计算结构体的大小-数据对齐提高读取性能与可移植性,利用空间换时间
Posted Linux bsping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算结构体的大小-数据对齐提高读取性能与可移植性,利用空间换时间相关的知识,希望对你有一定的参考价值。
大家学习C语言的时候基本都遇到过求结构体大小的问题吧,刚刚开始肯定都想着直接把结构体的各个因子相加起来就好了,但是这样确实是错误的,虽然有时候结果是对的。想得到结构体的大小可以使用sizeof()这个函数,当然也可以自己进行计算,下面就分享一下我的方法。
一、数据对齐
首先我们先了解一下什么是数据对齐,在C语言中,结构是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元。在结构中,编译器为结构的每个成员按其自然边界分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。为了使CPU能够对变量进行快速的访问,变量的起始地址应该具有某些特性,即所谓的”对齐”. 比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除。CPU在读取结构体的数据时会以固定的位数进行读取,当然这个位数我们用户可以改变。以下举例说明:
struct test
{
char x1;
short x2;
float x3;
char x4;
}; 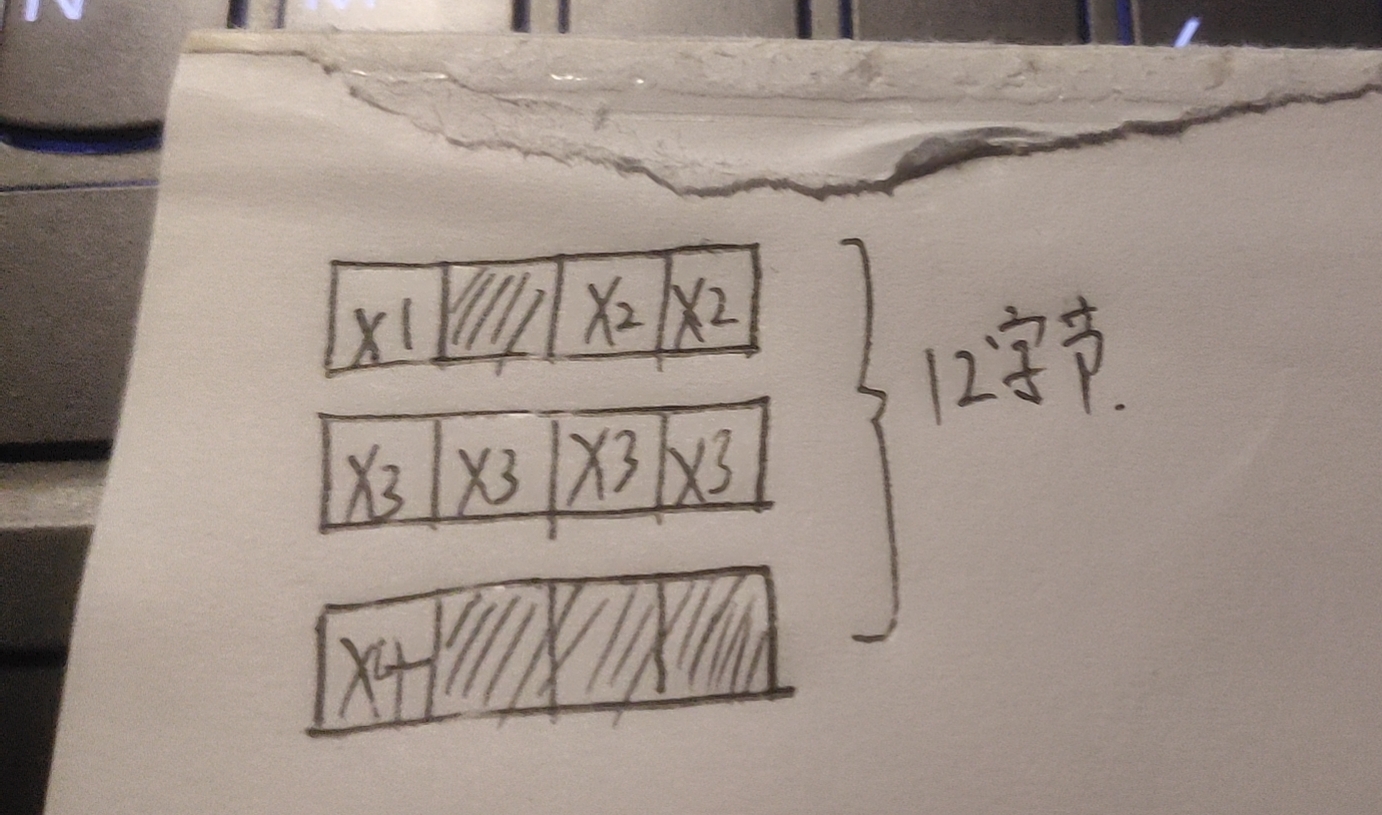
