MySQL<4>
Posted 一朵花花
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL<4>相关的知识,希望对你有一定的参考价值。
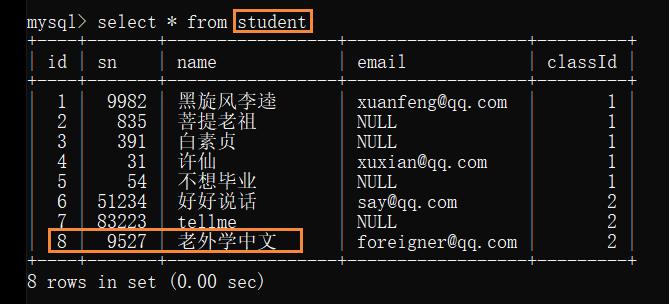
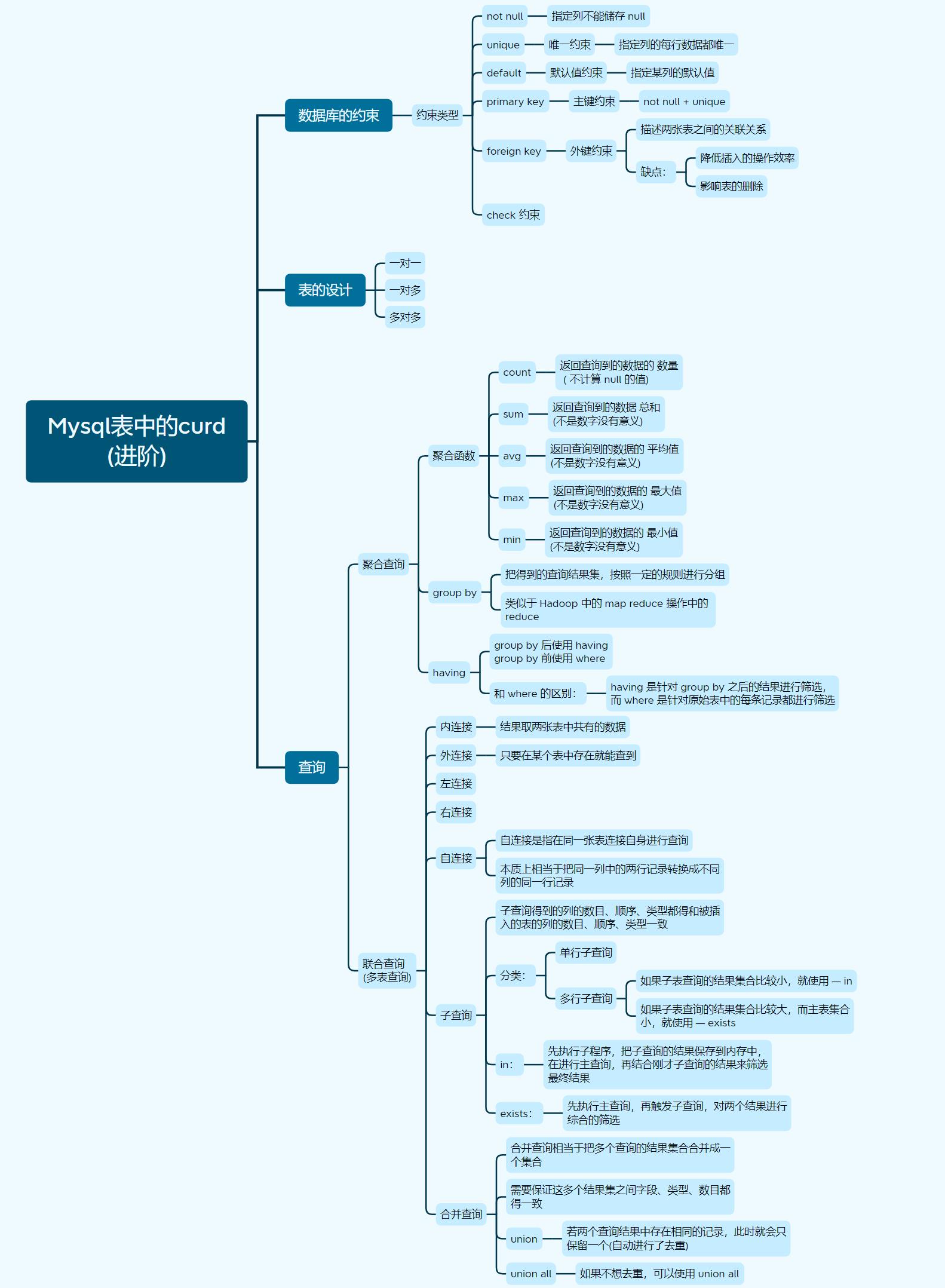
mysql表中的CRUD <进阶>
数据库的约束
约束: 数据库针对数据进行一系列的校验,如果发现插入的数据不符合约束中描述的校验规则,就会插入失败,为了更好的保证数据的正确性
约束类型
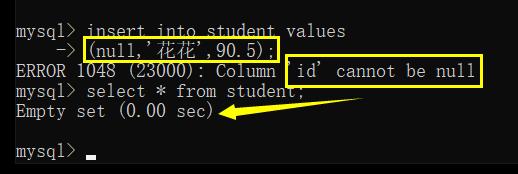
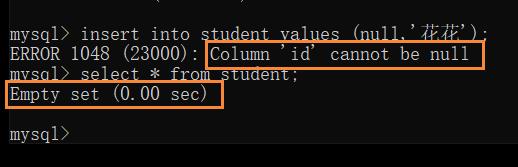
Not null — 指示某列不能存储 null 值
创建表时,可以指定某列不为空
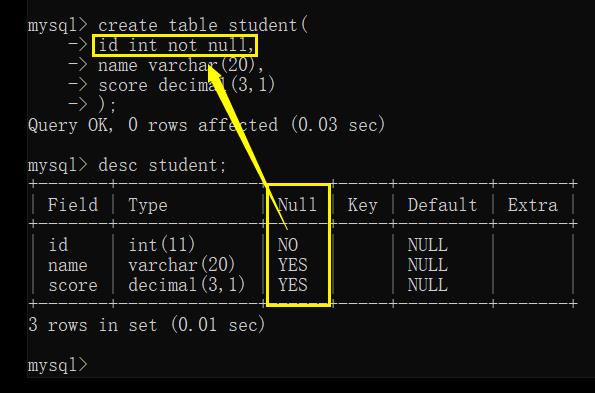
not null 约束后,再来插入 null 时,就会报错
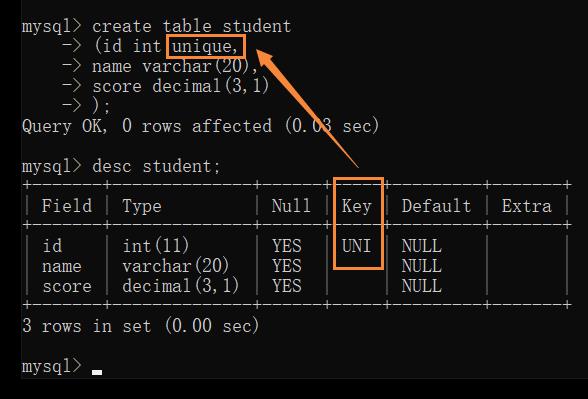
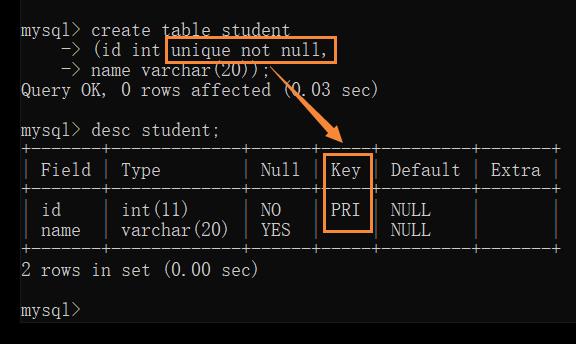
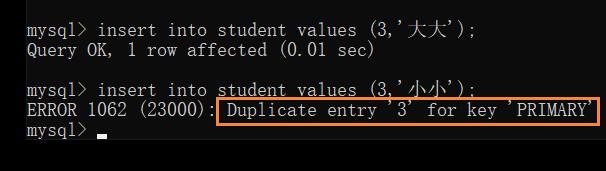
Unique — 唯一约束
保证某列的每行必须有唯一的值
此时插入重复数据时,也会报错
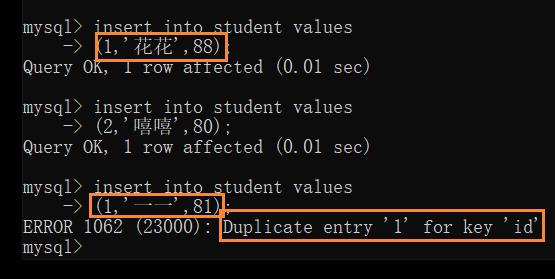
如果把 unique 和 not null 放在一起叠加,就相当于主键 primaryKey 的效果
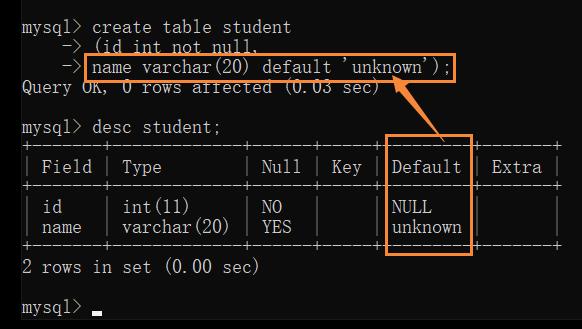
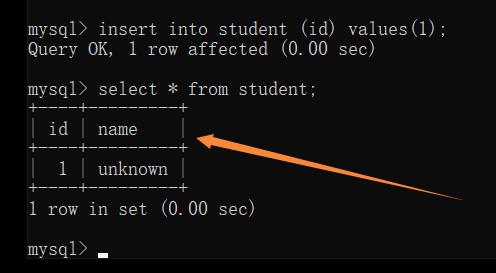
Default — 默认值约束
规定没有给列赋值时的默认值
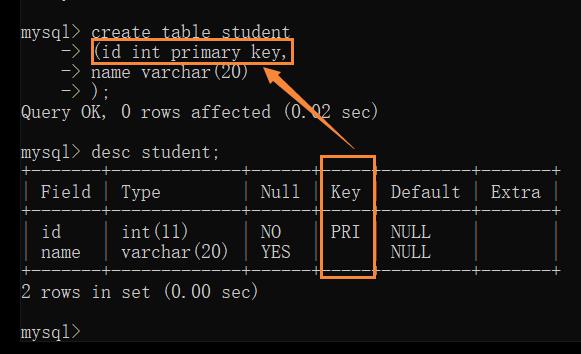
Primary Key — 主键约束 🔺
Primary Key = not null + unique
