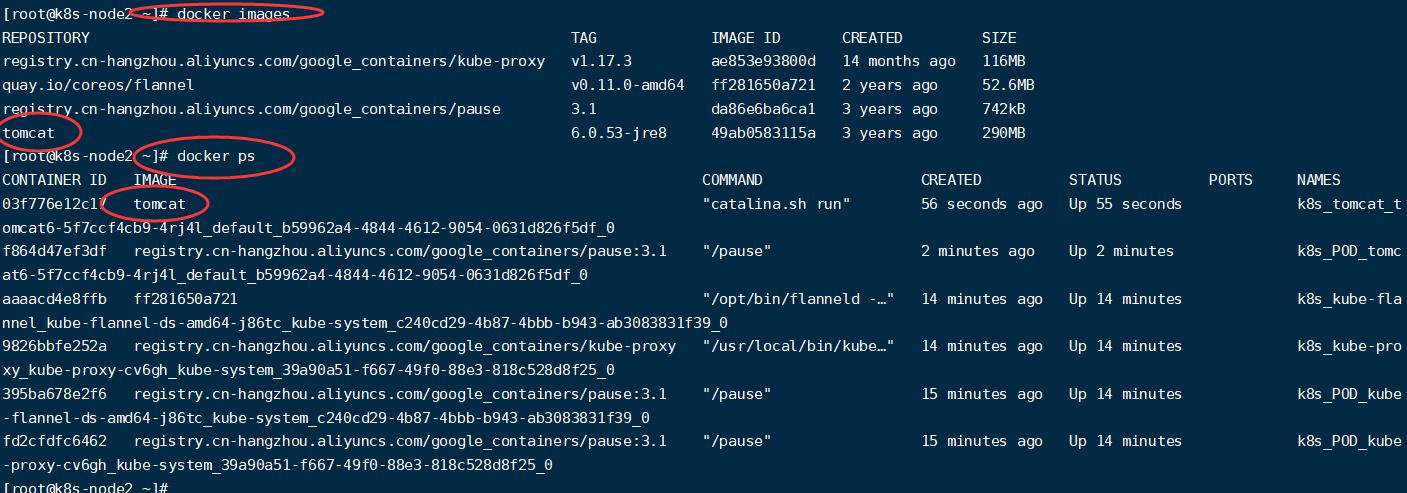
在默认命名空间中:
当我们模拟宕机情况,将node2关掉电源,master节点中需要过一点时间才能检测到容灾恢复
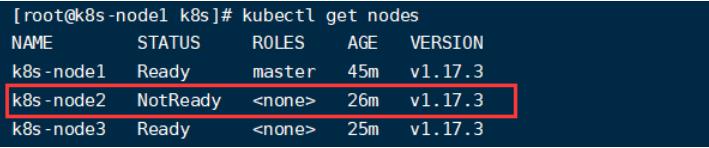
在我的电脑中,master节点中需要5分钟左右才能在node3中重新拉起一个tomcat:

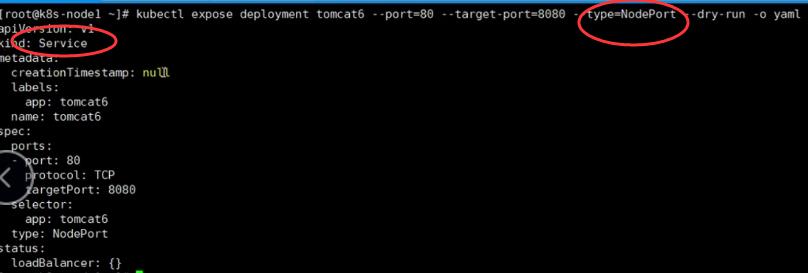
- 暴露tomcat访问
#Pod的80映射容器tomcat的8080;
#service会代理Pod的80
# 封装成的service模式为NodePort,随机分配一个端口进行暴露
# --port pod的端口
# --target-port pod里面的tomcat容器的端口
# --type指定以何种方式暴露端口
kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort
#执行完会自动随机一个端口对外暴露

