基础算法一致性Hash算法
Posted 醉酒的小男人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基础算法一致性Hash算法相关的知识,希望对你有一定的参考价值。
hash这个词对我们来说并不陌生,以缓存服务器来说,一般会在线上配置好几台服务器,然后根据hash来决定请求哪台缓存服务,比如常见的就是取模方式 hash(key)%num 来获取目标机器。
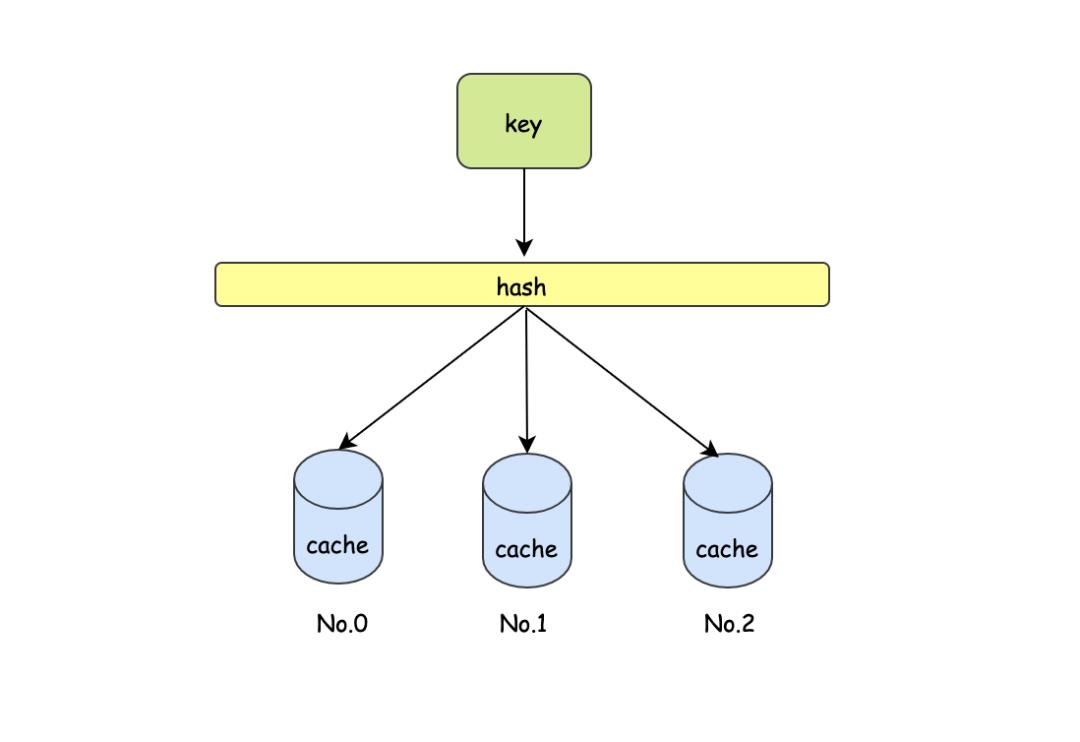
假设现在有3台缓存服务器,并且当前有3个缓存的key,分别是k0,k1,k2,在经过hash以后,它们的分布情况如下:
hash(k0)%3=0 #No.0
hash(k1)%3=1 #No.1
hash(k2)%3=2 #No.2
很幸运,分布的非常均匀,每台机器一个。某天,由于线上要做个活动,预计访问量会加大,需要选择加一台服务器来分担压力,于是经过hash之后,k0,k1,k2的分布情况如下:
hash(k0)%4=0 #No.1
hash(k1)%4=1 #No.2
hash(k2)%4=2 #No.3
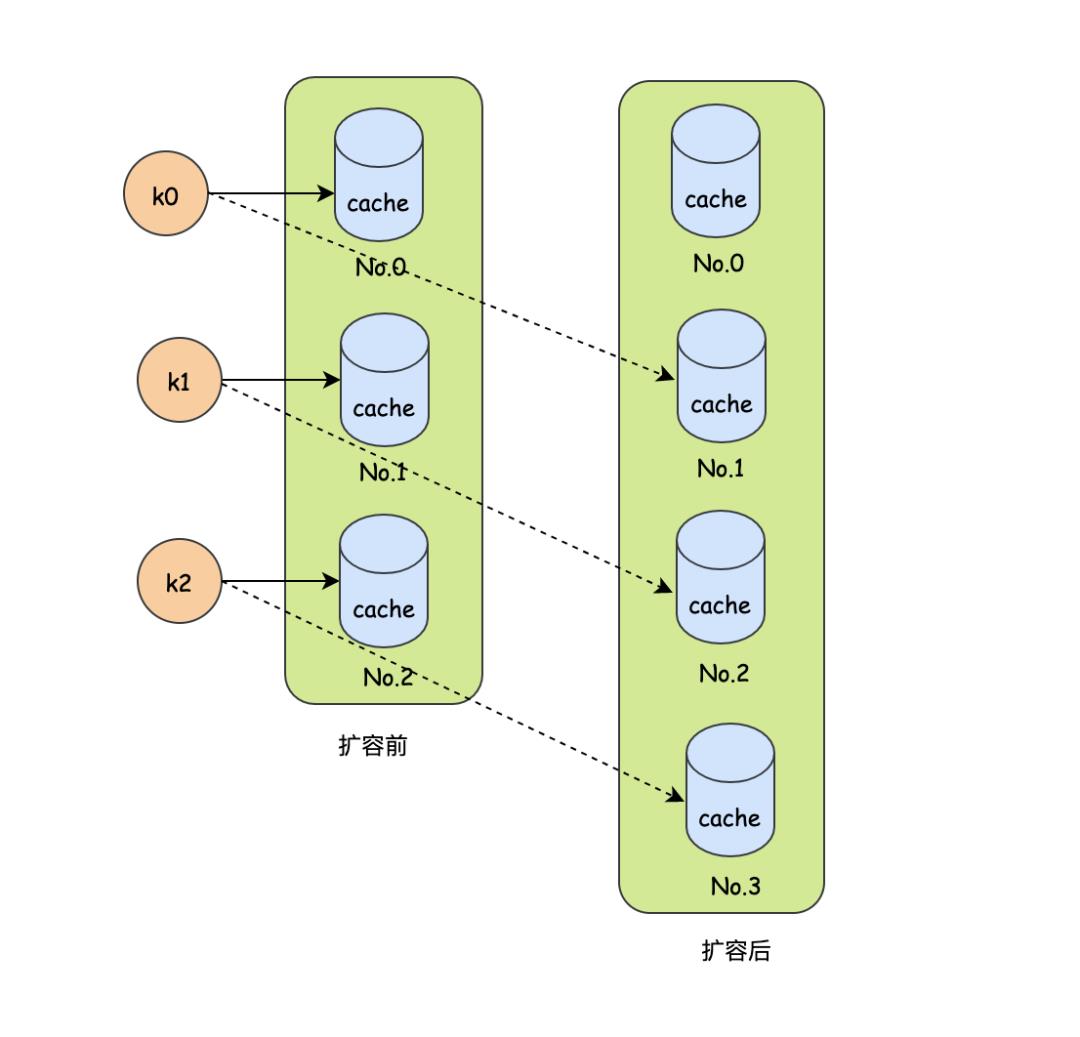
k0的目标缓存服务器由原本的No.0变成了No.1
k1的目标缓存服务器由原本的No.1变成了No.2
k2的目标缓存服务器由原本的No.2变成了No.3
可以发现因为添加了一台缓存节点,导致了k0,k1,k2原来的缓存全部失效了,这似乎有点问题,类似缓存雪崩,严重的话会对DB造成很大的压力,造成这个问题的主要原因是因为我们加了一个节点,导致hash结果发生了变动,此时的hash可以说是不稳定的。
为了解决rehash不稳定的问题,于是出现了一致性hash算法。一致性hash的原理比较简单,首先存在一个hash圆环,这个圆环可以存放 0-2^32-1 个节点。
