归并排序与快速排序背后的秘密
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了归并排序与快速排序背后的秘密相关的知识,希望对你有一定的参考价值。
排序问题一直都是各类考试和面试的热门问题,在读了《算法之美》第三章后,就发觉其实它在各个场合都很热门。其实我们一直在不断地排序,无论我们做什么。
说回具体的考试面试中的排序,很多人都能用各种语言写出各种排序算法,但很少有人会去思考这些算法步骤背后的秘密,那么本文来抛块砖,说说归并排序和快速排序。
到处都讲归并排序采用分治方法,所以效率比冒泡排序高:
将一个大问题分解成一些小问题,分而治之,各个击破…
但这些诠释都缺了关键点,即 效率必须随规模非线性增加的场景,分治才有意义,如果是线性系统,比如计数,分时调度,分治反而增加额外开销。
只要记住,基于比较的排序效率随着规模下凸增加,就足以理解分治方法了。这很容易理解,每次比较涉及两个数而不是一个,这意味着比较的次数比参与比较的数字规模更大。
把规模缩小一倍,排序效率便不止提升一倍,这是分治策略的基础。排序两个子数组(相当于降维)然后再合并的效率一定比直接排序一个大数组效率高,在此基础之上再看归并排序的时间复杂度。
设待排序数组大小为 n n n,使用冒泡排序算法,需要比较的次数为:
T ( n ) = ( n − 1 ) + ( n − 2 ) + . . . + 1 = n ( n − 1 ) 2 T(n)=(n-1)+(n-2)+...+1=\\dfrac{n(n-1)}{2} T(n)=(n−1)+(n−2)+...+1=2n(n−1)
按照时间复杂度的定义忽略小阶项, T ( n ) T(n) T(n)可以等价为 n 2 n^2 n2。
现在将数组均拆成两半,每一半分别冒泡排序,然后合并两个有序子数组,设 T i T_i Ti为将数组均拆成 i i i个子数组时的排序时间复杂度度量,则:
T 2 ( n ) = 2 ( n 2 ) 2 + n T_2(n)=2(\\dfrac{n}{2})^2+n T2(n)=2(2n)2+n
具体采用什么算法排序子数组无所谓,只是为了演示经过 log n \\log n logn次均拆之后,子数组将仅剩下一个元素,整个归并排序只需要 log n \\log n logn层的子数组合并即可,而每层若干合并的总比较次数为 n n n。
继续均拆,随着子数组变小,排序涉及的比较次数指数递减。
将大小为 i i i的子数组逐级合并为大小为 2 i 2i 2i的子数组,每次合并操作涉及的操作次数固定为 n n n,对于不同的 i i i,总比较次数分别为:
T 4 ( n ) = 4 ( n 4 ) 2 + 2 n T_4(n)=4(\\dfrac{n}{4})^2+2n T4(n)=4(4n)2+2n
T
8
(
n
)
=
8
(
n
8
)
2
+
3
n
T_8(n)=8(\\dfrac{n}{8})^2+3n
T8(n)=8(8n)2+3n
…
可以期望,子数组大小肯定会递减到1,合并两个大小为1的子数组仅需一次比较,此时:
T n ( n ) = n ( n n ) 2 + n log 2 n = n log 2 n + n T_n(n)=n(\\dfrac{n}{n})^2+n\\log_2n=n\\log_2n+n Tn(n)=n(nn)2+nlog2n=nlog2n+n
这就是归并排序的时间复杂度 O ( n log 2 n ) O(n\\log_2n) O(nlog2n)。从这个过程发现无论最好,最坏,平均,归并排序的时间复杂度不变。
这是一个非常清晰的过程,但并没有回答一个核心问题,与 O ( n 2 ) O(n^2) O(n2)的冒泡排序相比,归并排序到底省掉了哪些比较,从而让时间复杂度减少到 O ( log n ) O(\\log n) O(logn)?
