Deep Q-learning的发展及相关论文汇总(DQNDDQN,Priority experience replay 等)
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep Q-learning的发展及相关论文汇总(DQNDDQN,Priority experience replay 等)相关的知识,希望对你有一定的参考价值。
在DQN提出之前,强化学习与神经网络的结合遭受着不稳定和发散等问题的困扰。DQN做了以下改进:
(1)使用memory replay 和 target network 稳定基于DL的近似动作值函数;
(2)使用reward来构造标签,解决深度学习需要大量带标签的样本进行监督学习的问题

标准DQN利用max操作符使得目标值过高估计,于是下面这篇文献提出了Double DQN用于平衡值估计。
Deep Reinforcement Learning with Double Q-learning.(2016,AAAI) https://people.engr.tamu.edu/guni/csce689/files/ddqn.pdf 在利用时序差分(Temporal difference,TD)算法对目标Q值进行更新时,后继状态的动作选择来自于当前网络Q,而评估来自于目标网络Q_tartget:
https://people.engr.tamu.edu/guni/csce689/files/ddqn.pdf 在利用时序差分(Temporal difference,TD)算法对目标Q值进行更新时,后继状态的动作选择来自于当前网络Q,而评估来自于目标网络Q_tartget:
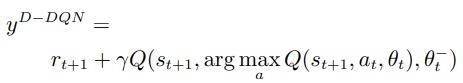

为了消除强化学习转移样本间的相关性, DQN 使用经历重放机制, 即在线存储和均匀采样早期交 互的经历对神经网络进行训练. 然而均匀采样方法 忽略了经历的重要性, 提出了优先经历 重放, 利用 TD error 对经历的重要性进行衡量, 对重要性靠前的经历重放多次, 进而提高学习效率.

此外, 在 DQN 的模型结构方面, 也有着较大的改进. 设计了竞争网络结构 (Dueling network), 在 Q 网络输出层的前一隐藏层输出两个 部分, 一部分估计了状态值函数 V (s), 另一部分估 计了相关动作的优势函数 A(s, a), 在输出层将二者 相加进而估计动作值函数 Q(s, a) = V (s) + A(s, a). 这一结构使得 Agent 在策略评估过程中能够更快地做出正确的动作.
[1511.06581] Dueling Network Architectures for Deep Reinforcement Learning (arxiv.org)https://arxiv.org/abs/1511.06581 将循环神经 网络 (Recurrent neural network, RNN) 引入 DQN 中, 提出了深度循环 Q 网络 (Deep recurrent Q-network,DRQN) 模型, 在部分可观测的强化学习 任务中, 性能超越了标准 DQN.
以上是关于Deep Q-learning的发展及相关论文汇总(DQNDDQN,Priority experience replay 等)的主要内容,如果未能解决你的问题,请参考以下文章
论文笔记之:Deep Recurrent Q-Learning for Partially Observable MDPs
强化学习 学习资料汇总强化学习:Q-learning与DQN(Deep Q Network)
Deep Reinforcement Learning with Double Q-learning: DDQN 简约不简单