not null 和 unique 的结合,确保某列 (或两个列多个列的结合) 有唯一标识,有助于更容易更快速地找到表中的一个特定的记录
not null:
unique:
一般建议创建一张表的时候,最好都给这个表指定一个主键
如何保证主键不重复?
人工保证不太靠谱,可以借助数据库自动来生成 (数据库自带了一个 auto_increment 选项)
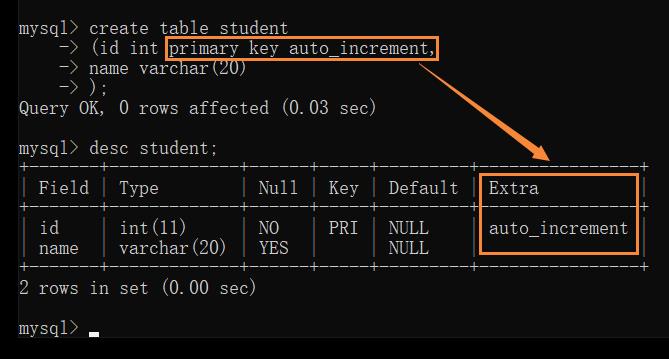
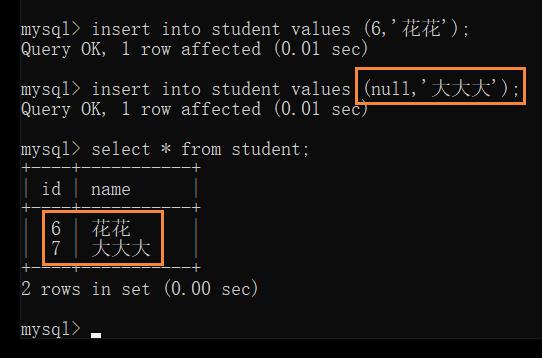
自增的特点: 如果表中没有任何记录,那么自增从 1 开始;如果表中已有记录,那么自增从上一条记录往下自增
若为 int 类型的自增主键,有效范围就是 -21亿 ~ +21亿,如果数据超出范围,再继续自增,就会出现溢出的情况
若把中间的数据删了,再次插入数据,刚才删掉的自增的主键的值不会被重复利用
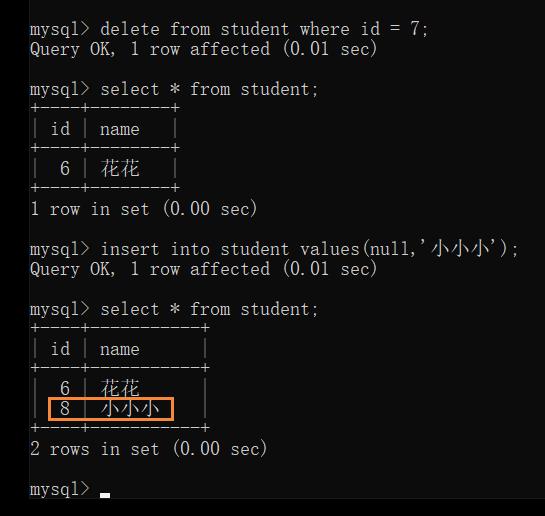
Foreign Key — 外键约束 🔺
描述两张表之间的关联关系
保证一个表中的数据匹配另一个表中的值的参照完整性
使用外键,会对插入操作的效率产生一定影响
外键操作也会影响表的删除
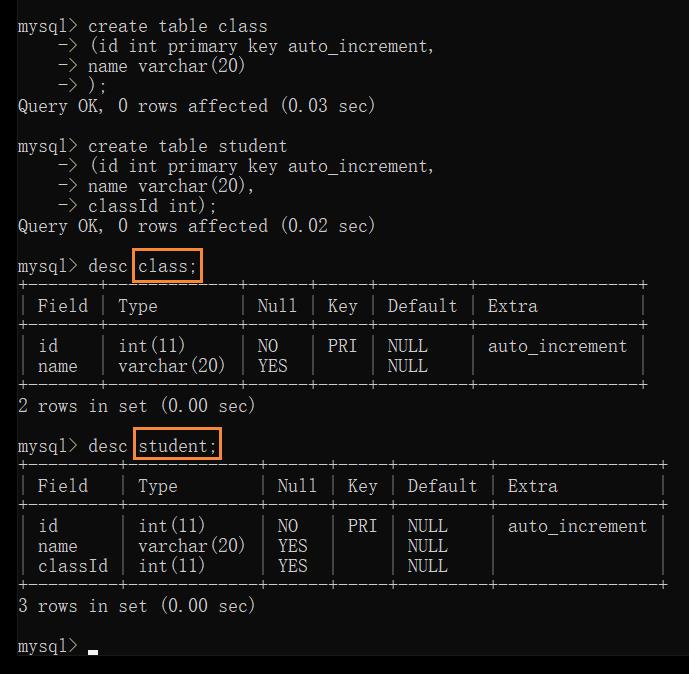
创建两张表:
插入数据:
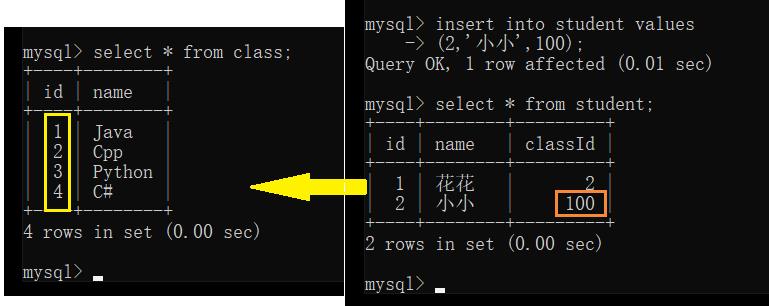
此处,student 表中的 classId 字段的值不合理,100 不在 class 表中,但插入操作仍然成功,按理说应该出现在 class 表中才正确
为了让此处数据校验更合格,就可以使用外键
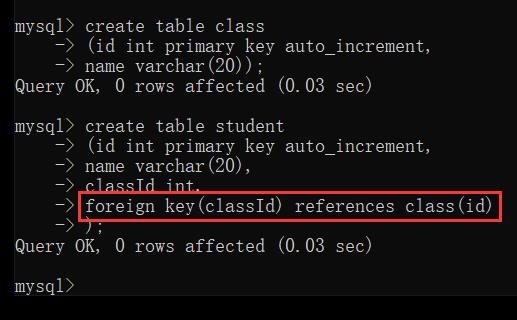
后续往 student 中插入数据,MySQL 就会自动检查当前的 class 字段的值是否在 class 表的 id 列出现过,如果没有出现过,就会插入失败
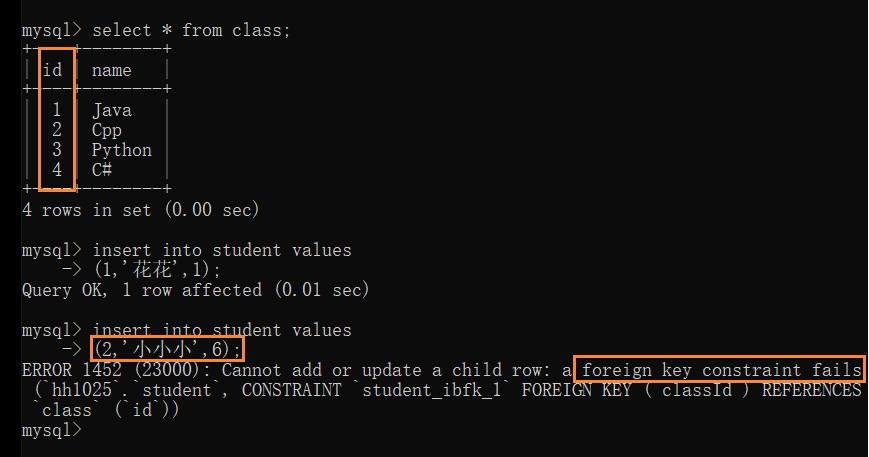
class 表被其他表关联着,此时是无法直接删除 class 表的

