SQL调优指南笔记4:Query Optimizer Concepts
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL调优指南笔记4:Query Optimizer Concepts相关的知识,希望对你有一定的参考价值。
本文为SQL Tuning Guide第4章“查询优化器概念”的笔记。
4.1 Introduction to the Query Optimizer
查询优化器(简称优化器)是内置的数据库软件,用于确定 SQL 语句访问请求数据的最有效方法。
4.1.1 Purpose of the Query Optimizer
优化器尝试为 SQL 语句生成最佳执行计划。
优化器在所有考虑的候选计划中选择成本最低的计划。 优化器使用可用的统计数据来计算成本。 对于给定环境中的特定查询,成本计算考虑了查询执行的因素,例如 I/O、CPU 和通信。
例如,优化器可能选择全表扫描以访问表中的大部分数据,或者使用索引访问表中少数几条数据。由于数据库有许多内部统计信息和工具可供其使用,因此优化器通常比用户更能确定语句执行的最佳方法。 为此,所有 SQL 语句都使用优化器。
4.1.2 Cost-Based Optimization
查询优化是选择执行 SQL 语句的最有效方法的过程。
SQL 是一种非过程语言(即声明式语言),因此优化器可以自由地以任何顺序进行合并、重组和处理。 数据库根据收集的有关访问数据的统计信息优化每个 SQL 语句。 优化器通过检查多种访问方法(例如全表扫描或索引扫描)、不同的连接方法(例如嵌套循环和哈希连接)、不同的连接顺序以及可能的转换来确定 SQL 语句的最佳计划。
对于给定的查询和环境,优化器为可能计划的每个步骤分配一个相对数字成本,然后将这些值组合在一起以生成计划的总体成本估计。 在计算其它替代计划的成本后,优化器选择成本估计最低的计划。 出于这个原因,优化器有时被称为基于成本的优化器 (CBO),以将其与传统的基于规则的优化器 (RBO) 进行对比。
不同数据库版本可能会影响执行计划的选择,因为可以获得更好的信息,更多的优化器转换。
4.1.3 Execution Plans
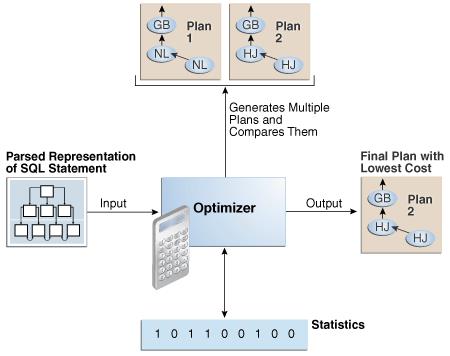
执行计划描述了 SQL 语句的推荐执行方法。该计划显示了 Oracle 数据库用于执行 SQL 语句的步骤的组合。 每个步骤要么从数据库物理检索数据行,要么为发出语句的用户准备数据。
执行计划显示整个计划的成本。 成本是一个内部单位,只用于进行计划比较。
4.1.3.1 Query Blocks
优化器的输入是 SQL 语句的解析表示。
原始 SQL 语句中的每个 SELECT 块在内部由一个查询块表示。 查询块可以是顶层语句、子查询或未合并的视图。
以下语句包括内部查询块(子查询)和外部查询块。
SELECT first_name, last_name
FROM hr.employees
WHERE department_id
IN (SELECT department_id
FROM hr.departments
WHERE location_id = 1800);
Query Subplans
对于每个查询块,优化器都会生成一个查询子计划。
数据库自下而上分别优化查询块。 因此,数据库首先优化最里面的查询块。
查询块的可能计划数与 FROM 子句中的对象数成正比。 这个数字随着对象的数量呈指数增长。
Analogy for the Optimizer
优化器的一个类比是在线旅行顾问。
