深度学习基础——硬件知识总结
Posted 非晚非晚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习基础——硬件知识总结相关的知识,希望对你有一定的参考价值。
文章目录
1. 深度学习用CPU和GPU训练的区别
CPU主要用于串行运算;而GPU则是大规模并行运算。由于深度学习中样本量巨大,参数量也很大,所以GPU的作用就是加速网络运算。- CPU算神经网络也是可以的,算出来的神经网络放到实际应用中效果也很好,只不过速度会很慢罢了。
而目前GPU运算主要集中在矩阵乘法和卷积上,其他的逻辑运算速度并没有CPU快。
2. GPU
GPU性能排行可以查看GPU天梯榜。
在英伟达产品系列中,有消费领域的GeForce系列,有专业绘图领域的Quadro系列,有高性能计算领域的Tesla系列,如何选择?有论文研究,太高的精度对于深度学习的错误率是没有提升的,而且大部分的环境框架都只支持单精度,所以双精度浮点计算是不必要,Tesla系列都去掉了。从显卡效能的指标看,CUDA核心数要多,GPU频率要快,显存要大,带宽要高。这样,最新Titan X算是价格便宜量又足的选择。
英伟达以其大规模的并行GPU和专用GPU编程框架CUDA主导着当前的深度学习市场。但是越来越多的公司开发出了用于深度学习的加速硬件,比如谷歌的张量处理单元(TPU/Tensor Processing Unit)、英特尔的Xeon Phi Knight‘s Landing,以及高通的神经网络处理器(NNU/Neural Network Processor)。像Teradeep这样的公司现在开始使用FPGA(现场可编程门阵列),因为它们的能效比GPU的高出10倍。 FPGA更灵活、可扩展、并且效能功耗比更高。 但是对FPGA编程需要特定的硬件知识,因此近来也有对软件层面的FPGA编程模型的开发。

3. CPU
在深度学习任务中,CPU并不负责主要任务,单显卡计算时只有一个核心达到100%负荷,所以CPU的核心数量和显卡数量一致即可,太多没有必要,但是处理PCIE的带宽要到40。
4. 其他硬件
- 内存条
内存大小最起码最起码要大于你所选择的GPU的内存的大小(最好达到显存的二倍,当然有钱的话越大越好)
在深度学习中,会涉及到大量的数据交换操作(例如按batch读取数据)。当然你也可以选择将数据存储在硬盘上,每次读取很小的batch块,这样你的训练周期就会非常长。常用的方案是“选择一个较大的内存,每次从硬盘中读取几个batch的数据存放在内存中,然后进行数据处理”,这样可以保证数据不间断的传输,从而高效的完成数据处理的任务。
- 电源问题
一个显卡的功率接近300W,四显卡建议电源在1500W以上,为了以后扩展,可选择更大的电源。
5. CPU 和 GPU 的冷却系统
冷却非常重要,是整个系统中一个重要的瓶颈。相比较于糟糕的硬件选择,它更容易降低性能。对于CPU,你可以使用标准散热器或者一体化(AIO)水冷解决方案。但是对于GPU,你需要特别注意。
- 风冷
- 1.被动式散热:它其实就是一个无风扇版的散热器,全靠空气流通带走鳍片上的热量。优点:完全没有噪音。缺点:散热性能差,适合发热量特别小的平台(我们的手机几乎都是被动式散热,甚至不如被动式散热)。
- 2.下压式散热:这种散热器风扇是朝下吹的,所以在兼顾CPU散热的同时也可以惠顾到主板和内存条散热。但是散热效果稍差,而且会扰乱机箱风道,所以适合发热小的平台,同时由于体积小不占空间,所以是小机箱的福音。
