分布式中间件之Kafka
Posted 田青钊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式中间件之Kafka相关的知识,希望对你有一定的参考价值。
安装kafka
下载地址
https://kafka.apache.org/documentation
解压
tar -zxvf kafka_2.12-2.4.1 -C /usr/local/
进入到config目录,编辑 server.properties 配置文件
# 每个broker节点的id,集群架构下要唯一
broker.id = 0
# kafka对外提供的ip和端口号
#listeners=PLAINTEXT://:9092 # 这是系统默认的
# 这里的ip要使用内网的,也就是ifconfig查看出来的
listeners=PLAINTEXT://内网ip:9092
# 外部代理地址,比如java代码使用客户端操作连接kafka服务器
advertised.listeners=PLAINTEXT://外网ip:9092
# 消息存储的目录
log.dirs=/usr/local/kafka_2.12-2.4.1/data
# zookeeper地址
zookeeper.connect=localhost:2181
# 消息保留的时间,单位为小时,默认为7天
log.retention.hours=168
启动kafka:
./bin/kafka-server-start.sh config/server.properties &
#或者
./bin/kafka-server-start.sh -daemon config/server.properties
查看是否启动成功
jps或者 ps -ef | grep kafka
Kafka核心组件
Broker
一个kafka节点就是一个broker,一个broker或者多个broker可以组成一个集群。(1台机器也是集群)
Topic
消息的主题,发送到kafka的每条消息都需要指定一个主题。
Producer
消息的生产者,向Broker发送消息的客户端。
Consumer
消息的消费者,从Broker消费消息的客户端。
ConsumerGroup
每个Consumer都可以指定一个ConsumerGroup,一条消息可以被不同的ConsumerGroup的Consumer进行消费,
但是一个ConsumerGroup中只有一个Consumer能够消费该消息。
Partition
物理概念,一个topic可以可以分为多个partition,每个partition内部消息是有序的。
命令行操作kafka
操作topic
# 把元信息数据存储到zk中,真正队列的数据还是存储在kafka的broker中
# --partitions为分区数量,默认也是1个分区 --topic test为指定topic的名称
./bin/kafka‐topics.sh ‐‐create ‐‐zookeeper localhost:2181 ‐‐replication‐factor 1 ‐‐partitions 1 ‐‐topic test
# 查询有哪些topic
./bin/kafka-topics.sh --list --zookeeper localhost:2181
# 删除一个topic
./bin/kafka‐topics.sh ‐‐delete ‐‐topic test ‐‐zookeeper localhost:2181
# 查看topic的情况
./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
使用producer生产者发送一条消息
# 这里的ip为内网ip
./bin/kafka-console-producer.sh --broker-list ip:9092 --topic test
出现下面这个界面表示生产者启动成功

可直接输入要发送的内容。
使用consumer消费者消费一条消息
# 这里的ip为内网ip,该命令只能消费该消费者启动成功之后生产者发送的消息
./bin/kafka-console-consumer.sh --bootstrap-server ip:9092 --topic test
# 消费生产者所有的消息,只需要在上面的命令加上 --from-beginning
# kafka消费完之前的消息不会立马删除,还会在磁盘的文件里面存在,默认保留一周,这是与传统消息中间件不同之一
./bin/kafka-console-consumer.sh --bootstrap-server ip:9092 --from-beginning --topic test
# 消费多个主题的消息,加上 --whitelist "topic1|topic2",每个主题中间用管道符 相隔
./bin/kafka‐console‐consumer.sh ‐‐bootstrap‐server ip:9092 ‐‐whitelist "test|test‐2"
每个消费者会记录上一次消费消息的偏移量,等下一次启动消费的时候从上一次的偏移量的下一条消息开始消费。
consumer-group
一个消费组可以有多个消费者。
单播消息
# 通过 --consumer-property group.id=testGroup 来进行指定消费者组名
./bin/kafka‐console‐consumer.sh ‐‐bootstrap‐server ip:9092 ‐‐consumer‐property group.id=testGroup ‐‐topic test
使用该命令打开两个窗口,只能被其中一个窗口的消费者消费。也就是说只能被同一个消费组下面的某一个消费者消费,类似于Queue模式。
多播消息
# 通过 --consumer-property group.id=testGroup 来进行指定消费者组名
./bin/kafka‐console‐consumer.sh ‐‐bootstrap‐server ip:9092 ‐‐consumer‐property group.id=testGroup2 ‐‐topic test
创建两个不同的消费组名称即可,也就是再创建一个testGroup2的消费组。每个消费组都可以消费到消息。类似于发布订阅的模式。
查看所有消费组
./bin/kafka-consumer-groups.sh --bootstrap-server ip:9092 --list
查看消费组的偏移量
./bin/kafka-consumer-groups.sh --bootstrap-server ip:9092 --describe --group testGroup
- GROUP:消费组名称
- TOPIC:主题名称
- PARTITION:分区名称,默认1个分区
- CURRENT-OFFSET:当前已消费的偏移量
- LOG-END-OFFSET:消息末尾的偏移量
- LAG:剩余未消费的消息数量
- CONSUMER-ID:消费者的id
- HOST:主机地址
- CLIENT-ID:

partition
创建多个分区的topic
##### --partitions 后面的参数为分区的数量
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic test1
- 创建完成之后查看该topic的情况,可以看到PartitionCount为2,也就是上面我们指定的分区数量

- 查看我们配置的log.dir文件夹目录下面,可以看到每个topic下面的分区对应一个文件夹

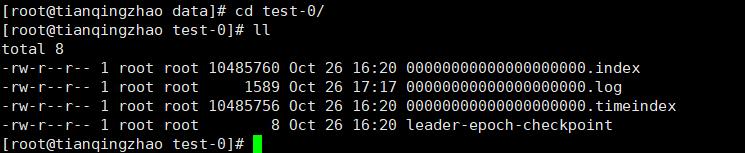
- 进入到test-0,可以看到当前分区的文件内容,以
.log文件结尾的文件就是消息日志存储的文件
扩容topic的分区数量
./bin/kafka‐topics.sh ‐alter ‐‐partitions 3 ‐‐zookeeper localhost:2181 ‐‐topic test
# 重新查看该topic的情况
./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
扩容主题的分区数量并重新查看主题情况,可以看到分区已经是3个了。

Kafka集群
这里使用单机搭建kafka集群,只需拷贝两份 server.properties 配置文件即可,在原先的kafka上面增加两个节点即可。
节点2的 server.properties 配置文件:
# 每个broker节点的id,集群架构下要唯一
broker.id = 1
# kafka对外提供的ip和端口号
#listeners=PLAINTEXT://:9092 # 这是系统默认的
# 这里的ip要使用内网的,也就是ifconfig查看出来的
listeners=PLAINTEXT://ip:9093
# 外部代理地址,比如java代码使用客户端操作连接kafka服务器
advertised.listeners=PLAINTEXT://外网ip:9093
# 消息存储的目录
log.dirs=/usr/local/kafka_2.12-2.4.1/data2
# zookeeper地址
zookeeper.connect=localhost:2181
节点3的 server.properties 配置文件:
# 每个broker节点的id,集群架构下要唯一
broker.id = 2
# kafka对外提供的ip和端口号
#listeners=PLAINTEXT://:9092 # 这是系统默认的
# 这里的ip要使用内网的,也就是ifconfig查看出来的
listeners=PLAINTEXT://ip:9094
# 外部代理地址,比如java代码使用客户端操作连接kafka服务器
advertised.listeners=PLAINTEXT://外网ip:9094
# 消息存储的目录
log.dirs=/usr/local/kafka_2.12-2.4.1/data3
# zookeeper地址
zookeeper.connect=localhost:2181
主要更改 broker.id、listeners、log.dirs 这三个属性。
kafka的集群是通过zookeer的地址去判断的,zookeeper的地址一样,后面的节点都会水平扩容到原先的集群上面去。
然后分别启动这里两个节点,带上这两个配置文件。
启动完成之后创建一个新的topic
# --replication-factor 3 指定副本为3个,每个分区都分别对应3个副本
# --partitions 2 分区为2个
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic my-replication-topic
可以看到两个分区分散在两个broker节点上面,防止其中一个节点挂掉了,另外一个节点可以继续提供工作。
这3个副本有一个leader和两个follower,Learder:0表示这三个副本的主节点所在的broker的id。

- Partition:分区
- Leader:该partition的Learder节点所在的broker节点的id
- Replicas:该partition在哪几个broker上备份着,不管是不是leader都会显示出来
- Isr:以存活着的节点的broker.id,这里只显示已备份该partition的节点的broker.id
停掉broker.id为1的节点,再来查看该topic的情况,此时分区1的Leader已经发生了变化,重新选举了brokder.id为2的作为了leader,Isr也没有之前的broker.id为1那台机器。Replicas副本位于哪几台机器上面是不会变化的。

