AI 芯片:商业项目 GPU 怎么选?
Posted Debroon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI 芯片:商业项目 GPU 怎么选?相关的知识,希望对你有一定的参考价值。
通用芯片
CPU
CPU是由十几亿的晶体管以分层的思想,制造出来的。
TA的模型是由信息论鼻祖 22岁的香农在硕士毕业时发表的一篇论文 , 名为《开关网络》,就俩种状态,开 or 关。
在这篇论文里,TA解释了一切的逻辑运算如何用开、关实现。
所以,晶体管您可以直观理解为开关,而十几亿开关组成的 CPU,也可以直观理解成 开关网络。
一个晶体管:
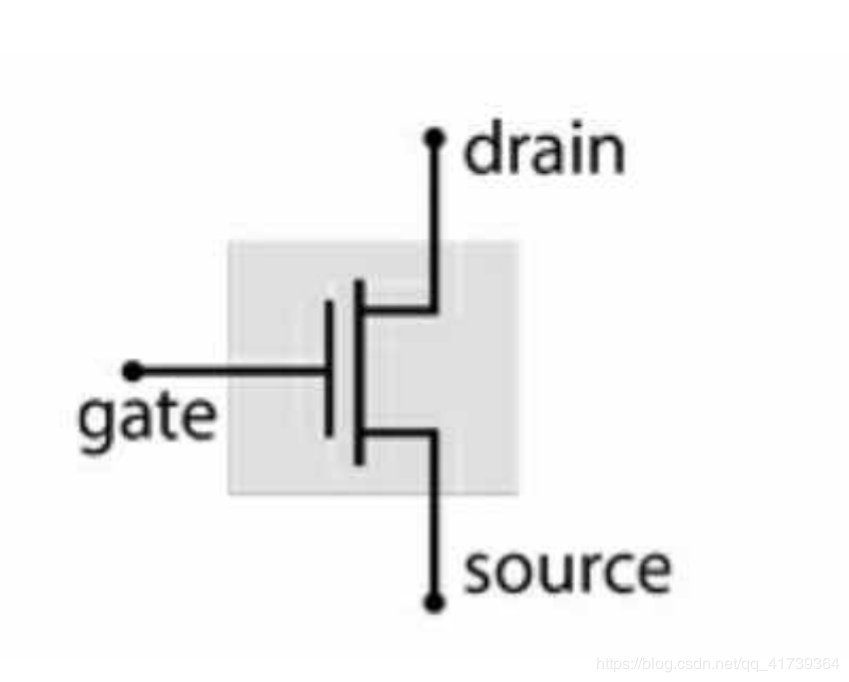
普通晶体管 有 3 极,gate : 栅极 source : 源极 drain : 漏极
- 栅极 电压高时,源极和漏极会连通,等同 开关打开
- 栅极 电压低时,源极和漏极会断开,等同 开关关闭
一个互补晶体管:
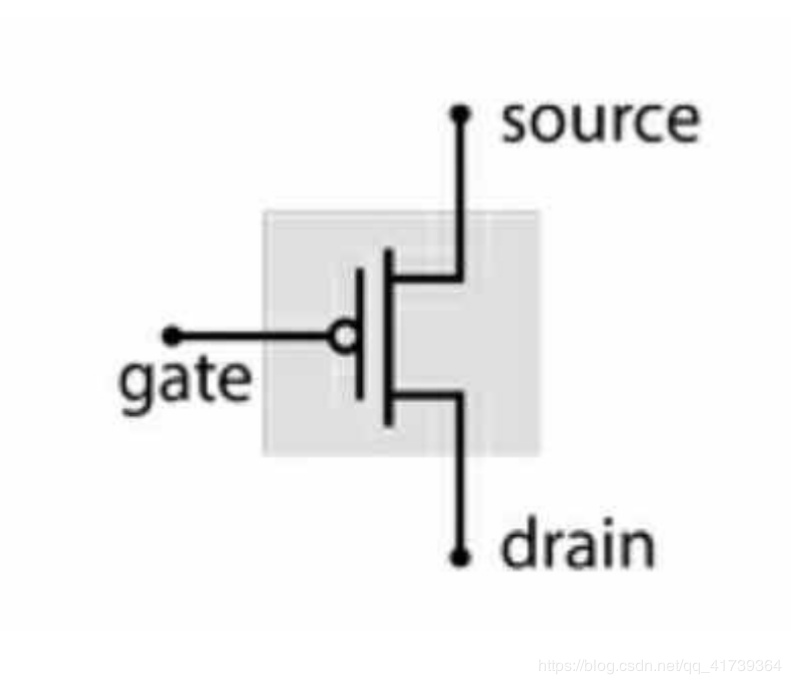
