神经网络学习到的是什么?(Python)
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络学习到的是什么?(Python)相关的知识,希望对你有一定的参考价值。

作者|泳鱼
来源|算法进阶
神经网络(深度学习)学习到的是什么?一个含糊的回答是,学习到的是数据的本质规律。但具体这本质规律究竟是什么呢?要回答这个问题,我们可以从神经网络的原理开始了解。
一、 神经网络的原理
神经网络学习就是一种特征的表示学习,把原始数据通过一些简单非线性的转换成为更高层次的、更加抽象的特征表达。深度网络层功能类似于“生成特征”,而宽度层类似于“记忆特征”,增加网络深度可以获得更抽象、高层次的特征,增加网络宽度可以交互出更丰富的特征。通过足够多的转换组合的特征,非常复杂的函数也可以被模型学习好。
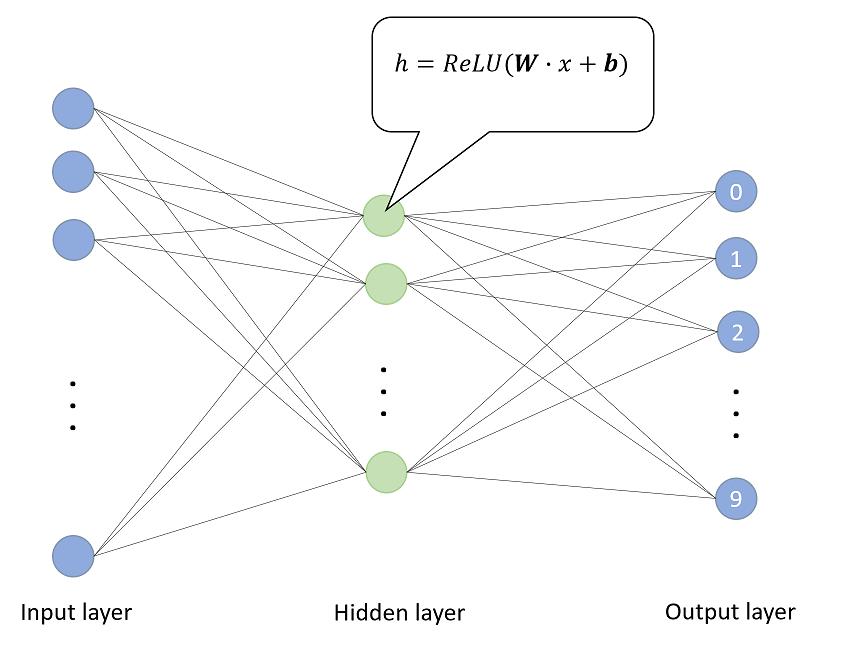
可见神经网络学习的核心是,学习合适权重参数以对数据进行非线性转换,以提取关键特征或者决策。即模型参数控制着特征加工方法及决策。了解了神经网络的原理,我们可以结合如下项目示例,看下具体的学习的权重参数,以及如何参与抽象特征生成与决策。
二、神经网络的学习内容
2.1 简单的线性模型的学习
我们先从简单的模型入手,分析其学习的内容。像线性回归、逻辑回归可以视为单层的神经网络,它们都是广义的线性模型,可以学习输入特征到目标值的线性映射规律。
如下代码示例,以线性回归模型学习波士顿各城镇特征与房价的关系,并作出房价预测。数据是波士顿房价数据集,它是统计20世纪70年代中期波士顿郊区房价情况,有当时城镇的犯罪率、房产税等共计13个指标以及对应的房价中位数。

import pandas as pd
import numpy as np
from keras.datasets import boston_housing #导入波士顿房价数据集
(train_x, train_y), (test_x, test_y) = boston_housing.load_data()
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
from sklearn.metrics import mean_squared_error
np.random.seed(0) # 随机种子
random.set_seed(0)
# 单层线性层的网络结构(也就是线性回归):无隐藏层,由于是数值回归预测,输出层没有用激活函数;
model = Sequential()
model.add(Dense(1,use_bias=False))
model.compile(optimizer='adam', loss='mse') # 回归预测损失mse
model.fit(train_x, train_y, epochs=1000,verbose=False) # 训练模型
model.summary()
pred_y = model.predict(test_x)[:,0]
print("正确标签:",test_y)
print("模型预测:",pred_y )
print("实际与预测值的差异:",mean_squared_error(test_y,pred_y ))通过线性回归模型学习训练集,输出测试集预测结果如下:

