语义分割(研究现状技术基础)
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语义分割(研究现状技术基础)相关的知识,希望对你有一定的参考价值。
前言
语义分割的目标是输入图像的每个像素分配一个标签,即像素级别的物体分类任务;主要是通过算法模型对输入图像的像素进行预测并分类,生成语义标签。如下图所示,

其中一张场景图像及该场景对应的语义分割标签图像,道路所属的所有像素区域都被标注为紫色,即道路类。
随着语义分割技术的不断发展与进步,它可以广泛地应用于人脸分割、医学图像处理和自动驾驶领域的感知应用。在医学图像处理领域中,利用语义分割技术实现病灶点分割、癌细胞分割等功能是目前研究的热点方向。在智能车场景下,语义分割技术应用更为广泛,通常将相机放置于智能车的前方,语义分割技术通过对可行驶区域、行人、车辆等目标进行精准分析,为实现车辆周围环境信息感知提供可能。
目录
一、国内外研究现状
1.1 通用语义分割
FCN:Fully Convolution Network(FCN),也称全卷积网络,2014年,作为语义分割在深度学习领域的开山之作,它第一次将语义分割任务分解成编码器、解码器两大部分;
特点:它将图像分类网絡的最后一层全连接层替换为一系列反卷积层,使得经过下采样的特征图层可以通过反卷积层上采样恢复回输入图像分辨率,从而完成像素级别的物体分类任务。自此,语义分割网络的基本结构大都沿用FCN采用的编码器-解码器(Encoder-Decoder)的结构。
模型思路:该方法将 VGG 基本分类网络作为编码器,将输入的图片经过编码器中的多个卷积层来进行特征提取和下采样操作之后,其分辨率降低为原始输入图片的 1/32 从而得到编码 器输出特征图,然后在解码器阶段通过上采样算法将所得到的特征图恢复到原始图片大 小,得到分割结果。
FCN 对细节信息的不足导致类别之间的边界轮廓等分割不明显。整体网络对小目标物体的分割效果不佳,同时类别之间的上下文关系并没有很好地捕获,导致各个类别之间容易产生混淆。
UNet:随后Olaf Ronneberger 等人提出的UNet,在编码器和解码器之间,通过采用跳跃连接将编码器获取的低级特征信息(Low-level,表征图像的纹理、色彩、明暗、轮廓等信息)和解码器获取的高级特征信息(High-level,富含语音信息、表征物体类别的信息)进行拼接,从而弥补了由于快速下采样而导致的图像边缘细节信息丢失的问题。
U-net 网络在定位准确性和获取上下文信息中需要权衡,影响了模型的效果。同时,U-net 网络在分割的过程中存在很多以像素为中 心的重叠区域,导致计算量大,冗余计算多。
SegNet:2015 年,Badrinarayanan 等人在 FCN 的基础上提出面向城市道路环境的语义分割模型 SegNet。它将反卷积替换为反池化层,利用编码器阶段带索引的池化信息去恢复特征图。
特点:池化层记录像素点的空间位置,为解码器能够快速有效地找回对应的位置提供便利,从而快速有效地找回位置实现精准的上采样。
模型结构:

但是由于 SegNet 对特征信息并没有很好地融合,物体边界轮廓的分割效果较差。
