IP协议数据报格式详解
Posted oOoOoOooOO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IP协议数据报格式详解相关的知识,希望对你有一定的参考价值。
🐱🏍写博客的主要原因是为了巩固所学知识 🐱🏍
IP数据报格式
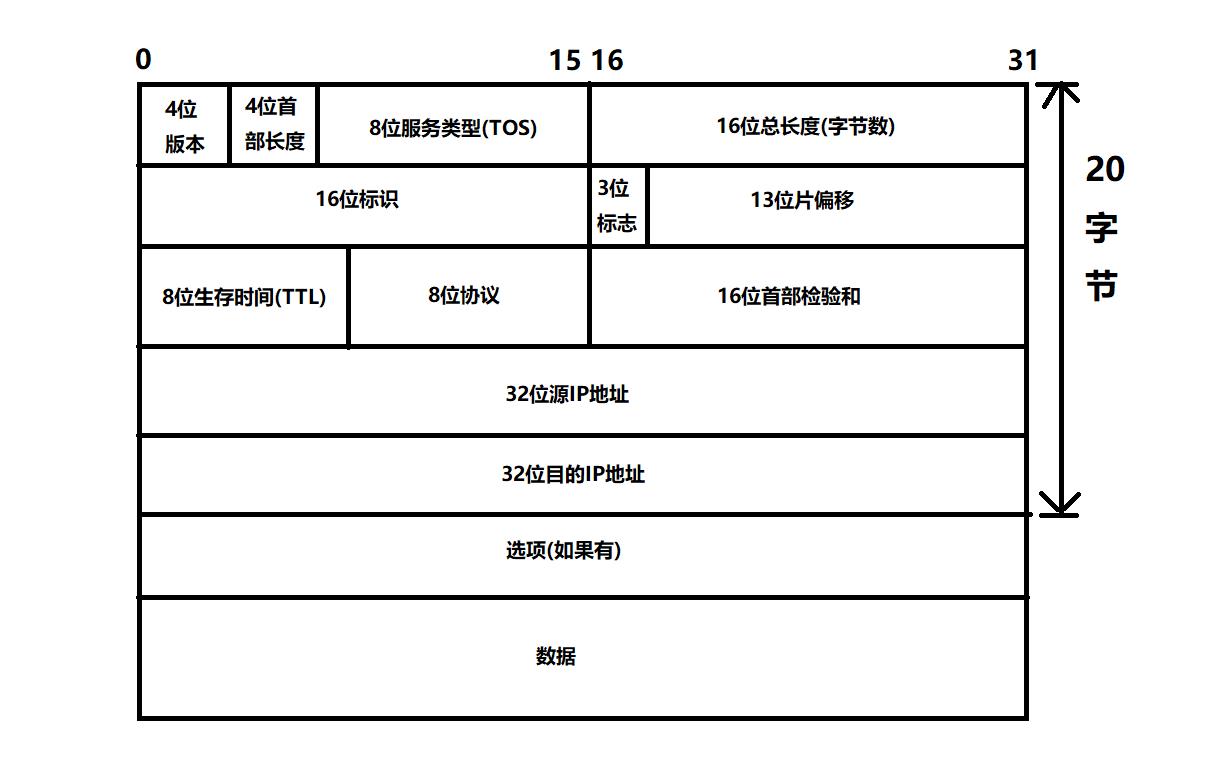
4位版本号(Version)
由4比特组成,用来指定IP协议的版本。IPv4的版本号为4,即0100。
4位首部长度(Header Length)
由4比特组成,表示IP协议的头部长度,用来作为header和payload之间的区分。单位为4字节,4比特位组成的最大的数为15,即1111,则header的最大长度则为60字节。其中固定长度(去掉选项)为20字节。
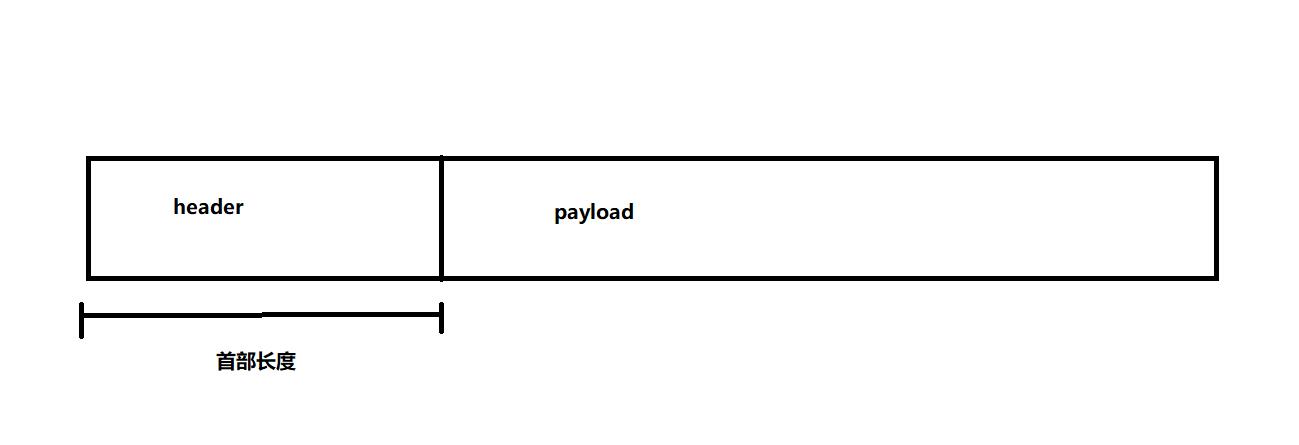
在数据报中,字节都是连续的。那么怎么区分header和payload呢?就是依靠4位首部长度。
8位服务类型(TOS:Type Of Service)
0~2位优先权字段(已经弃用),3~6位TOS字段,第7位保留字段(必须为0)。
TOS字段:
第3位: 最低延迟
第4位: 最大吞吐量
第5位: 最高可靠性
第6位: 最小成本
这四者互相冲突,只能选中的一个为1,其他的必须为0。不过现在几乎所有的网络都无视这些字段,是因为在符合质量要求的情况下按其要求发送本身的功能实现起来十分困难,还因为若不符合质量要求就可能会产生不公平的现象。
16位总字节长度(Total Length)
由16比特位组成,表示header和payload合起来的字节数。由于16比特组成最大的数为65536,所以IP数据报的最大长度为65535字节(64K),和UDP一样的大小。
那么IP数据报是如何传输大文件的呢?
虽然IP协议看起来也是有个最大64k的限制,但是实际上IP协议内置了分包组包的功能 如果一个数据太长了,协议就会自动的拆成多个数据包,进行传输,然后接受方就会重新进行组包。
16位标识(ID:Identification)
由16比特位组成,由于IP协议会对大的数据进行分片,同一个分片的标志位相同,接受发可用根据16位标识进行组包。但是若标识位相同,但协议、源IP地址或者目的IP地址不同,也会被认为是不同的分片。
3位标志段(Flags)
由3比特位组成,表示包被分片的相关信息。
第1位:保留字段(保留的意思是现在不用,以后可能会用到)。
第2位:指示是否进行分片(don't fragment)