分析预测的效果,用上面数值体现不太直观,如下画出实际值与预测值的曲线,可见,整体模型预测值与实际值的差异还是比较小的(模型拟合较好)。
#绘图表示
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置图形大小
plt.figure(figsize=(8, 4), dpi=80)
plt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')
plt.plot(range(len(pred_y)), pred_y, ls='-',lw=2,c='b',label='预测值')
# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') #设置x轴的标签文本
plt.ylabel('房价') #设置y轴的标签文本
# 展示
plt.show()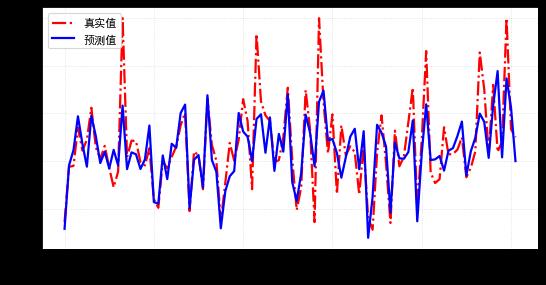
回到正题,我们的单层神经网络模型(线性回归),在数据(波士顿房价)、优化目标(最小化预测误差mse)、优化算法(梯度下降)的共同配合下,从数据中学到了什么呢?
我们可以很简单地用决策函数的数学式来概括我们学习到的线性回归模型,预测y=w1x1 + w2x2 + wn*xn。通过提取当前线性回归模型最终学习到的参数:
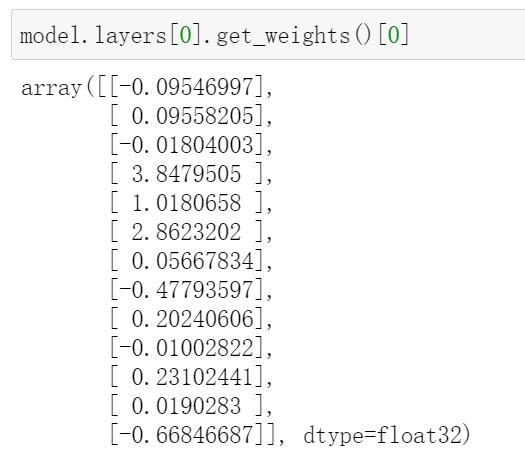
将参数与对应输入特征组合一下,我们忙前忙后训练模型学到内容也就是——权重参数,它可以对输入特征进行加权求和输出预测值决策。
小结:单层神经网络学习到各输入特征所合适的权重值,根据权重值对输入特征进行加权求和,输出求和结果作为预测值(注:逻辑回归会在求和的结果再做sigmoid非线性转为预测概率)。
2.2 深度神经网络的学习
深度神经网络(深度学习)与单层神经网络的结构差异在于,引入了层数>=1的非线性隐藏层。从学习的角度上看,模型很像是集成学习方法——以上层的神经网络的学习的特征,输出到下一层。而这种学习方法,就可以学习到非线性转换组合的复杂特征,达到更好的拟合效果。
