联邦学习:保护用户数据隐私
Posted 查里王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习:保护用户数据隐私相关的知识,希望对你有一定的参考价值。
对数据保护通常是对数据做加密或移除敏感信息,但实际上即使移除了敏感信息,有足够多的真实的信息,还是可以通过算法是找到对应的人的,如:
- 卡内基梅隆大学的Latanya Sweeney的将匿名化的GIC数据库(包含每位患者的出生日期、性别和邮政编码)与选民登记记录相连后,可以找出马萨诸塞州州长的病历。
- 2006年的Netflix的机器学习比赛,虽然可识别单个客户的所有个人信息已被删除,并且所有客户ID已用随机分配的ID替代,但德克萨斯州大学奥斯汀分校的研究员Arvind Narayanan和Vitaly Shmatikov利用一种叫做record linkage的技术将Netflix匿名化的训练数据库与IMDb数据库(根据用户评价日期)相连,能够部分反匿名化Netflix的训练数据库。
也就是,如果你公布一个数据集,仅仅只是移除一些ID名称,这远远是不够的,因为结合外部的一些信息是可以将数据集还原的,所以我们需要一些新的技术去保护用户的数据隐私,现在最热门的就是联邦学习。全球各地越来越多的国家出台保护用户隐私的相关法律——国外的个人数据隐私保护法,倒逼企业不断提升用户隐私保护技术,
Federated Learning,也叫Collaborative Learning,最初由谷歌在2016年提出,在国内叫联邦学习、协同学习。
联邦学习在保护隐私方面最重要的三大技术分别是:差分隐私(Differential Privacy)、同态加密(Homomorphic Encryption)和隐私保护集合交集(Private Set Intersection)。
差分隐私(Differential Privacy)
差分隐私是用户数据加密后上传到平台服务器后,平台可以用这些加密后的数据计算出用户群体的相关特征,但无法解析某个个体的信息。
通常采用的做法是给数据加入噪声,这个噪声不是随便加的,加得太大,数据失真,加得太少,起不到保护作用,噪声是有要求的,假设数据集D,现在加入噪声M等到数据集D’,将数据集D中随意拿到一个记录,再加入噪声M得到D”,对D’和D”的数据计算结果要一样的才可以。
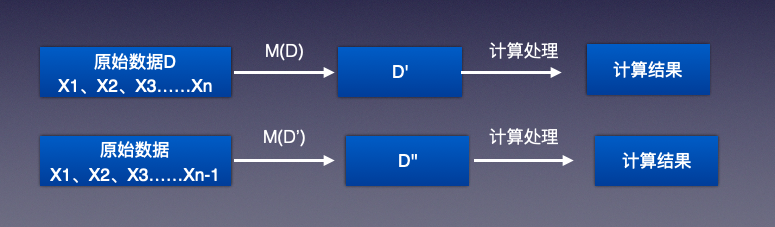
详细原理示例:
假设现在有一家10个员工的公司,员工想知道自己的工资水平在公司的水平,但又不想直接将自己的工资数据分享出去,所以它们找了一个第三方的人,然后让第三方的人去统计平均工资:

但如果其中有一个人知道其他八个人的工资,只有一个人的是不知道:

如果他知道平均工资,那么可以推断出那个人是45K,为了防止这种情况出现,第三方的人在数据中加入噪声,使得即使减少掉一个人计算出来的平均值也是在合理范围内

然后计算平均薪酬,这个薪酬是添加了噪声之后计算,就倒推不出那个人的工资,从而保护用户的隐私:

常用的噪音机制有指数、拉普拉斯和高斯。
差分隐私不是一个新的概念,十几年前就已经提出来了:
- 2006年,微软的 C. Dwork 提出差分隐私的概念,因为在该年Netflix的机器学习比赛使用的数据集被反匿名化,由此引发重视。
- 2014年,谷歌将差分隐私引入了Chrome,Google 使用名为RAPPOR的自定义系统来收集有关Chrome用户浏览模式的概率信息,在该系统中,浏览器使用哈希函数将字符串(如URL)转换为短字符串,然后添加概率噪声并将结果报告给Google。