如果该位为1,表示禁止分片。如果报文长度超过MTU(最大传输单元)后,
IP协议则丢弃该报文。
如果该位为0,表示可以分片,如果报文长度超过MTU(最大传输单元)后,
IP协议则会对其进行分片。
第3位:包被分片的情况下,表示是否为最后一个包。
0表示为最后一个分片的包。
1表示为分片中段的包。
13位分片偏移(framegament offset)
由13比特位组成,用来标识被分片的每一个分段相对于原始数据的位置。其实就是在表示当前分片在原始数据中处在哪个位置。
第一个分片的值为0,由于FO域占13位,因此最多可以表示 8192( = 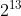 )个相对位置。单位为8字节,因此最大可表示原始数据 8×8192=65536字节的位置。
)个相对位置。单位为8字节,因此最大可表示原始数据 8×8192=65536字节的位置。
除了最后一个包之外,其他包的长度必须是8的整数倍(否则报文就不连续了)。
8位生存时间(TTL:Time To Live)
由8比特位组成,表示数据包到达目的地的最大报文跳数。它最初的意思是以秒为单位记录当前包的生存期限。在实际中它是指可以中转多少个路由器的意思。 每经过一个路由器,TTL会减少1,直到变成0则丢弃该包(TTL一般初始为64)。
可以在控制台输入 ping + 网址 获取到从本地到达目的地剩余的TTL
8位协议(Protocol)
由8比特位组成,表示上层协议类型。
TCP: 6
UDP: 17
16位首部校验和(Header Checksum)
由16比特位构成,用来校验数据报的首部,不校验数据部分。
为什么不对数据部分进行效验?
因为载荷部分就是一个完整的TCP/UDP数据报,由TCP和UDP本身进行效验即可。
计算方式:
首先要将该校验和的所有位置设置为0,然后以16比特为单位划分IP首部,并用1补数(1补数 通常计算机中对整数运算采用2补数的方式。但在校验和的计算中采用1补数运算方法。这样做的优点在于即使产生进位也可以回到第1位,可以防止信息缺失并且可以用2个0区分使用。) 计算所有16位字的和。最后将所得到这个和的1补数 赋给首部校验和字段。
源地址(Source Address)
由32比特位构成,表示发送端IP地址。
目标地址(Destination Address)
由32比特位构成,表示接收端IP地址。
选项
长度可变,通常只在进行实验或诊断时使用。
数据
一个完整的上层数据报。

以上是关于IP协议数据报格式详解的主要内容,如果未能解决你的问题,请参考以下文章