对于学习到的内容,他不仅仅是利用权重值控制输出决策结果--f(WX),还有比较复杂多层次的特征交互, 这也意味着深度学习不能那么直观数学形式做表示--它是一个复杂的复合函数f(f..f(WX))。
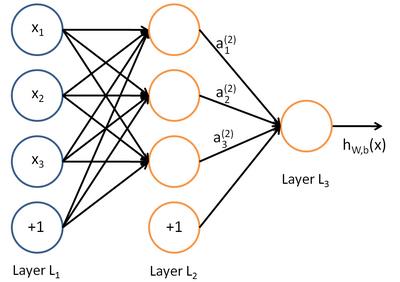
如下以2层的神经网络为例,继续波士顿房价的预测:
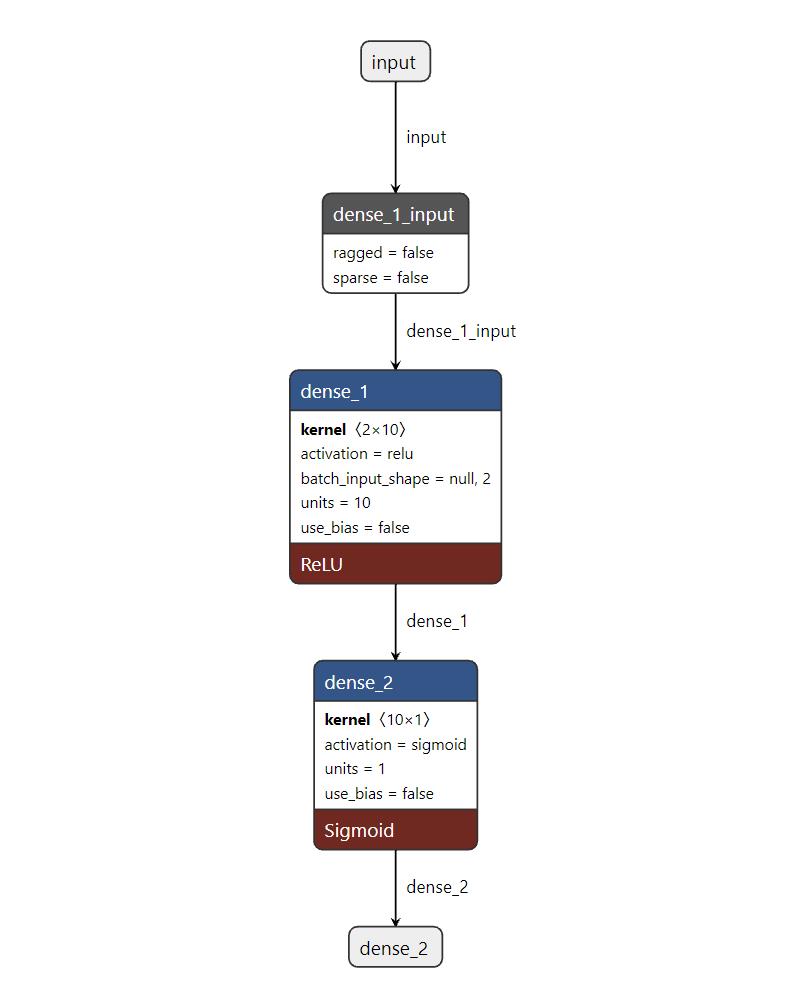
注:本可视化工具来源于https://netron.app/
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
from sklearn.metrics import mean_squared_error
np.random.seed(0) # 随机种子
random.set_seed(0)
# 网络结构:输入层的特征维数为13,1层relu隐藏层,线性的输出层;
model = Sequential()
model.add(Dense(10, input_dim=13, activation='relu',use_bias=False)) # 隐藏层
model.add(Dense(1,use_bias=False))
model.compile(optimizer='adam', loss='mse') # 回归预测损失mse
model.fit(train_x, train_y, epochs=1000,verbose=False) # 训练模型
model.summary()
pred_y = model.predict(test_x)[:,0]
print("正确标签:",test_y)
print("模型预测:",pred_y )
print("实际与预测值的差异:",mean_squared_error(test_y,pred_y ))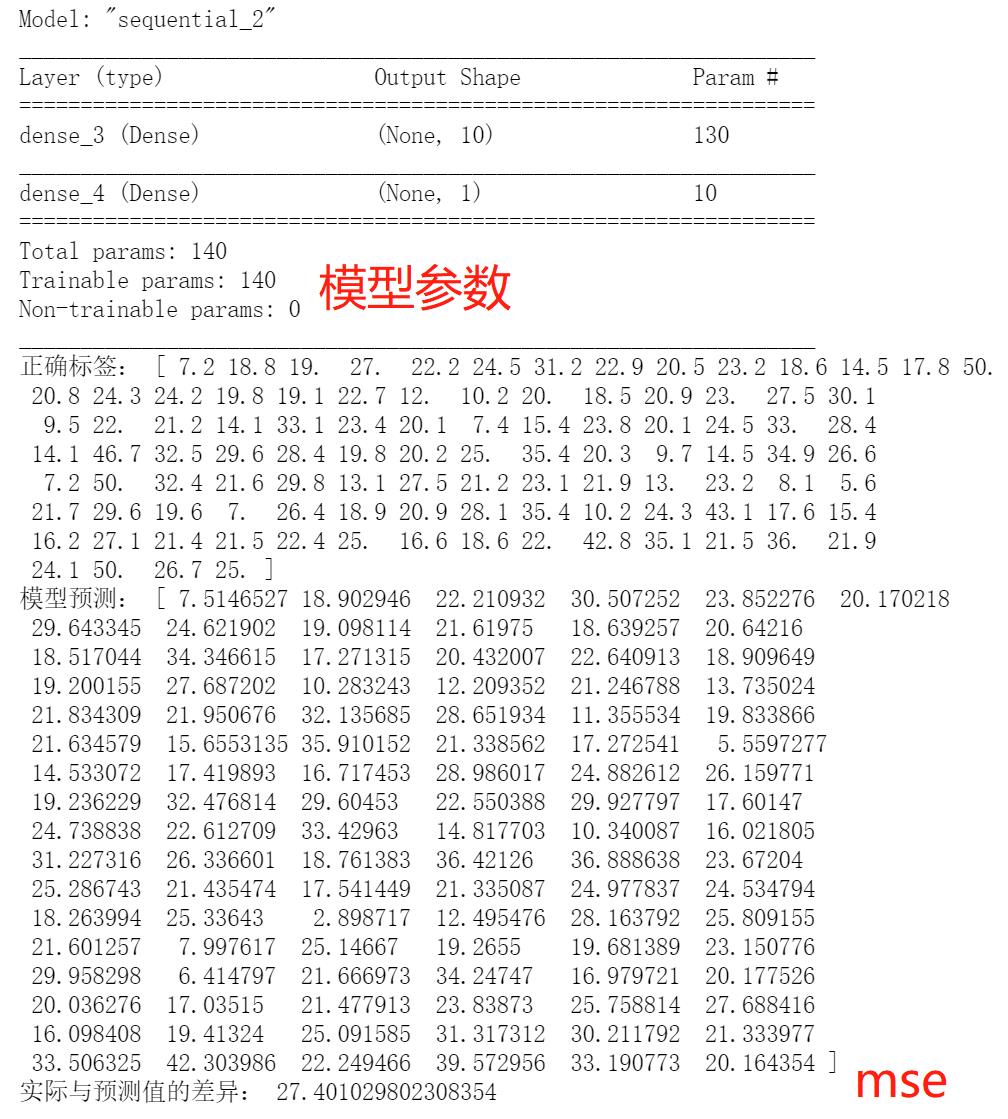