一个分区的消息可以被不同的消费组的某一个消费者消费,一个消费者可以消费不同分区的消息。
kafka在同一个partition内可以保证消息的消费顺序,不能在多个partition中保证总的消息消费顺序。每个partition会维护自己的offset。
如果需要保证总体上的顺序,只能将partition设置为,同时消费组里面设置1个consumer,这样性能会低,所以kafka的顺序消费很少用。
一个消费组中的消费者不能比分区数量多,否则多出来的消费者会消费不到消息。
Java 使用 Kafka
1.原生api方式
pom依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
生产者
public class Producer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
// 如果当前连接的kafka配置了集群,只需要注册一个就可以,他会自动把当前集群里面所有的节点注册进来。
// 一般情况下为了高可用,还是在这里多注册两个节点,以防某一个节点挂掉了,其他的也注册不上。
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"ip:9092,ip:9093,ip:9094");
// key 序列化
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 宕机的情况下重试几次,默认为3此
// properties.setProperty(ProducerConfig.RETRIES_CONFIG,"3");
// 每次重试间隔时间,单位毫秒
// properties.setProperty(ProducerConfig.RETRY_BACKOFF_MS_CONFIG,"100");
//生产者每次批量发送消息的大小,默认16kb,一定要配合下面的 linger.ms 参数使用
// properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"10");
// 生产者缓存数据到一定时间发送,默认时间为0毫秒(单位毫秒),kafka作者建议8-10毫秒
// properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"0");
// 压缩的类型,一共四种类型(none、gzip、snappy、lz4),一般情况下用第三个,使用压缩的会降低性能
// properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
//client.id,此参数也可以不配置,代表消息从哪里来(在发出请求时传递给服务器的id字符串。
// 这样做的目的是通过允许在服务器端请求日志中包含逻辑应用程序名称,从而能够跟踪ip/端口之外的请求源。)
// properties.setProperty(ProducerConfig.CLIENT_ID_CONFIG, "");
// 在阻塞之前,客户机在单个连接上发送的未确认请求的最大数目。请注意,如果此设置设置为大于1且发送失败,则由于重试(即,如果启用重试)
// properties.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "");
// 自定义分区管理器(分区就是存储数据所在的文件夹)
// properties.setProperty("partitioner.class",MyPartitioner.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 11; i <= 20; i++) {
// ProducerRecord<String, String> record = new ProducerRecord<String, String>("topic2", 0,"key" + i,"hello world" + i);
// 未指定分区,使用 hash(key) % partition 来选择分区。核心代码 `Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions`
ProducerRecord<String, String> record = new ProducerRecord<String, String>("my-replication-topic","key" + i, "hello world" + i);
// 使用的并发编程 `Future` ,异步发送,拿结果还是同步的。
// 也就是消息发送不成功,这里一直会阻塞
Future<RecordMetadata> send = kafkaProducer.send(record);
// 异步回调拿结果,假如下面有其他业务逻辑可以先行处理。比如扣减库存。
/*kafkaProducer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
}
});*/
// TODO 扣减库存的逻辑
// 拿到发送者的相关信息
RecordMetadata recordMetadata = send.get();
String sendTargetTopic = recordMetadata.topic();
long sendTargetOffset = recordMetadata.offset();
int sendTargetPartition = recordMetadata.partition();
System.out.println(
"发送的主题:" + sendTargetTopic + ", 偏移量:" + sendTargetOffset + ", 分区:" + sendTargetPartition);
}
kafkaProducer.flush();
// 优雅关闭,关闭之后kafka会有个心跳机制,默认10秒,
// 如果还没有连接上就认为当前生产者宕机了,然后重新进行分区负载均衡
kafkaProducer.close();
}
}
消费者
public class Consumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9092,ip:9093,ip");
// 反序列化器
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 反序列化器
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 关闭自动提交,默认值为true。true表示自动提交,也就是消费过的消息不再重复消费。false会一直重复消费。
// 配置true的话下一次消费会从最后消费的下一个偏移量去进行消费。
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 自动提交的间隔时间
properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 定义消费者群组
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "1111");
// 最小拉取消息的大小,默认1字节,一般配合下面的时间参数一起使用
// properties.setProperty(ConsumerConfig.FETCH_MIN_BYTES_CONFIG,"1");
// 最久等待数据时间
// properties.setProperty(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG,"500");
//最大拉取消息的大小,一般也是配合时间使用,默认50MB(50 * 1024 * 1024)
// properties.setProperty(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, "50");
// 从每个分区里面所能读取到的最大字节数,默认为1MB(1 * 1024 * 1024)
// properties.setProperty(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG,"1");
// 消费者定时发送心跳/多久没有发送心跳kafka判断消费者死亡,默认值为10秒(10000ms,单位毫秒),一般配合下面参数使用
// properties.setProperty(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "10000");
// 发送心跳的间隔时间,默认3秒(3000ms,单位也是毫秒)
// properties.setProperty(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, "1000");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
String topicName = "my-replication-topic";
// 绑定主题。注意:subscribe和assign方法只能是用一个
