SQL调优指南笔记5:Query Transformations
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL调优指南笔记5:Query Transformations相关的知识,希望对你有一定的参考价值。
本文为SQL Tuning Guide第5章“查询转换”的笔记。
优化器根据成本决定是否使用转换。 由于各种原因,包括提示或缺乏约束,优化器可能无法使用转换。 例如,子查询取消嵌套等转换不适用于包含不支持约束的外部分区的混合分区表。
本章介绍的各种转换,都是由优化器自动决定是否使用。下面的介绍和示例只是让读者了解其原理和使用场景。
5.1 OR Expansion
在 OR 扩展中,优化器将包含顶级析取(disjunction)的查询块转换为包含两个或多个分支的 UNION ALL 查询的形式。
优化器通过将析取拆分为其组件,然后将每个组件与 UNION ALL 查询的一个分支相关联来实现此目标。 优化器可以出于各种原因选择 OR 扩展。 例如,它可以启用更有效的访问路径或避免笛卡尔积的替代连接方法。 与往常一样,仅当转换后的语句的成本低于原始语句的成本时,优化器才会执行扩展。
来看一个例子,转换前的SQL如下:
SELECT *
FROM employees e, departments d
WHERE (e.email='SSTILES' OR d.department_name='Treasury')
AND e.department_id = d.department_id;
(e.email='SSTILES' OR d.department_name='Treasury')这一部分就称为顶级析取,虽然e.email和d.department_name列上各自有索引,但放在一起就只能全部扫描了。
因此拆分成如下,以利用两个索引:
SELECT *
FROM employees e, departments d
WHERE e.email = 'SSTILES'
AND e.department_id = d.department_id
UNION ALL
SELECT *
FROM employees e, departments d
WHERE d.department_name = 'Treasury'
AND e.department_id = d.department_id;
5.2 View Merging
在视图合并中,优化器将表示视图的查询块合并到包含它的查询块中。
视图合并可以通过使优化器考虑额外的连接顺序、访问方法和其他转换来改进计划。 例如,在合并视图并且多个表驻留在一个查询块中之后,视图内的表可能允许优化器使用联接消除来删除视图外的表。
5.2.1 Query Blocks in View Merging
优化器通过单独的查询块表示每个嵌套的子查询或未合并的视图。
数据库自下而上分别优化查询块。 因此,数据库首先优化最内层的查询块,为其生成部分计划,然后再为外层的查询块生成计划,代表整个查询。
解析器将查询中引用的每个视图扩展为单独的查询块。 块本质上代表视图定义,因此代表视图的结果。
5.2.2 Simple View Merging
转换前:
SELECT e.first_name, e.last_name, dept_locs_v.street_address,
dept_locs_v.postal_code
FROM employees e,
( SELECT d.department_id, d.department_name,
l.street_address, l.postal_code
FROM departments d, locations l
WHERE d.location_id = l.location_id ) dept_locs_v
WHERE dept_locs_v.department_id = e.department_id
AND e.last_name = 'Smith';
转换后:
SELECT e.first_name, e.last_name, l.street_address, l.postal_code
FROM employees e, departments d, locations l
WHERE d.location_id = l.location_id
AND d.department_id = e.department_id
AND e.last_name = 'Smith';
5.2.3 Complex View Merging
在视图合并中,优化器合并包含 GROUP BY 和 DISTINCT 的视图。 与简单视图合并一样,复杂的合并使优化器能够考虑额外的连接顺序和访问路径。
示例略,请参看原文。
5.3 Predicate Pushing
在谓词推送中,优化器将相关谓词从包含查询块“推送”到视图查询块中。
例如原SQL为:
SELECT last_name
FROM all_employees_vw
WHERE department_id = 50;
转换后为:
SELECT last_name
FROM ( SELECT employee_id, last_name, job_id, commission_pct, department_id
FROM employees
WHERE department_id=50
UNION
SELECT employee_id, last_name, job_id, commission_pct, department_id
FROM contract_workers
WHERE department_id=50 );
5.4 Subquery Unnesting
在子查询解嵌套中,优化器将嵌套查询转换为等效的连接语句,然后优化连接。
这种转换使优化器能够在访问路径、连接方法和连接顺序选择期间考虑子查询表。 仅当结果连接语句保证返回与原始语句相同的行,并且子查询不包含聚合函数(如 AVG)时,优化器才能执行此转换。
例如原SQL为:
SELECT *
FROM sales
WHERE cust_id IN ( SELECT cust_id
FROM customers );
转换后为:
SELECT sales.*
