C++STL之string类的使用和实现
Posted 小赵小赵福星高照~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++STL之string类的使用和实现相关的知识,希望对你有一定的参考价值。
STL简介
什么是STL
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
STL的版本
- 原始版本
Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。 HP 版本–所有STL实现版本的始祖。
- P. J. 版本
由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
- RW版本
由Rouge Wage公司开发,继承自HP版本,被C+ + Builder 采用,不能公开或修改,可读性一般。
- SGI版本
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版本。被GCC(Linux)采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。
C++标准委员会制定出语法规则,编译器厂商选择性的去支持语法,不一定所有的编译器都支持C++标准委员会制定出部分语法
STL的六大组件

STL的重要性
在笔试中:
有很多题我们需要用到数据结构和算法,但是笔试时间是有限的,我们总不能现写数据结构和一个算法,比如两个栈实现队列,我们写一个栈时间就够你用的了,别说实现队列了,所以是非常重要的
在招聘工作中:
经常会有C++程序员对STL不是非常了解,大多是有一个大致的映像,而对于在什么情况下应该使用哪个容器和算法都不清楚,STL是C++程序员不可或缺的技能,掌握它对C++提升有很多帮助。
string
为什么学习string类?
C语言中的字符串
C语言中,字符串是以’\\0’结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
#include<string>
int main()
{
cout<<sizeof(char)<<endl;
cout<<sizeof(wchar_t)<<endl;
return 0;
}

为什么会有wchar_t呢?而且它是两个字节。
关于编码
计算机中只有二进制0、1,我们如何去表示文字呢?建立对应的编码表
1、ASCII->支持英文,1字节==8bit,有符号有0-255种表示方法,ascii编码表就是对256个值建立一个对应的表示值
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dN7EJB7T-1636190891004)(https://ts1.cn.mm.bing.net/th/id/R-C.a8c58c9e1c63e23613d69316334505a9?rik=0EKQfdqIkkoNfw&riu=http%3a%2f%2fwww.asciima.com%2fimg%2fascii-Table.jpg&ehk=UiXHk2H6LELHzgDh1FxLn1%2bMFO82gg4BpJ0%2bvpLSx7w%3d&risl=&pid=ImgRaw&r=0)]
int main()
{
char ch=97;
char ch1=98;
char arr[]="hello world";
return 0;
}

计算机里存的是ascii码
2、全世界各个国家都开始用计算机了,早期的计算机中只能表示英文,不能表示其他国家的文字。需要建立出自己的编码表,那就非常乱,就出来了一个东西UniCode,Unicode的不同的实现,用了不同的存储方式。UTF-8, UTF-16, UTF-32,就是 Unicode 不同的实现。
1个字节可以有256状态,2个字节有256*256种状态,显然汉字用一个字节编码肯定是不够用的,所以汉字用两个字节去编码:
#include<string>
int main()
{
char arr2[]="中国";
return 0;
}

由于编码的原因,所以不仅仅有char,还有wchar_t
标准库中的string类
string类
- string是表示字符串的字符串类
- 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
- string在底层实际是:basic_string模板类的别名,typedef basic_string<char, char_traits, allocator>string;
- 不能操作多字节或者变长字符的序列。
- string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类,并用char_traits和allocator作为basic_string的默认参数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s1KihJMg-1636190891008)(C:\\Users\\15191107746\\AppData\\Roaming\\Typora\\typora-user-images\\image-20211102150244902.png)]
string类对象的构造函数
| 函数名称 | 功能说明 |
|---|---|
| string() | 构造空的string类对象,即空字符串 |
| string(const char* s) | 用C-string来构造string类对象 |
| string(size_t n,char c) | string类对象中包含n个字符c |
| string(const string&s) | 拷贝构造函数 |
string类对象构造函数的使用:
#include<string>
template<class T>
class basic_string
{
T* _arr;
int _size;
int _capacity;
};
int main()
{
string s1();
string s2("hello world");
string s3("中国");
string s4(10,'a');
string s5(s2);
cout<<s1<<endl;
cout<<s2<<endl;
cout<<s3<<endl;
cout<<s4<<endl;
cout<<s5<<endl;
s1 = s5;
cout<<s1<<endl;
return 0;
}

string类的成员函数的使用
上面知道了string类对象如何初始化,那么我们想要遍历string该怎么遍历呢?
1、for循环遍历 修改+读取
[]+下标方式:
int main()
{
string s2("hello world");
for (size_t i = 0; i < s2.size(); ++i)
{
//写
s2[i] += 1;
}
for (size_t i = 0; i < s2.size(); ++i)
{
//读
cout << s2[i] << " ";
}
cout << endl;
return 0;
}

