基于改进EAST算法的文本检测
Posted m0_51330713
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于改进EAST算法的文本检测相关的知识,希望对你有一定的参考价值。
这段时间阅读研究了EAST算法以及在EAST算法上的改进并完成了复现运用到其他场景中去。
当今社会已进入图像大数据时代,图像数量庞大种类繁多,包含大量的有用知识。从图像中高效、精准、全面地提取文本和地理信息坐标等有用知识这一课题,也成为图像处理的一个重要方向。
随着近些年来深度学习技术不断进步发展,对于一些特定场景的图像文本定位任务成为国内外计算机视觉、模式识别研究方向相关学者的研究方向之一。解决特定场景图像文本信息提取问题依赖于各种神经网络模型算法。需要考虑到各种因素,一般将场景文本提取拆分为两个主要任务:文本定位和文本识别。特定场景图像文本检测算法的大体框架也基于文本定位和文本识别这两大任务.
其中,文本定位算法主要通过计算机自动框定出文本在图像中的位置,作为后续文本识别过程的先行条件,在图像的知识提取中起着重要作用。目前基于深度学习的文本检测算法主要分为两类,一类是基于预选框的文本检测算法,另一类是使用全卷积神经网络直接预测目标位置。文献中提出的EAST(An Efficient and Accurate Scene Text Detector)算法是直接预测文本字符位置的定位算法,算法运行速度快,在基准数据集上准确率高。核心思想是直接预测单词或文本行的倾斜角度及多边形形状,消除多层神经网络中复杂的运算过程,在各种公开的数据集中取得了良好的成果。
同时,文本识别算法主要是通过文本定位的结果定位到文本的位置,然后通过端到端的转录算法将该位置的信息转换为中文文本。
EAST算法是旷世科技在2017年CVPR上提出的一种十分简洁高效的文本检测模型。论文全称是《 EAST: An Efficient and Accurate Scene Text Detector 》。作者在文中提出,过去的文本检测方法虽然实现了不错的效果,但这些方法基本上都是多阶段、多组件的联合作用。换句话说,就是作者认为以往的方法设计的步骤和组件过多,导致它们在一些具有挑战性的场景中表现不够好,速度也不够快。
因此,作者设计了一种十分简洁高效的方法,可以直接通过一个FCN网络来得到字符级或文本行的预测结果。且不论是精度还是速度,在各大基准数据集上都有杰出的表现(在ICDAR2015上得到了0.782的F值和13.2的fps)。方法的整体思路是通过一个FCN直接得到文本框预测,之后将预测通过NMS得到最终结果(two stage)。下面是这项工作的主要贡献:
1. 提出了一个两阶段的场景文本检测方法,FCN+NMS,不需要其他多余耗时的步骤。
2. 该方法可灵活生成字符级或文本行的预测,几何形状可以是旋转框或者矩形框。
3. 在精度和速度都优于当时其他的方法。
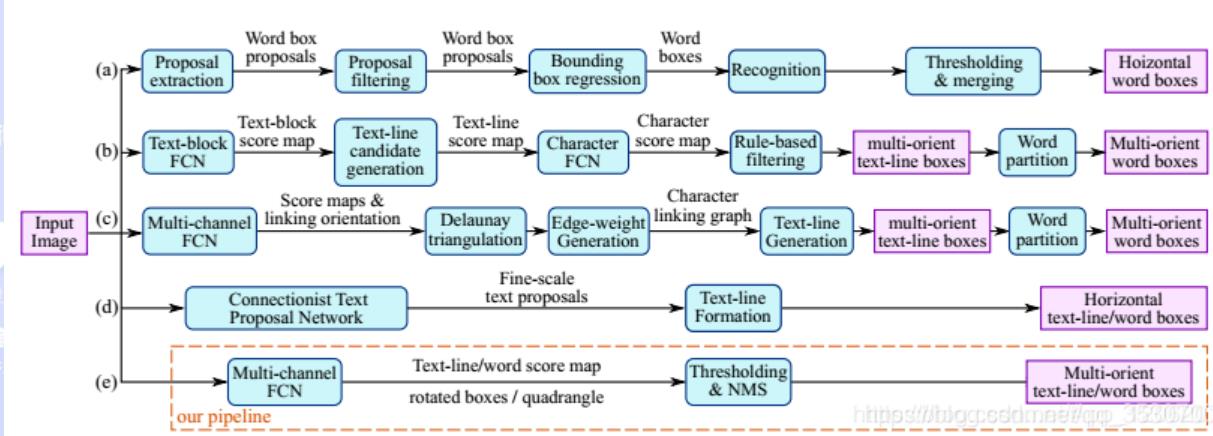
那么该算法的优势在于消除传统算法中间冗余而又慢速的步骤,只包含两个主要流程: 一是使用全卷积网络( fully convolutional networks,FCN) 模型直接生成单词或文本行级别预测; 二是将生成的文本预测( 可以是旋转的矩形或四边形) 输入到非极大值抑制 NMS( non-maximum suppression) 中以产生最终结果。而传统的文本检测方法和一些基于深度神经 网络的文本定位方法由若干组件构成,包含多个步骤且在训练时需要对其分别进行调优,耗费时间较多。
我打算先介绍一下EAST算法,然后再详细讲述基于EAST算法的改进。
https://github.com/argman/EAST
这是原作者参与的一份tensorflow版本代码,网上还有其他的实现。
开源代码一般都是在linux环境下编写、测试、运行。
首先是下载源码:
git clone https://github.com/argman/EAST.git然后就是下载好模型文件放到指定的位置测试。
第一次运行肯定会报错,windows和Linux毕竟不同。
参考博客:https://www.jianshu.com/p/c5a9e1ecf790
报错:import lanms
File "D:\\work\\Chepai\\License-Plate-Recognition-master1\\EAST-master\\lanms\\__init__.py", line 10, in <module>解决问题的办法是:
