江西开放数据创新应用大赛VTE赛道单特征0.5+分享
Posted m0_63816528
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了江西开放数据创新应用大赛VTE赛道单特征0.5+分享相关的知识,希望对你有一定的参考价值。
对VTE赛道的数据进行分析之后,发现诊断一栏的特征对整个结果的影响最大,所以想着能不能对诊断一栏的数据进行一个很好的处理。
一开始使用了OneHot编码对诊断特征数据进行编码,因为是字符数据,使用的模型不能直接使用,所以对诊断进行编码后,再送进去。但是最后的结果出人意料地低,线上只有0.1几,虽说是单特征,但是这样的效果实在太低了,所以就在想是不是特征本身没有问题的,是处理数据的方式还不太好。然后偶然看到网上有对字符数据特征进行处理的文章,主要是通过word2vec对文字生成词向量,再将词向量送入到模型中进行处理。
按照文章中的做法,单是针对诊断这一特征,做了简单的转换后,生成了11076*100维的数据,11076是原本数据中的行数,100是将诊断特征生成词向量之后的大小,送进模型进行运行后,发现最后的精度提升了不少,线下达到了0.2+
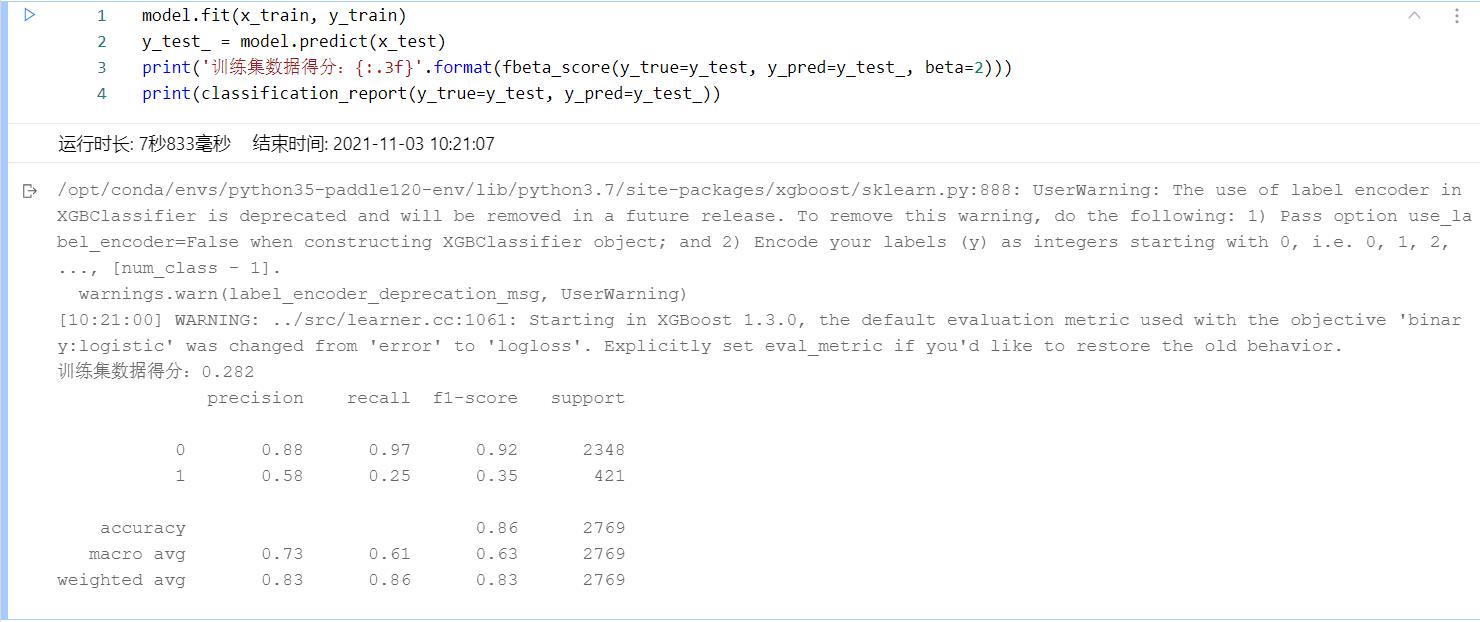
这个结果对于单特征来说已经算是还可以了,至少比之前OneHot编码要很好多了。但是到这里还只是一部分,通过对整个训练集数据的分析,不难发现其中flag0和1的个数相差太多,也就是数据的类别分类不均衡,对于这样的数据,进行训练后预测,得到的模型精度肯定也不会太高,因此应该想办法提高数据类别的分类占比,在西瓜书上,针对这一问题,书中给出了过拟合的方法--使用SMOTE算法,对数据进行采用的过程中通过相似性同时生成并插样“少数类别数据”。
通过这样的做法,再重新训练模型后,效果大大出人意料,在线下已经达到了0.50+!!!!
