90%的人以为会用ThreadPoolExecutor了,看了这10张图再说吧
Posted 程序新视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了90%的人以为会用ThreadPoolExecutor了,看了这10张图再说吧相关的知识,希望对你有一定的参考价值。
在阿里巴巴手册中有一条建议:
【强制】线程池不允许使用 Executors 去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
如果经常基于Executors提供的工厂方法创建线程池,很容易忽略线程池内部的实现。特别是拒绝策略,因使用Executors创建线程池时不会传入这个参数,直接采用默认值,所以常常被忽略。
下面我们就来了解一下线程池相关的实现原理、API以及实例。
线程池的作用
在实践应用中创建线程池主要是为了:
- 减少资源开销:减少每次创建、销毁线程的开销;
- 提高响应速度:请求到来时,线程已创建好,可直接执行,提高响应速度;
- 提高线程的可管理性:线程是稀缺资源,需根据情况加以限制,确保系统稳定运行;
ThreadPoolExecutor
ThreadPoolExecutor可以实现线程池的创建。ThreadPoolExecutor相关类图如下:
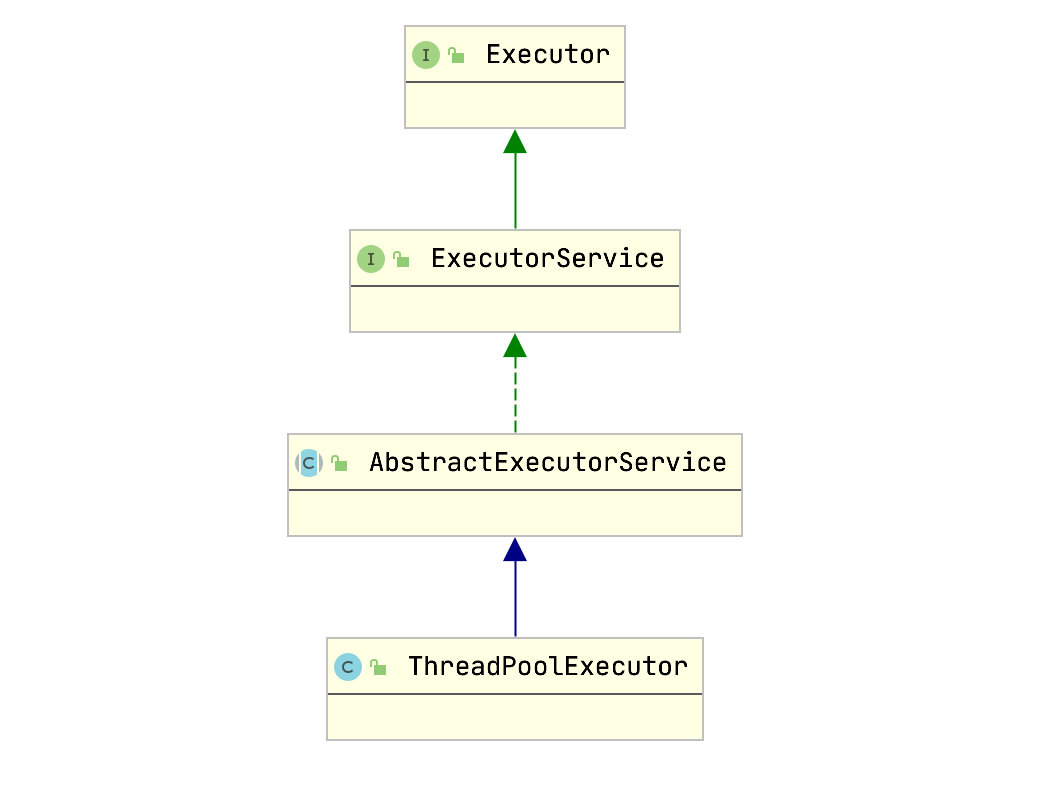
从类图可以看出,ThreadPoolExecutor最终实现了Executor接口,是线程池创建的真正实现者。
Executor两级调度模型

在HotSpot虚拟机中,Java中的线程将会被一一映射为操作系统的线程。在Java虚拟机层面,用户将多个任务提交给Executor框架,Executor负责分配线程执行它们;在操作系统层面,操作系统再将这些线程分配给处理器执行。
ThreadPoolExecutor的三个角色
任务
ThreadPoolExecutor接受两种类型的任务:Callable和Runnable。
- Callable:该类任务有返回结果,可以抛出异常。通过submit方法提交,返回Future对象。通过get获取执行结果。
- Runnable:该类任务只执行,无法获取返回结果,在执行过程中无法抛异常。通过execute或submit方法提交。
任务执行器
Executor框架最核心的接口是Executor,它表示任务的执行器。
通过上面类图可以看出,Executor的子接口为ExecutorService。再往底层有两大实现类:ThreadPoolExecutor和ScheduledThreadPoolExecutor(集成自ThreadPoolExecutor)。
执行结果
Future接口表示异步的执行结果,它的实现类为FutureTask。
三个角色之间的处理逻辑图如下:

线程池处理流程

一个线程从被提交(submit)到执行共经历以下流程:
- 线程池判断核心线程池里是的线程是否都在执行任务,如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下一个流程;
- 线程池判断工作队列是否已满。如果工作队列没有满,则将新提交的任务储存在这个工作队列里。如果工作队列满了,则进入下一个流程;