FROM sales, customers
WHERE sales.cust_id = customers.cust_id;
5.5 Query Rewrite with Materialized Views
物化视图是存储在表中的查询结果。
当优化器发现与物化视图关联的查询兼容的用户查询时,数据库可以根据物化视图重写查询。 该技术改进了查询执行,因为数据库已经预先计算了大部分查询结果。
优化器寻找与用户查询兼容的物化视图,然后使用基于成本的算法选择物化视图来重写查询。 除非基于物化视图计划成本较低,否则优化器不会在生成计划时重写查询。
5.5.1 About Query Rewrite and the Optimizer
优化器使用两种不同的方法来确定何时根据物化视图重写查询。 第一种方法将查询的 SQL 文本与物化视图定义的 SQL 文本进行匹配。 如果第一种方法失败,则优化器会使用更通用的方法,在该方法中比较查询和物化视图之间的联结、选择、数据列、分组列和聚合函数。
维度、约束和重写完整性级别会影响是否重写查询以使用物化视图。 此外,可以通过 REWRITE 和 NOREWRITE 提示以及 QUERY_REWRITE_ENABLED 会话参数启用或禁用查询重写。
DBMS_MVIEW.EXPLAIN_REWRITE 过程建议是否可以对查询进行查询重写,如果可以,则建议使用哪些物化视图。 它还解释了为什么不能重写查询。
5.5.2 About Initialization Parameters for Query Rewrite
查询重写相关初始化参数包括:
- OPTIMIZER_MODE
- QUERY_REWRITE_ENABLED
- QUERY_REWRITE_INTEGRITY
5.5.3 About the Accuracy of Query Rewrite
查询重写提供了三个级别的重写完整性,它们由初始化参数 QUERY_REWRITE_INTEGRITY 控制。
您可以为 QUERY_REWRITE_INTEGRITY 参数设置的值如下:
- ENFORCED,默认,要求视图的数据与基表是同步的,也就是数据是最新的。优化器仅使用强制主键约束和参照完整性约束来确保查询结果与直接访问物化视图时的结果相同。
- TRUSTED,在 TRUSTED 模式下,优化器相信维度和 RELY 约束中声明的关系是正确的。仍有生成不准确结果的风险。
- STALE_TOLERATED,允许视图中有陈旧数据。此模式提供最大的重写能力,但带来生成不准确结果的风险。
5.5.4 Example of Query Rewrite
可参考Oracle开发者性能课第6课(如何创建物化视图)实验
5.6 Star Transformation
星型转换是一种优化器转换,可避免对星型模式中的事实表进行全表扫描。
5.6.1 About Star Schemas
星型模式将数据划分为事实和维度。
事实是对诸如销售之类的事件的度量,通常是数字。 维度是标识事实的类别,例如日期、位置和产品。
事实表具有由维度表的主键组成的组合键。
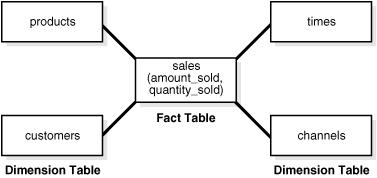
5.6.2 Purpose of Star Transformations
在事实表和维度表的连接中,星型转换可以避免对事实表进行全表扫描。
星形转换通过仅获取联结到约束维度行的相关事实行来提高性能。 在某些情况下,查询对维度表的其他列具有限制性过滤器。 过滤器的组合可以显著减少数据库从事实表中处理的数据集。
5.6.3 How Star Transformation Works
星型转换增加了子查询谓词,称为位图半连接谓词,对应于约束维度。
当事实连接列上存在索引时,优化器会执行转换。 通过驱动子查询提供的键值的位图 AND 和 OR 操作,数据库只需要从事实表中检索相关行。 如果维度表上的谓词过滤掉了大部分数据,那么转换可能比对事实表进行全表扫描更有效。
5.6.4 Controls for Star Transformation
STAR_TRANSFORMATION_ENABLED初始化参数。默认为禁用。
5.6.5 Star Transformation: Scenario
以下SQL中,sales是事实表:
SELECT c.cust_city,
t.calendar_quarter_desc,
SUM(s.amount_sold) sales_amount
FROM sales s,
times t,
customers c,
channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = 'CA'
AND ch.channel_desc = 'Internet'
AND t.calendar_quarter_desc IN ('1999-01','1999-02')
GROUP BY c.cust_city, t.calendar_quarter_desc;
转换后:
SELECT c.cust_city, t.calendar_quarter_desc, SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND c.cust_state_province = 'CA'
AND t.calendar_quarter_desc IN ('1999-01','1999-02')
AND s.time_id IN ( SELECT time_id
FROM times
WHERE calendar_quarter_desc IN('1999-01','1999-02') )
AND s.cust_id IN ( SELECT cust_id
FROM customers
WHERE cust_state_province='CA' )
AND s.channel_id IN ( SELECT channel_id
FROM channels
WHERE channel_desc = 'Internet' )
GROUP BY c.cust_city, t.calendar_quarter_desc;
对于渠道、时间和客户子查询产生的每个键值,数据库从销售事实表的索引(这个索引需要提前建立吗?)中检索位图 .
