PostgresSQL调优实践:分区表不能统计下推的排查
Posted PostgreSQLChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgresSQL调优实践:分区表不能统计下推的排查相关的知识,希望对你有一定的参考价值。
作者:母延年
在之前的分享中我们提到过,LXDB本质上是基于PGSQL的一个拓展,相当于更换了PG的底层数据结构。本次的实践就是基于对PG分区表无法进行统计下推的问题进行的排查和解决。
下面,开始我们本次的实践分享:
一、问题背景
近日,出于客户提出的需求,我们在LXDB中加入了分区功能。但是在功能上线之后,我们在测试拓展分区表的时候发现count(*)与group by这种分组统计并没有将计算下推到LXDB层去计算,而是将所有数据返回给PG层计算。由于数据格式的不同,在LXDB层的统计与将数据抛给PG层进行统计,两者性能相差了至少两个数量级。因此为了提高统计速度,我们需要进一步调研,为何使用Postgres的分区表后没有将count(*)与group by分组统计下沉到LXDB层中去计算。
在这里再简单介绍一下LXDB,LXDB本质是Postgres的一个拓展,相当于更换了Postgres底层的数据结构,用来解决原生PG多索引数据入库慢、更新效率较差,以及在点查、全文检索、统计分析等场景的薄弱之处。使得PG在单机情况下能做到百亿数据的毫秒级查询统计响应。
二、分区表建表
LXDB作为一款主打轻量级的数据库产品,整体的操作命令都很便捷,建表也只需要三步。
1.创建分区表
CREATE TABLE myn (
ukey text,
i1 integer,
i2 integer,
txt1 text,
txt2 text
)
PARTITION BY RANGE (i1);
2.添加分区
CREATE FOREIGN TABLE myn1 PARTITION OF myn FOR VALUES FROM (1000) TO (2000) SERVER lxdb options(store 'ios');
CREATE FOREIGN TABLE myn2 PARTITION OF myn FOR VALUES FROM (2000) TO (3000) SERVER lxdb options(store 'ios');
CREATE FOREIGN TABLE myn3 PARTITION OF myn FOR VALUES FROM (3000) TO (4000) SERVER lxdb options(store 'ios');
CREATE FOREIGN TABLE myn4 PARTITION OF myn FOR VALUES FROM (4000) TO (5000) SERVER lxdb options(store 'ios');
3.插入数据
INSERT INTO myn(ukey,i1, i2, txt1,txt2) VALUES ('1111',1500, 2, 'txt2', 'txt2');
INSERT INTO myn(ukey,i1, i2, txt1,txt2) VALUES ('1112',2500, 4, 'txt1', 'txt2');