RefineNet:为了更好地融合特征,2017 年 Lin 等人提出了 RefineNet 网络模型,该模型的主要思想是将不同分辨率的特征图以特定的方式进行融合,使用这种融合方式主要是为 了解决小目标物体的分割精度低的问题。
由于这样的融合操作使得整体网络结构 较复杂,不免会有参数量大的缺点。
DeepLab V1:提出的膨胀卷积(空洞卷积)在不增加模型复杂的的情况下增大了模型的感受野,并在最终的分类阶段结合条件随机场(Conditional Random Field,CRF)来修正分割结果。
空洞卷积结构应用于语义分割领域最具有代表性的工作是由谷歌公司提出的 DeepLab 系列模型。2014 年提出的 DeepLab v1 模型使用不同采样率的空洞卷积来聚 合不同尺度的感受野从而解决多尺度目标的分割问题。为了得到更加精细的结果,在后 处理环节使用了条件随机场算法。同时,在论文中也引入了多尺度训练的技巧,为之后 的方法提高语义分割精度提供了参考。
DeepLab V2 :在DeepLab V1基础上通过编码器和解码器中加入ASPP(Atrous Spatial Pyramid Pooling)模块,使得网络可以提取不同大小特征图的信息进而增加感受野,从而提升分割表现。
2017 年,Chen 通过改进 DeepLab v1 模型提出了 DeepLab v2 模型,模型中通过带空洞卷积的空间池化金字塔 ASPP(Atrous Sptial Pyramid Pooling)结构进一步聚合不 同尺度的感受野并捕捉图像的上下文信息。同样地,同年所提出的 DeepLab v3 模型通过将全局平均池化和 1 *1卷积引入到 ASPP 结构中来捕获全局信息。但是 DeepLab v3 模型分辨率恢复环节较为粗糙,同时由于采用空洞卷积来聚合感受野信息,这极大的增加了内存消耗。
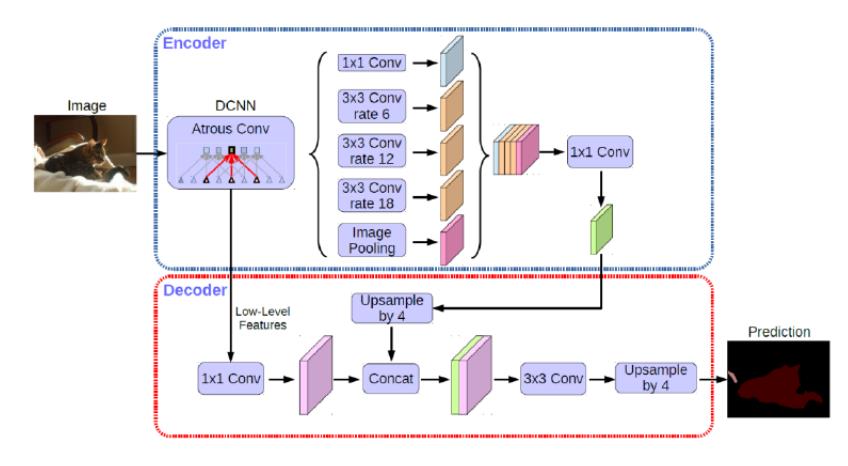
DeepLab 的 v3+:为改进 DeepLab v3 网络模型的缺点,2018 年 DeepLab 的 v3+网络模型被提出, 新版本的网络结构以改进版的 Xception作为基础网络,并在 DeepLab v3 的基础上加 入解码器,在解码器中直接将编码器的输出上采样4倍,使其分辨率和低层特征图一致, 对物体边缘信息有很好的保留。
模型结构:
PSPNet:通过“不同尺寸的池化层”并利用“金字塔池化结构”更好地提取局部上下文信息和全局信息从而达到良好地分割变现。
2017 年 Zhao 等人提出的 PSPNet 网络通过 使用不同内核大小的池化层完成多尺度信息的融合,并使用全局池化层为整个网络提供 相应的全局信息,有利于细节信息的把握。另外,网络中加入了额外的深度监督损失。
1.2 实时语义分割
传统语义分割将研究重点定位于提高模型的分割表和评价指标,而不考虑摸型的计算效率,因此不利于模型被部署于自动驾驶、盲人视觉辅助等实时性要求极高的环境感知应用。
实时语义分割对比非实时语义分割,如下图所示:
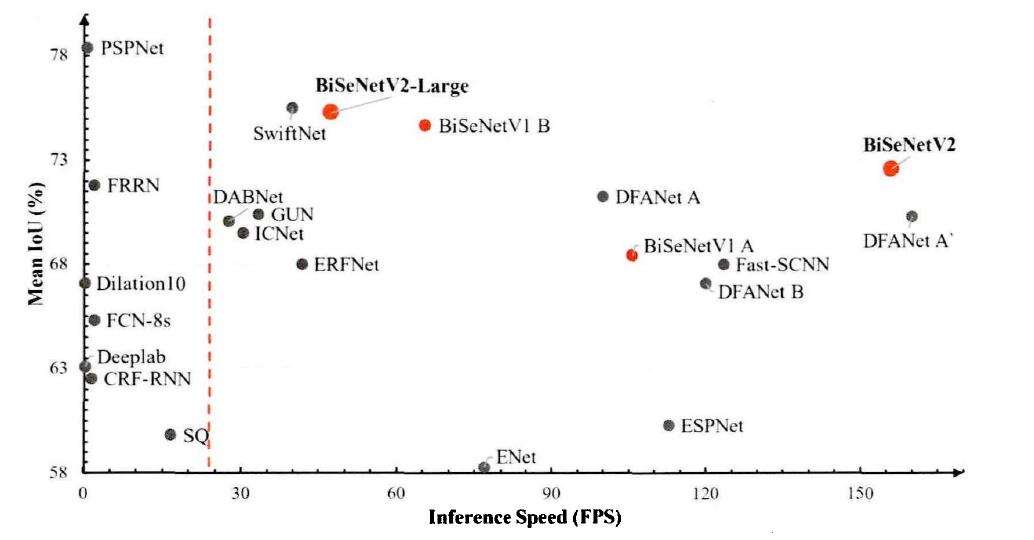
红色虚线右侧代表实时语义分割模型,横坐标代表每秒的运算帧数,纵坐标代表模型在Cityscape测试集上的表现指标。实时语义分割随着ENet 的问世而得到了广泛研究。
实时语义分割研究方案主要分为三类:
1)设计轻量化模块结构,如DUpsampling模块、ERF-PSPNet采用的残差分解卷积模块等;