第一步就是把我们的目标服务器节点通过hash映射到这个环上
第二步根据我们需要查找的key,它应该也对应hash环上的某个位置
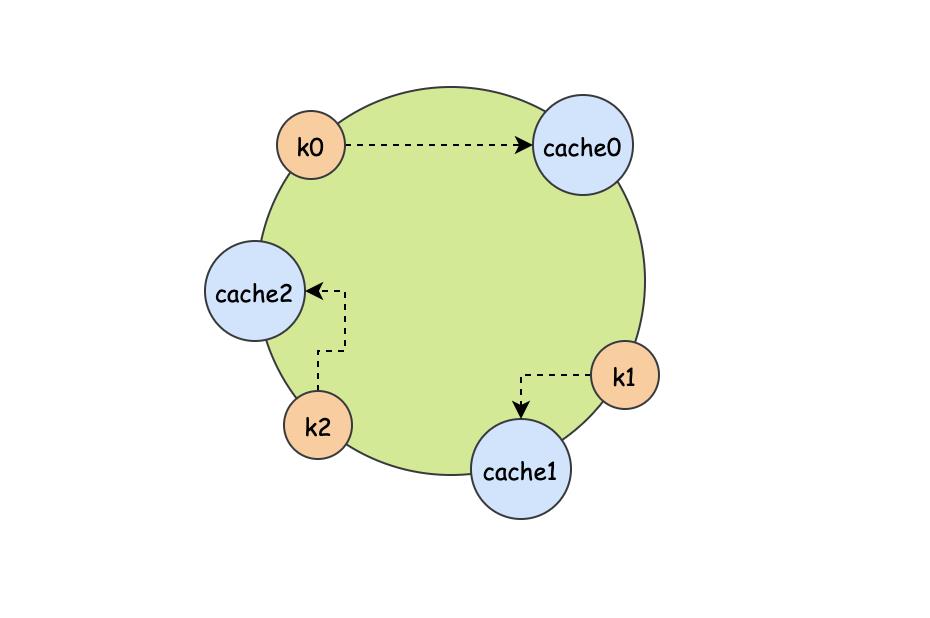
也许你会问,这k0、k1、k2也没和某个缓存节点对上呀~,这就是一致性hash不同的地方,它此时查找的方式并不是 hash(key)=某个节点,而是根据key的位置,顺时针找到第一个节点,这个节点就是当下这个key的目标节点。
我们再来看看在一致性hash的情况下,新增一个节点会发生什么。
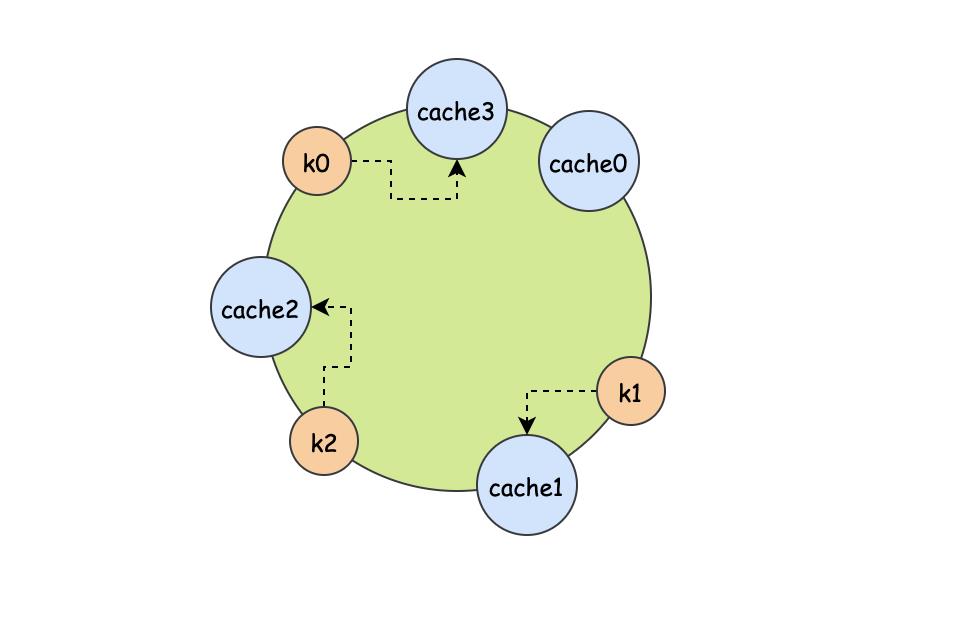
此时唯一的变动就是k0原本应该打到cache0节点的,现在却打到了我们新加的节点cache3上,而k1,k2是不变的,也就是说有且只有k0的缓存失效了,相比之前,大大降低了缓存失效的面积。
当然这样的节点分布算是比较理想的了,如果我们的节点是这样分布的:
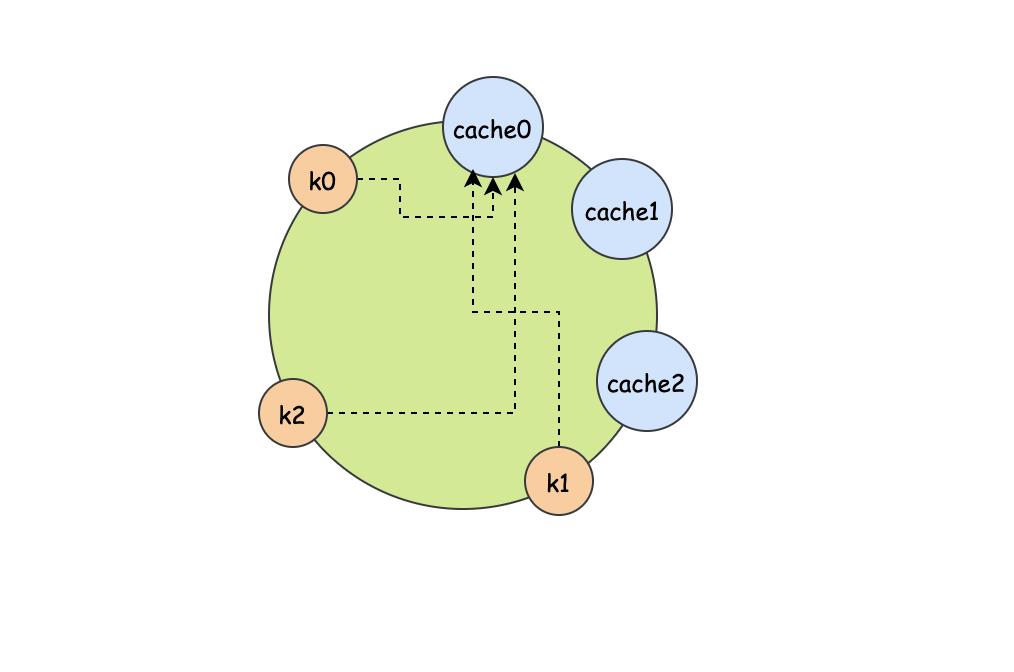
几个cache节点分布的比较集中,由于顺时针查找法,所以最终k0,k1,k2都落在cache0节点上,也就是说cache1、cache2基本就是多余的,所以为了解决这种数据倾斜的问题,一致性hash又引入了虚拟节点的概念,每个节点可以有若干个虚拟节点,比如:
cache0->cache0#1
cache1->cache1#1
cache2->cache2#1
虚拟节点并不是真正的服务节点,它只是一个影子,它的目的就是站坑位,让节点更加分散,更加均匀。
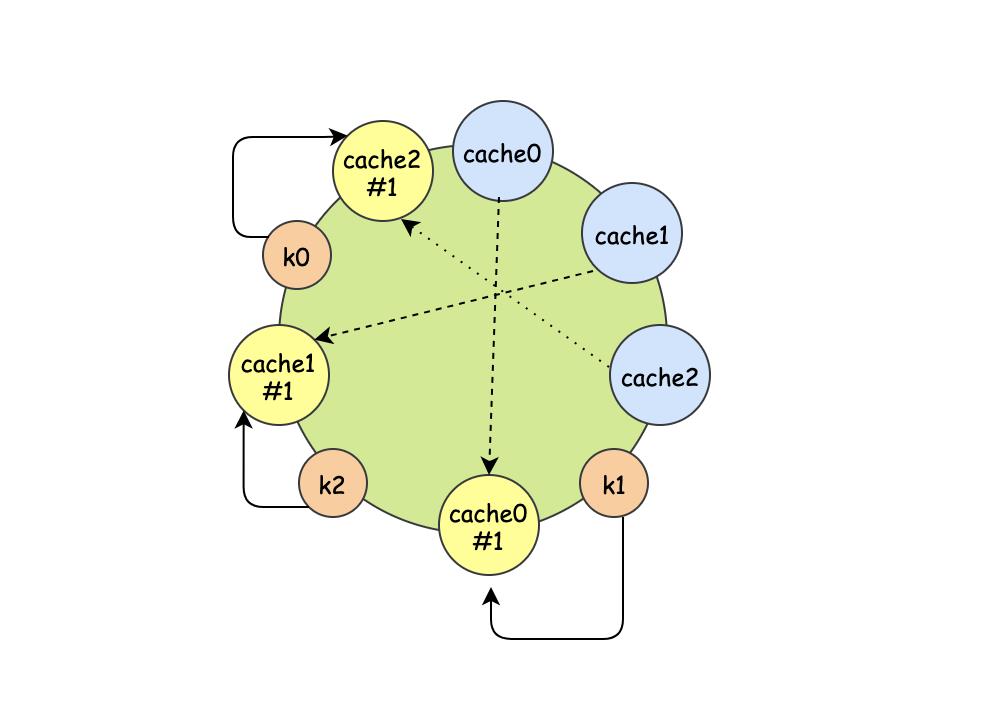
这样通过映射出虚拟节点以后,k0打到cache2,k1打到cache0,k2打到cache1,虚拟节点越多,理论分布的越均匀。
以上是关于基础算法一致性Hash算法的主要内容,如果未能解决你的问题,请参考以下文章