注释掉__init__.py中的下面这两行
# if subprocess.call(['make', '-C', BASE_DIR]) != 0: # return value
# raise RuntimeError('Cannot compile lanms: {}'.format(BASE_DIR))注释掉这两行还是会报错:
File "eval.py", line 162, in main
boxes, timer = detect(score_map=score, geo_map=geometry, timer=timer)
File "eval.py", line 100, in detect
boxes = lanms.merge_quadrangle_n9(boxes.astype('float32'), nms_thres)
File "D:\\Github\\EAST\\lanms\\__init__.py", line 12, in merge_quadrangle_n9
from .adaptor import merge_quadrangle_n9 as nms_impl
ImportError: No module named 'lanms.adaptor'解决办法是:
结果发现报eval.py中的100行错误,所以把这一行注释掉,换成上一句。
boxes = nms_locality.nms_locality(boxes.astype(np.float64), nms_thres)
# boxes = lanms.merge_quadrangle_n9(boxes.astype('float32'), nms_thres)结果不再报错了。
另外,我自己使用的是windows,所以源码中给出的test方法对我并不适用,会报错找不到模型文件路径。
File "eval.py", line 147, in main
model_path = os.path.join(FLAGS.checkpoint_path, os.path.basename(ckpt_state.model_checkpoint_path))
AttributeError: 'NoneType' object has no attribute 'model_checkpoint_path'原因是这个代码在windows下是用不了相对路径,换成绝对路径就可以了。
github 源码中给出的test脚本是:
python eval.py --test_data_path=/tmp/images/ --gpu_list=0 --checkpoint_path=/tmp/east_icdar2015_resnet_v1_50_rbox/ --output_dir=/tmp/我在windows下使用的脚本是:
(我把下面的脚本写到一个test.bat文件中,这样每次执行就不用敲代码了,双击一下就可以执行)
python eval.py --test_data_path=D:/Github/EAST/tmp/images/ --gpu_list=0 --checkpoint_path=D:/Github/EAST/tmp/east_icdar2015_resnet_v1_50_rbox/ --output_dir=D:/Github/EAST/tmp/
pause在windows下的训练脚本train.bat:
python multigpu_train.py --gpu_list=0 --input_size=512 --batch_size_per_gpu=8 --checkpoint_path=D:/Github/EAST/tmp/east_icdar2015_resnet_v1_50_rbox/ --text_scale=512 --training_data_path=D:/Github/EAST/data/ocr/icdar2015/ --geometry=RBOX --learning_rate=0.0001 --num_readers=24 --pretrained_model_path=D:/Github/EAST/tmp/resnet_v1_50.ckpt
pause第一次跑也是跑不不通,报错:
Generator use 10 batches for buffering, this may take a while, you can tune this yourself.