互补晶体管 ,结构和功能与晶体管几乎一致,功能相反
- 栅极 电压高时,源极和漏极会断开,等同 开关关闭
- 栅极 电压低时,源极和漏极会连通,等同 开关打开
一个晶体管和一个互补晶体管连接起来,就可以实现一个 “逻辑门”。
一个非门:
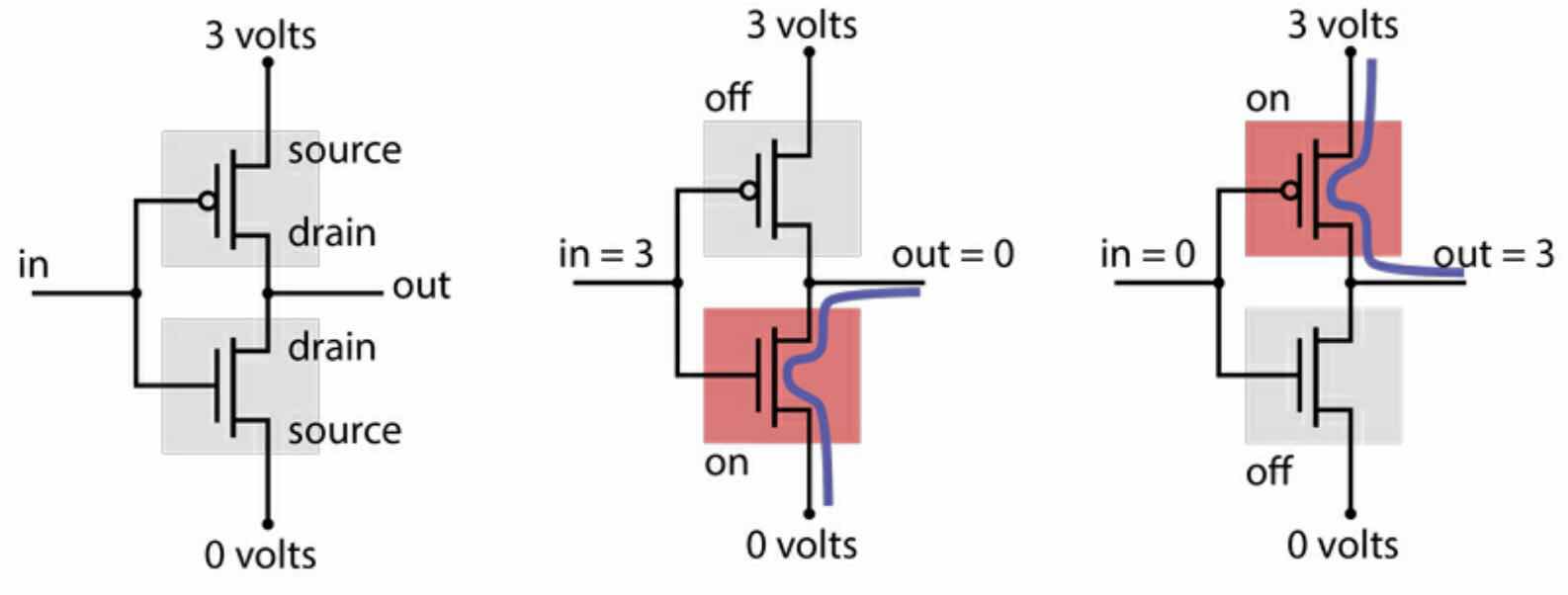
非门的功能:
- 输入 0 ,输出 1
- 输入 1,输出 0
用高电压代表 1,低电压代表 0。
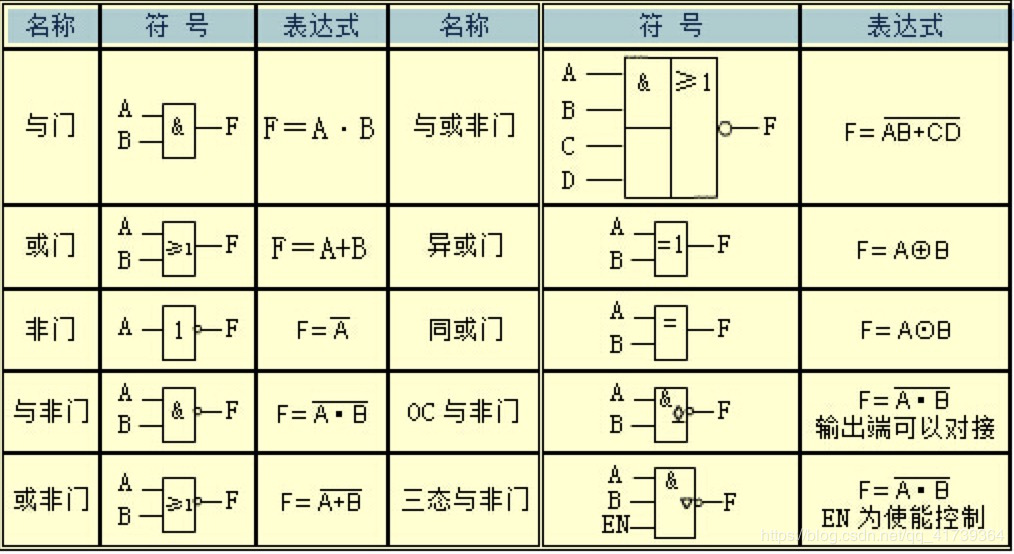
类似地,还有“或门”、“与非门”、“异或门”等等。
而后,我们再把晶体管、逻辑门组合成运算器:
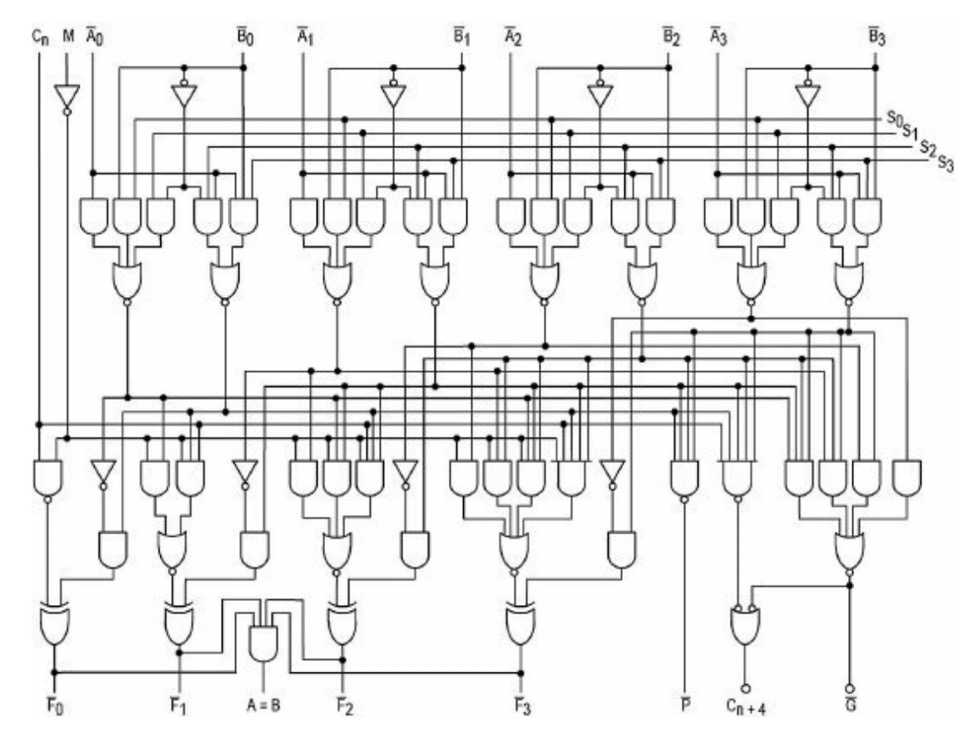
输入 A 和 B 两个二进制的 4位数,能判断 A 和 B 是否相等,还能计算 A+B 和 A-B。
运算器是计算机 CPU 的一部分,CPU 中还有 “数字同步逻辑”之类的组件,但是不管 CPU 有多复杂多高级,也是用各种逻辑门组成的,而逻辑门是用开关做的。
所以整个 CPU 就是一个开关网络!
开关的功能是如此的简单。