- 3.塔式散热:这种散热器高高耸立如高塔一般,故名塔式散热。这种散热器单向吹风,不会扰乱风道,而且鳍片和风扇可以做的比较大,因此散热性能最好。但是不能兼顾主板和内存散热,因此需要机箱上的风扇辅助才行。
- 水冷:
- 优点:因为减少了风扇的数量,所以也减少了风扇所产生的振动及噪音。散热效果比风冷系统高出许多。
- 缺点:水冷散热器所需的用具非常庞大,占用了一定的空间。价钱比风冷系统较高。因为结构比风冷系统复杂,还多加了一级的工质,所以可靠性也较差。若组装过程不慎或材料不佳时,会出现漏水,有可能会损害电脑零件。
6. 深度学习四种基本的运算
-
矩阵相乘(Matrix MulTIplicaTIon)——几乎所有的深度学习模型都包含这一运算,它的计算十分密集。
-
卷积(ConvoluTIon)——这是另一个常用的运算,占用了模型中大部分的每秒浮点运算(浮点/秒)。
-
循环层(Recurrent Layers )——模型中的反馈层,并且基本上是前两个运算的组合。
-
All Reduce——这是一个在优化前对学习到的参数进行传递或解析的运算序列。在跨硬件分布的深度学习网络上执行同步优化时(如AlphaGo的例子),这一操作尤其有效。
7. 算力–处理单元
人工智能的实现需要依赖三个要素:算法是核心,硬件和数据是基础。
从产业结构来讲,人工智能生态分为基础、技术、应用三层。
基础层包括数据资源和计算能力;技术层包括算法、模型及应用开发;应用层包括人工智能+各行业(领域),比如在互联网、金融、汽车、游戏等产业应用的语音识别、人脸识别、无人机、机器人、无人驾驶等功能。
1Flops/s简写为T/s,是数据流量的计数单位,意思是“1万亿次浮点指令每秒”,它是衡量一个电脑计算能力的标准。
1TFlops=1024GFlowps,即1T=1024G。
各种FLOPS的含义:
1) 一个MFLOPS(megaFLOPS)等于每秒1百万(=10^6)次的浮点运算;
2) 一个GFLOPS(gigaFLOPS)等于每秒10亿(=10^9)次的浮点运算;
3) 一个TFLOPS(teraFLOPS)等于每秒1万亿(=10^12)次的浮点运算;
4) 一个PFLOPS(petaFLOPS)等于每秒1千亿(=10^15)次的浮点运算。
8. 查看硬件信息
(1)查看GPU信息
- 命令一
lspci | grep -i nvidia
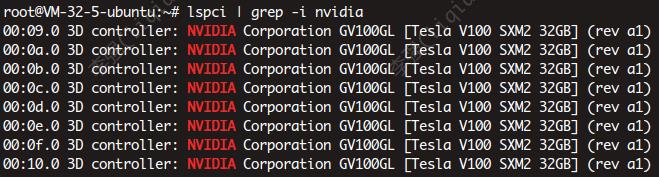
- 命令二
nvidia-smi
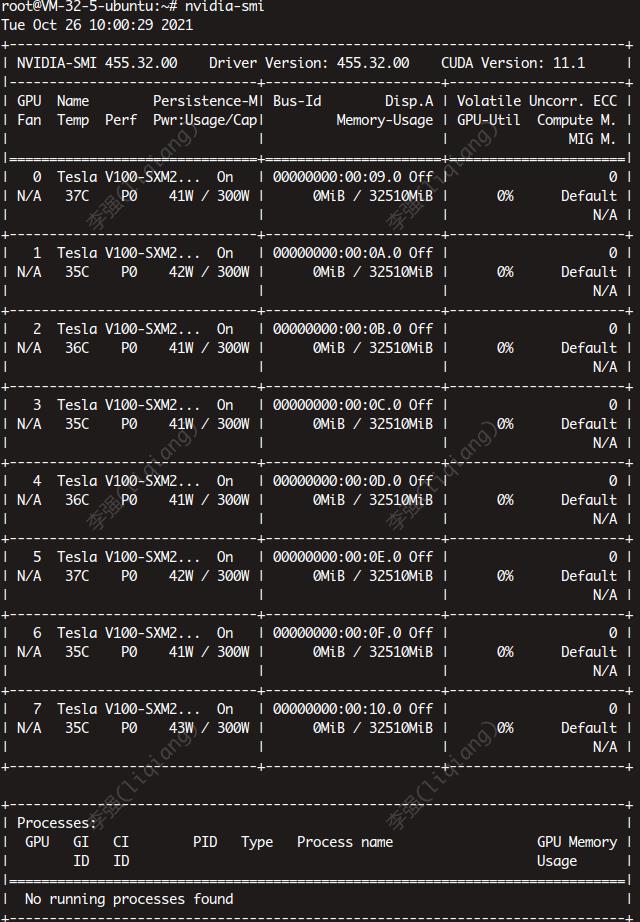
上图显示8个GPU(8卡),上图详细信息如下:
- Fan:显示风扇转速,数值在0到100%之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
Temp:显卡内部的温度,单位是摄氏度;- Perf:表征性能状态,从P0到P12,
P0表示最大性能,P12表示状态最小性能;- Pwr:能耗表示;
- Bus-Id:涉及GPU总线的相关信息;
- Disp.A:是Display Active的意思,表示GPU的显示是否初始化;
Memory Usage:显存的使用率;Volatile GPU-Util:浮动的GPU利用率,GPU占用率;- Compute M:计算模式;
(2)查看CPU信息
top
top的解释和其他其他硬件信息查看可见这篇文章
以上是关于深度学习基础——硬件知识总结的主要内容,如果未能解决你的问题,请参考以下文章