可见,其模型的参数(190个)远多于单层线性网络(13个);学习的误差(27.4)小于单层线性网络模型(31.9),有着更高的复杂度和更好的学习效果。
#绘图表示
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置图形大小
plt.figure(figsize=(8, 4), dpi=80)
plt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')
plt.plot(range(len(pred_y)), pred_y, ls='-',lw=2,c='b',label='预测值')
# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') #设置x轴的标签文本
plt.ylabel('房价') #设置y轴的标签文本
# 展示
plt.show()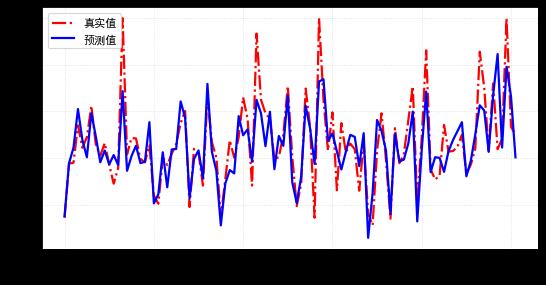
回到分析深度神经网络学习的内容,这里我们输入一条样本,看看每一层神经网络的输出。
from numpy import exp
x0=train_x[0]
print("1、输入第一条样本x0:\\n", x0)
# 权重参数可以控制数据的特征表达再输出到下一层
w0= model.layers[0].get_weights()[0]
print("2、第一层网络的权重参数w0:\\n", w0)
a0 = np.maximum(0,np.dot(w0.T, x0))
# a0可以视为第一层网络层交互出的新特征,但其特征含义是比较模糊的
print("3、经过第一层神经网络relu(w0*x0)后输出:\\n",a0)
w1=model.layers[1].get_weights()[0]
print("4、第二层网络的权重参数w1:\\n", w1)
# 预测结果为w1与ao加权求和
a1 = np.dot(w1.T,a0)
print("5、经过第二层神经网络w1*ao后输出预测值:%s,实际标签值为%s"%(a1[0],train_y[0]))运行代码,输出如下结果