需要指定三方面信息:
1.指定当前表中哪一列进行关联
2.指定和哪张表关联
3.指定和目标表中的哪一列关联
Check 约束
保证列中的值符合指定的条件,对于 MySQL 数据库,对 check 子句进行分析,但是忽略 check 子句
表的设计
聚焦于设计表时实体间的关系
一对一
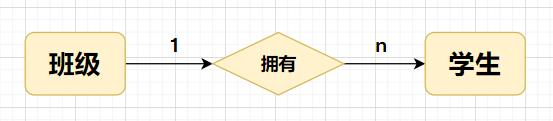
一对多
组织形式: 例如上边的例子:class表(id,name);student表(id,name,classId)
这个 student 表中可能会存在很多条记录,这很多条记录中,其中的 classId 可能都是相同的
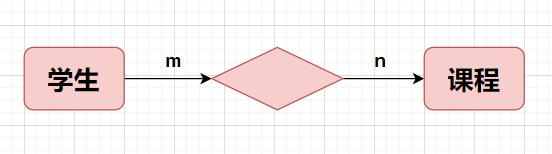
多对多
例如: 当前有很多学生,甲乙丙丁…当前又有很多课程,语文,数学,英语,物理,化学…
任意一个学生都有可能选择多门课程
任意一门课程都有可能会被多个学生选择
举例:
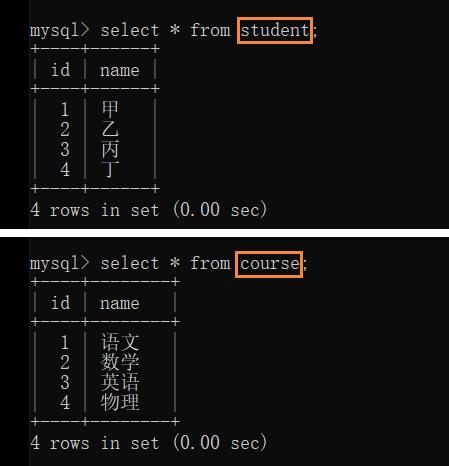
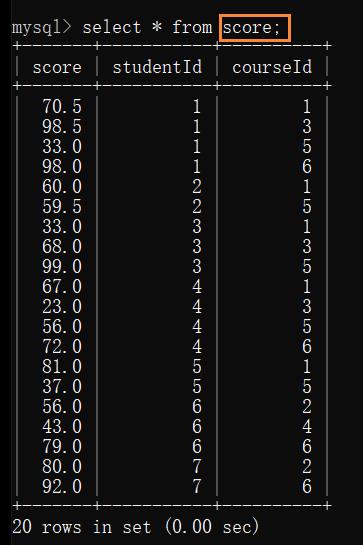
为了描述每个学生每门科目考了多少分,需要创建一个中间表来描述
如:甲 的语文考了 90分
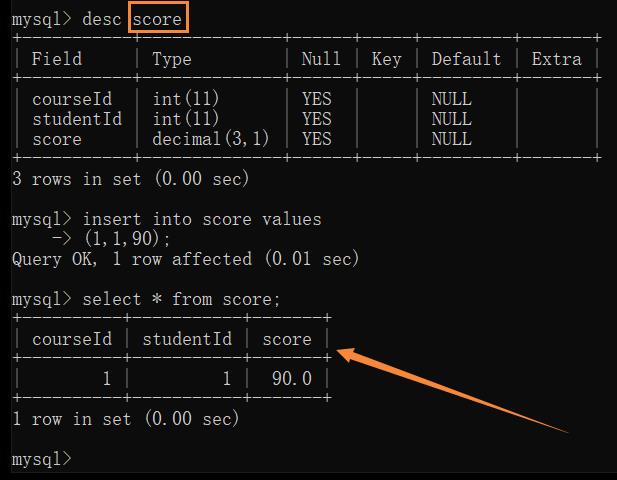
由于是多对多的关系,会看到 courseId 存在很多重复的(因为很多同学可能选修了这门课)
很多 studentId 存在很多重复的 (因为一个同学可能选修了多门课)
查询
聚合查询
可以借助 MyAQL 中内置的函数,帮我们完成一些更加复杂的运算
聚合函数
| 函数 | 说明 |
|---|---|
| count ( [distinct] expr ) | 返回查询到的数据的 数量 ( 不计算 null 的值) |
| sum ( [distinct] expr ) | 返回查询到的数据的 总和,不是数字没有意义 |
| avg ( [distinct] expr ) | 返回查询到的数据的 平均值,不是数字没有意义 |
| max ( [distinct] expr ) | 返回查询到的数据的 最大值,不是数字没有意义 |