- 线程池判断其内部线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已满了,则交给饱和策略来处理这个任务。
线程池在执行execute方法时,主要有以下四种情况:
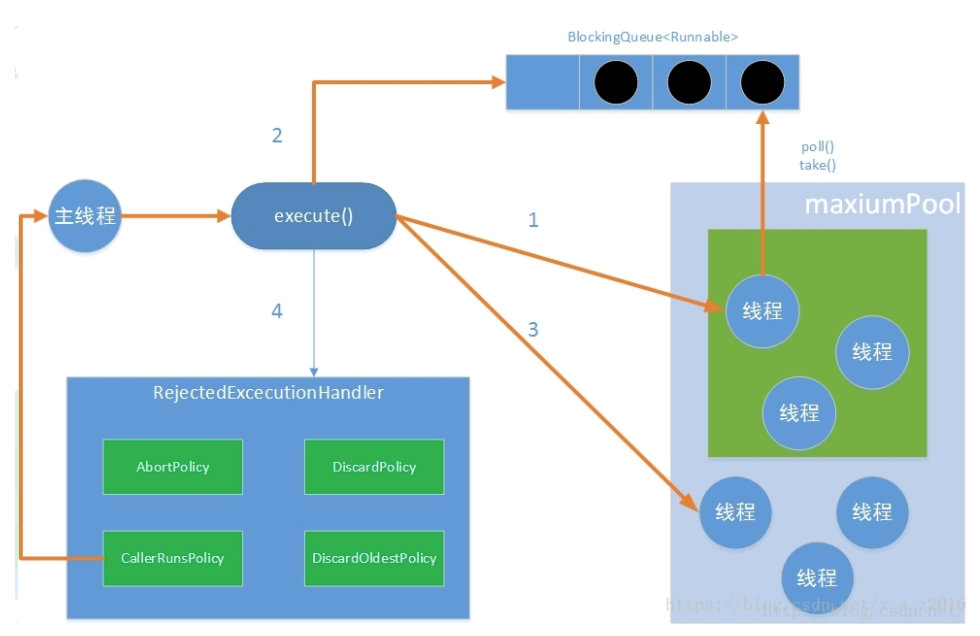
- 如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(需要获得全局锁);
- 如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue;
- 如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(需要获得全局锁);
- 如果创建新线程将使当前运行的线程超出maxiumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
线程池采取上述的流程进行设计是为了减少获取全局锁的次数。在线程池完成预热(当前运行的线程数大于或等于corePoolSize)之后,几乎所有的excute方法调用都执行步骤二。
线程的状态流转
顺便再回顾一下线程的状态的转换,在JDK中Thread类中提供了一个枚举类,例举了线程的各个状态:
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
一共定义了6个枚举值,其实代表的是5种类型的线程状态:
- NEW:新建;
- RUNNABLE:运行状态;
- BLOCKED:阻塞状态;
- WAITING:等待状态,WAITING和TIMED_WAITING可以归为一类,都属于等待状态,只是后者可以设置等待时间,即等待多久;
- TERMINATED:终止状态;
线程关系转换图:
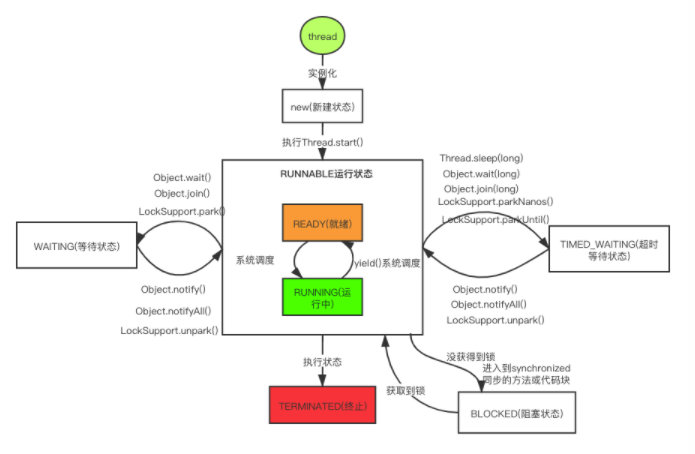
当new Thread()说明这个线程处于NEW(新建状态);调用Thread.start()方法表示这个线程处于RUNNABLE(运行状态);
但是RUNNABLE状态中又包含了两种状态:READY(就绪状态)和RUNNING(运行中)。调用start()方法,线程不一定获得了CPU时间片,这时就处于READY,等待CPU时间片,当获得了CPU时间片,就处于RUNNING状态。
在运行中调用synchronized同步的代码块,没有获取到锁,这时会处于BLOCKED(阻塞状态),当重新获取到锁时,又会变为RUNNING状态。在代码执行的过程中可能会碰到Object.wait()等一些等待方法,线程的状态又会转变为WAITING(等待状态),等待被唤醒,当调用了Object.notifyAll()唤醒了之后线程执行完就会变为TERMINATED(终止状态)。
线程池的状态
线程池中状态通过2个二进制位(bit)来表示线程池的5个状态:RUNNING、SHUTDOWN、STOP、TIDYING和TERMINATED:
- RUNNING:线程池正常工作的状态,在 RUNNING 状态下线程池接受新的任务并处理任务队列中的任务;
- SHUTDOWN:调用
shutdown()方法会进入 SHUTDOWN 状态。在 SHUTDOWN 状态下,线程池不接受新的任务,但是会继续执行任务队列中已有的任务; - STOP:调用