// kafkaConsumer.subscribe(Collections.singletonList(topicName));
// 指定分区消费
// kafkaConsumer.assign(Collections.singletonList(new TopicPartition(topicName, 0)));
// 从头开始消费,对应from-beginning命令
// kafkaConsumer.assign(Collections.singletonList(new TopicPartition(topicName, 0)));
// kafkaConsumer.seekToBeginning(Collections.singletonList(new TopicPartition(topicName, 0)));
// 指定offset消费
// kafkaConsumer.assign(Collections.singletonList(new TopicPartition(topicName, 0)));
// kafkaConsumer.seek(new TopicPartition(topicName, 0), 10);
// 消费1小时之前的数据
List<PartitionInfo> partitions = consumer.partitionsFor(topicName);
long fetchDateTime = new Date().getTime() - 60 * 60 * 1000;
Map<TopicPartition, Long> partitionLongMap = new HashMap<>(10);
for (PartitionInfo partitionInfo : partitions) {
partitionLongMap.put(new TopicPartition(topicName, partitionInfo.partition()), fetchDateTime);
}
// 根据时间戳找分区的偏移量,并从该偏移量往后面去进行消费
Map<TopicPartition, OffsetAndTimestamp> map = consumer.offsetsForTimes(partitionLongMap);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : map.entrySet()) {
TopicPartition topicPartition = entry.getKey();
OffsetAndTimestamp offsetAndTimestamp = entry.getValue();
if (topicPartition == null || offsetAndTimestamp == null) {
continue;
}
// 得到分区
int partition = topicPartition.partition();
// 得到偏移量
long offset = offsetAndTimestamp.offset();
System.out.println("分区:" + partition + ",偏移量:" + offset);
// 最终还是根据分区和偏移量消费消息
consumer.assign(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, offset);
}
try {
//拉取消息
while (true) {
// 参数为每间隔多久拉取一次
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
//偏移量是根据同一个分区里面的偏移量递增的
System.out.println(
"消息所在分区:" + consumerRecord.partition() + ",消息的偏移量:" + consumerRecord.offset() + ",key:"
+ consumerRecord.key() + ",value:" + consumerRecord.value());
}
// 同步提交偏移量,当前线程阻塞,直至消息提交完成之后处理后面的业务逻辑。
consumer.commitSync();
// 异步提交偏移量(可能会有消息丢失的情况)。也就是不管当前消费的消息是否提交了offset,都不会阻塞,可以继续处理后面的业务逻辑。
/*kafkaConsumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (null != exception) {
System.out.println("error offset:" + offsets);
System.out.println("error stackTrace:" + exception.getStackTrace());
}
}
});*/
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
2.Spring Boot方式
pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tqz</groupId>
<artifactId>kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.1</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
application.properties配置
spring.application.name=kafka-service
### 服务端地址
spring.kafka.bootstrap-servers=ip:9092,ip:9093,ip:9094
### 生产者配置
### 等leader写成功,不要等follower写成功就可以发送下一条消息
spring.kafka.producer.acks=1
#重试次数
spring.kafka.producer.retries=3
### kafka会从本地缓冲区取数据,批量发送到broker,设置批量发送的大小,默认值是16384,即16kb。也就是说一个batch满了16kb就发送出去。
spring.kafka.producer.batch-size=16384
### 生产者可用于缓冲等待发送到服务器的记录的总内存字节数,设置了该缓冲区,消息会先缓存到本地,可以提高消息发送的性能。默认值是32MB,即 33554432
spring.kafka.producer.buffer-memory=33554432
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
### 消费者配置
### 消费者组名
spring.kafka.consumer.group-id=myGroup
### 是否自动提交,true表示自动提交。false关闭自动提交,会一直重复消费。
spring.kafka.consumer.enable-auto-commit=false
### 当Kafka中没有初始偏移量或者服务器上不再存在当前偏移量时该怎么办,默认值为latest,表示自动将偏移重置为最新的偏移量。可选的值为latest, earliest, none
spring.kafka.consumer.auto-offset-reset=latest
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.listener.ack-mode=manual_immediate
# RECORD 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# BATCH 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# TIME 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# COUNT 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# TIME 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT_TIME TIME或COUNT有一个条件满足时提交
# MANUAL 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL_IMMEDIATE 手动调用Acknowledgment.acknowledge()后立即提交
生产者
/**
* <p>发送消息的控制器
*
* @author tianqingzhao
* @since 2021/10/28 13:50
*/
@RestController
public class ProducerController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
private static final String TOPIC_NAME = "my-replication-topic";
@RequestMapping("send以上是关于分布式中间件之Kafka的主要内容,如果未能解决你的问题,请参考以下文章