Traceback (most recent call last):
File "multigpu_train.py", line 180, in <module>
tf.app.run()
File "D:\\Anaconda3\\envs\\py35\\lib\\site-packages\\tensorflow\\python\\platform\\app.py", line 126, in run
_sys.exit(main(argv))
File "multigpu_train.py", line 153, in main
data = next(data_generator)
File "D:\\Github\\EAST\\icdar.py", line 726, in get_batch
enqueuer.start(max_queue_size=10, workers=num_workers)
File "D:\\Github\\EAST\\data_util.py", line 81, in start
thread.start()
File "D:\\Anaconda3\\envs\\py35\\lib\\multiprocessing\\process.py", line 105, in start
self._popen = self._Popen(self)
File "D:\\Anaconda3\\envs\\py35\\lib\\multiprocessing\\context.py", line 212, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "D:\\Anaconda3\\envs\\py35\\lib\\multiprocessing\\context.py", line 313, in _Popen
return Popen(process_obj)
File "D:\\Anaconda3\\envs\\py35\\lib\\multiprocessing\\popen_spawn_win32.py", line 66, in __init__
reduction.dump(process_obj, to_child)
File "D:\\Anaconda3\\envs\\py35\\lib\\multiprocessing\\reduction.py", line 59, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'GeneratorEnqueuer.start.<locals>.data_generator_task'问题出现在上面的提示 enqueuer.start(max_queue_size=10, workers=num_workers)
参考:https://blog.csdn.net/weixin_41437855/article/details/90259922 的评论stoneboy1211
解决办法:
将icdar.py 724行开始的部分改为(改动部分 True改为False,10改为1,numworks改为1):
enqueuer = GeneratorEnqueuer(generator(**kwargs), use_multiprocessing=False)
print('Generator use 10 batches for buffering, this may take a while, you can tune this yourself.')
enqueuer.start(max_queue_size=1, workers=1)接着还会报错:
Traceback (most recent call last):
File "D:\\Github\\EAST\\icdar.py", line 609, in generator