2)设计新型网络设计范式,如ICNet 和 BiSeNet采用的多支路进行信息补充的结构、将超分辨率算法引入指导低分辨率图像语义分割的方式、利用知识蒸馏指导实时语义分割网络的训练等;
3)采用轻量级基础网络提取低级特征信息,如SwiftNet和DFANet等。
ENet:采用残差网络结构和轻量的模块设计提高了模型的计算效率。ERFNet 和 ERF-PSPNet 利用残差分解卷积模块在保证良好特征抽取能力的基础上进一步减少计算参数从而提升计算效率。此外,基于数据的上采样池化模块(DUpsampling)使得模型可以在更小的特征图上恢复信息,进而可以在低分辨率特征图上获取信息,从而减少运算量。
ICNet 和 BiSeNet:为了让实时语义分割的输出结果在兼具运算效率的同时具有更加精细的空间细节,学界对ICNet和BiSeNet这类多支路网络结构进行了大量研究。它们的具体思路是将网络结构分成两条支路,其中一条深层网络支路用来处理低分辨率的图像,去提取出图像的语义信息从而减少计算量;另一条浅层网络支路用来处理高分辨率图像,去获取低级的空间分布特征信息从而修正语义信息的空间精细程度,最终融合层将各支路信息通过相关模块进行特征融合。这类网络在输出精细程度、语义信息提取能力和计算效率上进行了良好的平衡。
2018 年,Yu 等人提出了 BiSeNet(Bilateral Segmentation Network)将语义分割 任务分为两大路径:空间路径和上下文路径。其中空间路径主要用于解决空间信息的缺 失,而上下文路径则用于解决感受野缩小的问题。BiSeNet 主要用于实时语义分割,在 精度和速度上力求兼顾。
超分辨算法:Wang等人将超分辨算法和语义分割算法相结合去提升计算效率,其通过共享编码器的方式有效地提取低分辨率图像的低级特征信息,再利用超分辨算法支路在模型训练过程中修正语义分割网络的输出精细程度,并在最终的前向传播过程中将超分辨支路去除从而可以使得语义分割模型在低分辨率图像上完成特征提取和整合。
轻量级特征提取网络:此外,一系列以轻量级特征提取网络为基础网络的实时语义分割模型被广泛提出并投入应用,SwiftNet采用ResNet-18为基础网络并结合U-Shape型编码器-解码器结构达到了良好的分割表现;DFANet采用改良的Xception网络作为基础网络,并让特征图多次经过该特征提取网络进而得到不同分辨率下的特征图从而进一步提取有效的语义信息。
2019 年,越来越多的研究者在考虑语义分割任务的实时性与精度的兼顾。例如,旷视科技提出的 DFANet(Deep Feature Aggregation Network) 就通过所设计的级联子网 和级联子阶段来聚合相应的特征,同时具有实时性和准确性。
二、语义分割技术基础
语义分割的本质是像素级别的物体分类任务,其基本结构可以被概括为编码器-解码器结构(Encoder-Decoder)。输入图像经过“编码”阶段提取出颜色、纹理、边缘等低级特征,再经过“解码”阶段将获取的低级特征信息进行加工获取富含语义信息和物体分类相关的高级特征信息,然后通过相关上采样技术将下采样后的特征图上采样回原始输入图像分辨率,最终经过分类层完成像素级别的物体分类任务。
2.1 编码器技术