| min ( [distinct] expr ) | 返回查询到的数据的 最小值,不是数字没有意义 |
count:
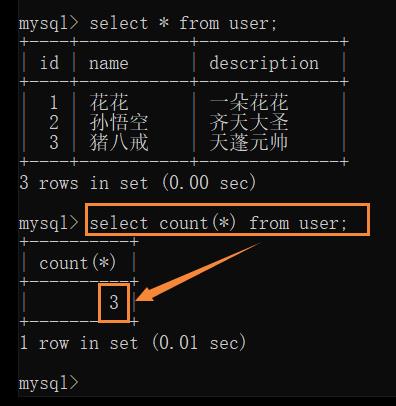
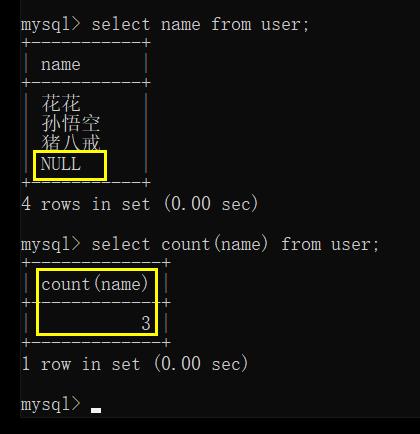
select count(*) from user; 相当于计算 select * from user 的结果行数
(开销更大)
select count(name) from user; 相当于计算 select name from user 的结果行数
select count(id) from user; 相当于计算 select id from user 的结果行数
sum, avg, max, min:
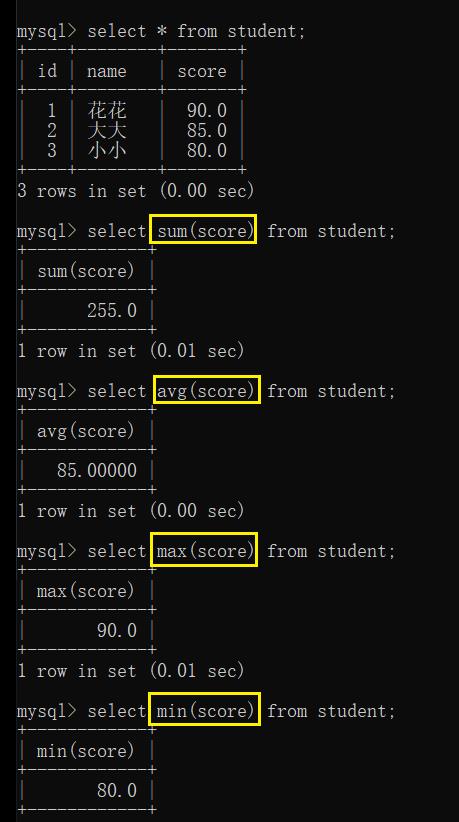
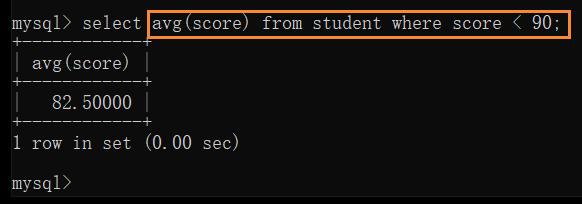
也可搭配条件来完成:
例: 成绩 < 90 的同学的平均分
group by 子句
把得到的查询结果集,按照一定的规则分组(可能分成多个组)
类似于 hadoop 中 map reduce 操作中的 reduce
创建表:
例: 查询每个岗位对应的最高工资,最低工资,平均工资
- 按 role 进行分组:
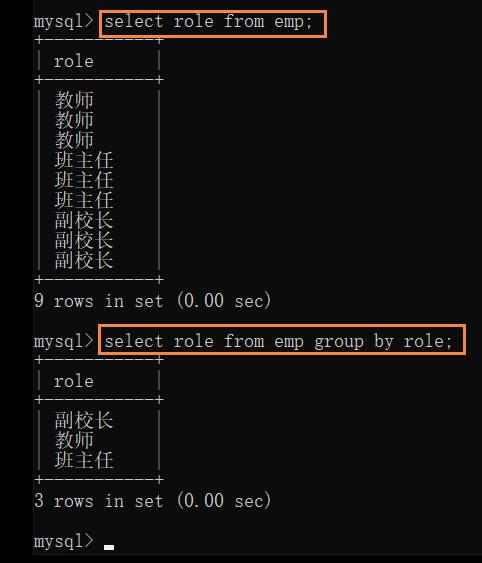
上述这个操作,不是单单的进行了去重,而是把查询结果中,role 相同的放到了一起
(角色相同的记录会被分配到同一个组中)
- 根据聚合函数查询即可
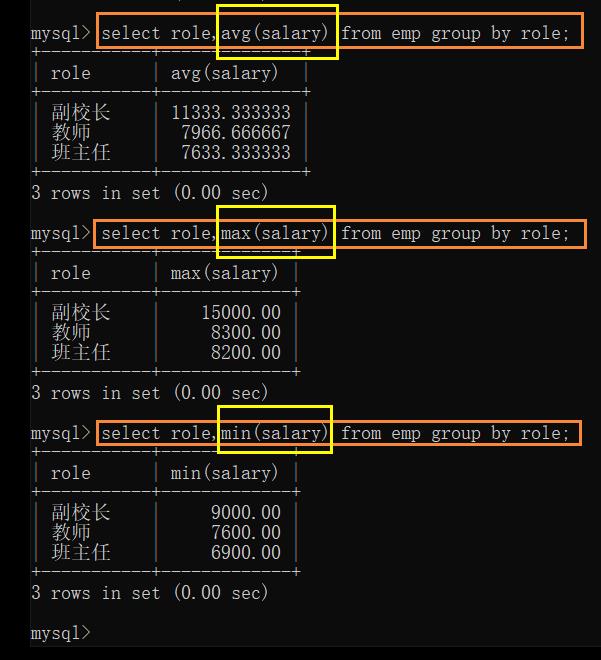
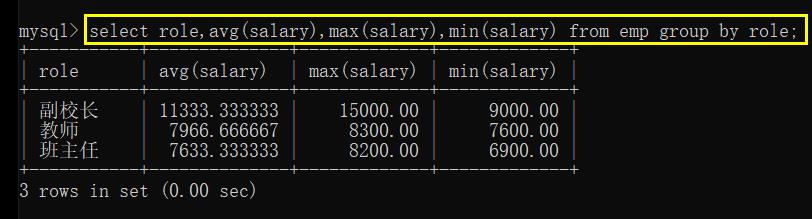
也可以一起查询:
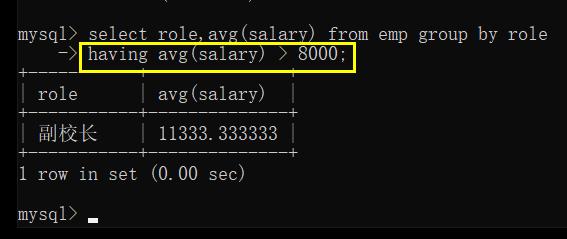
having
group by 中也可以结合一些条件来对数据进行进一步的筛选,不是使用 where,而是 having
