学习笔记Python - Beautiful Soup
Posted SAP剑客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Python - Beautiful Soup相关的知识,希望对你有一定的参考价值。
Beautiful Soup
Beautiful Soup是一个模块,用于从html页面中提取信息(类似于正则表达式的功能)。Beautiful Soup的模块名称是“bs4”(表示Beautiful Soup的第4版)。
安装Beautiful Soup
命令:pip install beautifulsoup4
导入:import bs4

使用Beautiful Soup
1、根据HTML创建一个Beautiful Soup对象
bs4.BeautifulSoup()函数调用时需要一个字符串,其中包含了将要解析的HTML文件。
bs4.BeautifulSoup()函数返回一个BeautifulSoup对象。
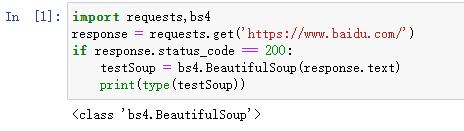
当然bs4.BeautifulSoup()函数也可以从本地读入HTML文件,前提是在本地保存了HTML文件,它会返回一个BeautifulSoup对象。
2、使用select()方法寻找元素
选择器就好比正则表达式,它们指定了要寻找的模式,就可以取得Web页面元素。
| 传递给select()方法的选择器 | 将要匹配... |
| soup.select(‘div’) | 所有名为<div>的元素 |
| soup.select(‘#author’) | 带有id属性为author的元素 |
| soup.select(‘.notice’) | 所有使用CSS class属性名为notice的元素 |
| soup.select(‘div span’) | 所以在<div>元素之内的<span>元素 |
| soup.select(‘div > span’) | 所有直接在<div>元素之内的<span>元素,中间没有其他元素 |
| soup.select(‘input[name]’) | 所有名为<input>,并有一个name属性,其值无所谓的元素 |
| soup.select(‘input[type=”button”]’) | 所有名为<input>,并有一个type属性,其值为button的元素 |
不同的选择器模式可以组合起来,形成更复杂的匹配。
比如soup.select(‘p#author’)将匹配在<p>元素内所有id属性为author的元素。
select()方法将返回一个Tag对象的列表,这是Beautiful Soup表示一个HTML元素的方式。Tag值可以传递给str()函数,显示它们代表的HTML标签。Tag值也可以有attrs属性,它将该Tag的所有HTML属性作为一个字典。
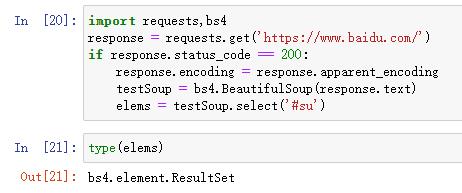
上面的代码将所有带有id = “su”的元素都找出来了,返回一个列表,列表中只有一个Tag对象(仅一次匹配),getText()方法返回元素内部文本或者内部HTML(即开始/结束标签之间的内容),最后attrs属性返回了一个字典。

3、通过元素获取数据
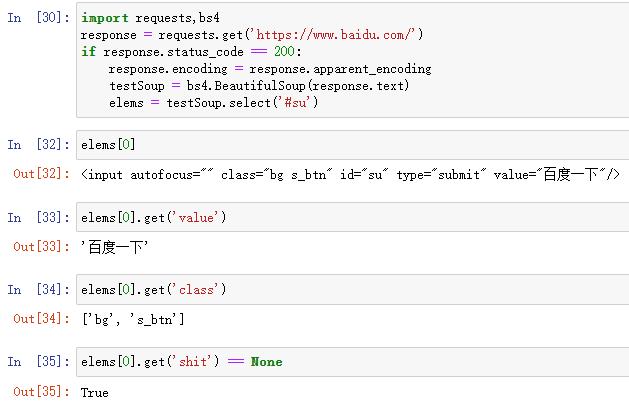
Tag对象的get()方法可以很容易从元素中获取属性值,向该方法传入一个属性名称的字符串,它将返回该属性的值。

以上是关于学习笔记Python - Beautiful Soup的主要内容,如果未能解决你的问题,请参考以下文章