编码器主要的技术手段是利用卷积操作去提取图像中含有的低级特征信息。这类低级特征信息往往含有与物体相关的边缘信息、颜色信息和纹理信息等等。
通常在“编码”阶段,模型需要采用池化层或者带有跨步操作的卷积层进行下采样,从而减少模型的计算量,提高模型的运算效率。
普通的卷积操作如下图所示,当输入张量的维度为H*W*M时,H代表张量行数,W代表张量列数,M代表张量的通道数;

若输出张量的通道数为N,则一个标准卷积需要N个通道数为M的卷积核去与输入张量做点运算(假设卷积核大小为K*K)。因此,其参数量可以表示为:
Number of Parameter = K * K * M * N
解释:普通卷积中,卷积核行列是K * K;输入张量通道数为M,所以卷积核的通道数也为M;输出张量的通道数为N,所以需要N个卷积核。即:K * K * M * N
深度可分离卷积,能减少标准卷积的参数量,提升模型的运算效率。深度可分离卷积核如下图所示,它的每一个卷积核只负责输入张量的一个通道。
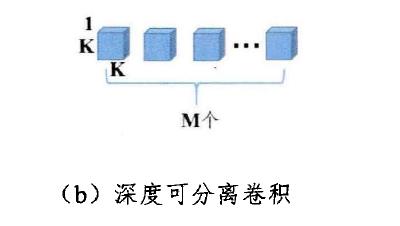
因此,深度可以分离卷积的卷积核数等于输入张量的通道数,输出张量的通道数和输入张量的通道数一致。
但深度可分离卷积缺乏各个不同通道之间特征信息的交互,为了进一步增加跨通道信息,深度可分离卷积之后往往需要增加下图所示的卷积核大小为1*1的普通卷积(逐点卷积),由此可以得到跨通道交互的特征信息。
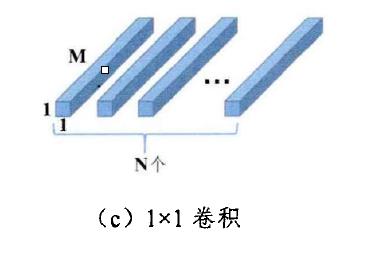
最终在达到相同感受野及相同大小输出张量时,深度可分离卷积和逐点卷积可将普通卷积的参数数量减少为:
Number of Parameter = K * K *1 * M + 1 * 1 *M * N
因此,深度可分离卷积和逐点卷积的结合可以在相同感受野和通道寄到胡的情况下大大减少普通卷积的参数量,从而有助于模型的轻量化与移动端设备的部署。
空洞卷积,Dilated Convocation,也被译作膨胀卷积、带孔卷积、扩张卷积,随着模型对感受野需求的增大被引入到模型设计中。它可以在保持模型参数量不变的情况下,增大模型的感受野进而跟更好提取特征图中的上下文信息,从而提高模型对有效特征的选择和利用。
空洞卷积相当于通过对普通卷积核本身进行补零,然后在输入特征图的两个维度上进行卷积运算的方法增加感受野,普通卷积就相当于膨胀率为1时的空洞卷积。
如下图所示,其中a图代表核大小为3*3的普通卷积核;b图代表膨胀率为2,核大小为3*3的空洞卷积核(通过对普通卷积核进行间隔补零)。

它们具有明显的感受野差异,同样为3*3大小的卷积核,普通卷积核的感受野为3*3,而膨胀率为2的空洞卷积的感受野为7*7。
除了上述卷积操作外,还有可变形卷积、空间变换卷积模型等等特殊的卷积操作。它们可以提取出与输入物体空间分布相关的特征。池化层是在“编码”阶段下采样的另一种常用操作,它不需要任何训练参数即可以较好地保留特征。池化层主要分为平均池化层核最大池化层。平均池化层在对应池化核中平均相应区域的特征值,而最大池化层在对应池化核保留该区域内特征图的最大值。
2.2 解码器技术
语义分割解码器阶段主要的任务是将经过编码器阶段的下采样后的低级特征信息进行处理,进而提取富含语义信息的高级特征信息,并通过相关技术将其分辨率恢复为输入图像的分辨率大小。