看一下合并两个已排序数组的过程,请看下图:
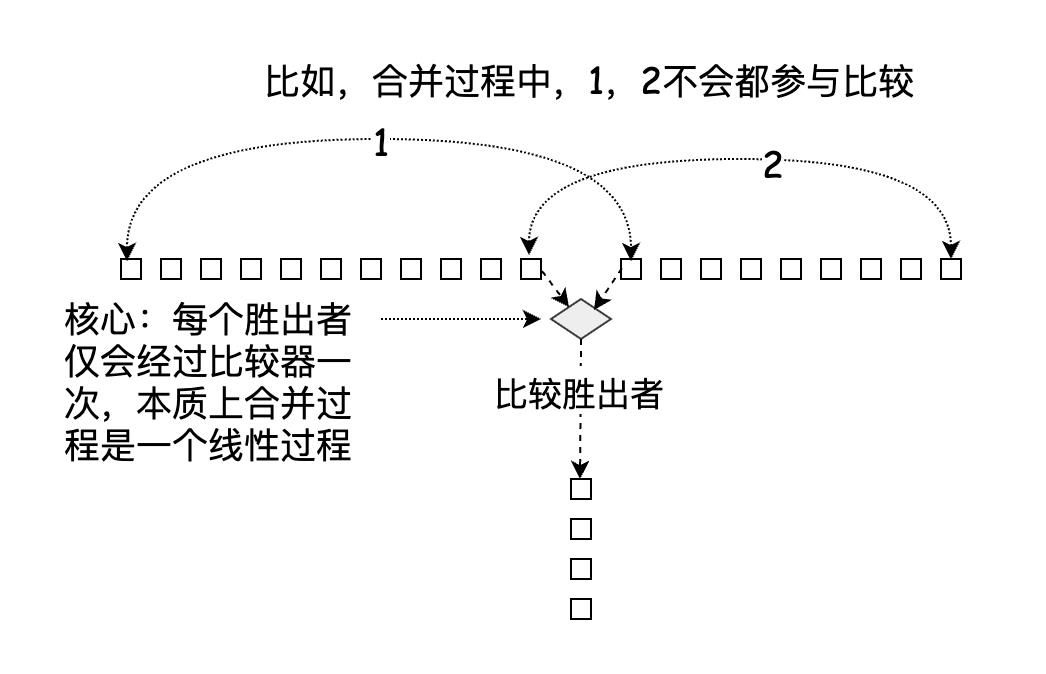
两个有序子数组中两组数字,其中一个的头和另一个的尾,在一次合并中不会同时参与比较,减少的比较操作正是来源于此,经过不断分治,归并排序实际上就是一个递归合并的过程。
若仅仅考虑时间复杂度,归并排序可以证明是最高效的排序算法。 O ( n log n ) O(n\\log n) O(nlogn)是比较排序算法绕不过的极限,而这很容易证明。
n n n个数字有 n ! n! n!种序列,升序(或者降序)是其中一种。 n n n个数字中两数经过一次比较可确定两数的相对位置,那么就剩下 n ! 2 \\dfrac{n!}{2} 2n!种序列,在 n ! 2 \\dfrac{n!}{2} 2n!种序列中,再比较一次,就会剩下 n ! 4 \\dfrac{n!}{4} 4n!种序列,以此类推,现在问,至少比较多少次能只剩下1种序列,设比较 x x x次可达,那么:
2 x ≥ n ! 2^x\\geq n! 2x≥n!
两边取对数,解 x x x,即:
x ≥ log 2 n ! x\\geq\\log_2n! x≥log2n!
不等号右边用斯特林公式近似,得到比较排序的时间复杂度极限 O ( n log n ) O(n \\log n) O(nlogn),而归并排序就是比较排序的一种,它的最差情况都能达到 O ( n log n ) O(n\\log n) O(nlogn),这无疑是最棒的算法。
遗憾的是,它的空间复杂度为 O ( n ) O(n) O(n),在实际实现中,随着 n n n的增加,排序操作需要大量的内存,这非常不利于cache亲和,而快速排序的原地排序优化可以避免空间问题,这就是快速排序胜出的原因。
那么快速排序为什么可以胜任?它的时间复杂度表现如何呢?