骑自行车的人想知道从 A 点到 B 点的最有效的自行车路线。查询就像指令“我需要从 A 点到 B 点的最有效路线”或“我需要从 A 点到 B 点并经过C 点的最有效路线” 。” 旅行顾问使用内部算法,该算法依赖于速度和难度等因素,以确定最有效的路线。 骑自行车的人可以通过使用诸如“我想尽快到达”或“我想尽可能轻松地骑行”等指令来影响旅行顾问的决定。
在这个类比中,执行计划是旅行顾问生成的可能路线。 在内部,顾问可以将整个路线划分为多个子路线(subplans),并分别计算每个子路线的效率。 例如,旅行顾问可能会估计一条中等难度的 15 分钟的子路线,或估计一条具有最小难度的22 分钟的替代子路线,依此类推。
顾问根据用户指定的目标以及有关道路和交通状况的可用统计数据选择最有效(成本最低)的整体路线。 统计数据越准确,建议就越好。 例如,如果没有经常通知顾问交通拥堵、道路封闭和道路状况不佳,那么推荐的路线可能会变得效率低下(成本高)。
4.2 About Optimizer Components
优化器包含三个组件:转换器(Query Transformer)、估计器(Estimator)和计划生成器(Plan Generator)。
| 阶段 | 操作 | 描述 |
|---|---|---|
| 1 | 优化器决定改变查询的形式是否有助于优化器生成更好的执行计划。 | 转换器 |
| 2 | 优化器根据数据字典中的统计信息估计每个计划的成本。 | 估计器 |
| 3 | 优化器比较计划的成本并选择成本最低的计划(称为执行计划)传递给行源生成器。 | 计划生成器 |
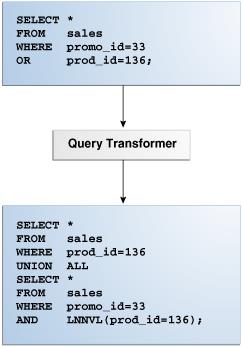
4.2.1 Query Transformer
对于某些语句,查询转换器会确定将原始 SQL 语句重写为语义等效的成本更低的 SQL 语句是否有利。
当存在可行的替代方案时,数据库会分别计算替代方案的成本并选择成本最低的替代方案。 下图显示了查询转换器将使用 OR 的输入查询重写为使用 UNION ALL 的输出查询。
4.2.2 Estimator
估算器是优化器的组件,用于确定给定执行计划的总体成本。
估算器使用三种不同的度量来确定成本:
- Selectivity(选择性)
查询选择的行集合中行的百分比,0 表示没有行,1 表示所有行。 选择性与查询谓词相关联,例如 WHERE条件。当选择性值接近0时,谓词变得更具选择性,而当值接近1时,谓词变得更不具选择性。 - Cardinality(基数)
基数是执行计划中每个操作返回的行数。 此输入对于获得最佳计划至关重要,对于所有成本函数都是通用的。 估算器可以从 DBMS_STATS 收集的表统计信息中推导出基数,或者在考虑谓词(过滤器、联结等)、DISTINCT 或 GROUP BY 操作等的影响后推导出基数。 执行计划中的Rows列显示估计的基数。 - Cost(成本)
此度量表示使用的工作或资源的单位。 查询优化器使用磁盘 I/O、CPU 使用率和内存使用率作为工作单元。
4.2.2.1 Selectivity
选择性表示行集(表,视图或联结结果)中的一小部分行。
谓词从行集中过滤特定数量的行。 因此,谓词的选择性表明有多少行通过了谓词测试。 选择性范围从 0.0 到 1.0。 0.0 的选择性意味着没有从行集中选择任何行,而 1.0 的选择性意味着所有行都被选中。 当值接近 0.0 时,谓词变得更具选择性,而当值接近 1.0 时,谓词变得更不具有选择性。
当统计信息可用时,估计器使用它们来估计选择性。 假设有 150 个不同的员工姓氏(在Oracle中的术语为NDV,即Nunber of Distinct Values)。 对于相等谓词 last_name = ‘Smith’,选择性是 last_name 的不同值的数量 n 的倒数,在此示例中为 0.006(即1/150),因为查询选择包含 150 个不同值中的 1 个的行。换句话说,NDV越大,选择性越强。