- 2016年,苹果在WWDC 大会上提到了一项 Differential Privacy 差分隐私技术,按苹果的说法,苹果是唯一一家将差分隐私作为标准大规模布署的公司,此后这一领域广受关注。
- 2017年,Uber于发布了差分隐私工具,限制从司机处获得的数据。
- 2019年,谷歌宣布开源创新隐私保护技术的开源版。
- 2019年,微众银行AI团队自研并推出了基于联邦学习开源框架Federated AI Technology Enabler (简称FATE)。
- 2020年,小米在MIUI 12系统中还运用到了“差分隐私”保护算法,这项技术会在数据上传之前添加一些干扰噪声,确保上传数据已经不是用户的真实数据,仅可以用于整体数据的趋势研究。
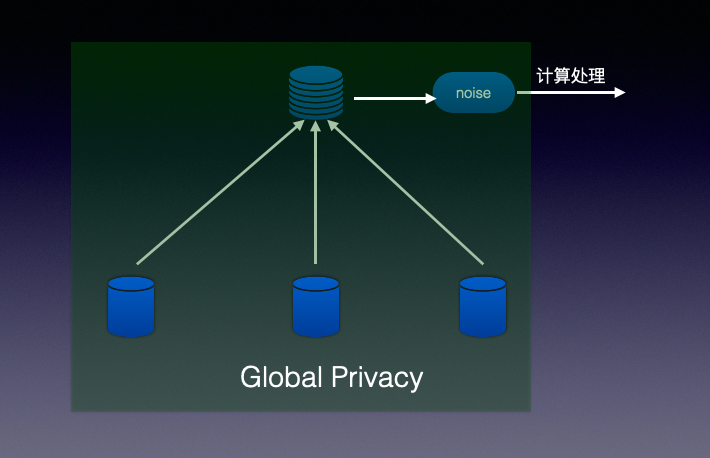
差分隐私有两种工作模式:Global Privacy和Local Privacy。
Global Privacy
数据中心统一加噪声后再对外提供服务。
Local Privacy
在用户设备本地完成模型的训练,上传权重参数,而非数据,不再需要用户把数据发送到服务器,然后在服务器上进行模型训练,而是用户本地训练,加密上权重参数,服务器端会综合成千上万的用户模型后再反馈给用户模型改进方案。
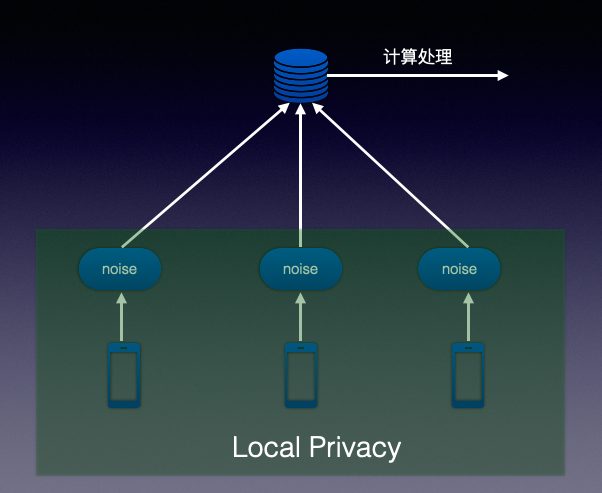
在全球范围内,Local通常更准确,更为保守,更安全的模式。
这种方式也是有缺点的:首先对于小型数据不适用;其次要加入噪声,是对数据准确度要求高的也不适用,如做异常监测的时候,你给它加个干扰项?
同态加密(Homomorphic Encryption)
同态加密属于密码学领域,同态加密是一种加密形式,它允许人们对密文进行特定形式的代数运算得到仍然是加密的结果,将其解密所得到的结果与对明文进行同样的运算结果一样,从数据的角度如下图:
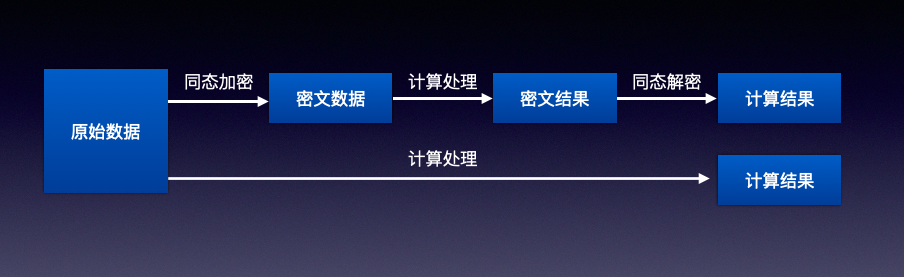
同态加密可以分为以下4个步骤:
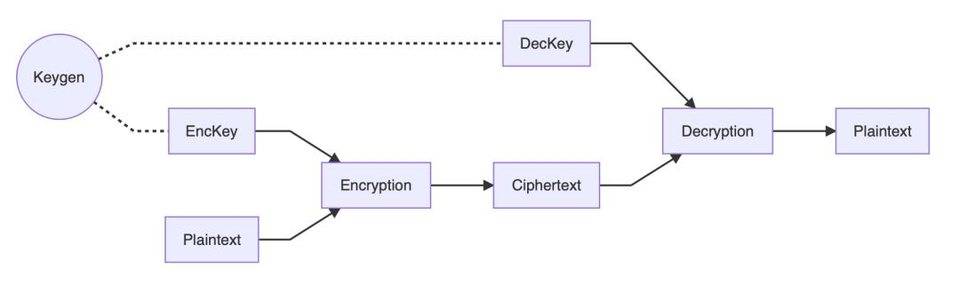
- 密钥生成算法:Keygen就是秘钥生成算法,它生成了秘钥EncKey和解密算法Deckey
- 加密算法:用秘钥算法生成的的秘钥Enckey对数据Plaintext做加密Encryption,生成加密的Cliphertext
- 计算算法:对加密数据Cliphertext做处理结算
- 解密算法:就是DecKey,可以将加密数据Cliphertext还原成Plaintext
同态加密很早就提出了,但直到2009年Gentry开发出首个全同态加密方案后才有显著发展:
- 1978年,Ron Rivest, Leonard Adleman, 以及Michael L. Dertouzos就以银行为应用背景提出了的隐私同态 (privacy homomorphic) 这个概念,
- 2009年,斯坦福大学的博士生Gentry基于理想格提出一个全同态加密方案,实现了同态加密,此后便快速发展。
全同态加密
全同态加密(Fully Homomorphic Encryption, FHE),自2009年提出经过10年的发展,已经有了很大的突破,可以分为三个阶段:
第一代方案:理想格(ideal lattice)