2、范围for遍历 修改+读取
for(auto& e : s2)//想要修改需要加引用
{
//写
e += 1;
}
for(auto e : s2)//取该对象的每个字符赋给e
{
//读
cout<< e <<" ";
}
cout<<endl;
3、迭代器遍历:
使用迭代器遍历我们需要了解String中的Iterators成员函数,下面我们来看看迭代器遍历是怎么遍历的:

int main()
{
string s2("hello");
string::iterator it = s2.begin();
//s2.begin()返回第一个有效数据位置的迭代器
//s2.end()返回最后一个有效数据的下一个位置的迭代器
while(it!=s2.end())
{
*it+=1;
++it;
}
cout<<endl;
it = s2.begin();
while(it!=s2.end())
{
cout<<*it<<" ";
++it;
}
cout<<endl;
return 0;
}
s2.begin()返回第一个有效数据位置的迭代器
s2.end()返回最后一个有效数据的下一个位置的迭代器
迭代器是一个像指针一样的东西,有可能是指针,也有可能不是指针,迭代器遍历的好处,可以用统一类似的方式去访问容器

注意:
建议用判断循环是否继续时用!=,如果不用,遇到不是顺序表的结构就会有问题。比如链表的结构:
int main()
{
vector<int> v = {1,2,3,4};
vector<int>::iterator vit = v.begin();
while (vit != v.end())
{
cout <<*vit << "";
++vit;
}
cout << endl;
list<int> lt = { 1,2,3,4 };
list<int> ::iterator lit = lt.begin();
while ( lit !=lt.end())
{
cout <<*lit <<" ";
++lit;
}
cout << endl;
return 0;
}
这里就会出问题:
因为list是链表结构,不用!=进行比较,而用<比较的话是不行的,因为链表元素的地址并不一定后面的地址大,前面的地址小
注意:
1、所有的容器都支持用迭代器,所以迭代器才是容器通用访问方式
2、vector/string这种顺序表结构支持下标+[]去访问,像list、map就不支持了
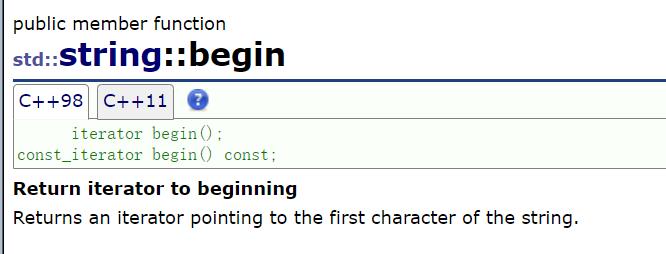
const修饰的迭代器:
void Print(const string& s)
{
//const对象要用const迭代器,只读,不能写
string::iterator it = s.begin();
//string::const_iterator it = s.begin();
//
while(it!=s.end())
{
cout<<*it<<" ";
++it;
}
cout<<endl;
}
void test_string2()
{
string s1("hello");
Print(s1);
}
int main()
{
test_string2();
return 0;
}
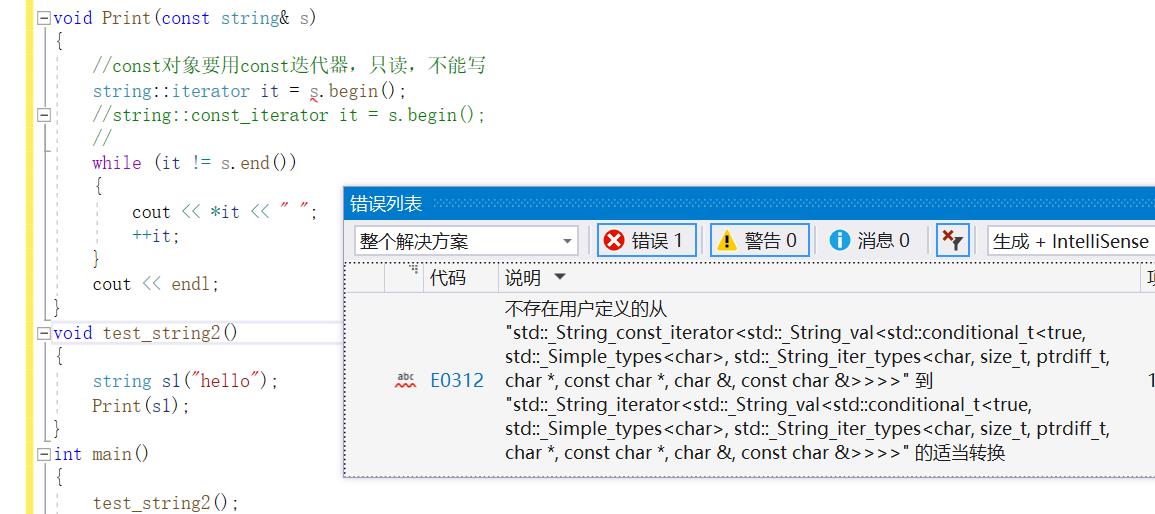
编译不通过,为什么呢?因为s1传参到s是const对象,const对象要用const迭代器,只读,不能写
所以我们需要这样写:
string::const_iterator it = s.begin();
了解了遍历方式,下面我们来做一道OJ题:仅仅反转字母
题目描述:
给定一个字符串
S,返回 “反转后的” 字符串,其中不是字母的字符都保留在原地,而所有字母的位置发生反转。
示例 1:
输入:"ab-cd"
输出:"dc-ba"
示例 2:
输入:"a-bC-dEf-ghIj"
输出:"j-Ih-gfE-dCba"
[]+下标进行遍历:
class Solution
{
public:
bool isLetter(char ch)
{
if(ch >= 'a'&& ch <= 'z ')
return true;
if(ch >= 'A'&& ch <= 'Z')
return true;
return false;
}
string reverseOnlyLetters(string s)
{
int begin =0;
int end = s.size()-1;
while(begin<end)
{
while(begin<end && !isLetter(s[begin]))
{
begin++;//找是字母
}
while(begin<end && !isLetter(s[end]))
{
end--;//找是字母
}
swap(s[begin],s[end]);
begin++;
end--;
}
}
return s;
};
使用迭代器的解法:
class Solution {
public:
bool isLetter(char ch)
{
if(ch >= 'a'&& ch <= 'z ')
return true;
if(ch >= 'A'&& ch <= 'Z')
return true;
return false;
}
string reverseOnlyLetters(string s)
{
auto it_left =s.begin();
auto it_right = s.end()-1;
while(it_left<it_right)
{
while(it_left<it_right && !isLetter(*it_left))
{
it_left++;//找是字母
}
while(it_left<it_right && !isLetter(*it_right))
{
it_right--;
}
swap(*it_left,*it_right);
it_left++;
it_right--;
}
return s;
}
};
下面我们来看迭代器中的rbegin和rend