只能根据两种命令完成两个动作,虽然是纯机械化地事,没有任何智能;但是亿万个这样的开关组成在一起,就是 CPU,就能运行软件,就能实现人工智能。
CPU 的设计思想,是分层,分层使简单的东西解决复杂的问题,只要系统足够复杂,就值得这么做。
专用芯片
我们说的AI芯片,其实全称叫“人工智能加速芯片”,它是一种专门芯片,作用就是来加速AI算法的。
传统的 CPU 芯片是一种通用芯片,要干的事情很多,除了用来计算,还要做很多功能,比如说要调取数据,要控制操作,要分析指令等等。
在一个CPU上,能用来计算的,就其实只有一小部分。
- 相当于说,河面上有一艘船,但是船上坐着的人不都是划船的,还有一些其他人,有指挥的,有厨子,有负责看天气的等等。一艘船上10个座位,划桨的人可能只能坐下3-4个,剩下的位置都被“闲杂人等”占了。
但是GPU就不一样了。
- GPU是“专用芯片”,它有专门的功能,处理图像数据。这就相当于,同样是一艘船,GPU这艘船上大部分的位置都给了划桨的人,闲杂人等不让上船,10个座位上的人,可能八九个都在划船,船当然划得快。
GPU芯片性能的提升,主要还是通过优化硬件以及优化算法做到的。
硬件优化是什么呢?