having 是针对 group by 之后的结果进行筛选,而 where 是针对原始表中的每条记录都进行筛选
例: 查找出所有平均工资高于8000的岗位和平均薪资
注意事项:
- 分组前条件过滤使用 where,分组后条件过滤使用 having
- 分组操作中,查询字段中循序的是分组字段,聚合函数,其他非分组字段需要保证分组后没有多行
联合查询 / 多表查询 (难点) 🔺🔺
实际开发中往往数据来自不同的表,所以需要多表联合查询
多表查询是对多张表的数据取笛卡尔积
多表查询的过程:先计算多个表的笛卡尔积,在基于一些条件针对笛卡尔积中的记录进行筛选
实际联合查询的基本机制:笛卡尔积
若针对两个比较大的表进行联合查询,笛卡尔积的计算开销会很大,最终的查找效率也就较低
(故:不应该在生产环境上对大表进行联合查询)
笛卡尔积的本质就是在:排列组合
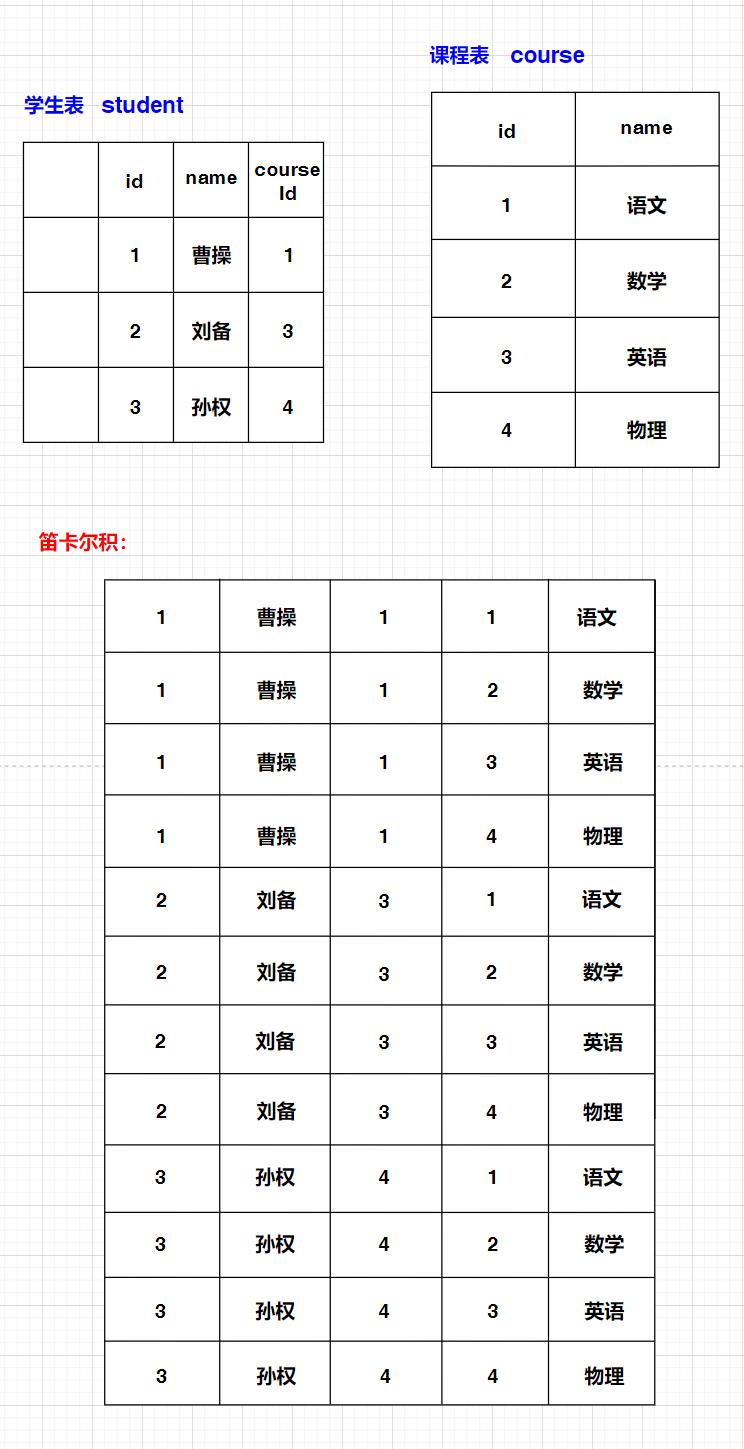
创建表:
内连接 inner join
结果取两张表中共有的数据
同时在 student 和 score 表中出现的数据才能查到
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
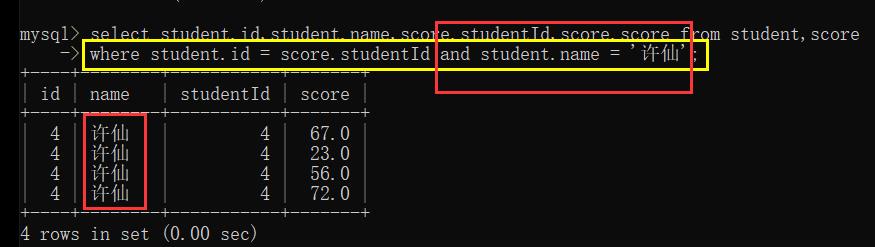
例1: 查询 “许仙” 同学的 成绩
分析: 姓名,包含在 student 表中,分数包含在 score 表中,那么就要针对这两个表进行联合查询
直观解决思路:
- 先找到名为许仙的 id
- 拿着 id 去 score 表中查询
.实际的解决思路:
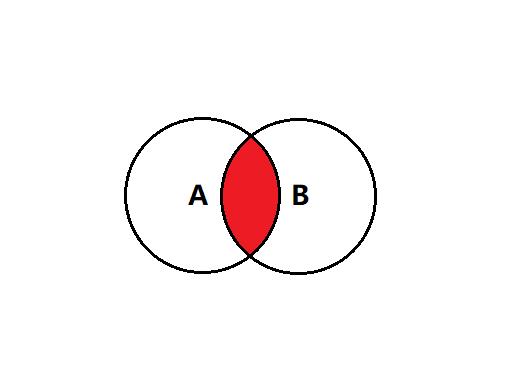
- 先把两张表联合在一起,得到笛卡尔积
- 按照 studentId 对笛卡尔积的记录进行筛选,保留有意义的数据
- 在针对名字进行筛选
先看看两个表的笛卡尔积的结果,直接借助 SQL 语句就行
多表查询时,写列的时候:表名.列名
where 中没有添加任何条件,得到的结果就是两表的笛卡尔积
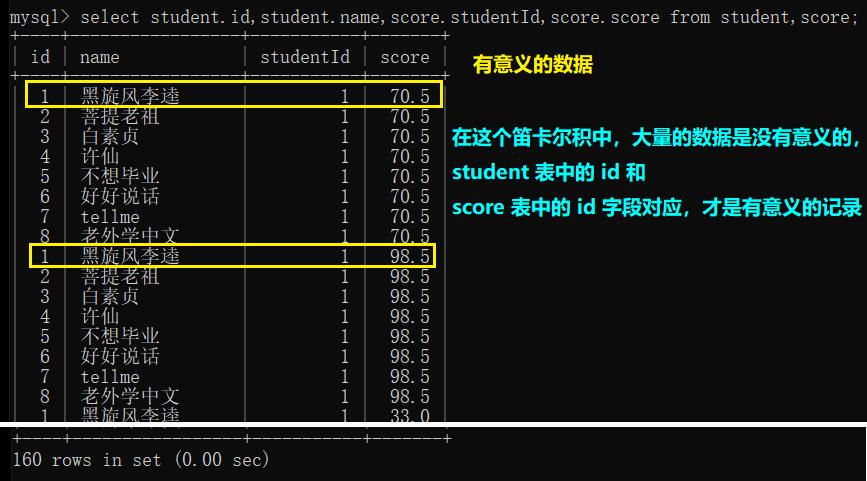
加上 where 语句之后:
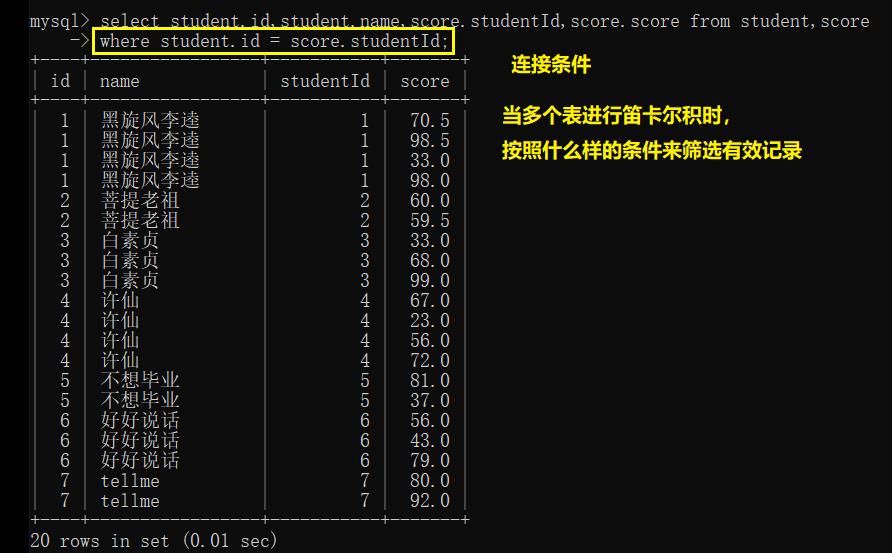
为了查找名为 “许仙” 的成绩信息,就在刚才的 where 基础上,再加一个条件来去筛选姓名:
使用 join on 写法:
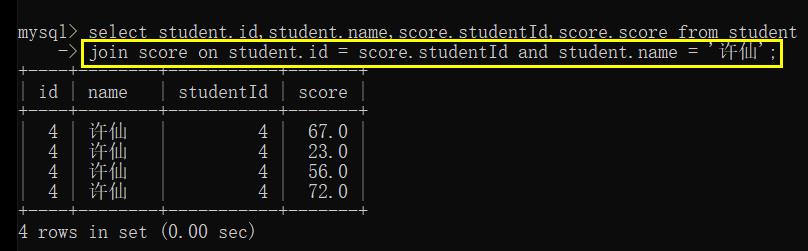
例2: 查询所有同学的总成绩 以及该同学的基本信息
分析: 同学信息在 student 表中,成绩在 score 表中,仍需对两表联合
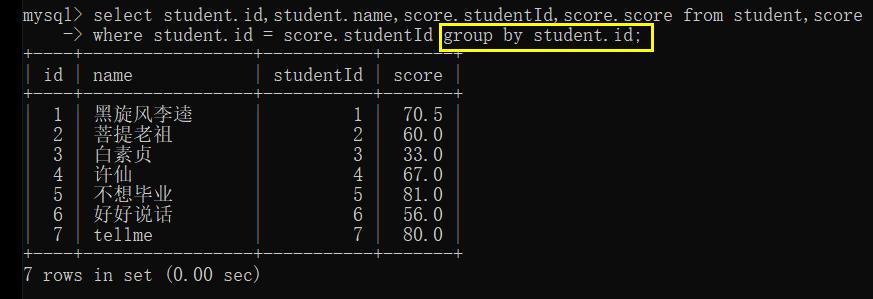
筛选条件:
- 按照 studentId 来筛选,干掉笛卡尔积中的不必要数据
- 按照 studentId 进行 group by,求每个同学的总成绩
- where 中没有添加任何条件,得到的结果就是两表的笛卡尔积
- 加上 where 语句之后,根据 student.id 筛选
- 按照 student.id 进行 group by
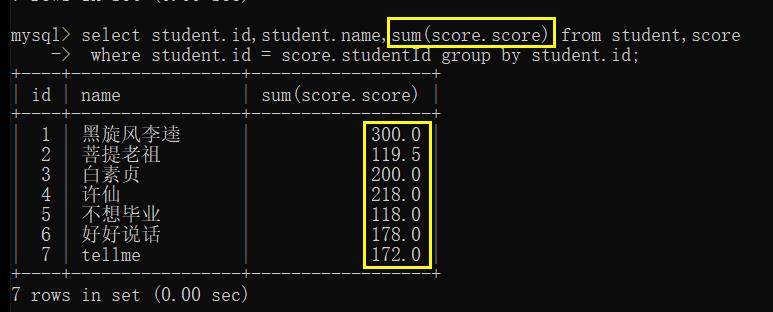
我们发现 score 那一列 还未求得总成绩
- 求总成绩
例3: 查询所有同学的每科的成绩 以及该同学的基本信息
分析: 最终显示效果 —— 同学姓名,科目名称,对应的科目成绩
同学姓名在 student 表中,科目在 course 表中,对应的科目成绩在 score 表中 (三表联合)
- 先针对三张表进行联合
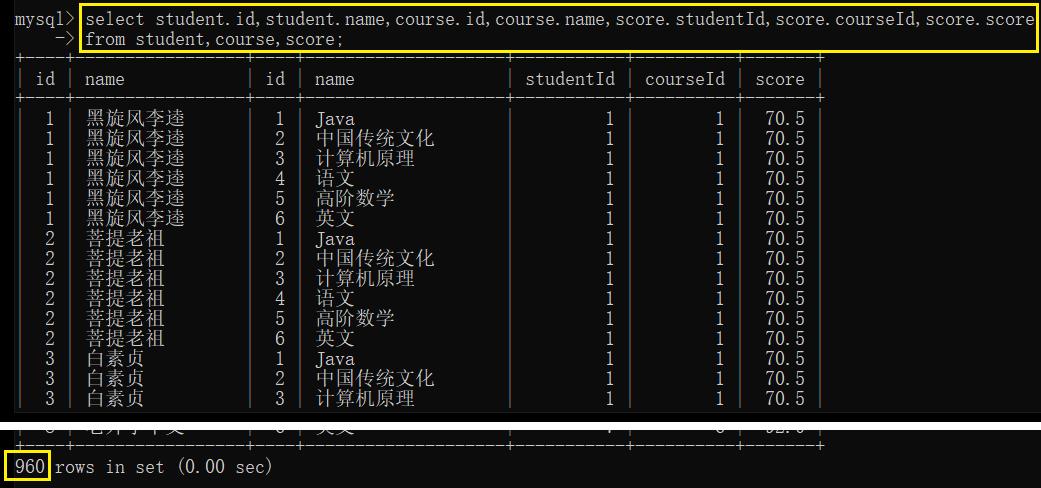
- 按照 student.id 和 score.studentId,针对笛卡尔积的数据进行筛选:
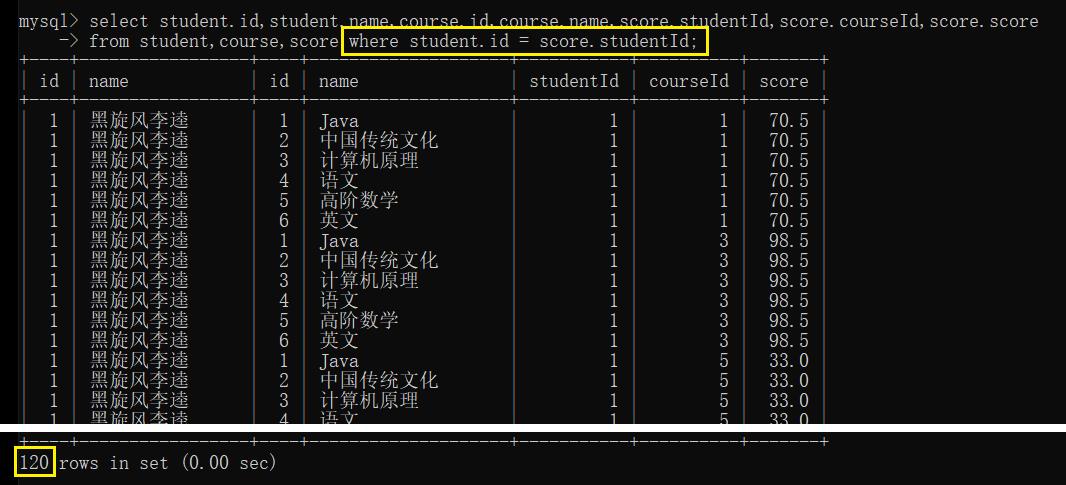
- 结合 course.id 再进行筛选
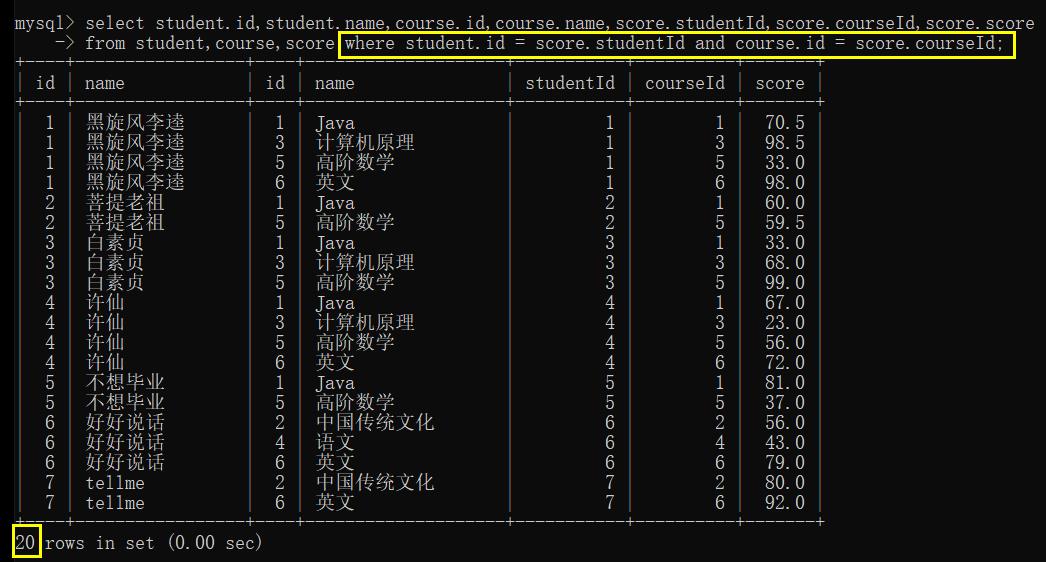
- 去掉重复列
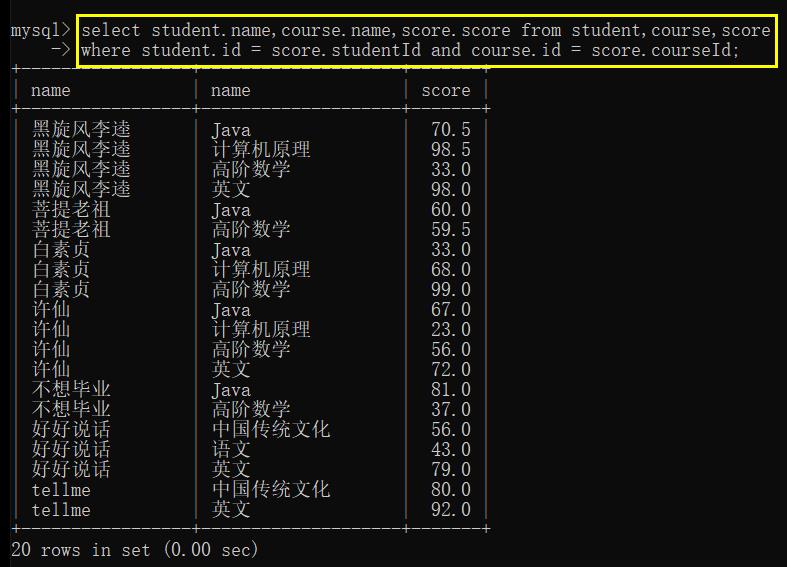
仔细观察,学生表中本来有8个同学,最终查询所有同学成绩的时候,发现只有7个同学有成绩,“老外学中文” 没有成绩
