对图片中的表格进行识别,并转换成excel文件(python小软件)(批量)
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对图片中的表格进行识别,并转换成excel文件(python小软件)(批量)相关的知识,希望对你有一定的参考价值。
一、python 调用腾讯接口
识别效果就比较拉胯,这个SecretId 和 SecretKey 需要你自己去申请,不难,去腾讯云捣鼓吧。
https://www.cnblogs.com/littlefatsheep/p/11024505.html
import numpy as np
import pandas as pd
import os
import json
import re
import base64
import xlwings as xw
##导入腾讯AI api
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.ocr.v20181119 import ocr_client, models
#定义函数
def excelFromPictures(picture,SecretId,SecretKey):
try:
with open(picture,"rb") as f:
img_data = f.read()
img_base64 = base64.b64encode(img_data)
cred = credential.Credential(SecretId, SecretKey) #ID和Secret从腾讯云申请
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = ocr_client.OcrClient(cred, "ap-shanghai", clientProfile)
req = models.TableOCRRequest()
params = '{"ImageBase64":"' + str(img_base64, 'utf-8') + '"}'
req.from_json_string(params)
resp = client.TableOCR(req)
# print(resp.to_json_string())
except TencentCloudSDKException as err:
print(err)
##提取识别出的数据,并且生成json
result1 = json.loads(resp.to_json_string())
rowIndex = []
colIndex = []
content = []
for item in result1['TextDetections']:
rowIndex.append(item['RowTl'])
colIndex.append(item['ColTl'])
content.append(item['Text'])
##导出Excel
##ExcelWriter方案
rowIndex = pd.Series(rowIndex)
colIndex = pd.Series(colIndex)
index = rowIndex.unique()
index.sort()
columns = colIndex.unique()
columns.sort()
data = pd.DataFrame(index = index, columns = columns)
for i in range(len(rowIndex)):
data.loc[rowIndex[i],colIndex[i]] = re.sub(" ","",content[i])
writer = pd.ExcelWriter("../tables/" + re.match(".*\\.",f.name).group() + "xlsx", engine='xlsxwriter')
data.to_excel(writer,sheet_name = 'Sheet1', index=False,header = False)
writer.save()
# 获取文件夹中的图片名
path = 'C:\\\\Users\\\\ABC\\\\Desktop\\\\tables'#指定文件所在路径
filetype ='.jpg'#指定文件类型
def get_filename(path,filetype):
name =[]
final_name = []
for root,dirs,files in os.walk(path):
for i in files:
if filetype in i:
name.append(i.replace(filetype,''))
final_name = [item + filetype for item in name]
return final_name
pictures = get_filename(path,filetype)
SecretId = 'xxxxxxxxxxx'
SecretKey = 'xxxxxxxxxxx'
for pic in pictures:
excelFromPictures(pic,SecretId,SecretKey)
print("已经完成" + pic + "的提取.")
二、python+百度API识别图片中表格并保存到excel
调用百度的表格识别接口,效果就还真不错,虽然有一些小错误,但整体是可以的,只要图片中的表格标准,就基本都能精准识别出来。
同样的,需要去百度申请 APP_ID=‘xxxx’ 、API_KEY=‘xxxx’、 SECRET_KEY=‘xxxxx’
import pandas as pd
import numpy as np
import re
# 图片识别
from aip import AipOcr
# 时间模块
import time
# 网页获取
import requests
# 操作系统接口模块
import os
image_path=''
# 获取文件夹中所有图片
def get_image():
images=[] # 存储文件夹内所有文件的路径(包括子目录内的文件)
for root, dirs, files in os.walk(image_path):
path = [os.path.join(root, name) for name in files]
images.extend(path)
return images
def Image_Excel(APP_ID,API_KEY,SECRET_KEY):
# 调用百度AI接口
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 循环遍历文件家中图片
images=get_image()