使用外网访问:
http://192.168.56.100:32671/
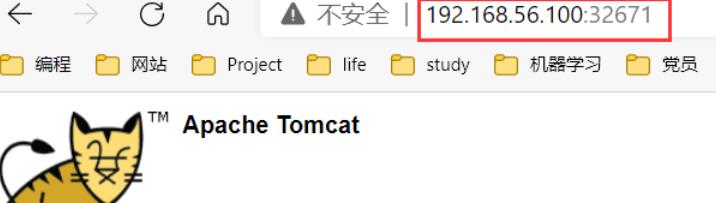
- 动态扩容副本数量的测试
kubectl get deployment
# 扩容-扩容了多份,所以无论访问哪个node的指定端口,都可以访问到tomcat6
# --replicas=扩容数
kubectl scale --replicas=3 deployment tomcat6
应用升级:kubectl set image(–help查看帮助)

- 删除
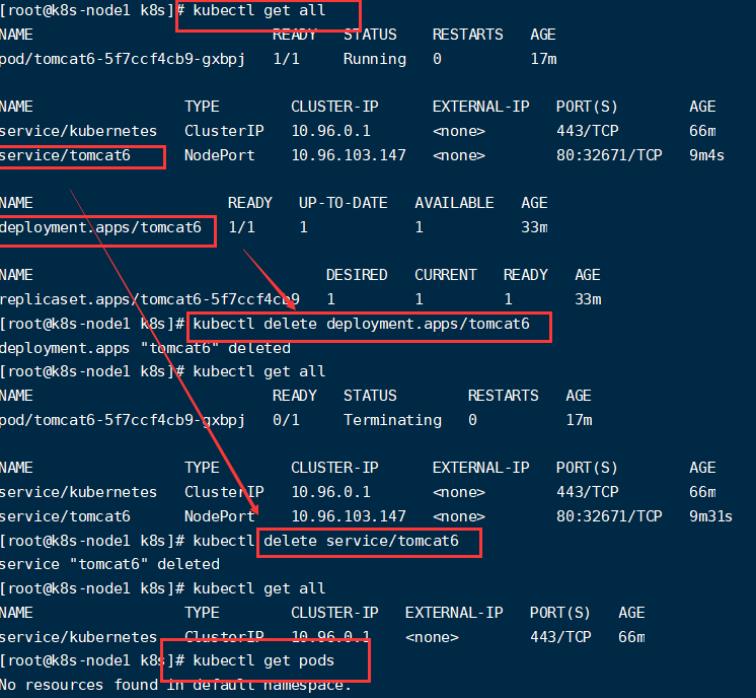
# 获取资源后进行删除
kubectl get all
kubectl delete deployment.apps/tomcat6
kubectl delete service/tomcat6
流程:创建deployment会管理replicas,replicas控制pod数量,有pod故障会自动拉起新的pod。
②yaml&基本使用
- 参考网址
# kubectl文档
https://kubernetes.io/zh/docs/reference/kubectl/overview/
# 资源类型
https://kubernetes.io/zh/docs/reference/kubectl/overview/#%e8%b5%84%e6%ba%90%e7%b1%bb%e5%9e%8b
# 格式化输出
https://kubernetes.io/zh/docs/reference/kubectl/overview/
- yaml模板
创建的部署和service都可以使用下面yaml格式进行操作:

查看某个pod的具体信息:
# --dry-run 测试运行并不真正执行;输出一点yaml
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 --dry-run -o yaml
输出结果:
[root@k8s-node1 k8s]# kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 --dry-run -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: tomcat6
name: tomcat6
spec:
replicas: 1
selector:
matchLabels:
app: tomcat6
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: tomcat6
spec:
containers:
- image: tomcat:6.0.53-jre8
name: tomcat
resources: {}
status: {}
暴露tomcat访问产生的yaml文件:
③pod、service理解
- 一次部署deployment就是一个controller

- service和deployment之间的关系
service是统一应用访问入口
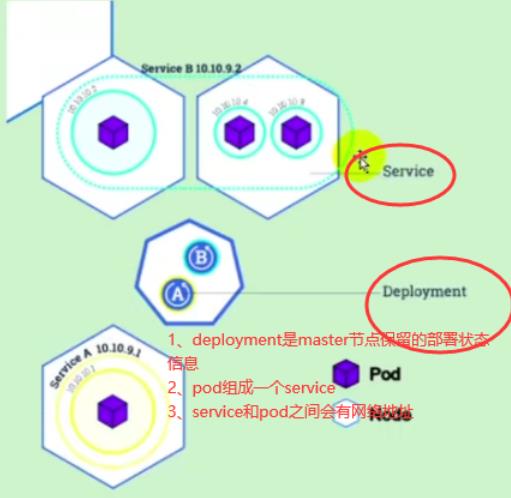
service之间能够相互访问,通过访问service,该请求可以转发给里面的pod节点。