比如说你可以优化船体本身的设计,既然这个船只有一个任务,就是划得快,那不如按照赛艇的模型去设计,还有船的里面,座位怎么排布,甚至用什么样的桨来划,也都可以优化。
对应到芯片设计领域,专业的术语就是,电路设计可以优化。
另一种方式,就是重新设计划船的技术,提升船上每个人划船的效率或者说提升整个团队的效率。
比方说,在软件的层面,你可以使用更好、更高效的算法去发挥芯片的效率。
GPU
CPU 的计算速度之所以不够快,是因为被设计成能够适应所有的计算了,很大晶体管都用搭建控制电路。
而在计算机里,有一种计算相对单一 — 控制显示器的图形计算。
于是,英伟达专门设计了图像型处理器 GPU,原来只有一些游戏发烧友才会追求高性能的 GPU,那是为了更好的游戏效果。
-
电路设计:控制电路单一了,更多晶体管用于计算,这样就可以建立多核,核心越多性能更好,目前一个 GPU 可能有 3000 个内核。
-
算法设计:单次计算变成了向量的批量化计算,很多重复一致的计算就可以并行,如图像识别领域常用的卷积神经网络算法,主要的一个运算就是针对很大的矩阵进行大量的乘法操作,如果能针对这个特点来处理,自然就能提高计算速度。
现在人工智能加速芯片的实现方案,就是GPU、FPGA和ASIC这三种了。在不同的应用场景下,会选用不同的方案。
FPGA
FPGA,可编程逻辑阵列。
作为音响发烧友,经常在顶级音源、放大设备中见到FPGA形式的音频芯片,处理音频信号解码、升频、滤波、放大等运算,当时一直不理解FPGA的本质以及厂家为什么这么设计。
厂家是为实现专门的音频处理定制了芯片,且根据自己的调音需求,特地烧录出满足自己调音偏好的FPGA。
FPGA 是一颗通用专一芯片,但做好以后,你可以根据需要,修改芯片里的连接形式,构成各种各样不同功能的芯片。
你可以把FPGA当作是送外卖。虽然送外卖是一项通用的服务,谁都可以用,但是你一旦下了的订单,这个送外卖小哥,他就只服务于你了。他会在你和你的目标之间建立一条最优的路径,最快速度把东西送到。服务结束之后他才会接下一单,又针对新的用户建立新的路线。
外卖下单就对应着FPGA的编程烧录,烧录好了之后,这块FPGA就成了你的专用芯片,针对你的具体问题高效解决。完成任务之后,你还可以根据新的问题来改变电路结构,变成另一颗专用芯片,高效地完成新任务。
ASIC
现在芯片技术最热门的叫,ASIC 定制化芯片,定制化就是专门设计一颗芯片,不做其他事·。
毕竟机器学习的向量计算,和通用的向量计算稍稍有点不同,能否让计算的内核功能再专一点,只做特定的机器学习算法。
于是,Google 提出了张量计算的概念,并设计了一种仅仅针对特定张量计算的处理器 TPU。
所谓张量,原本是一个数学概念,如俩张照片是俩个不同的向量,它们之间的相似性计算一个张量。
俩个最重要的张量计算:
- 矩阵乘法
- 卷积
TPU 设计的目的,就是快速计算矩阵乘法。
TPU、GPU 谁更好,完全要看做什么事情,不同的项目适合不同的处理器。
商业项目的芯片怎么选?
现在人工智能的商业项目,必定离不开 CPU,那应该买什么样的 CPU 呢?
最简单的方法,是办一个 visa 的信用卡,就可以免费使用谷歌的云服务器。
具体来说,不同的深度学习架构,选择 GPU 参数优先级也不同:
-
卷积网络和变换器 (Transformer):张量核心 > FLOPs (每秒浮点运算次数) > 显存带宽 > 16 位浮点计算能力
-
循环神经网络:显存带宽 > 16 位浮点计算能力 > 张量核心 > FLOPs (每秒浮点运算次数)
针对不同的研究、预算看:
- 最佳 GPU:RTX 2070
- 高性价比:RTX 2070、RTX 2060、RTX 1060
- 学生党:RTX 1060
- 最便宜:RTX 1050 Ti、CPU + AWS/TPU、Colab(visa支付一点点钱还可以用Google训练好的模型)
- Kaggle:RTX 2070
- 计算机视觉、机器翻译:采用鼓风设计的 GTX 2080 Ti,如果训练网络非常大,用 RTX TItans
- 自然语言处理:RTX 2080 Ti
以上是关于AI 芯片:商业项目 GPU 怎么选?的主要内容,如果未能解决你的问题,请参考以下文章