shutdownNow()会进入 STOP 状态。在 STOP 状态下线程池既不接受新的任务,也不处理已经在队列中的任务。对于还在执行任务的工作线程,线程池会发起中断请求来中断正在执行的任务,同时会清空任务队列中还未被执行的任务; - TIDYING:当线程池中的所有执行任务的工作线程都已经终止,并且工作线程集合为空的时候,进入 TIDYING 状态;
- TERMINATED:当线程池执行完
terminated()钩子方法以后,线程池进入终态 TERMINATED;
ThreadPoolExecutor API
ThreadPoolExecutor创建线程池API:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
参数解释:
- corePoolSize :线程池常驻核心线程数。创建线程池时,线程池中并没有任何线程,当有任务来时才去创建线程,执行任务。提交一个任务,创建一个线程,直到需要执行的任务数大于线程池基本大小,则不再创建。当创建的线程数等于corePoolSize 时,会加入设置的阻塞队列。
- maximumPoolSize :线程池允许创建的最大线程数。当队列满时,会创建线程执行任务直到线程池中的数量等于maximumPoolSize。
- keepAliveTime :当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
- unit :keepAliveTime的时间单位,可选项:天(DAYS)、小时(HOURS)、分钟(MINUTES)、毫秒(MILLISECONDS)、微妙(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微妙)。
- workQueue :用来储存等待执行任务的队列。
- threadFactory :线程工厂,用来生产一组相同任务的线程。主要用于设置生成的线程名词前缀、是否为守护线程以及优先级等。设置有意义的名称前缀有利于在进行虚拟机分析时,知道线程是由哪个线程工厂创建的。
- handler :执行拒绝策略对象。当达到任务缓存上限时(即超过workQueue参数能存储的任务数),执行拒接策略。也就是当任务处理不过来的时候,线程池开始执行拒绝策略。JDK 1.5提供了四种饱和策略:
- AbortPolicy:默认,直接抛异常;
- 只用调用者所在的线程执行任务,重试添加当前的任务,它会自动重复调用execute()方法;
- DiscardOldestPolicy:丢弃任务队列中最久的任务;
- DiscardPolicy:丢弃当前任务;
适当的阻塞队列
当创建的线程数等于corePoolSize,会将任务加入阻塞队列(BlockingQueue),维护着等待执行的Runnable对象。
阻塞队列通常有如下类型:
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。可以限定队列的长度,接收到任务时,如果没有达到corePoolSize的值,则新建线程(核心线程)执行任务,如果达到了,则入队等候,如果队列已满,则新建线程(非核心线程)执行任务,又如果总线程数到了maximumPoolSize,并且队列也满了,则发生错误。
- LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。这个队列在接收到任务时,如果当前线程数小于核心线程数,则新建线程(核心线程)处理任务;如果当前线程数等于核心线程数,则进入队列等待。由于这个队列没有最大值限制,即所有超过核心线程数的任务都将被添加到队列中,这也就导致了maximumPoolSize的设定失效,因为总线程数永远不会超过corePoolSize。
- PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
- DelayQueue: 一个使用优先级队列实现的无界阻塞队列。队列内元素必须实现Delayed接口,这就意味着传入的任务必须先实现Delayed接口。这个队列在接收到任务时,首先先入队,只有达到了指定的延时时间,才会执行任务。
- SynchronousQueue: 一个不存储元素的阻塞队列。这个队列在接收到任务时,会直接提交给线程处理,而不保留它,如果所有线程都在工作就新建一个线程来处理这个任务。所以为了保证不出现【线程数达到了maximumPoolSize而不能新建线程】的错误,使用这个类型队列时,maximumPoolSize一般指定成Integer.MAX_VALUE,即无限大。
- LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque: 一个由链表结构组成的双向阻塞队列。
明确的拒绝策略
当任务处理不过来时,线程池开始执行拒绝策略。
支持的拒绝策略:
- ThreadPoolExecutor.AbortPolicy: 丢弃任务并抛出RejectedExecutionException异常。 (默认)
- ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务。(重复此过程)
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务。
线程池关闭
shutdown:将线程池状态置为SHUTDOWN,并不会立即停止。停止接收外部submit的任务,内部正在跑的任务和队列里等待的任务,会执行完后,才真正停止。shutdownNow:将线程池状态置为STOP。企图立即停止,事实上不一定,跟shutdown()一样,先停止接收外部提交的任务,忽略队列里等待的任务,尝试将正在跑的任务interrupt中断(如果线程未处于sleep、wait、condition、定时锁状态,interrupt无法中断当前线程),返回未执行的任务列表。awaitTermination(long timeOut, TimeUnit unit)当前线程阻塞,直到等所有已提交的任务(包括正在跑的和队列中等待的)执行完或者等超时时间到或者线程被中断,抛出InterruptedException,然后返回true(shutdown请求后所有任务执行完毕)或false(已超时)。
Executors
Executors是一个帮助类,提供了创建几种预配置线程池实例的方法:newSingleThreadExecutor、newFixedThreadPool、newCachedThreadPool等。