其主要核心技术目标是解决上采样问题。语义分割的上采样技术主要包括插值、反卷积和反池化操作。
插值:插值操作是语义分割常见的技术方案,主要包括最近邻插值、双线性插值和双立方插值。为了保证特征图的连续性和良好的计算效率,双线性插值是常用的方法。
反池化:反池化是池化操作的反向操作,可以在不引入额外参数的情况下实现特征图尺寸的恢复。SegNet是第一个运用反池化技术的语义分割模型。反池化过程如下图所示,
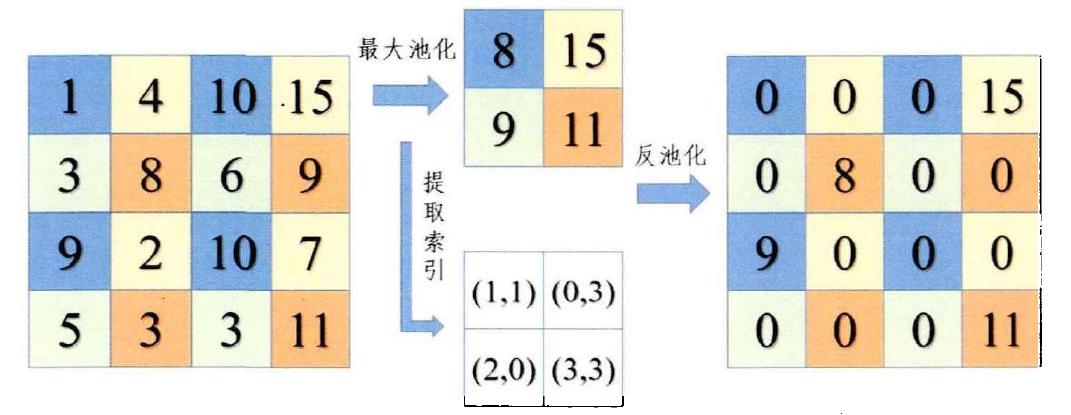
“编码”阶段利用最大池化层获取降采样特征图,同时保留了相应的位置索引信息;“解码”阶段利用该索引信息将特征图的信息和分辨率进行恢复。
反卷积:又称为转置卷积,最早由FCN使用而被广泛运用在语义分割模型中。反卷积并不是卷积运算的逆运算,相反它是一种特殊的卷积运算。它先按照一定的比例通过对特征图补零来扩大输入特征图的尺寸,接着再利用和普通卷积一样的运算过程进行正向卷积。
如下图所示,3*3特征图经过3*3卷积核大小,步长为1的反卷积过程。其中,橙色区域代表输入3*3特征图;灰色区域代表卷积操作的区域;蓝色区域代表经过反卷积之后的5*5特征图。
首先通过对输入分辨率为3*3的特征图进行补零,获取7*7的特征图(虚框区域),再经过一个3*3卷积核进行普通卷积运算即可得到5*5的特征图。
图像经过“编码”和“解码”阶段特征重构后,模型的最后阶段将利用一个输出通道数为类别数的普通卷积操作进行特征选取以完成语义分割。
2.3 多尺度特征融合
随着模型深度的不断加大,与输入图像轮廓特征有关的信息会逐层丢失。传统的语义分割模型在“编码”层和“解码”层之间通过直接相连的方式进行特征图和信息的传递。因此在“编码”阶段,特征图各个位置均以相同的感受野获取输入图像的信息。但是对于尺寸、体积大小不同的物体,感受野需求往往是不一样的。
例如,汽车和房屋需要相对较大的感受野获取足够的语义信息完成物体的识别,而人以及其他小物体所需的感受野相对较小。完全一致的单一感受野难以适应真实场景下各类物体大小不同的分割问题,于是多尺度特征融合得到了广泛研究和采用。
多尺度特征融合,它主要解决的问题是对“编码”阶段获取的低级特征进行相关操作获取不同尺度下的特征,然后进行多尺度特征融合使得“编码”可以获取不同感受野大小的特征。
多尺度特征融合一般分为两种类型,图像金字塔和特征金字塔模式。图像金字塔模型在传统数据图像处理中得到了广泛的应用。如下图所示:
图像金字塔:在语义分割领域,多支路结构是典型的图像金字塔模型,如ICNet、BiSeNet等。这类模型在不同模块或处理支路中输入不同分辨率大小的图像,通过对不同分辨率大小图像的处理提取出不同感受野下的特征,最终将特征进行融合以补充输出结果中缺失的空间轮廓细节信息。
图像金字塔充分利用了多尺度图像的各类信息,模仿人眼观察不同大小分辨率图像获取信息的方式,较好地补充了多尺度信息。但是,图像金字塔并行的网络结构使得模型的内存消耗较大。
特征金字塔:它解决了图像金字塔内存消耗较大的问题,主要思路是利用不同分辨率大小的特征图进行融合,获取不同感受野大小的特征。带有跳跃连接的U-Shape型网络是典型的利用不同层特征图信息的结构。在语义分割领域得到广泛应用的特征金字塔模型,包括金字塔池化模型(Pyramid Pooling Module,PPN)和空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP)等。
