Hadoop完全分布式搭建
Posted 会飞的鲁班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop完全分布式搭建相关的知识,希望对你有一定的参考价值。
集群配置
可以将服务分别去配置在多台服务器上面以hadoop105,hadoop106,Hadoop107为案例
| 组件 | hadoop105 | hadoop106 | hadoop107 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
NAMENODE职责
NAMENODE职责:
负责客户端请求的响应
元数据的管理(查询,修改)
是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
SecondaryNameNode
从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
默认在安装在NameNode节点上,但这样…不安全!
DATANODE
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
注意:
- NameNode 和 SecondaryNameNode 不要安装在同一台服务器。
- ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上。
需要配置4个配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 | 解释说明 |
|---|---|---|
| core-default.xml | hadoop-common-3.1.3.jar/core-default.xml | Hadoop的全局配置文件,配置分布式文件系统的入口地址NameNode的地址和分布式文件系统中数据落地到服务器本地磁盘位置的配置。配置 HDFS 网页登录使用的静态用户 |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml | 配置HDFS文件系统属性配置。nn web 端访问地址,2nn web 端访问地址 |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml | 配置YARN的相关参数 |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml | MapReduce的运行框架为YARN. |
配置文件的路径
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
四个配置文件存放在$HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
案例路径:
/opt/module/hadoop-3.1.3/etc/hadoop
配置 core-site.xml
[tedu@hadoop105 hadoop]$sudo vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop105:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 tedu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>tedu</value>
</property>
:wq!
配置 hdfs-site.xml
[tedu@hadoop105 hadoop]$ sudo vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop105:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop107:9868</value>
</property>
:wq!
配置 yarn-site.xml
[tedu@hadoop105 hadoop]$ sudo vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop106</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
:wq!
mapred-site.xml
[tedu@hadoop105 hadoop]$ sudo vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
每一步修改完毕需要进行保存退出
:wq!
在集群上分发配置好的 Hadoop 配置文件
[tedu@hadoop105 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
群起集群
1.配置 workers
[tedu@hadoop105 hadoop]$ sudo vim /opt/module/hadoop-3.1.3/etc/hadoop/workers