如果查看源码就会发现,Executors本质上就是实现了几类默认的ThreadPoolExecutor。而阿里巴巴开发手册,不建议采用Executors默认的,让使用者直接通过ThreadPoolExecutor来创建。
Executors.newSingleThreadExecutor()
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())
该类型线程池的结构图:
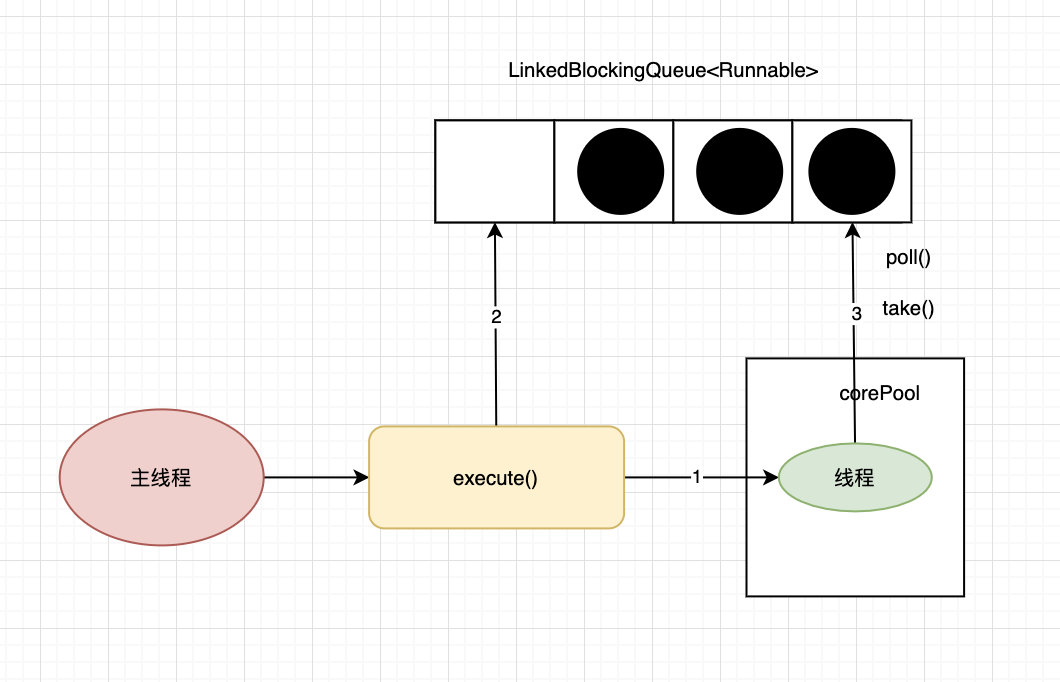
该线程池的特点:
- 只会创建一条工作线程处理任务;
- 采用的阻塞队列为LinkedBlockingQueue;
Executors.newFixedThreadPool()
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
该类型线程池的结构图:
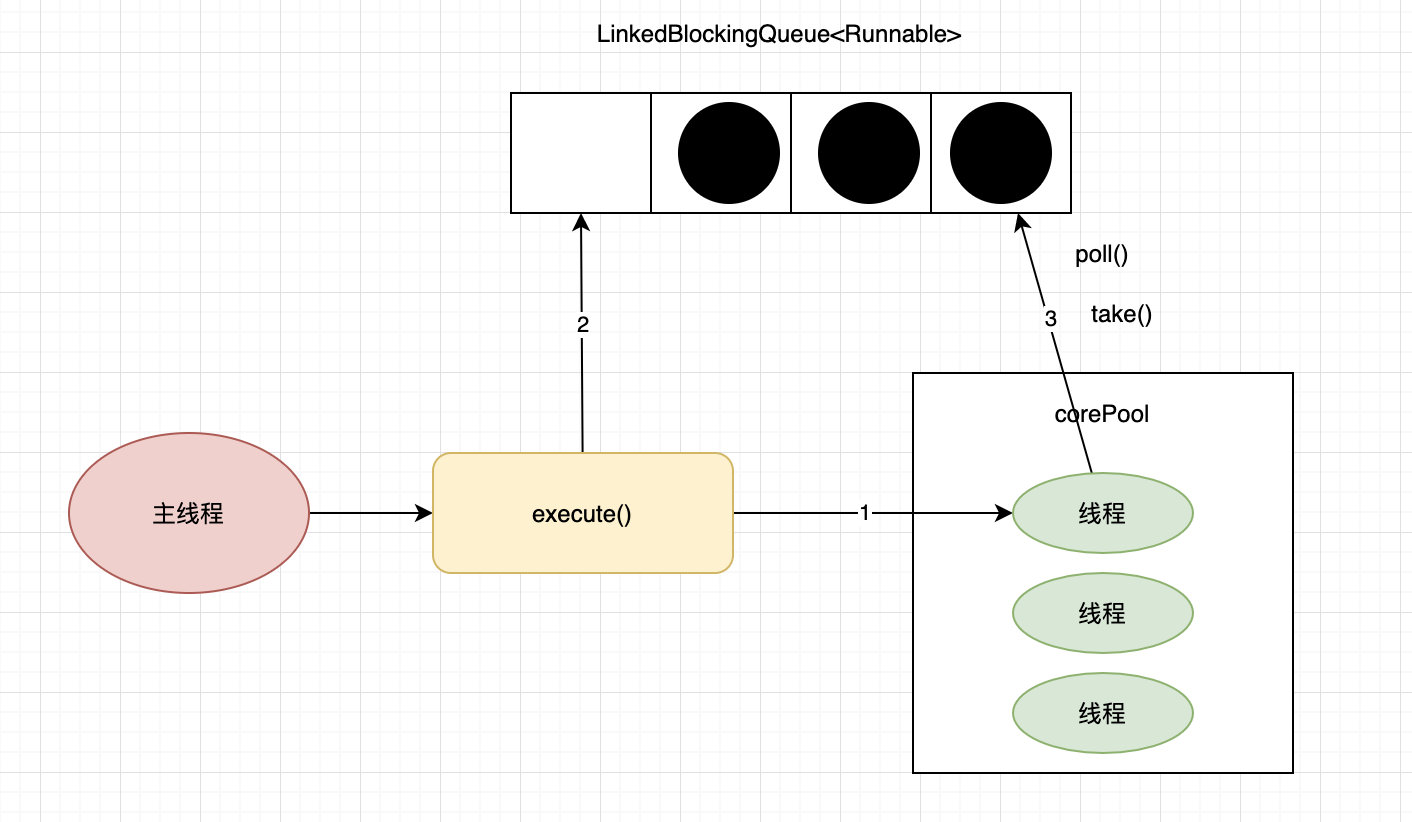
该线程池的特点:
- 固定大小;
- corePoolSize和maximunPoolSize都为用户设定的线程数量nThreads;
- keepAliveTime为0,意味着一旦有多余的空闲线程,就会被立即停止掉;但这里keepAliveTime无效;
- 阻塞队列采用了LinkedBlockingQueue,一个无界队列;
- 由于阻塞队列是一个无界队列,因此永远不可能拒绝任务;
- 由于采用了无界队列,实际线程数量将永远维持在nThreads,因此maximumPoolSize和keepAliveTime将无效。
Executors.newCachedThreadPool()
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
该类型线程池的结构图:

该线程池的特点:
- 可以无限扩大;
- 比较适合处理执行时间比较小的任务;
- corePoolSize为0,maximumPoolSize为无限大,意味着线程数量可以无限大;
- keepAliveTime为60S,意味着线程空闲时间超过60s就会被杀死;
- 采用SynchronousQueue装等待的任务,这个阻塞队列没有存储空间,这意味着只要有请求到来,就必须要找到一条工作线程处理它,如果当前没有空闲的线程,那么就会再创建一条新的线程。
Executors.newScheduledThreadPool()
创建一个定长线程池,支持定时及周期性任务执行。
new ThreadPoolExecutor(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
该线程池类图:
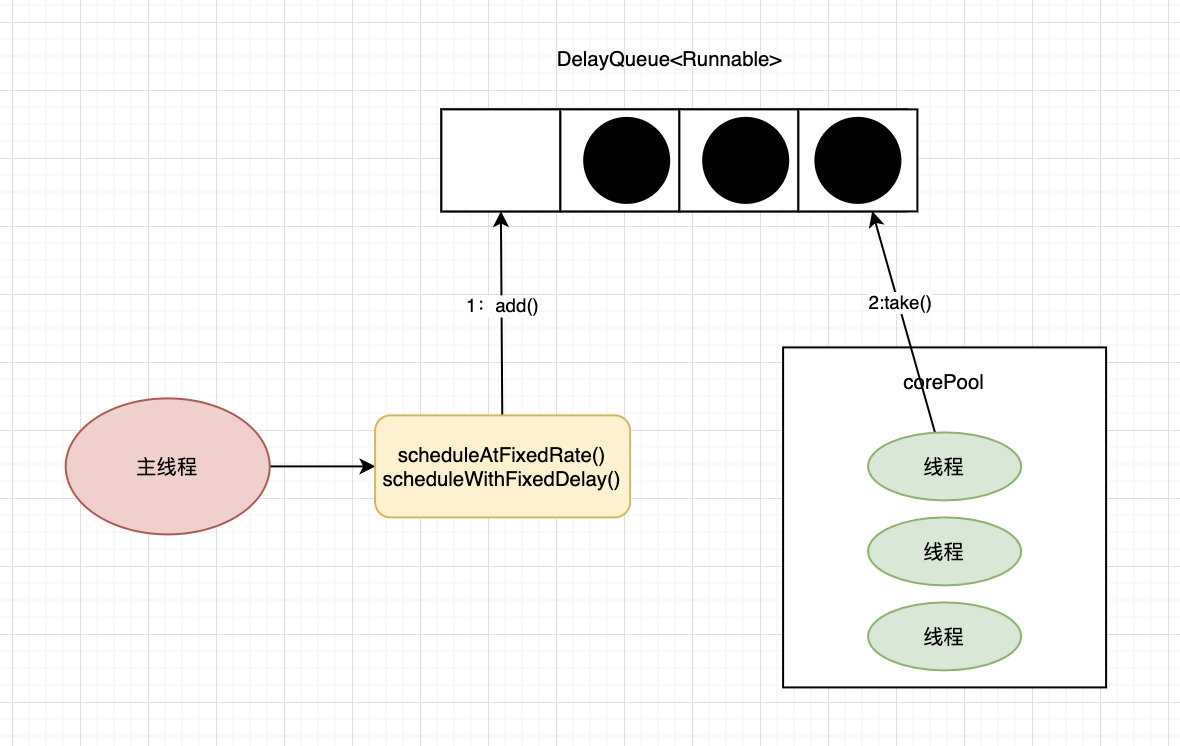
该线程池的特点:
- 接收SchduledFutureTask类型的任务,有两种提交任务的方式:scheduledAtFixedRate和scheduledWithFixedDelay。SchduledFutureTask接收的参数:
- time:任务开始的时间
- sequenceNumber:任务的序号
- period:任务执行的时间间隔
- 采用DelayQueue存储等待的任务;