for image in images:
# 以二进制方式打开图片
img_open=open(image,'rb')
# 读取图片
img_read = img_open.read()
# 调用表格识别模块识别图片
table = client.tableRecognitionAsync(img_read)
# 获取请求ID
request_id = table['result'][0]['request_id']
#获取表格处理结果
result = client.getTableRecognitionResult(request_id)
# 处理状态是“已完成”,获取下载地址
while result['result']['ret_msg'] != '已完成':
time.sleep(2) # 暂停2秒再刷新
result = client.getTableRecognitionResult(request_id)
download_url = result['result']['result_data']
print(download_url)
# 获取表格数据
excel_data = requests.get(download_url)
# 根据图片名字命名表格名称
xlsx_name = image.split(".")[0] + ".xls"
# 新建excel文件
xlsx = open(xlsx_name, 'wb')
# 将数据写入excel文件并保存
xlsx.write(excel_data.content)
if __name__=='__main__':
image_path ='C:\\\\Users\\\\ABC\\\\Desktop\\\\市场行情截图\\\\市场行情截图\\\\'
APP_ID='xxxx'
API_KEY='xxxx'
SECRET_KEY='xxxxx'
Image_Excel(APP_ID,API_KEY,SECRET_KEY)
配合python,对识别的结果在处理一遍
比如我这里,是针对我的图片识别结果,对一些错误进行处理
# --------------------------------------------------------------------2021年
path = 'C:\\\\Users\\\\ABC\\\\Desktop\\\\截图\\\\截图\\\\2021\\\\'#指定文件所在路径
filetype ='.xls'#指定文件类型
def get_filename(path,filetype):
name =[]
final_name = []
for root,dirs,files in os.walk(path):
for i in files:
if filetype in i:
name.append(i.replace(filetype,''))
final_name = [item +'.xls' for item in name]
return final_name
lli = get_filename(path,filetype)
writer = pd.ExcelWriter('result.xlsx')
for k in lli:
print('开始',k)
df = pd.read_excel(path+k)
# 删除最后行(最后一行数据不完整)
df.drop([df.shape[0]-1],inplace=True)
# 把
if df.iloc[0,3]=='':
df.drop([0,1],inplace=True)
df.index = range(df.shape[0])
df_yao = df.iloc[4:9,:]
# 删除最后的空列
for i in df_yao.columns[::-1]:
if df_yao[i].isnull().sum()==df_yao.shape[0]:
df_yao.drop([df_yao.columns[-1]],axis=1,inplace=True)
else:
break
# 定义列名
if df_yao.iloc[0,0]=='银票':
df_yao.columns = ['票据类型','票据介质','期限品种','最新利率','加权平均利率','最高利率','最低利率','开盘利率','收盘利率','前收盘利率','前加权平均利率','成交量']
if df_yao.iloc[0,0]=='电票':
df_yao.columns = ['票据介质','期限品种','最新利率','加权平均利率','最高利率','最低利率','开盘利率','收盘利率','前收盘利率','前加权平均利率','成交量']
# 处理 票据类型 错误(只处理银票、电票)
if '票据类型' in df_yao.columns:
if '银票电票' in df_yao['票据类型'].unique().tolist():
df_yao['票据介质'][df_yao['票据类型']=='银票电票'] = '电票'
df_yao['票据类型'][df_yao['票据类型']=='银票电票'] = '银票'
# 处理 票据介质 错误
df_yao['期限品种'][~df_yao['票据介质'].isin(['纸票','电票'])]=df_yao[~df_yao['票据介质'].isin(['纸票','电票'])]['票据介质'].apply(lambda x:re.sub('[\\u4e00-\\u9fa5]', '', x))
df_yao['票据介质'][~df_yao['票据介质'].isin(['纸票','电票'])]=df_yao[~df_yao['票据介质'].isin(['纸票','电票'])]['票据介质'].str.slice(0, 2)
if len(df_yao['票据介质'].unique().tolist())==1:
df_yao.to_excel(excel_writer=writer,sheet_name=k.replace('.xls',''),index=False)
print('完成',k)
writer.save()
writer.close()
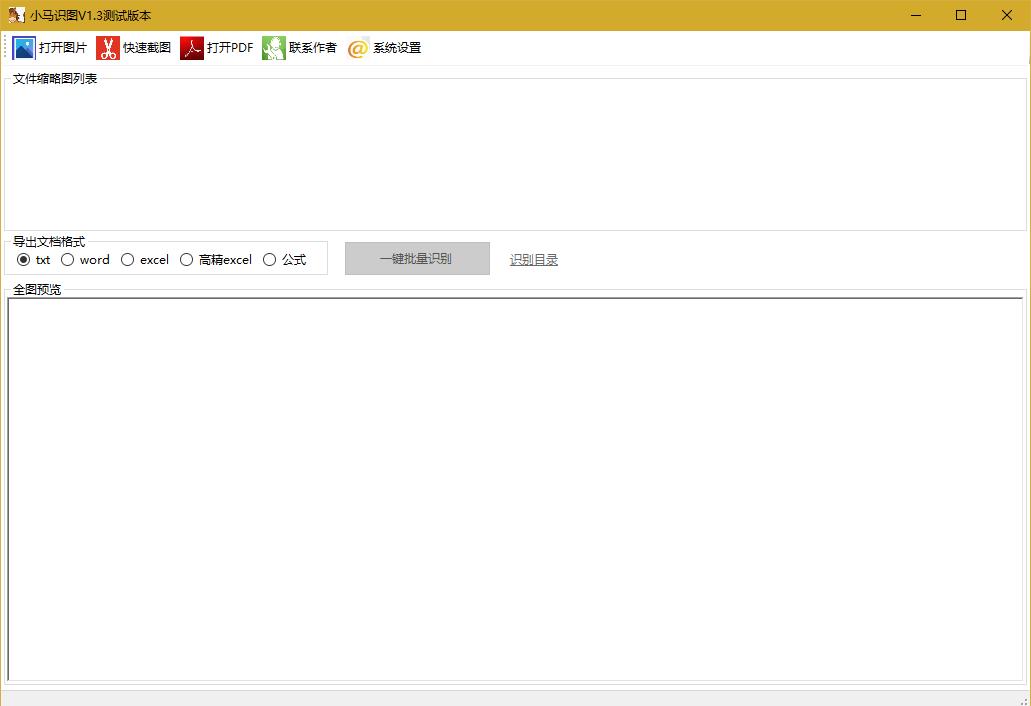
三、小马识图识别工具
在网上找一个小软件,可以批量的识别图片中的表格,并转换为想要的格式,但是效率不高,我试过100张图片,大概需要15分钟。其识别效果还行,但还是有一些会是错,比如表头容易混在一起,我看了一下,其实现猜测也是调用的百度接口。
下载地址:
https://www.onlinedown.net/soft/1229664.htm
识别出来以后,可以再用Python进行处理
以上是关于对图片中的表格进行识别,并转换成excel文件(python小软件)(批量)的主要内容,如果未能解决你的问题,请参考以下文章