位图中的每一位对应于事实表中的一行。 当来自子查询的键值与事实表行中的值相同时,设置该位。 也就是说,通过多个bitmap的与操作,确定事实表中的行是否满足条件。
5.6.6 Temporary Table Transformation: Scenario
在上一个场景中,优化器不会将表 channels 联结回 sales 表,因为它没有被外部引用(没有出现在select列表中)并且 channel_id 是唯一的。
但是,如果优化器无法消除回联,则数据库将子查询结果存储在临时表中,以避免为位图键生成和回联重新扫描维度表。 此外,如果查询并行运行,则数据库将结果物化,以便每个并行执行服务器可以从临时表中选择结果,而不是再次执行子查询。
5.7 In-Memory Aggregation (VECTOR GROUP BY)
内存聚合优化的关键是边扫描边聚合。
为了优化涉及从单个大表到多个小表的聚合和联接的查询块,例如在典型的星型查询中,转换使用 KEY VECTOR 和 VECTOR GROUP BY 操作。 这些操作使用高效的内存中数组进行联结和聚合,当表是内存中的列式表时尤其有效(也就是说,此优化也支持没有发布到IMCS中的表)。
此优化的前提是有联结,有聚合,表已发布到内存列式存储(IMCS)中,优化器会决定是否进行此优化。
5.8 Cursor-Duration Temporary Tables
为了实现查询的中间结果,Oracle 数据库可能会在查询编译期间在内存中隐式创建一个游标持续时间临时表。
5.8.1 Purpose of Cursor-Duration Temporary Tables
复杂查询有时会多次处理同一个查询块,这会产生不必要的性能开销。
为了避免这种情况,Oracle 数据库可以自动为查询结果创建临时表,并在游标期间将它们存储在内存中。 对于 WITH 子句查询、星形转换和分组集等复杂操作,此优化增强了重复使用子查询的中间结果的物化。 通过这种方式,游标持续时间临时表提高了性能并优化了 I/O。
5.8.2 How Cursor-Duration Temporary Tables Work
游标定义临时表的定义驻留在内存中。 表定义与游标相关联,并且仅对执行游标的会话可见。
5.8.3 Cursor-Duration Temporary Tables: Example
重复相同子查询的 WITH 查询有时可以从游标持续时间临时表中受益。
体现在执行计划中的关键字为TEMP TABLE TRANSFORMATION和CURSOR DURATION MEMORY。
5.9 Table Expansion
在表扩展中,优化器生成一个计划,该计划在分区表的主要读取部分上使用索引。
5.9.1 Purpose of Table Expansion
基于索引的计划可以提高性能,但索引维护会产生开销。 在许多数据库中,DML 只影响一小部分数据。
表扩展对高更新表使用基于索引的计划。 您可以仅在读取最多的数据上创建索引,从而消除活动数据上的索引开销。 这样,表扩展提高了性能,同时避免了索引维护。
5.9.2 How Table Expansion Works
表分区使表扩展成为可能。
如果分区表上存在本地索引,则优化器可以将该索引标记为对特定分区不可用。 实际上,某些分区未编入索引。
在表扩展中,优化器将查询转换为 UNION ALL 语句,其中一些子查询访问索引分区,其他子查询访问未索引分区。 优化器可以为分区选择最有效的访问方法,无论查询中访问的所有分区是否都存在该方法。
5.9.3 Table Expansion: Scenario
优化器根据查询中出现的谓词跟踪每个表中必须访问的分区。 分区修剪使优化器能够使用表扩展来生成更优化的计划。
这个例子使用SH Schema中的分区表sales,将查询涉及到的多个分区中的一个上的索引置为unusable(优化器不再考虑此分区上的索引)。最终表扩展的效果为:优化器会对此分区使用全表扫描,而其它分区仍使用索引。
以下为禁用索引的SQL:
ALTER INDEX sales_prod_bix MODIFY PARTITION sales_q4_2003 UNUSABLE;
ALTER INDEX sales_time_bix MODIFY PARTITION sales_q4_2003 UNUSABLE;
以下为重新使索引可用的SQL:
ALTER INDEX sales_prod_bix REBUILD PARTITION sales_q4_2003;
ALTER INDEX sales_time_bix REBUILD PARTITION sales_q4_2003;
5.9.4 Table Expansion and Star Transformation: Scenario
此优化仍需要基于分区表。
星型转换使特定类型的查询能够避免访问大事实表的大部分。
星型转换需要定义多个索引,这些索引在频繁更新的表中可能会产生开销。 通过表扩展,您可以仅在非活动分区上定义索引,以便优化器可以仅在表的索引部分考虑星型转换。
5.10 Join Factorization
在称为联结分解的基于成本的转换中,优化器可以分解来自 UNION ALL 查询分支的常见计算。
5.10.1 Purpose of Join Factorization
UNION ALL 查询在数据库应用程序中很常见,尤其是在数据集成应用程序中。
通常,UNION ALL 查询中的分支引用相同的基表。 如果没有连接分解,优化器会独立评估 UNION ALL 查询的每个分支,这会导致重复处理,包括数据访问和联结。 联结分解转换可以跨 UNION ALL 分支共享公共计算。 避免对大型基表进行额外扫描以带来巨大的性能提升。
5.10.2 How Join Factorization Works
参见原文示例。
5.10.3 Factorization and Join Orders: Scenario
参见原文示例。
5.10.4 Factorization of Outer Joins: Scenario
参见原文示例。
以上是关于SQL调优指南笔记5:Query Transformations的主要内容,如果未能解决你的问题,请参考以下文章
SQL调优指南笔记1:Introduction to SQL Tuning