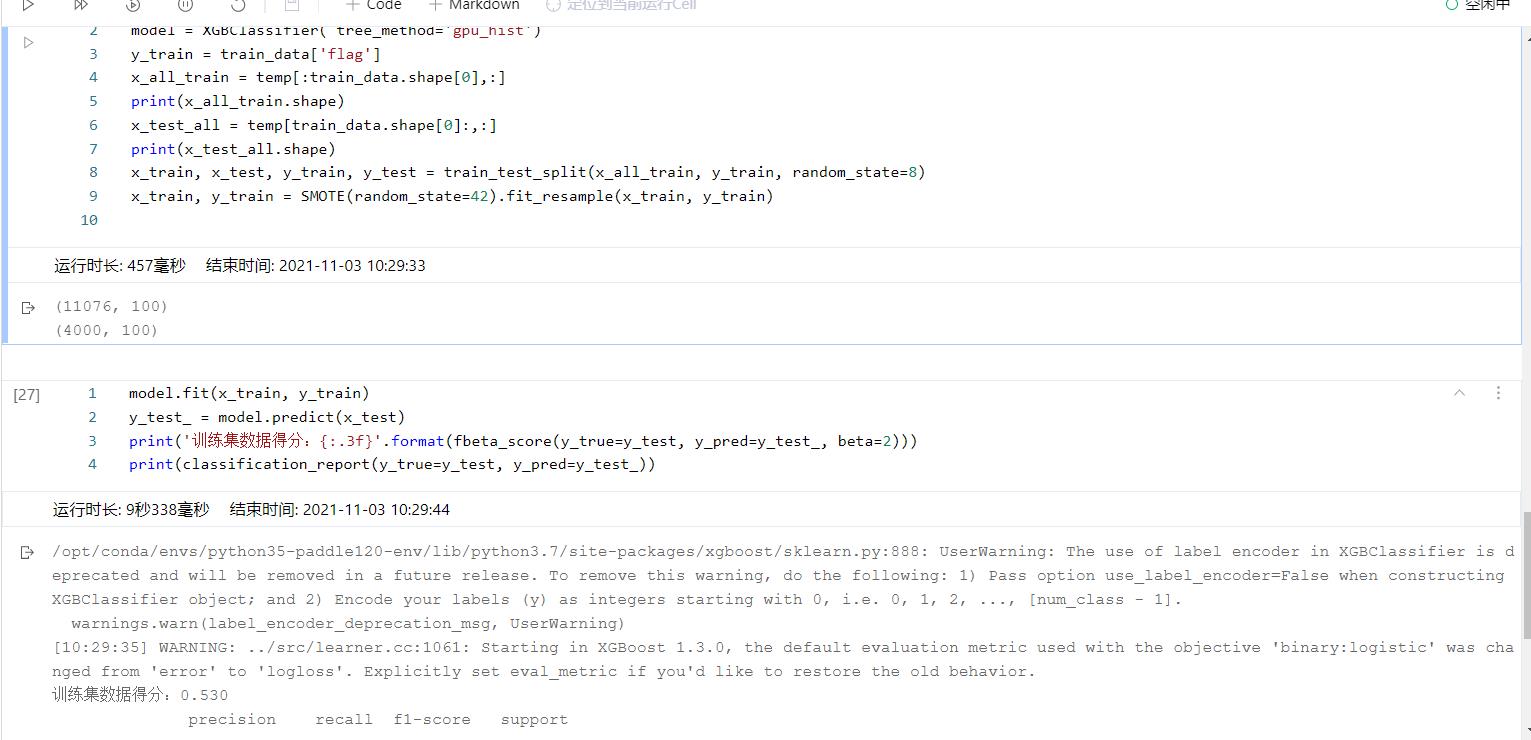
可以看到图中最后预测的结果达到了0.530,经检验,线上的精度也在0.50以上
以上是关于江西开放数据创新应用大赛VTE赛道单特征0.5+分享的主要内容,如果未能解决你的问题,请参考以下文章
50万奖金池:欢迎全球学子报名参加中国移动第二届梧桐杯大数据应用创新大赛湖北赛道