rbegin指向最后一个元素,rend指向第一个元素的前一个位置:
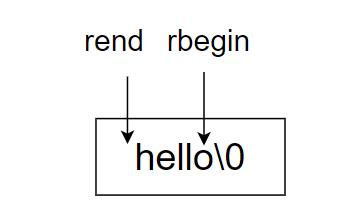
反着遍历对象:
void test_string3()
{
//反着遍历对象
string s1("hello");
string::reverse_iterator rit = s1.rbegin();
while (rit != s1.rend())
{
cout << *rit << endl;
++rit;
}
cout << endl;
//不想改可以加const
string::const_reverse_iterator rit1 = s1.rbegin();
while (rit1 != s1.rend())
{
cout << *rit1 << endl;
++rit1;
}
cout << endl;
}
int main()
{
test_string3();
return 0;
}

String中的Capacity成员函数

size、length、capacity、max_size:
void test_string3()
{
string s1("hello");
cout<<s1.size()<<endl;//推荐用size
cout<<s1.length()<<endl;
cout<<s1.capacity()<<endl;//随着字符串长度改变
cout<<S1.max_size()<<endl;//实际中没什么意义
}

size和length是一样的意思,都是计算对象的长度,但推荐用size,而capacity就是容量,它是随着字符串长度的改变而改变的,max_size实际中没什么意义,因为不管初始化还是不初始化在32位操作系统下它都是231 -1字节,2*1024*1024*1024-1字节,也就是相当于2G
resize:
首先看下面代码:
int main()
{
string s2("hello world");
cout<<s2.size()<<endl;
s2.resize(20);
cout<<s2.size()<<endl;
return 0;
}

大小不一样了,我们使用了resize,传参为20时,s2对象的size改变了,为什么呢?我们来看C++文档当中怎么说明这个函数的:

我们来翻译一下它的意思:
改变这个字符串对象的长度为n,如果n小于当前字符串的长度,则将当前值缩短到第n个字符,删除第n个字符以外的字符。如果n大于当前字符串长度,延长字符串长度,并在最后插入指定内容直到达到的延长后的长度n。如果指定c, 用c来初始化,否则,他们初始化值字符(null字符)。
对于上面的代码我们进行调试:
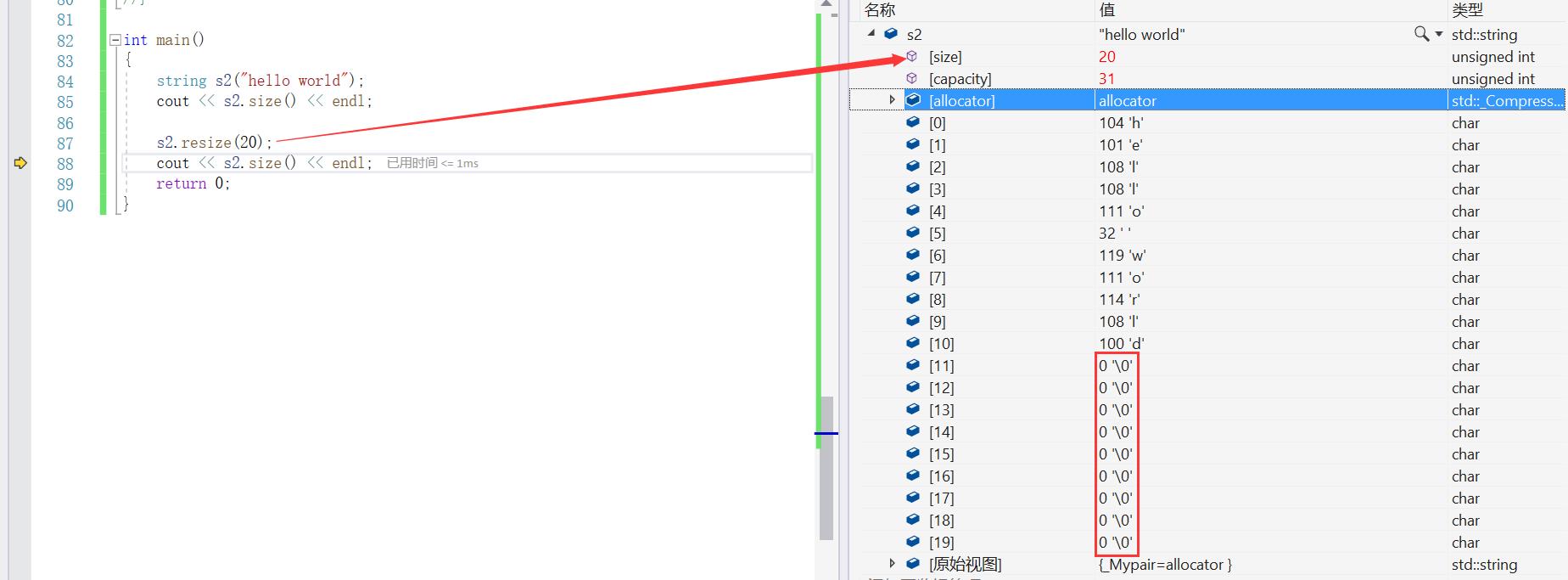
当指定了填充的字符:

上面是resize大于size的情况,那么小于的情况呢,请看下面的调试:
int main()
{
string s2("hello world");
cout<<s2.size()<<endl;
s2.resize(5);
cout<<s2.size()<<endl;
return 0;
}
可以看到当前值缩短到第5个字符,删除第5个字符以外的字符

reserve:
首先看下面代码:
int main()
{
string s4("hello world");
cout<<s4.capacity()<<endl;
s4.reserve(20);
cout<<s4.size()<<endl;
cout<<s4.capacity()<<endl;
return 0;
}

reserve是一个改变容量的函数,这里我们明明改了20,为什么容量变成了31呢?我们同样的查看一下C++文档:

如果n大于当前字符串的容量,该函数将使容器的容量增加至少n个字符。其他情况容量不会改变
n大于当前字符串容量的测试:
n小于当前字符串的测试:

windows和Linux的增容规则的测试
windows下的增容规则:
void test()
{
string s;
size_t sz = s.capacity();
cout<<"making s grow:\\n"<<sz<<endl;
for(int i = 0;i<500;i++)
{
s.push_back('c');
if(sz!=s.capacity())//如果真,则说明增容了
{
sz = s.capacity();
cout<<"capacity changed: "<<sz<<'\\n';
}
}
}

可以看到windows下的增容规则大约是1.5倍的增容
Linux下的增容规则:

可以看到Linux下的增容规则是二倍增容
那么resize和reserve的意义是什么呢?
reserve的作用:如果我们知道数据的多少,就可以一次性就把空间开好,避免增容,提高效率,resize的作用:既要开好空间,还要对这些空间初始化,就可以用resize
clear

clear就是将字符串变成空字符串
void test_string()
{
string s1("hello");
cout<<s1<<endl;
s1.clear();
cout<<s1<<endl;
}

可以看到s1已经变成了空字符串
empty

判断一个字符串是不是空字符串
String中Modifiers的成员函数
push_back、append
push_back尾插一个字符,append为尾插字符串
int main()
{
string s1以上是关于C++STL之string类的使用和实现的主要内容,如果未能解决你的问题,请参考以下文章