- DelayQueue内部封装了一个PriorityQueue,它会根据time的先后时间排序,若time相同则根据sequenceNumber排序;
- DelayQueue也是一个无界队列;
- 工作线程执行时,工作线程会从DelayQueue取已经到期的任务去执行;执行结束后重新设置任务的到期时间,再次放回DelayQueue;
Executors.newWorkStealingPool()
JDK8引入,创建持有足够线程的线程池支持给定的并行度,并通过使用多个队列减少竞争。
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
Executors方法的弊端
1)newFixedThreadPool 和 newSingleThreadExecutor:允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)newCachedThreadPool 和 newScheduledThreadPool:允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
合理配置线程池大小
合理配置线程池,需要先分析任务特性,可以从以下角度来进行分析:
- 任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
- 任务的优先级:高,中和低。
- 任务的执行时间:长,中和短。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接。
另外,还需要查看系统的内核数:
Runtime.getRuntime().availableProcessors());
根据任务所需要的CPU和IO资源可以分为:
- CPU密集型任务: 主要是执行计算任务,响应时间很快,CPU一直在运行。一般公式:线程数 = CPU核数 + 1。只有在真正的多核CPU上才能得到加速,优点是不存在线程切换开销,提高了CPU的利用率并减少了线程切换的效能损耗。
- IO密集型任务:主要是进行IO操作,CPU并不是一直在执行任务,IO操作(CPU空闲状态)的时间较长,应配置尽可能多的线程,其中的线程在IO操作时,其他线程可以继续利用CPU,从而提高CPU的利用率。一般公式:线程数 = CPU核数 * 2。
使用实例
任务实现类:
/**
* 任务实现线程
* @author sec
* @version 1.0
* @date 2021/10/30
**/
public class MyThread implements Runnable{
private final Integer number;
public MyThread(int number){
this.number = number;
}
public Integer getNumber() {
return number;
}
@Override
public void run() {
try {
// 业务处理
TimeUnit.SECONDS.sleep(1);
System.out.println("Hello! ThreadPoolExecutor - " + getNumber());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