查询发现,在 score 表中,没有 “老外学中文” 的成绩 (没有学号为 8 的同学的成绩)
当前咱们进行笛卡尔积之后再按照 id 筛选,这样的筛选结果一定同时在两张表中都出现过的记录(内连接)
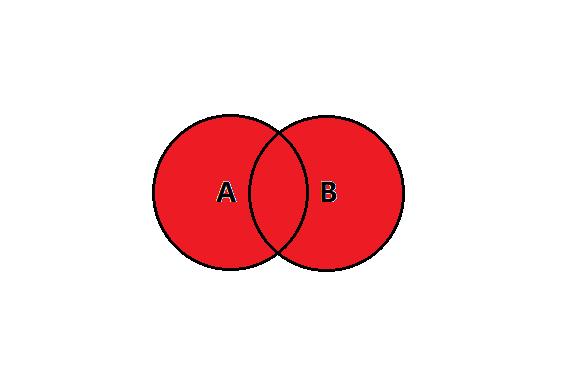
外连接 outer join
如果有些数据在 student 中存在,在 score 中不存在,或者 student 中不存在,score 中存在,这样的记录也能查出来
只要在某个表中存在就能查到
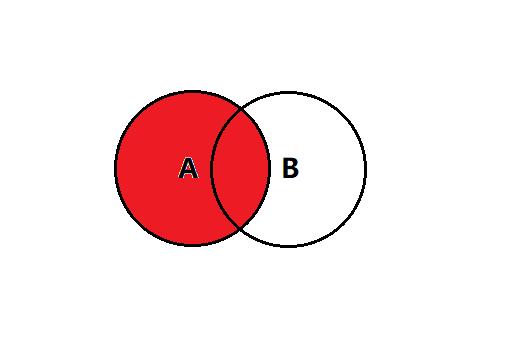
左连接 left join
如果有些数据在 student 中存在,在 score 中不存在 —— 能查到
student 中不存在,score 中存在 —— 查不到
右链接 right join
如果有些数据在 student 中存在,在 score 中不存在 —— 查不到
student 中不存在,score 中存在 —— 能查到
自连接
自连接是指在同一张表连接自身进行查询
自连接本质上相当于把同一列中的两行记录转换成不同列的同一行记录
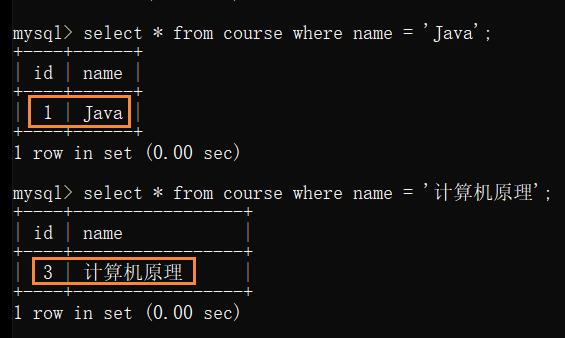
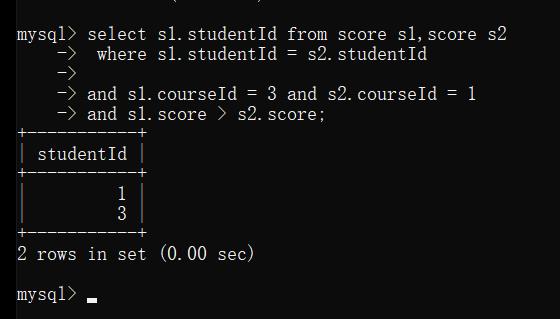
例1: 查询所有计算机原理成绩比Java高的同学
- 先找到 Java 和 计算机与原理 的 course.id
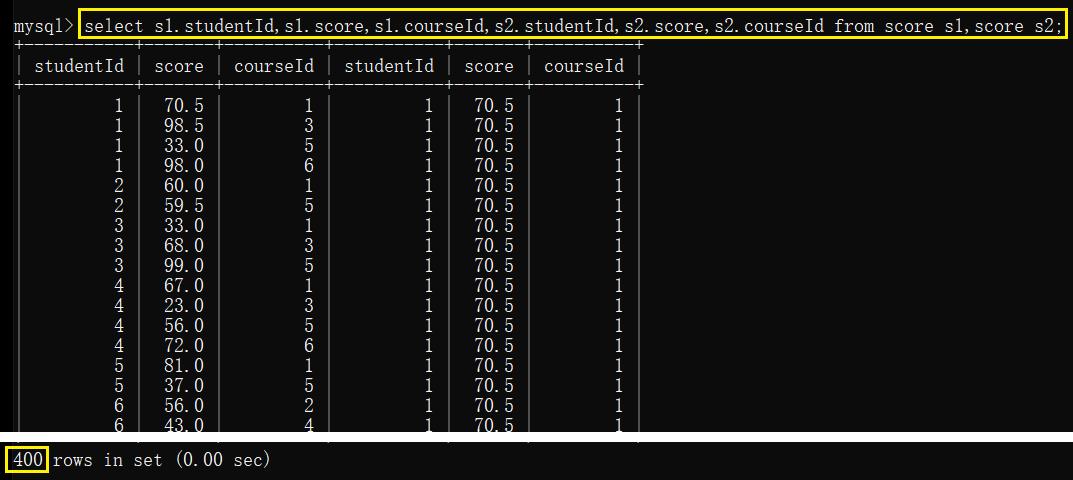
- 按照 course.id 在分数表中筛选数据
2.1 针对 score 表自身 直接进行笛卡尔积
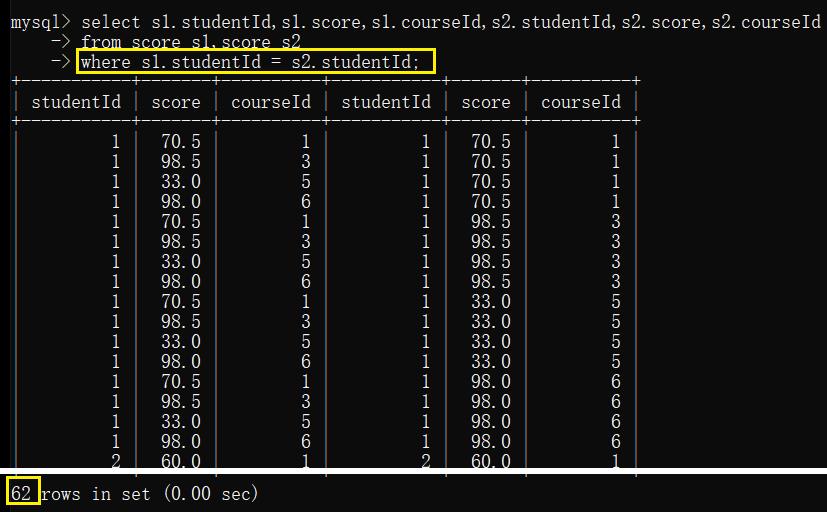
2.2 加上 studentId 的限制
2.3 加上 courseId 的限制
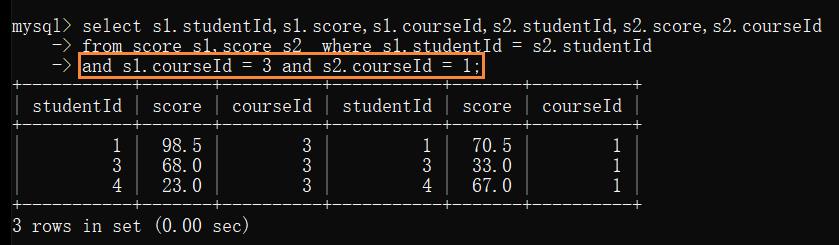
2.4 按照分数大小进行比较
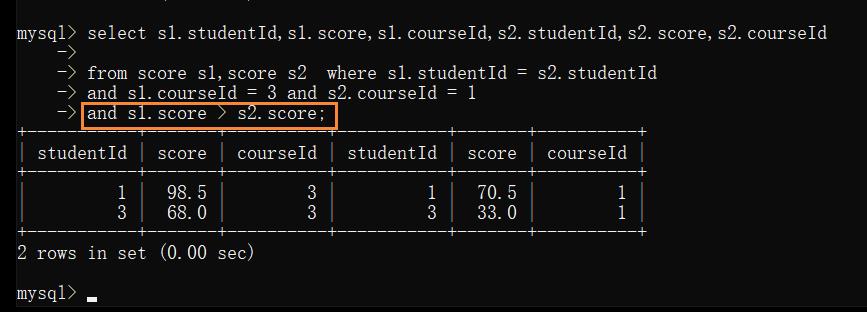
2.5 去掉不必要的列
子查询
子查询是指嵌入在其他 SQL 语句中的 select 语句,也叫嵌套查询