金字塔池化模型最早由H Zhao等人提出的PSPNet使用,如下图所示,“编码器”获取的特征首先利用自适应池化获取不同分辨率的特征图,然后用一系列1*1卷积对获取的特征图处理获取新特征,再用双线性插值将新特征图恢复为初始分辨率,最终将特征值通过堆叠的方式进行特征融合从而完成了对不同感觉野特征的融合。
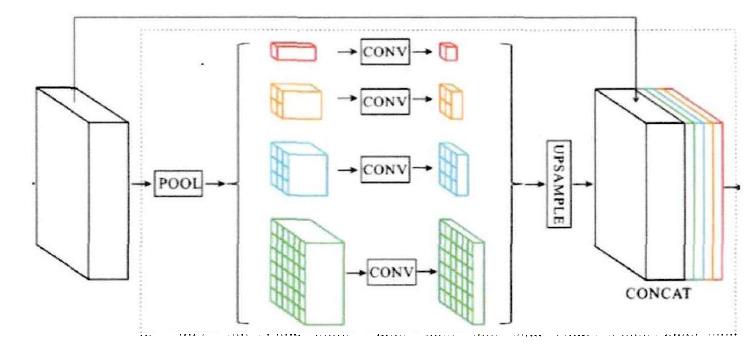
ASPP模型采用相似的方式,利用不同膨胀率的空洞卷积对特征图进行操作获取不同感觉野大小的特征图,然后将各特征图进行通道堆叠。
三、语义分割评价标准
语义分割算法的评价指标主要包括执行时间、内存占用、准确度三部分。
其中执行时间和内存占用反映的是算法模型的运行速度和参数量,而准确度主要分为像素精度和交并比 IoU 两大类。
模型运行速度主要由每秒帧数 fps(frames per second)和浮点运算数体现。
模型参数量代表模型的参数规模,通常模型生成的权重是用模型体积来衡 量占用空间大小的,由于深度学习模型的参数一般是单精度浮点型(32 位浮点型),每个参数占用 4B,因此模型的体积大约为参数量的 4 倍。
四、自动驾驶——语义分割相关数据集
面向自动驾驶场景下的语义分割任务,由于非结构化场景的复杂性,是一个非常具有 挑战性的任务,所以有许多研究者和研究机构公开了很多相关的数据集推动语义分割领域的发展,这些数据集通过使用多个摄像头采集图片数据,并图像上进行精细的标注形成准确的标签值。
在本文中选用了常用的 Cityscapes 数据集和 CamVid 数据集,下面是 这两个数据集的简介:
(1)Cityscapes 数据集
Cityscapes 数据集上专门针对城市街道场景的数据集,整个数据集由 50 个不同 城市的街景组成,数据集包括了 5000 张精准标注的图片和 20000 张粗略标注的图片。
其中精准标注的图片主要用于强监督学习,可分为训练集、验证集和测试集,而粗略标 注的图片主要用于弱监督语义分割算法的训练与测试。在 Cityscapes 数据集中通常使用 19 种常用的类别用于类别分割精度的评估。
(2)CamVid 数据集
CamVid 数据集是由剑桥大学公开发布的城市道路场景的数据集。数据集包 括 700 多张精准标注的图片用于强监督学习,可分为训练集、验证集、测试集。同时, 在 CamVid 数据集中通常使用 11 种常用的类别来进行分割精度的评估,分别为:道路 (Road)、交通标志(Symbol)、汽车(Car)、天空(Sky)、行人道(Sidewalk)、电线杆 (Pole)、围墙(Fence)、行人(Pedestrian)、建筑物(Building)、自行车(Bicyclist)、 树木(Tree)。
参考文献
[1] 项凯特.面向交通场景感知的语义分割技术研究[D].浙江大学,2021
[2] 向石方.面向智能车场景的语义分割算法研究[D].华南理工大学,2020
本文直供大家参考和学习,谢谢。
以上是关于语义分割(研究现状技术基础)的主要内容,如果未能解决你的问题,请参考以下文章