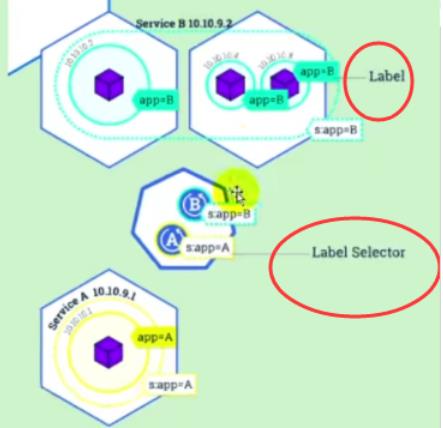
- labels 和 selectors之间关系:
- labels 类似给pod打上标签人然后用selectors去选择
- selectors类似jq的id选择器
④Ingress
- 介绍
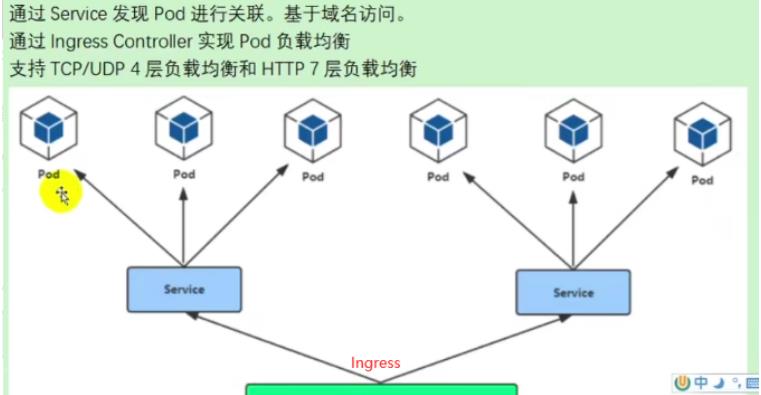
service以域名方式暴露,外部访问Ingress,通过service将请求转发给pod端口。
步骤:
1、部署Ingress controller
2、创建Ingress规则
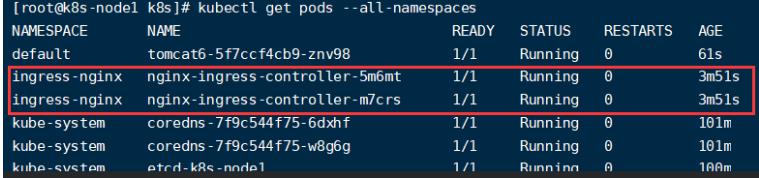
- 配置
执行“k8s/ingress-controller.yaml”
kubectl apply -f ingress-controller.yaml
需要等待Ingress启动完成:
- 配置规则
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web
spec:
rules:
- host: tomcat6.kubenetes.com # 使用的域名
http:
paths:
- backend:
serviceName: tomcat6 # 后台服务跟下面的service名对应
servicePort: 80
serviceName需要和下面对应:
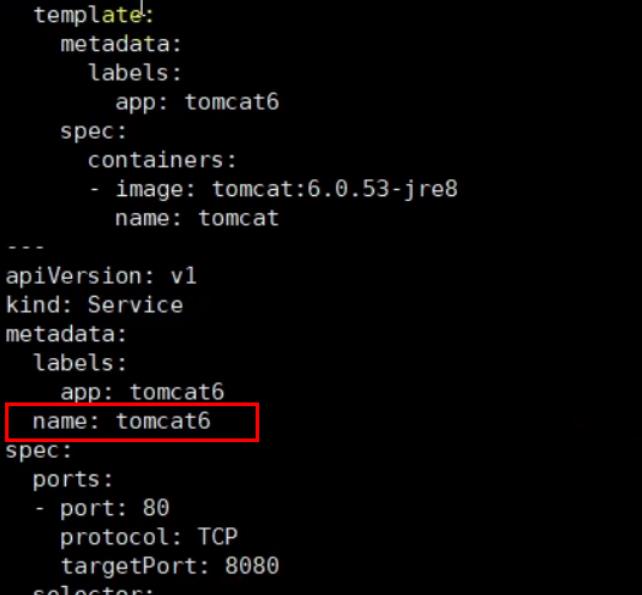
我们以后只需要访问域名tomcat6.kubenetes.com,就可以访问到后台的tomcat6服务了。
# 将上面规则添加进ingress-tomcat6.yaml文件中
touch ingress-tomcat6.yaml
# 启动配置文件
kubectl apply -f ingress-tomcat6.yaml
- 配置域名映射
192.168.56.102 tomcat6.kubenetes.com
- 测试
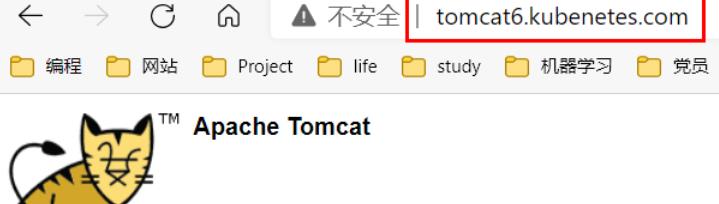
三、kubesphere
1、前置环境
- 安装默认的DhashBoard