也是计算是基于数据分布均匀的前提下,如果数据分布不均匀(Data Skew),例如出现value skew和range skew,则还需要借助列上的直方图统计信息。
当统计信息不可用时,则依赖于初始化参数OPTIMIZER_DYNAMIC_SAMPLING等一些设定。
Cardinality
基数是执行计划中每个操作返回的行数。基数估计必须尽可能准确,因为它们会影响执行计划的所有方面。 当优化器确定连接的成本时,基数很重要。基数对于确定排序成本也很重要。
当数据分布均匀且为等值查询时,Cardinality = 行数 x Selectivity
Cost
优化器成本模型考虑了查询预计使用的机器资源。执行时间是成本的函数,但成本并不直接等同于时间。换句话说,执行得快并不表示成本低。
4.2.3 Plan Generator
计划生成器通过尝试不同的访问路径、连接方法和连接顺序来探索查询块的各种计划。
由于数据库可以使用各种组合来产生相同的结果,因此许多计划都是可能的。 优化器选择成本最低的计划。
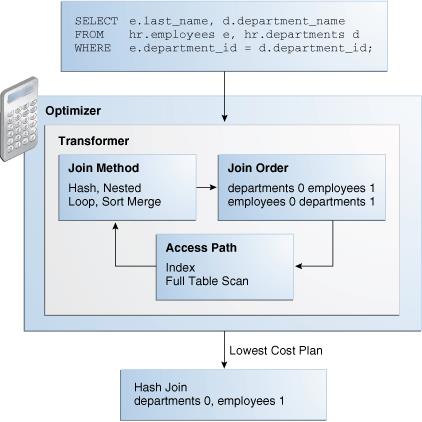
优化器使用内部阈值来减少它在找到最低成本计划时尝试的计划数量。
4.3 About Automatic Tuning Optimizer
优化器根据调用方式执行不同的操作。数据库提供以下类型的优化:
-
正常优化
优化器编译 SQL 并生成执行计划。 正常模式为大多数 SQL 语句生成合理的计划。 在正常模式下,优化器在严格的时间限制下运行,通常只有几分之一秒,在此期间它必须找到最佳计划。 -
SQL Tuning Advisor 优化
当 SQL Tuning Advisor 调用优化器时,优化器会执行额外的分析以进一步改进在正常模式下生成的计划。 优化器输出不是执行计划,而是一系列操作,以及它们的理由和产生明显更好的计划的预期收益。
4.4 About Adaptive Query Optimization
在 Oracle 数据库中,自适应查询优化使优化器能够对执行计划进行运行时调整,并发现可以产生更好统计数据的附加信息。
当现有统计数据不足以生成最佳计划时,自适应优化很有帮助。 下图显示了自适应查询优化的功能集。
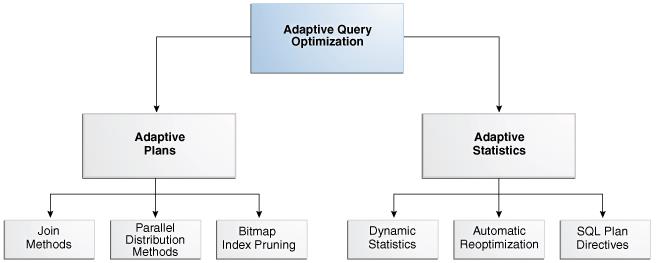
4.4.1 Adaptive Query Plans
自适应查询计划使优化器能够在执行期间为语句做出计划决策。
自适应查询计划使优化器能够在运行时修复某些类别的问题,默认情况下启用。
4.4.1.1 About Adaptive Query Plans
自适应查询计划包含多个预先确定的子计划和一个优化器统计信息收集器。 根据执行期间收集的统计信息,动态计划协调器在运行时选择最佳计划。
优化器统计信息收集器是在关键点插入计划的行源,用于收集与基数和直方图相关的运行时统计信息。 这些统计信息帮助优化器在多个子计划之间做出最终决定。
4.4.1.2 Purpose of Adaptive Query Plans
优化器根据执行期间获得的统计信息调整计划的能力可以大大提高查询性能。
自适应查询计划很有用,因为优化器偶尔会因为基数估计错误而选择次优的默认计划。 优化器在运行时根据实际执行统计数据选择最佳计划的能力会产生更优化的最终计划。 选择最终计划后,优化器将其用于后续执行,从而确保不重用次优计划。
4.4.1.3 How Adaptive Query Plans Work
选择联结方法的示例:
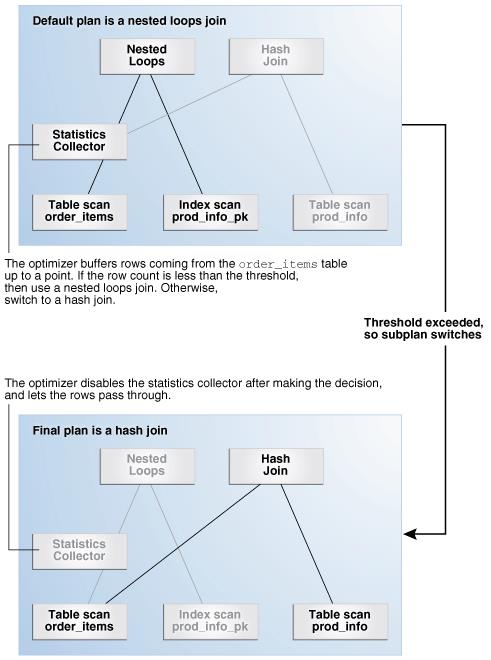
4.4.1.4 When Adaptive Query Plans Are Enabled
默认情况下启用自适应查询计划。
设置以下初始化参数时,将启用自适应计划:
- OPTIMIZER_ADAPTIVE_PLANS 为 TRUE(默认)
- OPTIMIZER_FEATURES_ENABLE 为 12.1.0.1 或更高版
- OPTIMIZER_ADAPTIVE_REPORTING_ONLY 为 FALSE(默认)
自适应计划控制以下优化:
- 嵌套循环和哈希联结选择
- 星形变换位图修剪
- 自适应并行分布方法
4.4.2 Adaptive Statistics
当查询谓词过于复杂而无法单独依赖基表统计信息时,优化器可以使用自适应统计信息。 默认情况下,禁用自适应统计信息(OPTIMIZER_ADAPTIVE_STATISTICS 为 false)。
4.4.2.1 Dynamic Statistics
动态统计是一种优化技术,指数据库执行递归 SQL 语句来扫描表块的小随机样本以估计谓词基数。
在 SQL 编译期间,优化器通过考虑可用的统计信息是否足以生成最佳计划来决定是否使用动态统计信息。 如果可用统计信息不足,则优化器使用动态统计信息来扩充统计信息。 为了提高优化器决策的质量,优化器可以对表扫描、索引访问、连接和 GROUP BY 操作使用动态统计信息。
4.4.2.2 Automatic Reoptimization
在自动重新优化中,优化器会在初始执行后更改后续执行的计划。
优化器使用上次执行期间收集的信息来帮助确定替代计划。 优化器可以多次重新优化查询,每次都收集额外的数据并进一步改进计划。
4.4.2.3 SQL Plan Directives(指示)
SQL 计划指示是优化器用来生成更优化计划的附加信息。
该指示是优化器的“自我标注”,表明它错误估计了某些类型谓词的基数,并且还提醒 DBMS_STATS 收集所需的统计信息以在未来纠正错误估计。
数据库自动创建指示,并将它们存储在 SYSAUX 表空间中。 您可以使用 PL/SQL 包 DBMS_SPD 更改、保存到磁盘和传输指示。
4.4.2.4 When Adaptive Statistics Are Enabled
默认禁用。设置以下初始化参数后,将启用自适应统计:
- OPTIMIZER_ADAPTIVE_STATISTICS 为 TRUE(默认为 FALSE)
- OPTIMIZER_FEATURES_ENABLE 为 12.1.0.1 或更高版本
将 OPTIMIZER_ADAPTIVE_STATISTICS 设置为 TRUE 可启用以下功能:
- SQL 计划指示
- 加入基数的统计反馈
- 自适应动态采样
4.5 About Approximate Query Processing
近似查询处理是一组优化技术,通过在可接受的误差范围内计算结果来加速分析查询。
商业智能 (BI) 查询严重依赖各类聚合函数(如 COUNT DISTINCT、SUM、RANK 和 MEDIAN)。 BI 应用程序具有以下要求的情况并不少见:
- 大数据集处理
- 实时响应
- 以上两者
对于大型数据集,精确聚合查询会消耗大量内存,通常会溢出到临时空间,并且速度可能慢得令人无法接受。 应用程序通常对泛模式比精确结果更感兴趣,因此客户愿意为了速度而牺牲精确性。 例如,如果目标是显示描述最受欢迎产品的条形图,那么产品销量是 100 万件还是 99.9 万件在统计上无关紧要。