text_polys, text_tags = load_annoataion(txt_fn)
File "D:\\Github\\EAST\\icdar.py", line 56, in load_annoataion
for line in reader:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xbf in position 2: illegal multibyte sequence解决办法:将icdar.py的54行由
with open(p, 'r') as f:
改为:
with open(p, 'r', encoding='utf-8') as f:
接下来训练也可以跑通了。
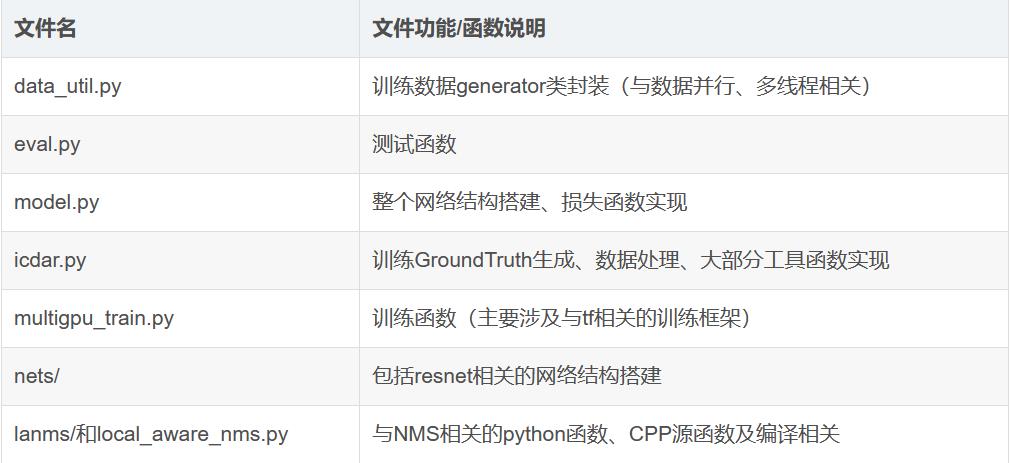
EAST源码主要包含3个功能模块:
- icdar.py此部分主要是对数据进行预处理;
- model.model()函数,该函数在model.py中,主要是完成网络结构搭建,特征图的生成;
- model.loss()函数,该函数在model.py中,主要是计算损失。
- 其他代码说明:
下面介绍基于EAST算法的改进。
改进后的EAST算法相比基于候选框的目标检测算法更加准确。对于大比例尺,文本尺度多样的图像中的文本检测更加准确。但仍然存在一些问题。如化学符号等特别密集的区域检测准确率较低。存在改进方向如下:提高更加清晰的训练样本,优化网络结构,进一步提升检测算法的准确性。改进后的EAST算法主要包含5个部分:算法神经网络结构、基于focal-loss[29]优化的损失函数、倾斜的局部感知非极大值抑制网络(NMS)、基于可变尺度的图像分割优化、按比例尺切割训练样本。
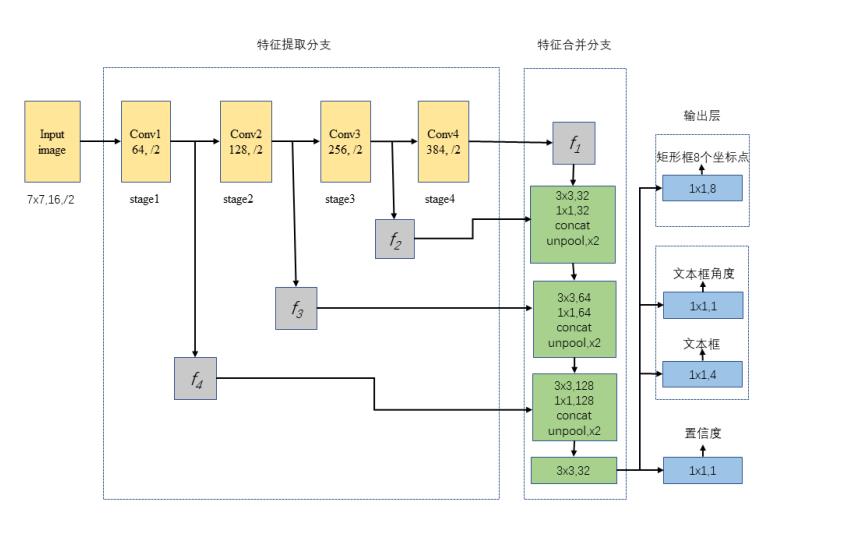
改进后的神经网络结构主要由特征提取分支、特征合并分支和输出层三个部分构成。
特征提取分支包含Conv1、Conv2、Conv3、Conv4四组卷积层,使用EAST算法在ImageNet数据集上进行训练,摘取其中部分的卷积神经网络层。其中f1、f2、f3为卷积层中的特征图。大小为原始输入图像的1/32、1/16、1/8、1/4。
在特征合并分支在每个合并阶段,将特征提取分支f1阶段的特征图输入到反池化层(unpool)中,输出图像为上一阶段输入图像的2倍 ;然后逐步合并,这一步操作会产生一部分计算代价。为提升算法效率,本文通过减少Conv1的通道数,接着合并局部卷积特征,通过Conv3进行操作输出到f3阶段中。在经过所有的特征合并阶段之后,将特征提取分支f4的输入结果输出到输出层当中。
输出层包含置信度、文本区域和文本区域旋转角度、包含8个坐标的矩形文本区域三个部分。最终的输出结果是1×1的卷积提取特征。
L为EAST算法的损失函数:
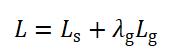
其中,表示分割图像背景和图像文本的分类损失,文本区域所在的部分表示1,非文本区域的背景部分表示0,即像素点的分类损失。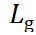 表示对应文本区域的像素点所组成的矩形框和矩形框角度的回归损失。
表示对应文本区域的像素点所组成的矩形框和矩形框角度的回归损失。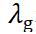 表示两个损失之间的相关性,作者在原EAST算法中将设置为1。
表示两个损失之间的相关性,作者在原EAST算法中将设置为1。
为了简化训练过程,分类损失使用平衡的交叉熵[31],公式如下:
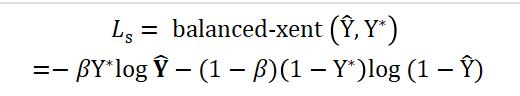
其中表示置信度的预测值,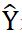 表示置信度的真实值,参数