结构的第一个成员x1,其偏移地址为0,占据了第1个字节。第二个成员x2为short类型,其起始地址必须2字节对界,因此,编译器在x2和x1之间填充了一个空字节。结构的第三个成员x3和第四个成员x4恰好落在其自然边界地址上,在它们前面不需要额外的填充字节。在test结构中,成员x3要求4字节对界,是该结构所有成员中要求的最大边界单元,因而test结构的自然对界条件为4字节,编译器在成员x4后面填充了3个空字节。整个结构所占据空间为12字节。
二、为什么要数据对齐
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐。其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。显然在读取效率上下降很多。如下图:

三、同一个结构体,顺序不同大小可能也不同
struct A
{
int a;
char b;
short c;
};
struct B
{
char b;
int a;
short c;
};经计算A的大小是8字节,B的大小是12字节。为什么呢,根据图解就可以知道:
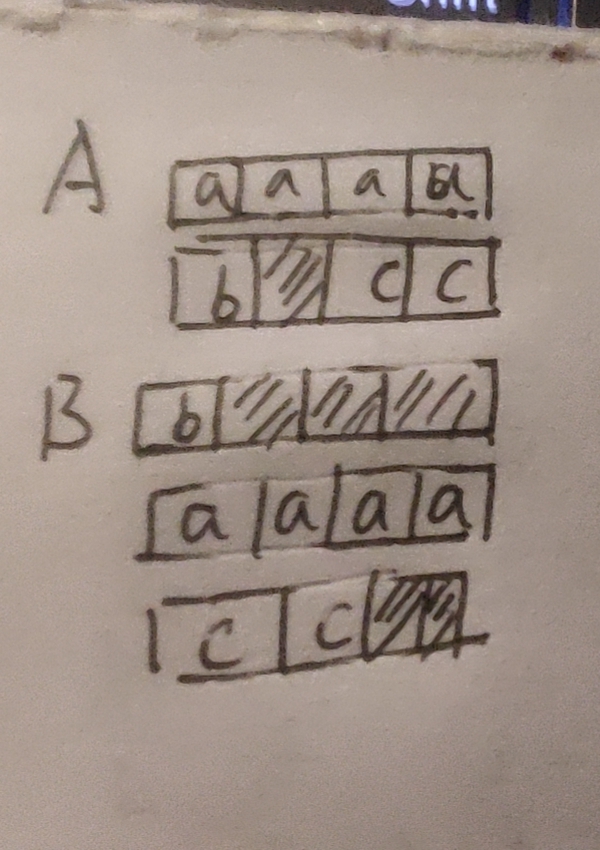
所以以后写结构体尽量把小数据靠前写。
四、数据对齐的一些特点
1、结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
2、结构体大小为其成员中自身对齐值最大的那个值的整数倍。
3、数据类型自身的对齐值:char自身对齐值为1,对于short型为2,int,float,double类型自身对齐值为4单位字节。
以上有自己的一些观点,如果有错误请批评指正。
以上是关于计算结构体的大小-数据对齐提高读取性能与可移植性,利用空间换时间的主要内容,如果未能解决你的问题,请参考以下文章