自定义阻塞提交的ThreadLocalExcutor:
/**
* 自定义阻塞提交的ThreadPoolExecutor
* @author sec
* @version 1.0
* @date 2021/10/30
**/
public class CustomBlockThreadPoolExecutor {
private ThreadPoolExecutor pool = null;
/**
* 线程池初始化方法
*/
public void init() {
// 核心线程池大小
int poolSize = 2;
// 最大线程池大小
int maxPoolSize = 4;
// 线程池中超过corePoolSize数目的空闲线程最大存活时间:30+单位TimeUnit
long keepAliveTime = 30L;
// ArrayBlockingQueue<Runnable> 阻塞队列容量30
int arrayBlockingQueueSize = 30;
pool = new ThreadPoolExecutor(poolSize, maxPoolSize, keepAliveTime,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(arrayBlockingQueueSize), new CustomThreadFactory(),
new CustomRejectedExecutionHandler());
}
/**
* 关闭线程池方法
*/
public void destroy() {
if (pool != null) {
pool.shutdownNow();
}
}
public ExecutorService getCustomThreadPoolExecutor() {
return this.pool;
}
/**
* 自定义线程工厂类,
* 生成的线程名词前缀、是否为守护线程以及优先级等
*/
private static class CustomThreadFactory implements ThreadFactory {
private final AtomicInteger count = new AtomicInteger(0);
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
String threadName = CustomBlockThreadPoolExecutor.class.getSimpleName() + count.addAndGet(1);
t.setName(threadName);
return t;
}
}
/**
* 自定义拒绝策略对象
*/
private static class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 核心改造点,将blockingqueue的offer改成put阻塞提交
try {
executor.getQueue().put(r);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 当提交任务被拒绝时,进入拒绝机制,实现拒绝方法,把任务重新用阻塞提交方法put提交,实现阻塞提交任务功能,防止队列过大,OOM