INSERT INTO myn(ukey,i1, i2, txt1,txt2) VALUES ('1113',3500, 6, 'txt2', 'txt2');
INSERT INTO myn(ukey,i1, i2, txt1,txt2) VALUES ('1114',4500, 8, 'txt1', 'txt2');
三、问题复现与分析排查
1.问题复现
首先是执行查询:
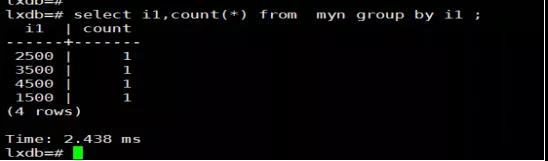
而后截获在LXDB里真实下发的SQL。
从截获的SQL中可以看出,系统在分组统计中暴力的将所有数据返回给了PG,结果导致了分组统计性能非常差。
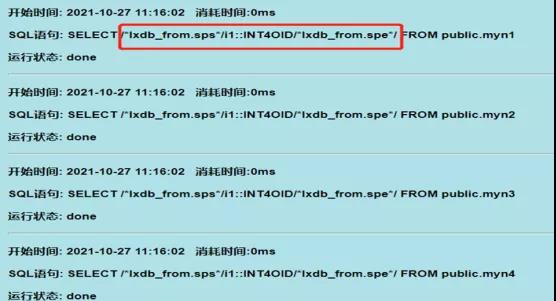
2.开始调试
首先,通过GDB调试正常分组统计的堆栈:
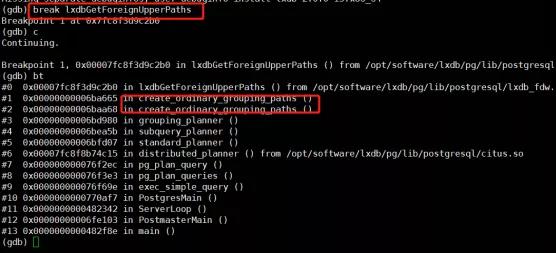
输入gdb postgres 15627命令后,上图红框处的lxdbGetForeignUpperPaths是LXDB中的分组统计的处理函数。
在这个堆栈的基础上,我们知道了函数调用堆栈是根据堆栈中的函数,一层一层的进行分析,最终发现调用堆栈差异在create_ordinary_grouping_paths这个方法上(见下图)。
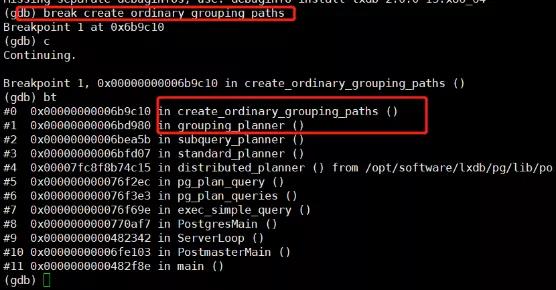
随后,通过pg源码分析我们在堆栈中找到的用来进行分组统计的create_ordinary_grouping_paths这个函数。
我们可以看到分区表的执行逻辑出现了问题(见下图),PARTITIONWISE_AGGREGATE_PARTIAL这个变量导致分区表过早的return。
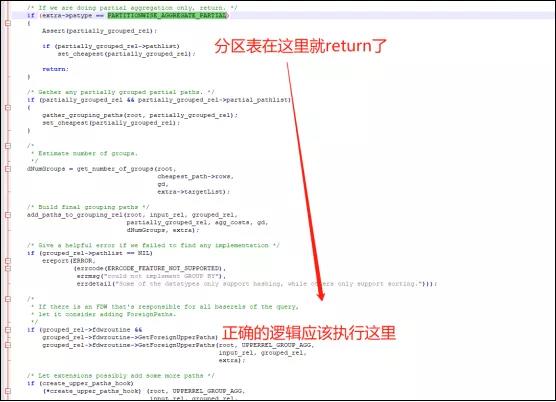
跟随这个问题,我们深入排查下PARTITIONWISE_AGGREGATE_PARTIAL这个变量的意思(见下图):
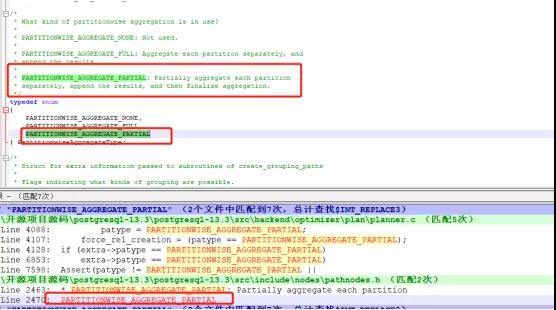
但是说实话,这里我也没太理解什么意思,只好继续查看赋值的地方。发现通过如下语句可以改变这里的赋值:set enable_partitionwise_aggregate=on;
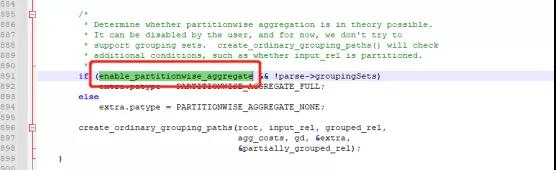
3.继续验证,问题解决
首先,执行一下SQL,确认一下通过该设置是否可以解决问题。

通过调整设置,确实使得分组统计下推到LXDB层进行了计算,问题已经得到了解决。
顺便查找了下资料,了解了下partition-wise aggregation的含义:
partition-wise aggregation允许对每个分区分别执行的分区表进行分组或聚合。如果GROUP BY子句不包括分区键,则只能在每个分区的基础上执行部分聚合,并且必须稍后执行最终处理。由于partitionwise分组或聚合可能在计划期间占用大量CPU时间和内存,因此默认设置为关闭。
以上是关于PostgresSQL调优实践:分区表不能统计下推的排查的主要内容,如果未能解决你的问题,请参考以下文章