从深度神经网络的示例可以看出,神经网络学习的内容一样是权重参数。由于非线性隐藏层的作用下,深度神经网络可以通过权重参数对数据非线性转换,交互出复杂的、高层次的特征,并利用这些特征输出决策,最终取得较好的学习效果。但是,正也因为隐藏层交互组合特征过程的复杂性,学习的权重参数在业务含义上如何决策,并不好直观解释。
对于深度神经网络的解释,常常说深度学习模型是“黑盒”,学习内容很难表示成易于解释含义的形式。在此,一方面可以借助shap等解释性的工具加于说明。另一方面,还有像深度学习处理图像识别任务,就是个天然直观地展现深度学习的过程。如下展示输入车子通过层层提取的高层次、抽象的特征,图像识别的过程。注:图像识别可视化工具来源于https://poloclub.github.io/cnn-explainer/

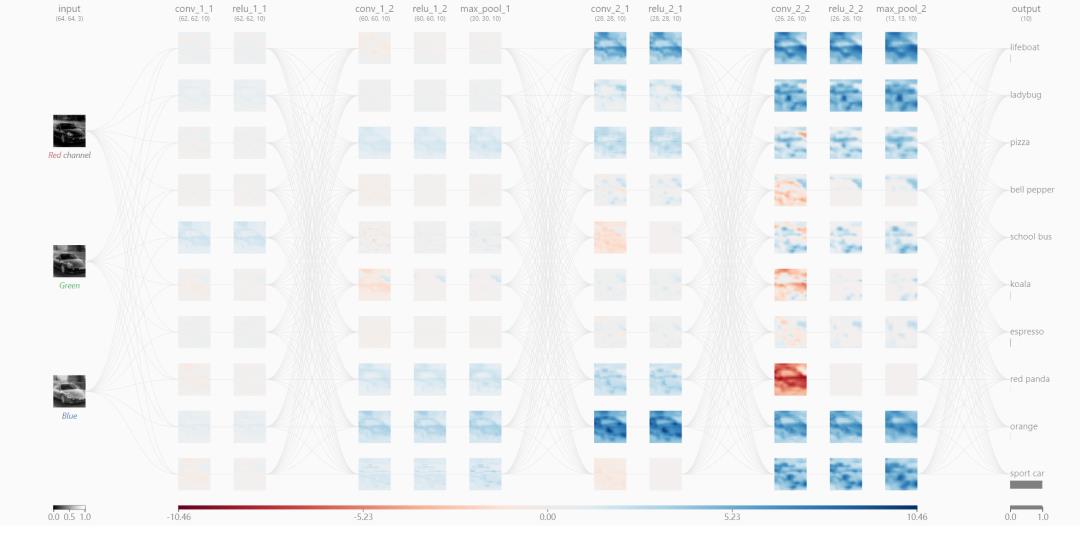
在神经网络学习提取层次化特征以识别图像的过程:
第一层,像是各种边缘探测特征的集合,在这个阶段,激活值仍然是保留了几乎原始图像的所有信息。
更高一层,激活值就变得进一步抽象,开始表示更高层次的内容,诸如“车轮”。有着更少的视觉表示(稀疏),也提取到了更关键特征的信息。
这和人类学习(图像识别)的过程是类似的——从具体到抽象,简单概括出物体的本质特征。就像我们看到一辆很酷的小车

然后凭记忆将它画出来,很可能没法画出很多细节,只有抽象出来的关键特征表现,类似这样🤣:
我们的大脑学习输入的视觉图像的抽象特征,而不相关忽略的视觉细节,提高效率的同时,学习的内容也有很强的泛化性,我们只要识别一辆车的样子,就也会辨别出不同样式的车。这也是深度神经网络学习更高层次、抽象的特征的过程。


往
期
回
顾
技术
资讯
资讯
资讯

分享

点收藏

点点赞

点在看
以上是关于神经网络学习到的是什么?(Python)的主要内容,如果未能解决你的问题,请参考以下文章