:wq!
注意:配置工作节点,该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
2.启动集群
(1).如果集群是第一次启动,需要在 hadoop105 节点格式化 NameNode(注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。)
[tedu@hadoop105 hadoop]$ hdfs namenode -format
格式化后我们就可以看到配置的数据文件了
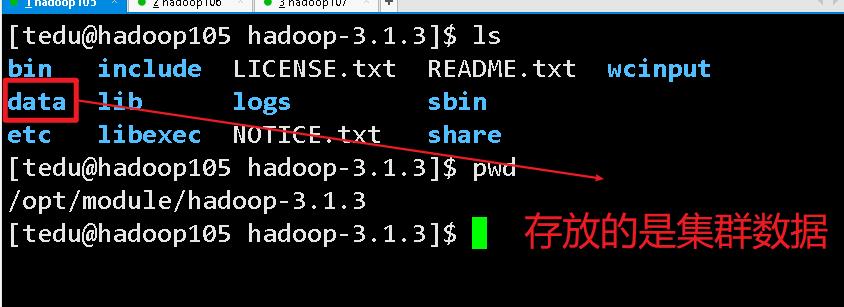
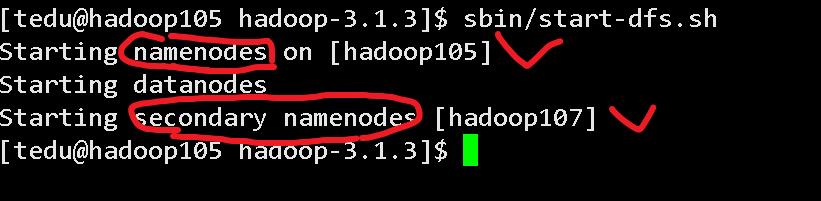
(2).启动 HDFS
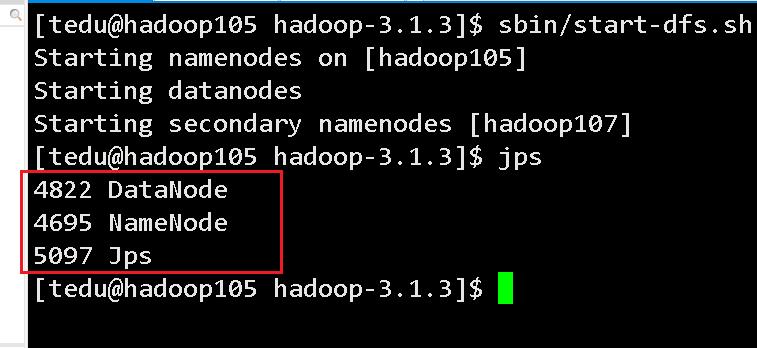
[tedu@hadoop105 hadoop-3.1.3]$ sbin/start-dfs.sh
hadoop105上面的节点
hadoop106节点
[tedu@hadoop106 ~]$ jps
2419 Jps
2343 DataNode
hadoop107节点
[tedu@hadoop107 ~]$ jps
2520 Jps
2473 SecondaryNameNode
2346 DataNode
启动yarn
[tedu@hadoop106 hadoop-3.1.3]$ sbin/start-yarn.sh
hadoop105
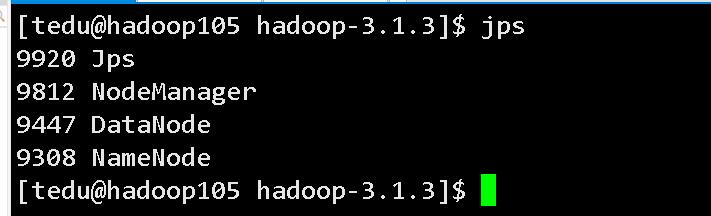
hadoop106
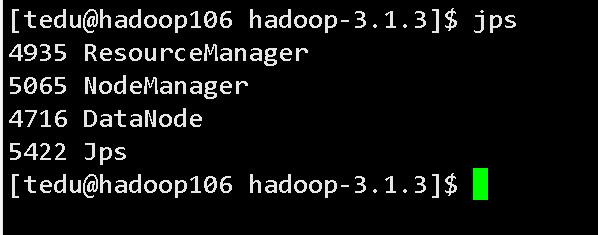
hadoop107
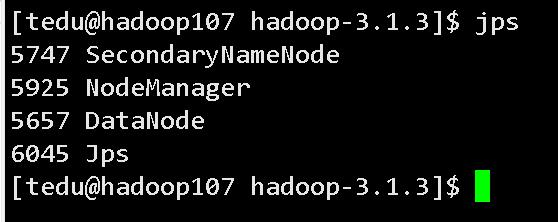
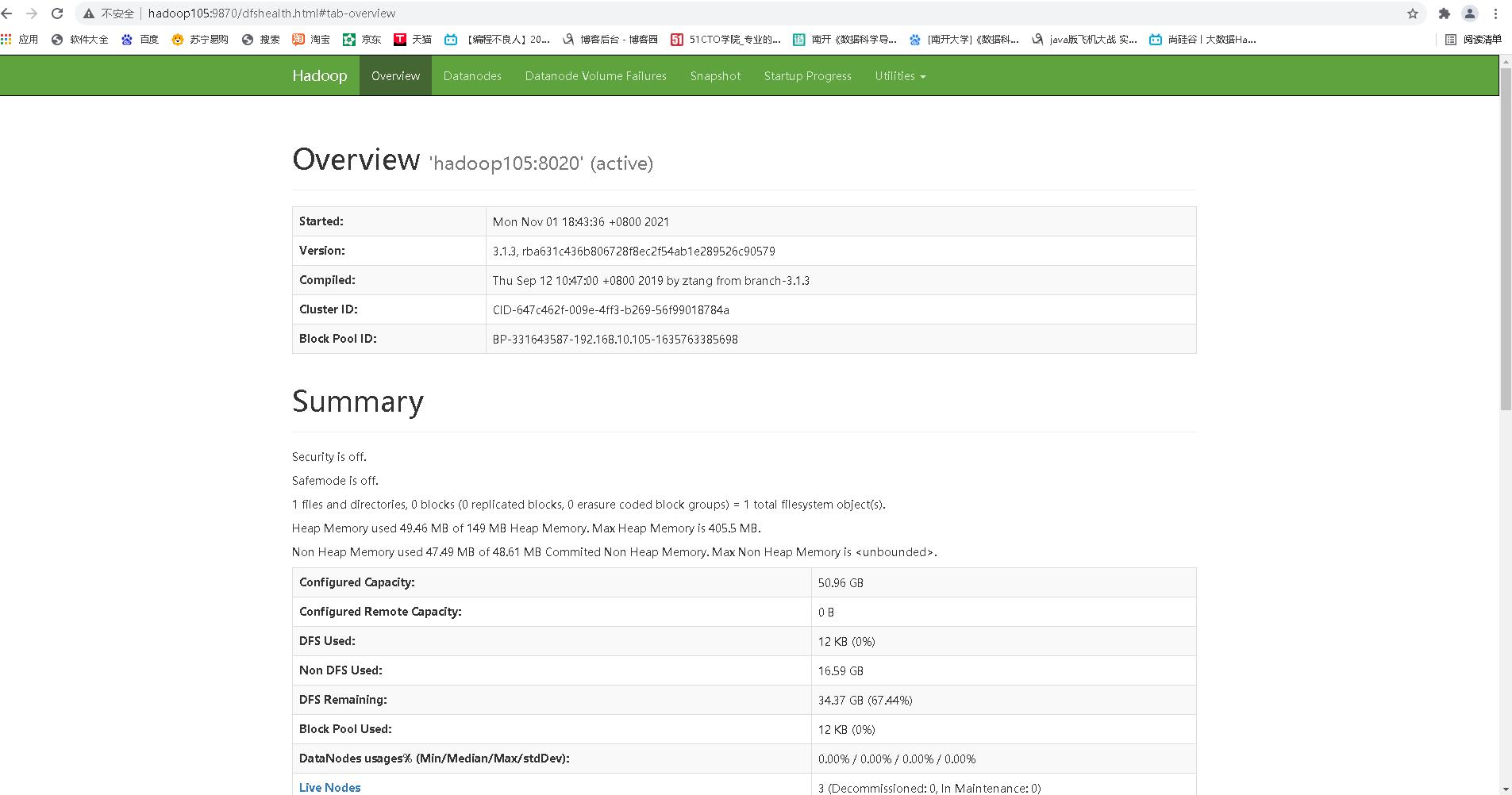
(4).Web 端查看 HDFS 的 NameNode**
- 浏览器中输入:http://hadoop105:9870
- 查看 HDFS 上存储的数据信息
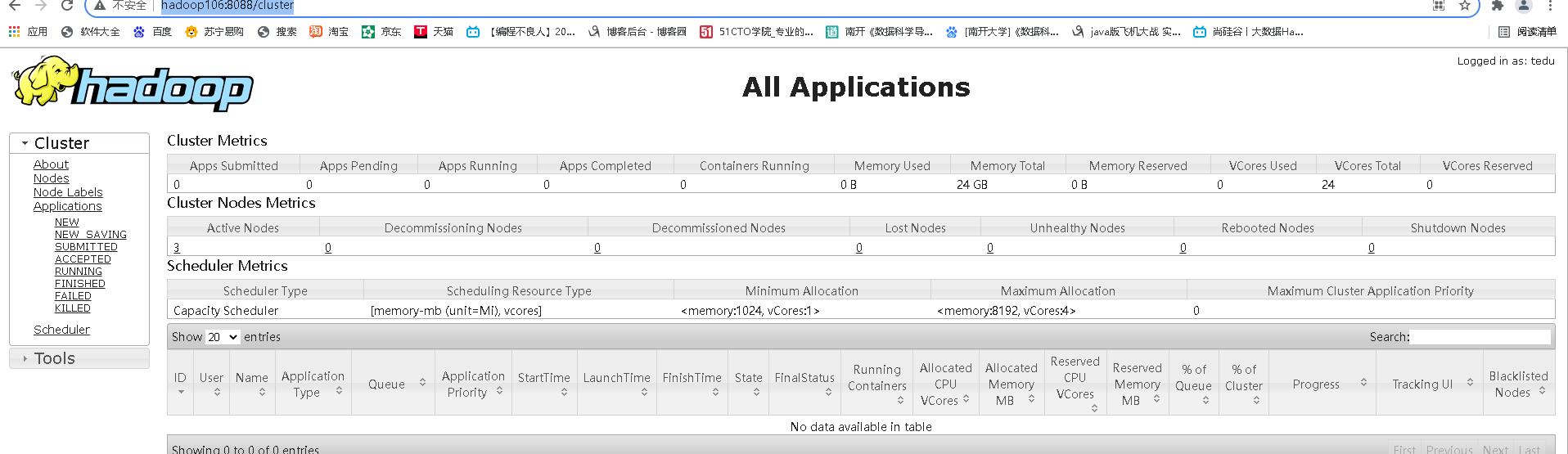
(5).Web 端查看 YARN 的 ResourceManager
- 浏览器中输入:http://hadoop106:8088
- 查看 YARN 上运行的 Job 信息
以上是关于Hadoop完全分布式搭建的主要内容,如果未能解决你的问题,请参考以下文章