# k8s文件下有
kubectl appy -f kubernetes-dashboard.yaml
添加权限
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 3001
selector:
k8s-app: kubernetes-dashboard
访问地址:
http://NodeIP:30001
创建授权账号
kubectl create serviceaccount dashboar-admin -n kube-sysem
kubectl create clusterrolebinding dashboar-admin --clusterrole=cluter-admin --serviceaccount=kube-system:dashboard-admin
kubectl create clusterrolebinding dashboar-admin --clusterrole=cluter-admin --serviceaccount=kube-system:dashboard-admin
使用输出的token登录dashboard:
- 介绍
在这里安装的时候,大约花费了一天时间,主要原因是外网无法访问导致,有些脚本命令无法执行。
具体参考网址有两个,将两个文件结合起来一起看比较好比较好:
https://blog.csdn.net/hancoder/article/details/107612802
https://www.cnblogs.com/wwjj4811/p/14117876.html
概述

安装参考网址:
# v3.0.0版本
https://kubesphere.com.cn/docs/quick-start/minimal-kubesphere-on-k8s/
# v2.1版本参考网址
https://v2-1.docs.kubesphere.io/docs/zh-CN/installation/prerequisites/
- 安装heml

安装给定的get_helm.sh
curl -L https://git.io/get_helm.sh | bash
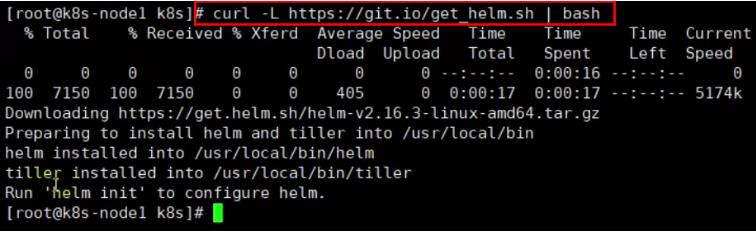
但是,上面的命令由于翻墙的原因一般都无法执行,推荐使用下面博客的方式在匹配好版本的情况下,进行离线安装:
https://blog.csdn.net/qq_30019911/article/details/113747673
获取安装包
https://get.helm.sh/helm-v2.16.3-linux-amd64.tar.gz
将解压后的文件linux-amd64/helm、linux-amd64/tiller文件放到/usr/local/bin/目录中
验证版本
helm version
# Client和Server版本要一致,Tiller初始化完成后会显示这个
Client: &version.Version{SemVer:"v2.16.3", GitCommit:"xx", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.16.3", GitCommit:"xx", GitTreeState:"clean"}

创建权限(master执行)
创建helm-rbac.yaml文件,将下面配置添加进里面:授权工作
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
启用配置
kubectl apply -f helm-rbac.yaml
- 安装Tiller(master执行)
初始化
# --tiller-image指定镜像,否则会被墙
# 等待节点上部署的tiller完成即可
helm init --service-account以上是关于Day442&443.K8s -谷粒商城的主要内容,如果未能解决你的问题,请参考以下文章