子查询得到的列的数目、顺序、类型都得和被插入的表的列的数目、顺序、类型一致
单行子查询
例: 查询和 “不想毕业” 同班的同学
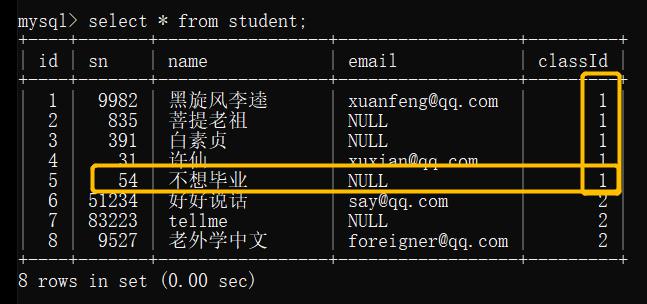
实现过程:
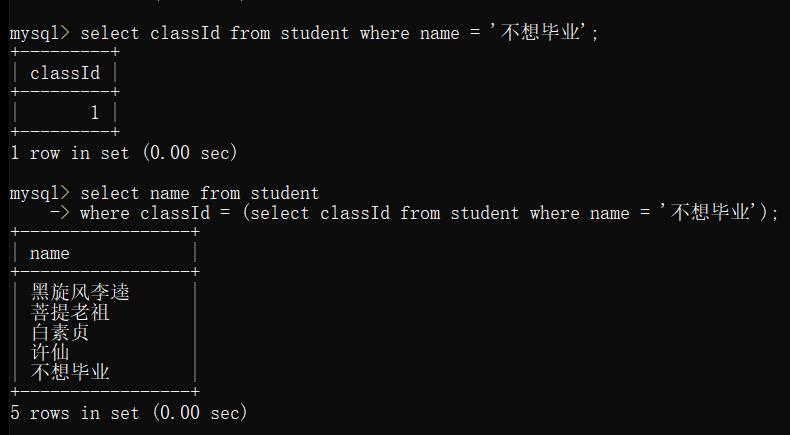
多行子查询
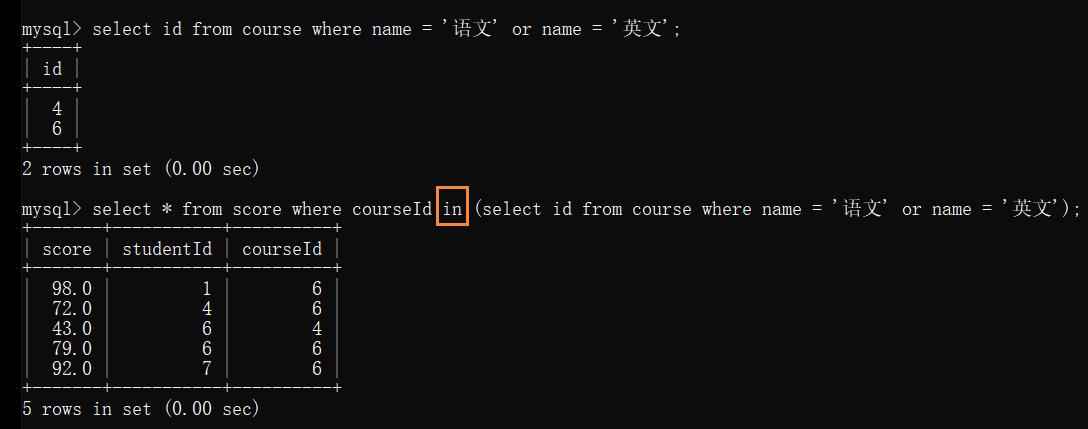
例: 查询 “语文 ”或 “英文” 课程的成绩
如果子表查询的结果集合比较小,就使用 — in
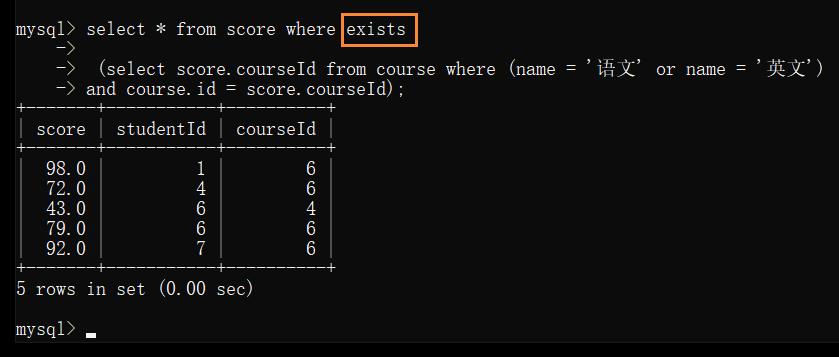
如果子表查询的结果集合比较大,而主表集合小,就使用 — exists
- in:
先执行子查询,把子查询的结果保存到内存中,在进行主查询,再结合刚才子查询的结果来筛选最终结果
- exists:
先执行主查询,再触发子查询,对两个结果进行综合的筛选
合并查询
合并查询相当于把多个查询的结果集合合并成一个集合
(需要保证这多个结果集之间字段、类型、数目都得一致)
- union
例: 查询 id < 3 或者 名字为 “英文” 的课程
直接查询:
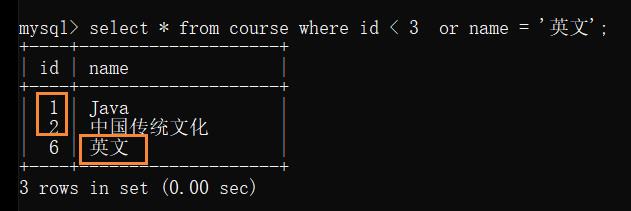
借助 union
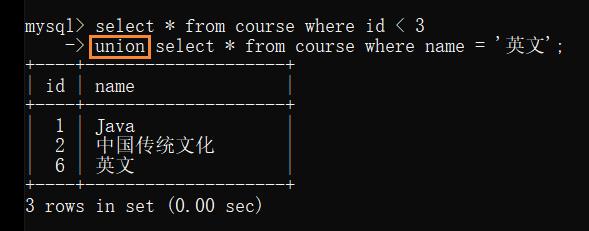
若两个查询结果中存在相同的记录,此时就会只保留一个(自动进行了去重)
如果不想去重,可以使用 union all
- union all
总结
以上是关于MySQL<4>的主要内容,如果未能解决你的问题,请参考以下文章
连接MySQL出现错误:ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)(代码片段
使用 json rereiver php mysql 在片段中填充列表视图
关于mysql驱动版本报错解决,Cause: com.mysql.jdbc.exceptions.jdbc4Unknown system variable ‘query_cache_size(代码片段