表示置信度的真实值,参数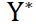 是调制系数,参数
是调制系数,参数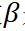 是调制系数,主要用来控制正负样本之间的比例。计算公式为:
是调制系数,主要用来控制正负样本之间的比例。计算公式为: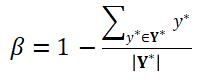
令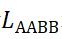 表示回归损失,旋转角度损失用
表示回归损失,旋转角度损失用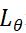 表示:
表示:
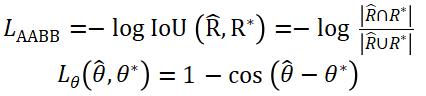
其中,预测出来的文本倾斜角度用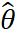 表示,而文本矩形框真实的倾斜角度则用
表示,而文本矩形框真实的倾斜角度则用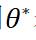 表示。让AABB表示从像素位置到文本矩形的上下左右4个边界的距离,令
表示。让AABB表示从像素位置到文本矩形的上下左右4个边界的距离,令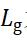 为回归损失和旋转角度损失加权和,合称为几何损失,计算公式如下:
为回归损失和旋转角度损失加权和,合称为几何损失,计算公式如下:
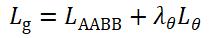
非极大值抑制简称NMS,简单理解就是局部最大搜索,主要应用于目标识别、目标检索、回归分析等方向。在图像文本定位过程中,分类器训练结束后会输出多个预测出来的文本矩形框,每个预测框都会有一个分数,但是绝大多数预测框会出现重叠的情况,所以NMS的主要作用就是在文本范围内去输出面积最大的矩形文本框,同时面积较小的文本预测框会收到抑制,得到最终结果。
标准NMS是直接取分数最高的预测框,而局部感知NMS则是基于邻近几个多边形是高度相关的假设,在标准NMS的基础上加了权重覆盖,就是将2个IoU(Intersection Over Union,交并比即重叠区域面积比例)[32]进行比较,首先设定一个面积为S的阈值,然后求两个预测框的交集,如果大于S则合并,反之则删除。经过合并后的预测框,其坐标位置相对于文本区域更加准确,不会浪费每一个预测框的信息,防止误差过大。
由于两个矩形文本框重叠的部分可以是任意多边形,计算重叠区域面积的难度较大。所以局部感知NMS一般采取简化的计算方式,将相交部分近似为一个矩形,每计算一次相当于计算矩形的顶点和坐标轴组成的梯形的面积。图中绿色的面积有四个点的坐标很容易求得。
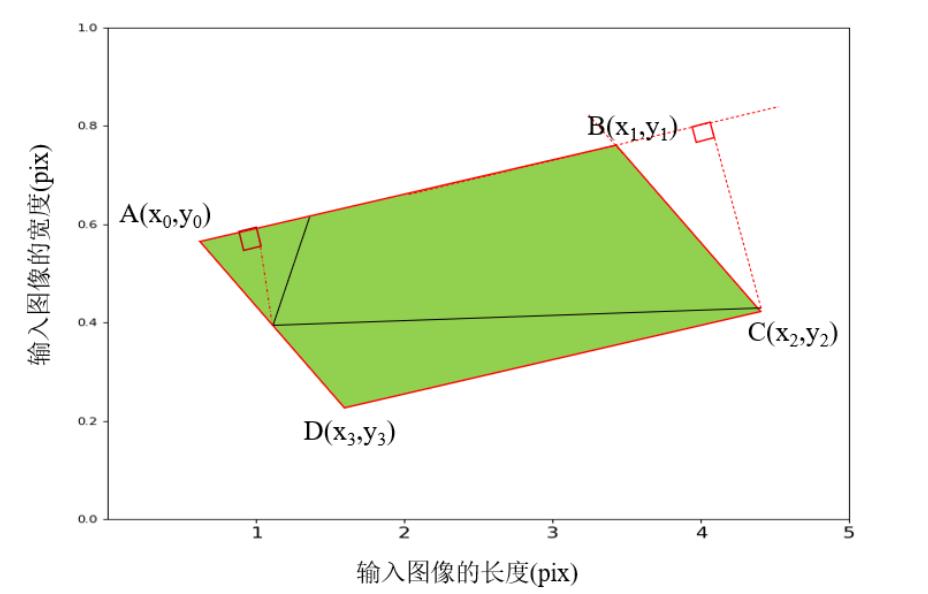
使用的图像数据集中包含有大量的倾斜文本(文本与水平形成夹角),所以本文在局部感知NMS的基础上增加了倾斜的NMS来处理这些倾斜文本,其基本步骤如下:
(1)对网络输出的旋转矩形文本检测框按照得分进行降序排列,并存储到一个降序列表里。
(2)依次遍历上述的降序列表,将当前的文本框和剩余的其它文本框进行交集计算的到相应的相交点集合。
(3)根据判断相交点集合组成的凸多边形的面积,计算每两个文本检测框的IOU(重叠区域面积比例);对于大于阈值的文本框进行过滤,保留小于阈值的文本框,并得到最终的文本矩形检测框。

最近实在疲惫不堪了 对于这两天发的博客 会进行完完全全认认真真地重新修改 复现代码也会展示最后如何运用到火车证身份证等新的场景。之后我会在此补充关于EAST和基于改进的EAST的文本检测的代码解释。
参考:https://blog.csdn.net/juluwangriyue/article/details/107295393
以上是关于基于改进EAST算法的文本检测的主要内容,如果未能解决你的问题,请参考以下文章