*/
public static void main(String[] args) {
CustomBlockThreadPoolExecutor executor = new CustomBlockThreadPoolExecutor();
// 初始化
executor.init();
ExecutorService pool = executor.getCustomThreadPoolExecutor();
for (int i = 1; i < 51; i++) {
MyThread myThread = new MyThread(i);
System.out.println("提交第" + i + "个任务");
pool.execute(myThread);
}
pool.shutdown();
try {
// 阻塞,超时时间到或者线程被中断
if (!pool.awaitTermination(60, TimeUnit.SECONDS)) {
// 立即关闭
executor.destroy();
}
} catch (InterruptedException e) {
executor.destroy();
}
}
}
小结
看似简单的线程池创建,其中却蕴含着各类知识,融合贯通,根据具体场景采用具体的参数进行设置才能够达到最优的效果。
总结一下就是:
- 用ThreadPoolExecutor自定义线程池,要看线程的用途。如果任务量不大,可以用无界队列,如果任务量非常大,要用有界队列,防止OOM;
- 如果任务量很大,且要求每个任务都处理成功,要对提交的任务进行阻塞提交,重写拒绝机制,改为阻塞提交。保证不抛弃一个任务;
- 最大线程数一般设为2N+1最好,N是CPU核数;
- 核心线程数,要根据任务是CPU密集型,还是IO密集型。同时,如果任务是一天跑一次,设置为0合适,因为跑完就停掉了;
- 如果要获取任务执行结果,用CompletionService,但是注意,获取任务的结果要重新开一个线程获取,如果在主线程获取,就要等任务都提交后才获取,就会阻塞大量任务结果,队列过大OOM,所以最好异步开个线程获取结果。
博主简介:《SpringBoot技术内幕》技术图书作者,酷爱钻研技术,写技术干货文章。
公众号:「程序新视界」,博主的公众号,欢迎关注~
技术交流:请联系博主微信号:zhuan2quan

参考文章:
[1]https://www.jianshu.com/p/94852bd1a283
[2]https://blog.csdn.net/jek123456/article/details/90601351
[3]https://blog.csdn.net/z_s_z2016/article/details/81674893
[4]https://zhuanlan.zhihu.com/p/33264000
[5]https://www.cnblogs.com/semi-sub/p/13021786.html
以上是关于90%的人以为会用ThreadPoolExecutor了,看了这10张图再说吧的主要内容,如果未能解决你的问题,请参考以下文章
六石编程学:不论是哪个功能,你觉得再没用,会用的人都离不了,所以至少要做到99%