Oracle 数据库通过近似查询处理实现其解决方案。 通常,近似聚合的准确度超过 97%(具有 95% 的置信度),但处理时间要快几个数量级。 数据库使用较少的 CPU,并避免写入临时文件的 I/O 成本。
4.5.1 Approximate Query Initialization Parameters
通过使用 APPROX_FOR_* 初始化参数,您可以在不更改现有代码的情况下实现近似查询处理。
相关初始化参数为:
- APPROX_FOR_COUNT_DISTINCT
- APPROX_FOR_COUNT_DISTINCT
- APPROX_FOR_PERCENTILE
4.5.2 Approximate Query SQL Functions
近似查询处理使用 SQL 函数为可以接受近似值的探索性查询提供实时响应。它们包括:
- APPROX_COUNT
- APPROX_COUNT_DISTINCT
- APPROX_COUNT_DISTINCT_AGG
- APPROX_COUNT_DISTINCT_DETAIL
- APPROX_MEDIAN
- APPROX_PERCENTILE
- APPROX_RANK
- APPROX_SUM
4.6 About SQL Plan Management(SPM)
SQL 计划管理使优化器能够自动管理执行计划,确保数据库仅使用已知或经过验证的计划。
SQL 计划管理可以建立一个 SQL 计划基线,其中包含每个 SQL 语句的一个或多个可接受的计划。 优化器可以访问和管理 SQL 语句的计划历史和 SQL 计划基线。 主要目标如下:
- 识别可重复的 SQL 语句
- 维护一组 SQL 语句的计划历史记录,以及可能的 SQL 计划基线
- 检测不在计划历史中的计划
- 检测不在 SQL 计划基线中的可能更好的计划
4.7 About Quarantined(隔离) SQL Plans
您可以将 Oracle 数据库配置为自动隔离因超出资源限制而被 Oracle 数据库资源管理器(资源管理器)终止的 SQL 语句的计划。
SQL 隔离的工作原理
资源管理器可以设置一条SQL 语句的最大预计执行时间,例如20 分钟。 如果语句执行超过此限制,则资源管理器将终止该语句。 但是,该语句在终止之前可能会重复运行,每次执行会浪费 20 分钟的资源。
SQL Quarantine 基础架构(SQL Quarantine)解决了重复浪费资源的问题。 如果语句超过指定的资源限制,则资源管理器将终止执行并“隔离”计划。 (执行一次后不再被执行,除非资源限制向上调整)隔离计划意味着将其放在数据库不会为此语句执行的计划的黑名单中。 请注意,已终止语句的计划是隔离的,而不是语句本身。
SQL 隔离用户界面
DBMS_SQLQ PL/SQL 包使您能够通过指定消耗系统资源的阈值来手动为执行计划创建隔离配置。
4.8 About the Expression Statistics Store (ESS)
Expression Statistics Store (ESS) 是一个由优化器维护的存储库,用于存储有关表达式评估的统计信息。
启用 In-Memory列存储(Database In-Memory选件的功能)后,数据库将 ESS 用于其内存中表达式(IM 表达式)功能。 但是,ESS 独立于 IM 列存储。 ESS 是数据库的永久组件,无法禁用。
数据库使用 ESS 来确定表达式是否“热门”(经常访问),从而确定是否是 IM 表达式的候选。 在查询的硬解析期间,ESS 会在 SELECT 列表、WHERE 子句、GROUP BY 子句等中查找活动表达式。
以上是关于SQL调优指南笔记4:Query Optimizer Concepts的主要内容,如果未能解决你的问题,请参考以下文章