第一代方案其实是包含基于理想格和基于最大近似公因子问题的变种两种方案:
- 基于理想格(ideal lattice)的方案:Gentry 和 Halevi 在 2011 年提出的基于理想格的方案可以实现 72 bit 的安全强度,对应的公钥大小约为 2.3 GB,同时刷新密文的处理时间需要几十分钟。
- 基于整数上近似 GCD 问题的方案:Dijk 等人在 2010 年提出的方案(及后续方案)采用了更简化的概念模型,可以降低公钥大小至几十 MB 量级。
这一代方案缺点是密钥尺寸大、效率低下。
第二代方案:容错学习
第二代全同态加密方案通常基于(R)LWE假设,LWE全称是Learning with Eror,是有错误学习。
- BV方案(Brakerski-Vaikuntanathan):2011 年,Brakerski 和 Vaikuntanathan基于 LWE 与 RLWE 分别提出了全同态加密方案,其核心技术是再线性化和模数转换。他们还提出了循环安全的类同态加密方案,但由于不能自举,所以达不到全同态。
- BGV方案(Brakerski-Gentry-Vaikuntanathan ):依次使用模数转换能够很好的控制噪音的增长,层次型全同态加密可以同态计算任意多项式深度的电路,从而在实际应用中无需启用计算量过大的自举。
这一代方案计算是简单,缺点是在使用密钥交换技术时需要增加大量用于密钥交换的矩阵,从而导致公钥长度的增长。
第三代方案:特征向量
第三代是一种基于矩阵近似特征向量的全同态加密方案。
- GSW方案:Gentry 等人利用“ 近似特征向量”技术,设计了一个无需计算密钥的全同态加密方案。
- 此后很多方案都是基于GSW的优化。
不再需要密钥交换与模转换技术
半同态加密
半同态加密或部分同态加密,英文简称为SWHE(Somewhat Homomorphic Encryption)或PHE(Partially Homomorphic Encryption):
乘法同态
乘法同态性表现为 E(m1)E(m2)=E(m1m2):
- RSA算法:RSA 算法是建立在因子分解困难性假设基础上的公钥加密算法
- ElGamal算法:ElGamal算法建立在计算有限域上离散对数困难性假设基础上
加法同态
加法同态性表现为 E (m1 )E(m2)=E(m1+m2 mod n):
- Paillier:建立在合数模的高阶剩余计算困难性假设基础上
隐私保护集合交集(Private Set Intersection)
隐私保护集合交集属于安全多方计算领域的特定应用问题,安全多方计算(Secure Multi-party Computation, SMC)是解决分布式环境下多个参与者在计算过程中的 隐私保护技术之一. 保护隐私的集合运算(Private Set Intersection, PSI)是安全多方计算的一个重要研究分支,
隐私保护集合交集允许双方私下加入他们的集合并发现他们共有的标识符,一般使用一个不经意问题的变种协议,它只标记加密的标识符而不学习任何标识符。在数据由不同管理者持有的条件下,通过 PSI 计算达到保护隐私与信息共享的双赢局面。
问题模型可以抽象为:
- 双方拥有的一定数量的用户,其中部分是共有的
- 在不泄露用户输入的任何隐私信息下,这些共同用户的数据打通
这种情况很像线上广告投放,线下转化的数据打通,已经公司在这么做。
以上是关于联邦学习:保护用户数据隐私的主要内容,如果未能解决你的问题,请参考以下文章