很著名的一篇文章:
数学之美番外篇:快排为什么那样快
我觉得小题大做了,没那么复杂,快速排序核心就是随机,如果每次都能抓到剩余子数组的中位数,每次都是均拆,考虑到每拆到一层
i
i
i,该层比较总和为
n
−
1
−
i
n-1-i
n−1−i,总的操作次数是可以算出来的:
T = ∑ i = 0 log n ( n − 1 − i ) T=\\sum\\limits_{i=0}^{\\log n}(n-1-i) T=i=0∑logn(n−1−i)
在最好的情况下,快速排序和归并排序时间复杂度均一致,均为 O ( n log n ) O(n\\log n) O(nlogn)。
但每次都抓住中位数几乎不可能, n n n个数选一个,概率均为 1 n \\dfrac{1}{n} n1,所有子数组均能选中中位数概率可想而知。
无论是否抓到了中位数,快速排序每一步总是可以将子数组分成两个部分,相比 O ( n 2 ) O(n^2) O(n2)的冒泡排序,快速排序减少比较次数从而降低时间复杂度的秘密在于,在某层被拆开的两部分之间,直到排序结束,均不会发生任何比较。
既然最好情况几乎不可达,最差时间复杂度又是不可接受的 O ( n 2 ) O(n^2) O(n2),问题是,平均情况下,距离最好情况,差多少呢?如果平均情况接近最好情况,也不错。
快速排序的平均情况显然也是 O ( n log n ) O(n\\log n) O(nlogn),若非如此,也就没有本文,问题是不光要把它推导出来,还要能直观地描绘出来。
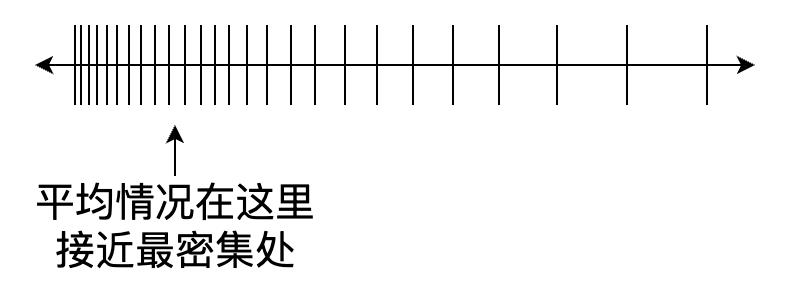
平均情况体现在所有排序可能性最接近所有可能性平均数的地方,下图展示了最坏情况到最好情况的单调过渡:

退化成链表的二叉树高度为
h
=
n
h=n
h=n,它逐渐变矮,直到满二叉树最矮
h
=
log
n
h=\\log n
h=logn,这个过程中,
h
h
h越小,可以构造的二叉树越多,可能性分布越密集。而每一棵二叉树都表示一种可能的快速排序,所有可能的平均数位置必然接近密度最大处,显然
h
a
v
g
h_{avg}
havg会很小:
有了直观的感受,推导出来的平均时间复杂度就容易理解了。来自wiki,设
T
(
n
)
T(n)
T(n)为排序
n
n
n个数所需的操作:
T
(
n
)
=
1
n
∑
i
=
0
n
−
1
(
T
(
i
)
+
T
(
n
−
i
−
1
)
)
+
(
n
−
1
)
=
1.39
n
log
n
T(n)=\\dfrac{1}{n}\\sum\\limits_{i=0}^{n-1}(T(i)+T(n-i-1))+(n-1)=1.39n\\log n
以上是关于归并排序与快速排序背后的秘密的主要内容,如果未能解决你的问题,请参考以下文章